
【深度学习】使用 Pytorch 进行多类图像分类

此数据包含大小为150x150、分布在6个类别下的约25k图像。
{'建筑物':0,'森林':1,'冰川':2,'山':3,'海':4,'街道':5}
训练、测试和预测数据在每个 zip 文件中分开。训练中有大约 14k 图像,测试中有 3k,预测中有 7k。
这是一个多类图像分类问题,目标是将这些图像以更高的精度分类到正确的类别中。
基本理解python、pytorch和分类问题。
做一些探索性数据分析 (EDA) 来分析和可视化数据,以便更好地理解。
定义一些实用函数来执行各种任务,从而可以保持代码的模块化。
加载各种预先训练的模型并根据我们的问题对它们进行微调。
为每个模型尝试各种超参数。
保存模型的权重并记录指标。
结论
未来的工作
让我们深入研究代码!
1. 库
首先,导入所有重要的库。
import osimport torchimport tarfileimport torchvisionimport torch.nn as nnfrom PIL import Imageimport matplotlib.pyplot as pltimport torch.nn.functional as Ffrom torchvision import transformsfrom torchvision.utils import make_gridfrom torch.utils.data import random_splitfrom torchvision.transforms import ToTensorfrom torchvision.datasets import ImageFolderfrom torch.utils.data import Dataset, DataLoaderfrom torchvision.datasets.utils import download_url
2. 图片文件夹到数据集
由于我们的数据存在于文件夹中,因此让我们将它们转换为数据集。
transform_train = transforms.Compose([transforms.Resize((150,150)), #becasue vgg takes 150*150transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.ToTensor(),transforms.Normalize((.5, .5, .5), (.5, .5, .5))])#Augmentation is not done for test/validation data.transform_test = transforms.Compose([transforms.Resize((150,150)), #becasue vgg takes 150*150transforms.ToTensor(),transforms.Normalize((.5, .5, .5), (.5, .5, .5))])
train_ds = ImageFolder('../input/intel-image-classification/seg_train/seg_train', transform=transform_train)test_ds = ImageFolder('../input/intel-image-classification/seg_test/seg_test', transform=transform_test)pred_ds = ImageFolder('/kaggle/input/intel-image-classification/seg_pred/', transform=transform_test)
3. 探索性数据分析 (EDA)
作为 EDA 的一部分,让我们在这里回答一些问题,但这里并未广泛涵盖 EDA。
让我们继续回答一些问题。
a) 数据集中有多少张图片?
回答 :

这意味着有 14034 张图像用于训练,3000 张图像用于测试/验证,7301 张图像用于预测。
b) 你能告诉我图像的大小吗?
回答:

这意味着图像的大小为 150 * 150,具有三个通道,其标签为 0。
c) 你能打印一批训练图像吗?
回答:此问题的答案将在创建数据加载器后给出,因此请等待并继续下面给出的下一个标题。
4. 创建数据加载器
为将批量加载数据的所有数据集创建一个数据加载器。
batch_size=128train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(test_ds, batch_size, num_workers=4, pin_memory=True)pred_dl = DataLoadebatch_size=128train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(test_ds, batch_size, num_workers=4, pin_memory=True)pred_dl = DataLoader(pred_ds, batch_size, num_workers=4, pin_memory=True)r(pred_ds, batch_size, num_workers=4, pin_memory=True)
batch_size=128train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(test_ds, batch_size, num_workers=4, pin_memory=True)pred_dl = DataLoader(pred_ds, batch_size, num_workers=4, pin_memory=True)
5. 生成类名
虽然可以通过查看文件夹名称手动列出类名称,但作为一个好习惯,我们应该为此编写代码。

6. 创建精度函数
定义一个函数来计算我们模型的准确性。

7. 下载预训练模型
下载我们选择的任何预训练模型,可以根据需要自由选择任何模型,这里我选择了两个模型 VGG 和 ResNet50 来做实验。让我们下载模型。
8. 冻结所有图层
下载模型后,可以根据需要训练整个架构。一种可能的策略是我们可以训练预训练模型的某些层,而一些层则不能。在这里,我选择了这样一种策略,即在新输入的模型训练期间不必训练任何现有层,因此通过将模型的每个参数的 requires_grad 设置为 False 来保持所有层冻结。

