点击上方 “小白学视觉 ”,选择加" 星标 "或“ 置顶 ”
重磅干货,第一时间送达
深度图像分类模型通常在大型带注释数据集上以监督方式进行训练。尽管模型的性能会随着更多注释数据的可用而提高,但用于监督学习的大规模数据集通常难以获得且成本高昂,需要专家注释者花费大量时间。考虑到这一点,人们可能会开始怀疑是否存在更便宜的监督资源。简而言之, 是否有可能从已经公开可用的数据中学习高质量的图像分类模型?OpenAI提出的对比语言图像预训练 (CLIP) 模型 [1] 最近由于在 DALLE-2模型 中的使用而重新流行起来,并且以积极的方式回答了这个问题。特别是,CLIP 提出了一个简单的预训练任务——选择哪个标题与哪个图像相配——它允许深度神经网络单独从自然语言(即图像标题)中学习高质量的图像表示。由于图像-文本对很容易在线获得并且通常很容易获得,因此可以轻松地为 CLIP 策划一个大型预训练数据集,从而最大限度地减少训练深度网络所需的注释成本和工作量。 除了学习丰富的图像表示之外,CLIP 通过在不观察单个标签的情况下在 ImageNet 上实现 76.2% 的测试准确率,彻底改变了零样本图像分类——与之前SOTA的零样本学习框架的 11.5% 测试准确率相比有了显着改进[2]。通过将自然语言作为图像感知任务的可行训练信号,CLIP 改变了监督学习范式,并使神经网络能够显着减少对注释数据的依赖。在这篇文章中,我将概述 CLIP 的细节,如何使用它来最大程度地减少对传统监督数据的依赖,以及它对深度学习的影响。 在了解 CLIP 的细节之前,了解模型提出之前的相关研究很有必要。 在本节中,我将概述先前相关的工作,并提供有关 CLIP 的灵感和发展的直觉。 即, 通过 初步工作表明自然语言是图像感知监督的有用来源来证明概念。 然而,由于此类方法相对于替代方法(例如,监督训练、弱监督等)表现不佳,因此在 CLIP 提出之前,通过自然语言进行的训练仍然不常见。
使用 CNN 预测图像说明。 先前的工作表明,预测图像说明允许 CNN 开发有用的图像表示 [3]。这种分类是通过将每个图像的标题、描述和主题标签元数据转换为 词袋 向量来执行的,然后可以将其用作多标签分类任务的目标。有趣的是,以这种方式学习的特征与通过 ImageNet 预训练获得的特征的质量相匹配,从而证明图像说明提供了关于每张图像的足够信息以学习判别表示。
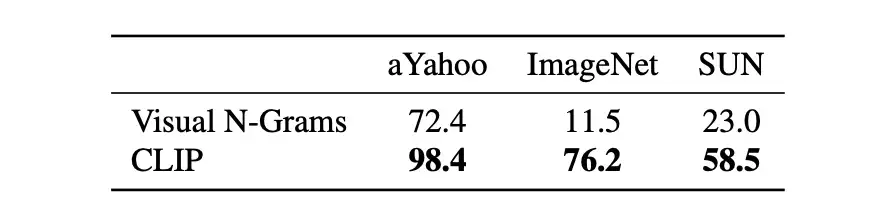
后来的工作将这种方法扩展到预测与每个图像相关的短语 [2],从而实现到其他分类数据集的零样本迁移。尽管这种方法的零样本性能很差(即在 ImageNet 上的测试准确率为 11.5%),但它表明仅使用自然语言就可以产生远远超过随机性能的零样本图像分类结果,从而初步证明弱监督零样本分类的概念。 来自带有Transformer的文本的图像表示。 同时,几项工作——包括 VirTex [4]、ICMLM [5] 和 ConVIRT [6]——探索了使用Transformer 架构 从文本数据中学习视觉特征。在高层次上,此类方法使用常见的训练任务让Transformer 从相关的图像说明中学习有用的图像表示。作为此类工作的结果, 掩码语言建模 (MLM)、 语言建模 和 对比学习 目标——通常用于在自然语言处理领域训练转换器——被发现是学习高质量图像表示的有用代理任务。 为未来的发现铺平道路 尽管以前的方法没有在大规模数据集上实现令人印象深刻的零样本性能,但这些基础工作提供了有用的经验教训。也就是说,之前的工作明确两点:1. 自然语言是计算机视觉监督的有效来源。2. 通过自然语言监督进行零样本分类是可能的。由于这些发现,进一步的研究工作被投入到在监督来源较弱的情况下执行零样本分类。这些努力产生了突破性的方法,例如 CLIP,它将自然语言监督从一种罕见的方法转变为一种出色的零样本图像分类方法。
CLIP 架构和训练方法的可视化概述 简而言之,上图中总结的 CLIP 模型旨在从相关图像说明中学习图像中的视觉概念。在本节中,我将概述 CLIP 架构、其训练以及生成的模型如何应用于零样本分类。 CLIP 由两个编码器模块组成,分别用于对文本和图像数据进行编码。对于图像编码器,探索了许多不同的模型架构,包括五个不同大小的 ResNets [7](即,模型尺寸是使用 EfficientNet 样式 [8] 模型缩放规则确定的)和三个 视觉Transformer 架构 [9]。图像编码器的这两个选项如下所示。然而,CLIP 的视觉Transformer 变体在训练时的计算效率提高了 3 倍,使其成为首选的图像编码器架构。 CLIP 中图像编码器架构的不同选项
CLIP 中的文本编码器只是一个仅解码器的Transformer ,这意味着在每一层中都使用了Mas k ed 的自注意力(与双向自注意力相反)。 Mas k ed 的 自注 意力 确保Transformer 对序列中每个标记的表示仅取决于它之前的标记,从而防止任何标记“展望未来”以更好地告知其表示。下面提供了文本编码器体系结构的基本描述。然而,应该注意的是,这种架构与大多数先前提出的语言建模架构(例如 GPT-2 或 OPT )非常相似。 CLIP 的文本编码器架构
尽管 CLIP 未应用于原始出版物中的任何语言建模应用,但作者利用掩蔽自注意力使 CLIP 将来更容易扩展到此类应用。 尽管之前的工作表明自然语言是一种可行的计算机视觉训练信号,但用于在图像和文本对上训练 CLIP 的确切训练任务并不是很明显。 我们应该根据标题中的文字对图像进行分类吗?以前的工作已经尝试过这个想法,但效果不是很好 [2, 3]。 有趣的是,作者发现预测确切的图像说明太困难了因为任何图像都可以用多种不同的方式来描述,这使得模型学习非常缓慢 。 理想的 CLIP 预训练任务应该是可扩展的,这意味着它允许模型从自然语言监督中有效地学习有用的表示。借鉴 对比表示学习 中的相关工作,作者发现可以使用一项非常简单的任务来有效地训练 CLIP——在一组候选字幕中预测正确的、相关联的字幕。下图说明了这样的任务。 CLIP 的图文对比预训练
在实 践中,这一 目标 是通过以下方式实现的:
这样的目标被称为多类 N 对(或 InfoNCE)损失 [10],通常应用于对比和度量学习中的问题。作为这个预训练过程的结果,CLIP 为图像和文本形成了一个联合嵌入空间,使得对应于相似概念的图像和标题具有相似的嵌入。 更好的任务 = 更快的学习。 通过使用这个更简单的代理任务训练 CLIP 模型,作者观察到训练效率提高了 4 倍;如下图所示。
CLIP 由于其对比目标提高了训练效率
在这里,训练效率是使用 ImageNet 上的零样本学习迁移率来衡量的。换句话说,当使用这个简单的目标时,CLIP 模型花费更少的训练时间(根据观察到的图像文本示例的数量)来实现在 ImageNet 上产生高零样本精度的模型。 因此,正确选择训练目标会对模型效率和性能产生巨大影响。
我们如何在没有训练示例的情况下对图像进行分类? CLIP 执行分类的能力最初看起来像是一个谜。鉴于它只从非结构化的文本描述中学习,它 怎么可能推广到图像分类中看不见的对象类别?CLIP 经过训练可以预测图像和文本片段是否配对在一起。 有趣的是,这种能力可以重新用于执行零样本分类。 特别是,通过利用未见类别的文本描述(例如,类别名称),可以通过将文本和图像传递给它们各自的编码器并比较生成的嵌入来评估每个候选类别; 请参阅下面的视觉描述。 使用 CLIP 执行零样本分类
形式化这个过程,零样本分类实际上包括以下步骤:
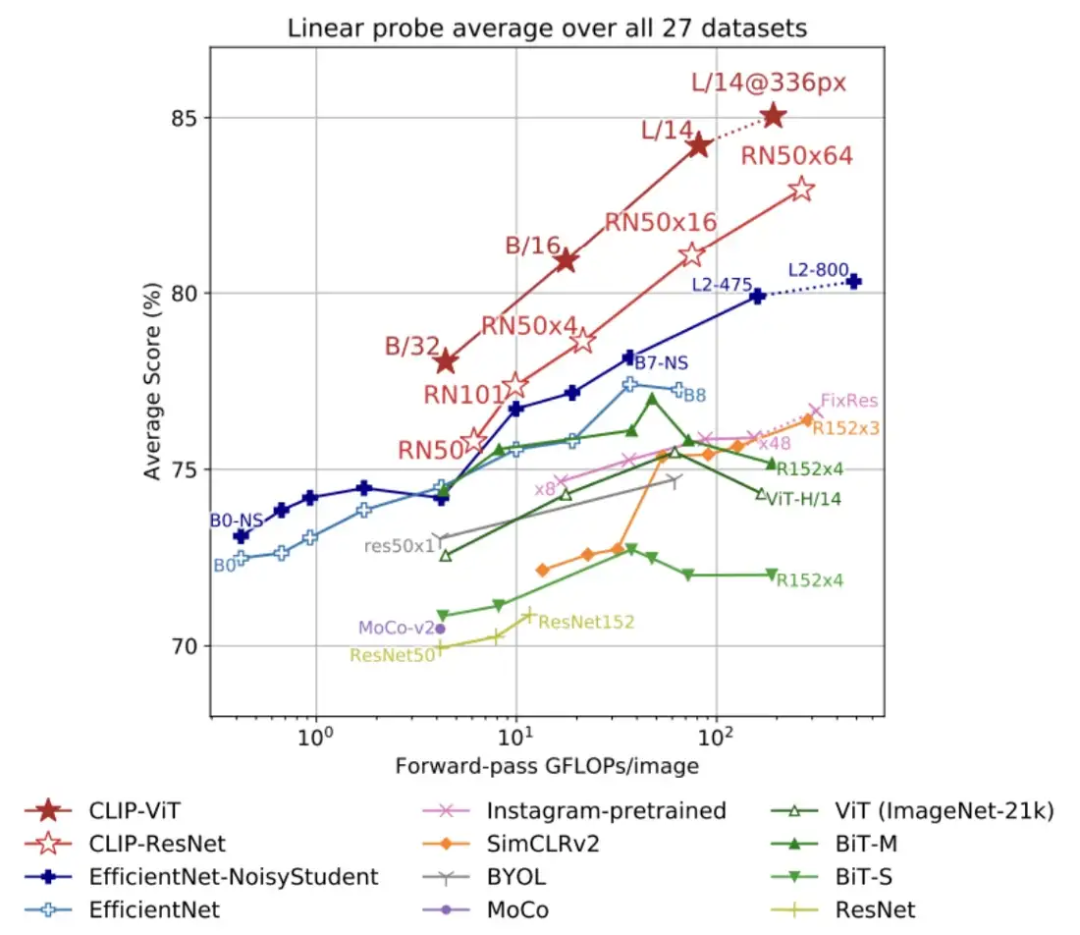
这种方法有局限性:一个类的名称可能缺乏揭示其含义的相关上下文(即 多义 问题),一些数据集可能完全缺乏元数据或类的文本描述,并且对图像进行单词描述在用于训练的图像-文本对。这些问题可以通过制作“提示”来以文本形式表示不同的类别或创建多个零样本分类器的集合来缓解;见下图。 当 (i) 提示用于生成类嵌入和 (ii) 零样本分类器的集合用于预测时,CLIP 实现了改进的性能 然 而, 这种方法仍然具有 根本 的局限性,最终必须解决这些局限性,以提高零样本学习能力。 CLIP 实践——没有训练数据的准确分类! 在原文中,CLIP 在零样本域中进行评估,并添加了微调(即少样本或完全监督域)。在这里,我将概述这些使用 CLIP 进行的实验的主要发现,并提供有关 CLIP 何时可以和不可以用于解决给定分类问题的相关详细信息。 零样本 。在零样本领域,CLIP 取得了突破性的成果,将 ImageNet 上最先进的零样本测试准确率从 11.5% 提高到 76.2%;见下文。 零样本 CLIP 精度与之前最先进技术的比较
当将 CLIP 的零样本性能与以预训练的 ResNet50 特征作为输入的完全监督线性分类器的性能进行比较时,CLIP 继续在各种数据集上取得显著成果。即,CLIP 在所研究的 27 个总数据集中的 16 个上优于线性分类器(完全监督!),尽管从未观察到单个训练示例。
CLIP 与以预训练的 ResNet50 特征作为输入的线性分类器
当分析每个数 据 集的性能时,很明显 CLIP 在一般对象分类数据集(例如 ImageNet 或 CIFAR10/100)上表现良好,甚至在动作识别数据集上表现更好。 直觉上,这些任务的良好表现是由于 CLIP 在训练期间接受的广泛监督以及图像说明通常以动词为中心的事实,因此与动作识别标签的相似性高于数据集中使用的以名词为中心的类,例如图片网。 有趣的是,CLIP 在卫星图像分类和肿瘤检测等复杂和专门的数据集上表现最差。
少样本: CLIP 的零样本和少样本性能也与其他少样本线性分类器的性能进行了比较。在观察每个类中的四个训练示例后,发现零样本 CLIP 与少样本线性分类器的平均性能相匹配。此外,当允许观察训练示例本身时,CLIP 优于所有小样本线性分类器。这些结果总结在下图中。 与少镜头线性分类器相比,CLIP 零和少镜头性能
当使用 CLIP 特征训练完全监督的线性分类器时,发现它在准确性和计算成本方面都优于许多基线,从而强调了 CLIP 通过自然语言监督学习的表示的质量; 见下 文。
尽管 CLIP 的性能并不完美(即,它在专门 的任务上表现不佳,并且仅适用于对每个类别都有良好文本描述的数据集),但 CLIP 实现的零样本和少样本结果预示了 高概率产生的可能性- 图像和文本的质量联合嵌入空间。 更多可能,但 CLIP 为此类通用分类方法提供了初步(令人印象深刻的)概念证明。 毫无疑问,CLIP 彻底改变了零样本图像分类领域。尽管先前在语言建模方面的工作表明,可以利用非结构化输出空间(例如,文本到文本语言模型,如 GPT-3 [11])来实现零样本分类目的,但 CLIP 通过 i)形成对这些结果进行了扩展一种适用于计算机视觉的方法,以及 ii)将整个训练过程建立在易于获取的图像文本描述的基础上。 CLIP 坚定地认为自然语言提供了足够的训练信号来学习高质量的感知特征。这一发现对深度学习研究的未来方向具有重大影响。特别是,图像的自然语言描述比遵循特定任务本体的图像注释(即用于分类的传统单热标签)更容易获得。因此,为 CLIP 风格的分类器标注训练数据更具可扩展性, 特别是因为许多图像-文本配对可以免费在线下载。 CLIP 的主要局限性源于以下事实: i)在分类问题中获得每个类的良好文本嵌入是困难的,并且 ii)复杂/特定任务(例如,肿瘤检测或预测图像中对象的深度)难以通过学习通用自然语言监督。尽管如此,CLIP 学习到的表示是高质量的,并且可以通过探索对预训练过程中观察到的数据的修改来提高更专业任务的性能。 import clip available_models = clip.available_models() device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load(available_models[0], device=device) [1] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning . PMLR, 2021. [2] Li, Ang, et al. “Learning visual n-grams from web data.” Proceedings of the IEEE International Conference on Computer Vision . 2017. [3] Joulin, Armand, et al. “Learning visual features from large weakly supervised data.” European Conference on Computer Vision . Springer, Cham, 2016. [4] Desai, Karan, and Justin Johnson. “Virtex: Learning visual representations from textual annotations.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 2021. [5] Sariyildiz, Mert Bulent, Julien Perez, and Diane Larlus. “Learning visual representations with caption annotations.” European Conference on Computer Vision . Springer, Cham, 2020. [6] Zhang, Yuhao, et al. “Contrastive learning of medical visual representations from paired images and text.” arXiv preprint arXiv:2010.00747 (2020). [7] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition . 2016. [8] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” International conference on machine learning . PMLR, 2019. [9] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020). [10] Sohn, Kihyuk. “Improved deep metric learning with multi-class n-pair loss objective.” Advances in neural information processing systems 29 (2016). [11] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877–1901.
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉 扩展模块中文教程 , 即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理 等二十多章内容。在「小白学视觉 公众号后台回复:Python视觉实战项目 , 即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别 等31个视觉实战项目,助力快速学校计算机视觉。 在「小白学视觉 公众号后台回复:OpenCV实战项目20讲 , 即可下载含有20 个基于OpenCV 实现20个实战项目 ,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉 、传感器、自动驾驶、 计算摄影 、检测、分割、识别、医学影像、GAN、算法竞赛 等微信群(以后会逐渐细分), 请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过 。添加成功后会根据研究方向邀请进入相关微信群。请勿 在群内发送广告 ,否则会请出群,谢谢理解~

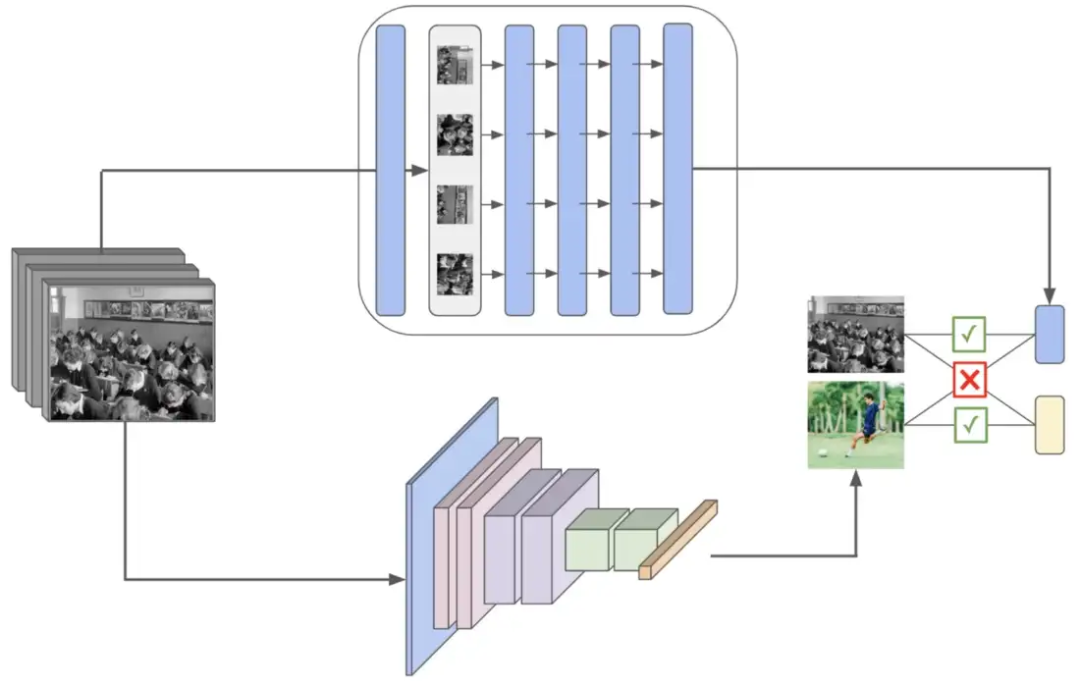