9. 添加我们自己的分类器层
现在要将下载的预训练模型用作我们自己的分类器,我们必须对其进行一些更改,因为我们要预测的类数可能与模型已训练的类数不同。另一个原因是有可能(几乎在所有情况下)模型已经过训练以检测某些特定类型的事物,但我们想使用该模型检测不同的事物。
所以模型的一些变化是可以有我们自己的分类层,它会根据我们的要求进行分类。因此,我们想在预训练模型中添加什么架构完全取决于我们自己。在这里,我选择了人们遵循的最常见的策略,即用我们自己的分类层替换模型的最后一层。
另一个策略是我们可以从最后一个图层删除一些层,例如我们删除了最后三层并添加了我们自己的分类层,为了更好地理解,请参见下文。
预训练的VGG 模型:
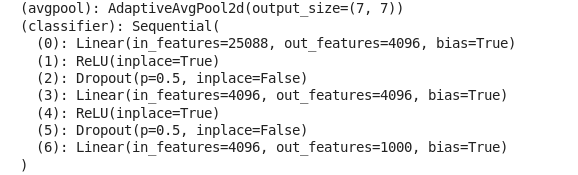
上图中显示了 VGG 模型的最后两层(avgpool 和 classsifer)。我们可以看到这个预训练模型是为对1000个类进行分类而设计的,但是我们只需要 6 类分类,所以稍微改变一下这个模型。
替换最后一层后的新模型:

我已经用我自己的分类器层替换了分类器层,因为我们可以看到有 6 个 out_features,这意味着 6 个输出,但在预训练模型中还有一些其他的数字,因为模型经过训练,可以对这些数量的类进行分类。
小伙伴们可能会问为什么分类器层内部的一些 in-features 和 out_features 发生了变化?
所以让我们回答这个。我们可以为这些选择任何数字,但请记住,第一个线性层内的 in_features 必须相同,即 25088,因为它是不得更改的输出层数。
与 ResNet50 相同:
预训练模型(最后两层)


请注意,第一个线性层 层中的 in_features 与 2048 相同,而最后一个 线性层层中的 out_features 为 6。除了上面提到的,其他任何 in_features 和 out_features 都可以根据我们的选择进行更改。
10.创建基类
创建一个基类,其中将包含将来要使用的所有有用函数,这样做只是为了确保 DRY的概念,因为这两个模型都需要该类中的函数,如果不在这里实现,我们必须分别为每个模型定义这些函数,这将违反DRY概念。
class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))
11.继承基类
通过继承基类为每个模型创建一个类,该类具有任何模型训练期间所需的所有有用函数。
12.创建继承类的对象
实例化该类

13. 检查设备
创建一个函数来检查当前存在哪个设备。如果存在 GPU,则选择它,否则选择 CPU 作为工作设备。

在这里,我使用 GPU,因此它将设备类型显示为 CUDA。
14. 移动到设备
创建一个可以将张量和模型移动到特定设备的函数。
15. 设备数据加载器
创建DeviceDataLoader类,该类包装DataLoader以将数据移动到特定设备,然后可以从该设备生成一批数据。