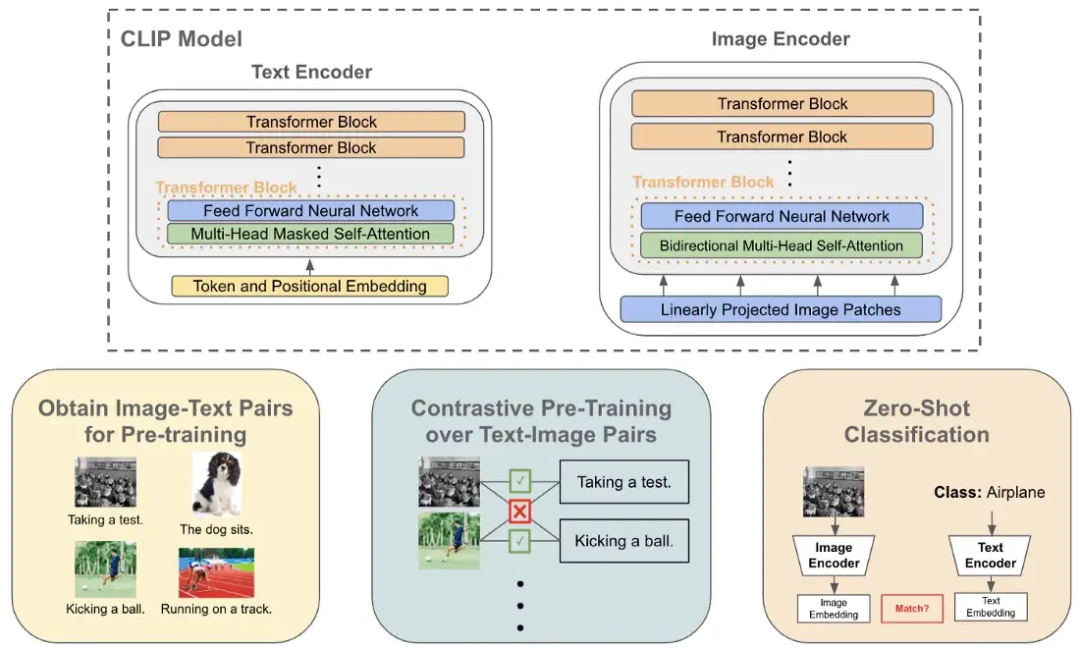
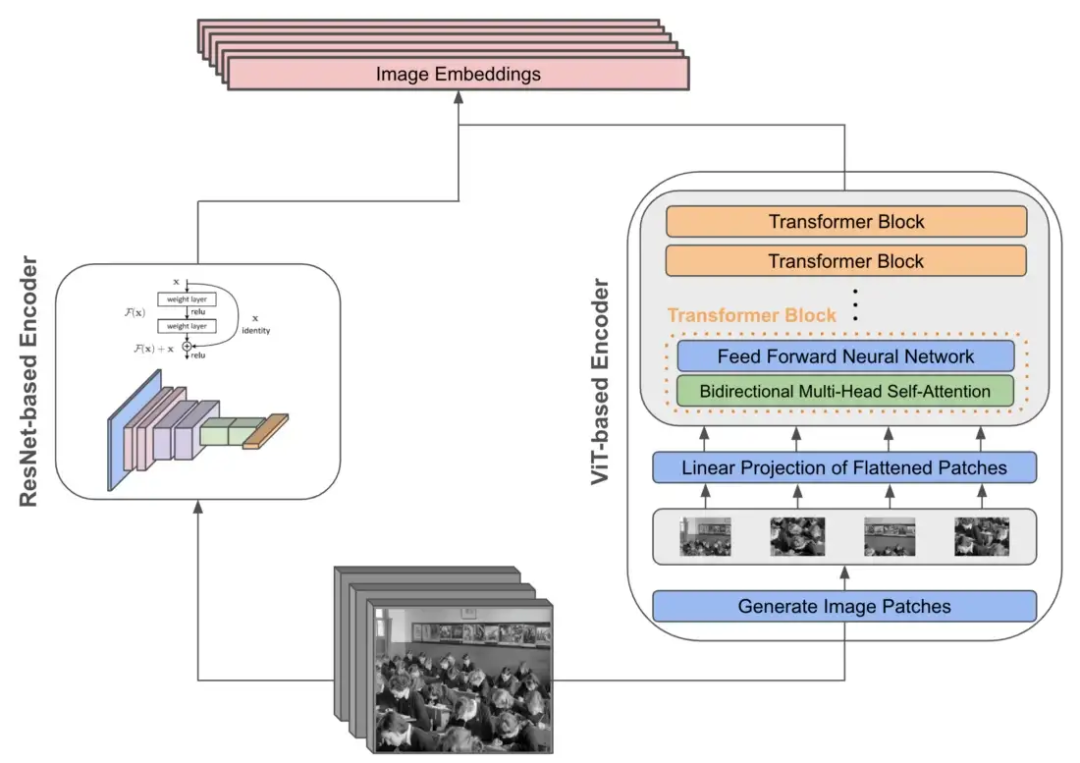 CLIP 中图像编码器架构的不同选项
CLIP 中图像编码器架构的不同选项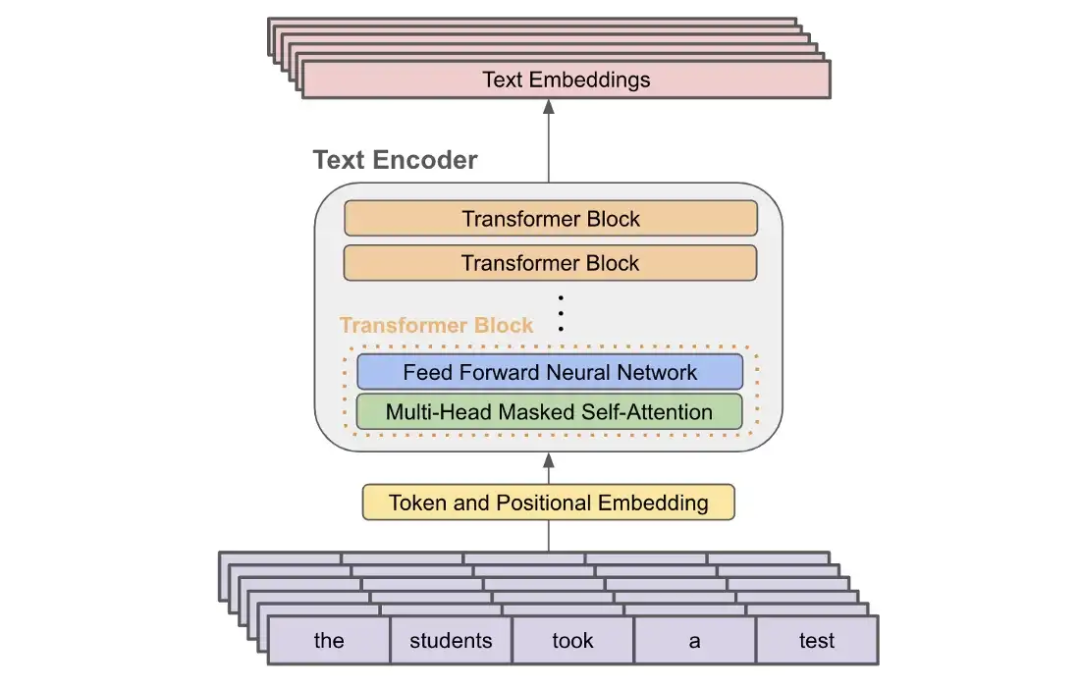 CLIP 的文本编码器架构
CLIP 的文本编码器架构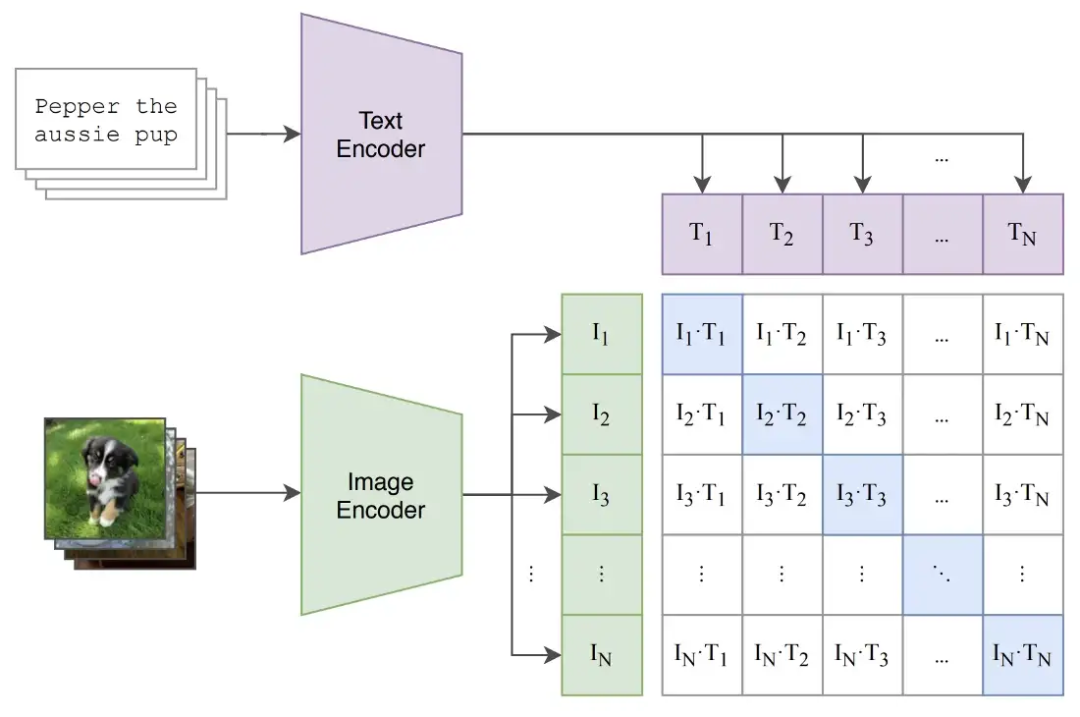 CLIP 的图文对比预训练
CLIP 的图文对比预训练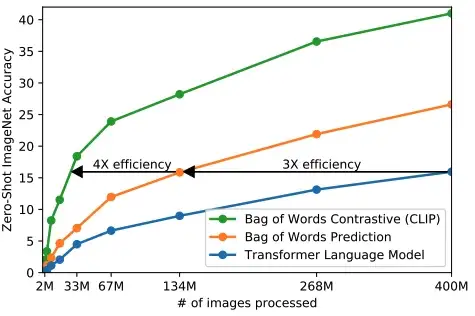
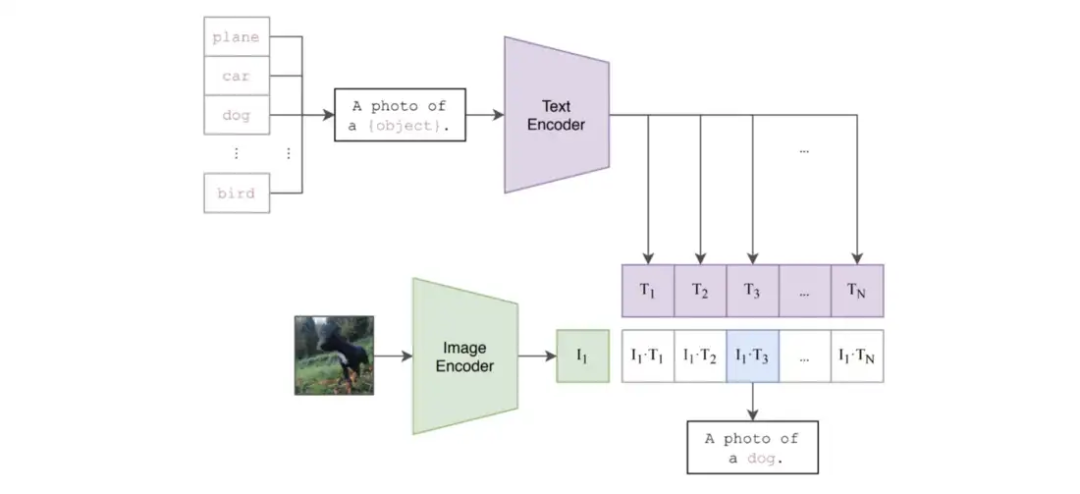 使用 CLIP 执行零样本分类
使用 CLIP 执行零样本分类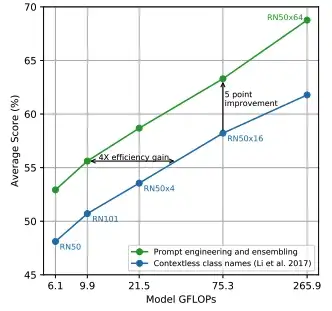
 零样本 CLIP 精度与之前最先进技术的比较
零样本 CLIP 精度与之前最先进技术的比较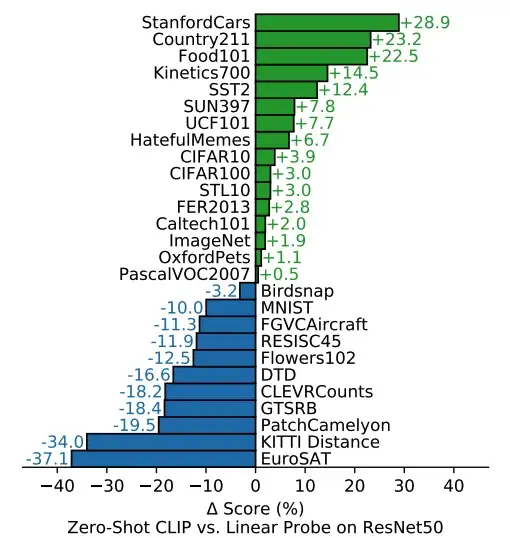
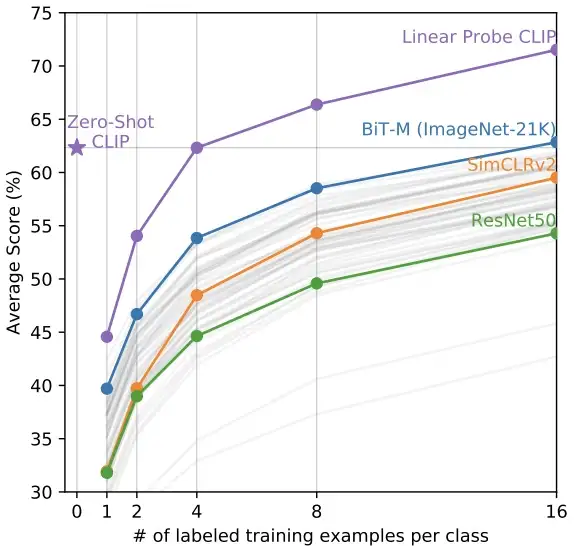 与少镜头线性分类器相比,CLIP 零和少镜头性能
与少镜头线性分类器相比,CLIP 零和少镜头性能