在这里我们可以看到张量和两个模型都已发送到当前存在的适当设备。
16.评估和拟合函数
让我们定义一个评估函数,用于评估模型在不可见数据上的性能,并定义一个拟合函数,该函数可用于模型的训练。
class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))
17. 训练(第一阶段)
让我们训练我们的模型,即 VGG 。
num_epochs = 10opt_func = torch.optim.Adamlr = 0.00001history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func)Epoch [0], train_loss: 0.8719, val_loss: 0.3769, val_acc: 0.8793Epoch [1], train_loss: 0.4265, val_loss: 0.3104, val_acc: 0.8942Epoch [2], train_loss: 0.3682, val_loss: 0.2884, val_acc: 0.9016Epoch [3], train_loss: 0.3354, val_loss: 0.2819, val_acc: 0.8988Epoch [4], train_loss: 0.3205, val_loss: 0.2704, val_acc: 0.9033Epoch [5], train_loss: 0.2977, val_loss: 0.2722, val_acc: 0.9021Epoch [6], train_loss: 0.2853, val_loss: 0.2629, val_acc: 0.9068Epoch [7], train_loss: 0.2784, val_loss: 0.2625, val_acc: 0.9045Epoch [8], train_loss: 0.2697, val_loss: 0.2623, val_acc: 0.9033Epoch [9], train_loss: 0.2530, val_loss: 0.2629, val_acc: 0.9018
18. 训练(第二阶段)
让我们训练更多的历元并评估该模型。
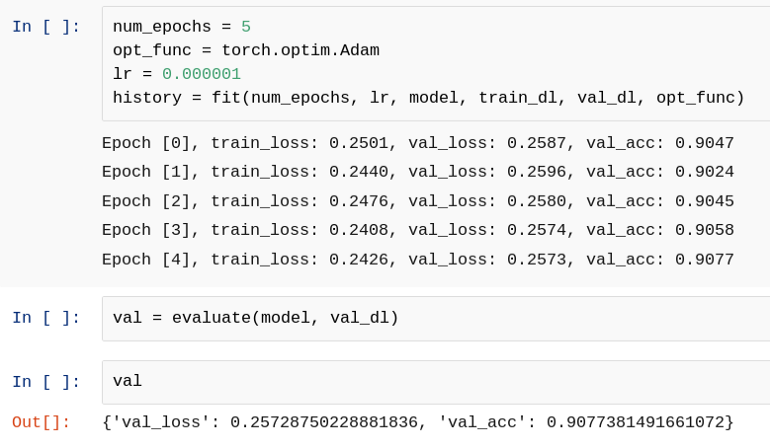
19. 训练(第 3 阶段)
让我们训练我们的模型 2 ,即 ResNet50 。
num_epochs = 10opt_func = torch.optim.Adamlr = 0.00001history = fit(num_epochs, lr, model2, train_dl, val_dl, opt_func)Epoch [0], train_loss: 1.6437, val_loss: 1.4135, val_acc: 0.7686Epoch [1], train_loss: 1.2088, val_loss: 0.9185, val_acc: 0.8582Epoch [2], train_loss: 0.8531, val_loss: 0.6467, val_acc: 0.8594Epoch [3], train_loss: 0.6709, val_loss: 0.5129, val_acc: 0.8640Epoch [4], train_loss: 0.5773, val_loss: 0.4416, val_acc: 0.8693Epoch [5], train_loss: 0.5215, val_loss: 0.4002, val_acc: 0.8739Epoch [6], train_loss: 0.4796, val_loss: 0.3725, val_acc: 0.8767Epoch [7], train_loss: 0.4582, val_loss: 0.3559, val_acc: 0.8795Epoch [8], train_loss: 0.4391, val_loss: 0.3430, val_acc: 0.8819Epoch [9], train_loss: 0.4262, val_loss: 0.3299, val_acc: 0.8823
num_epochs = 5opt_func = torch.optim.Adamlr = 0.0001history = fit(num_epochs, lr, model2, train_dl, val_dl, opt_func)Epoch [0], train_loss: 0.4183, val_loss: 0.3225, val_acc: 0.8753Epoch [1], train_loss: 0.3696, val_loss: 0.2960, val_acc: 0.8855Epoch [2], train_loss: 0.3533, val_loss: 0.2977, val_acc: 0.8814Epoch [3], train_loss: 0.3382, val_loss: 0.2970, val_acc: 0.8891Epoch [4], train_loss: 0.3289, val_loss: 0.2849, val_acc: 0.8933
20. 训练(第 4 阶段)
让我们训练更多的历元并评估该模型。
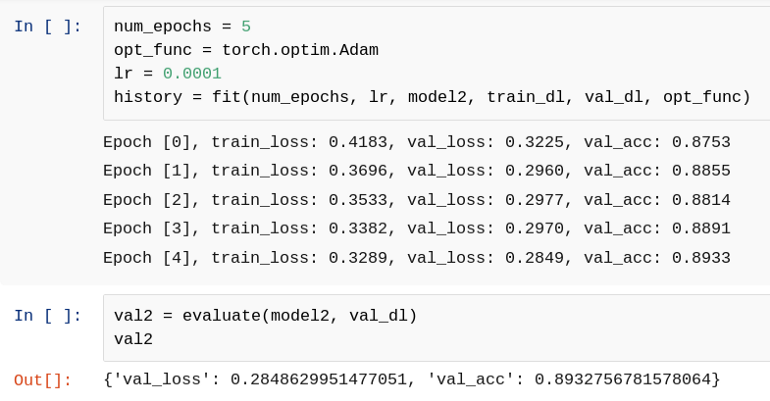
21. 预测单个图像
定义一个函数,该函数可由模型用于预测单个图像。
def predict_single(input,label, model):input = to_device(input,device)inputs = input.unsqueeze(0) # unsqueeze the input i.e. add an additonal dimensionpredictions = model(inputs)prediction = predictions[0].detach().cpu()print(f"Prediction is {np.argmax(prediction)} of Model whereas given label is {label}")
22.预测
让我们预测一下

可以看出,目前 VGG 给出了错误的预测,尽管它具有良好的验证精度 (val_acc),而 ResNet 给出了正确的预测,但我们不能说它会在每张图像上预测正确。
因此,让我们针对更多的历元训练这两个模型,以便将误差最小化,即 val_loss 可以尽可能地减少,并且两个模型都可以更准确地执行。
现在,轮到小伙伴们预测整个 pred 文件夹/数据集了。
提示:使用 pred_dl 作为数据加载器批量加载 pred 数据进行预测。练习它,并尝试使用集成预测的概念来获得更正确的预测数量。
23.保存模型
在很好地训练模型后,让我们保存它,以便我们可以将其用作下一个标题中给出的未来工作。

24. 未来工作
使用我们保存的模型集成两个模型的预测,进行最终预测并将此项目转换为flask/stream-lit网络应用程序。
往期精彩回顾 本站qq群851320808,加入微信群请扫码: