
使用Python+opencv进行图像处理
二条:9 个实用的 Shell 拿来就用脚本实例!! 三条:100 道 Linux 常见面试题!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包

图片处理库准备
OpenCV Python 来处理图片,安装过程如下:
pip install opencv-python
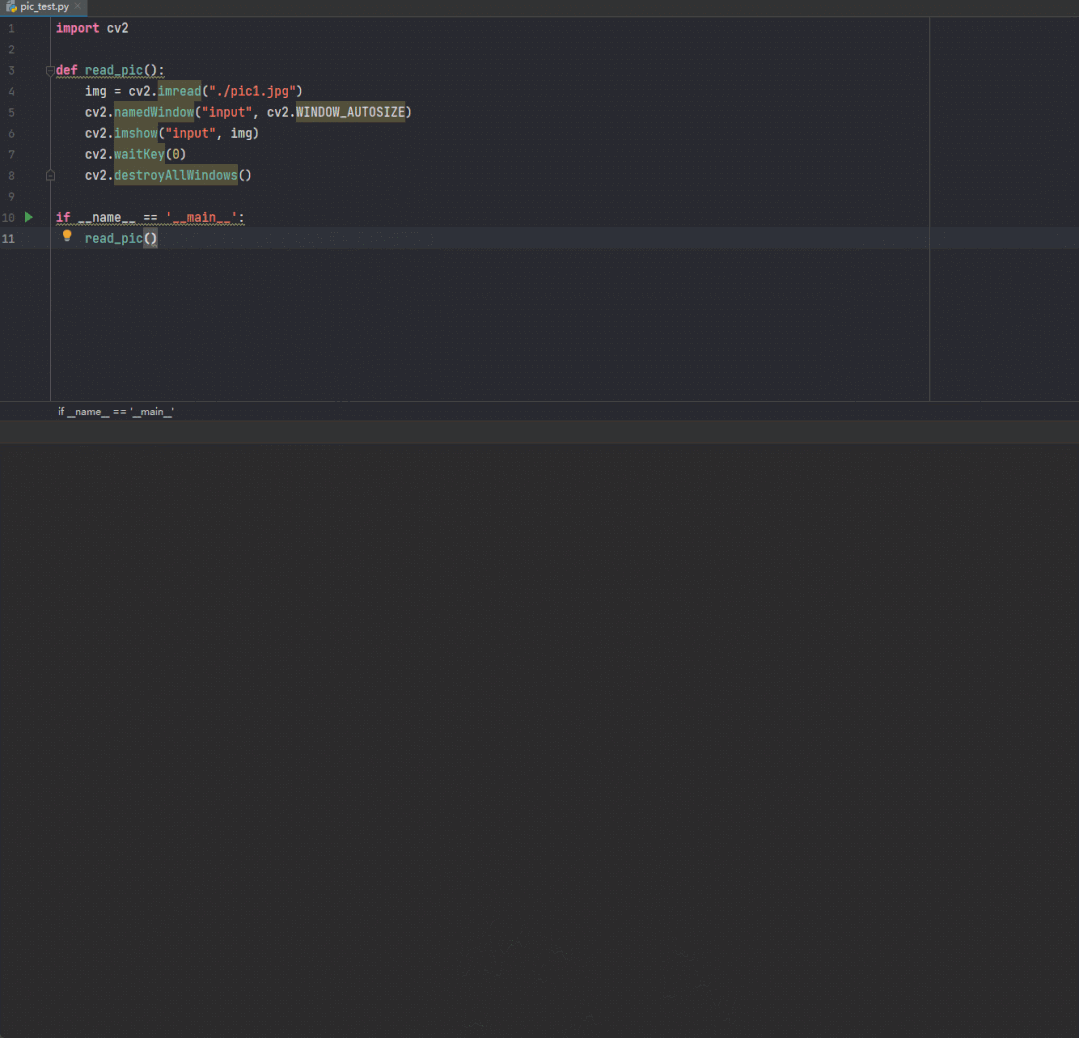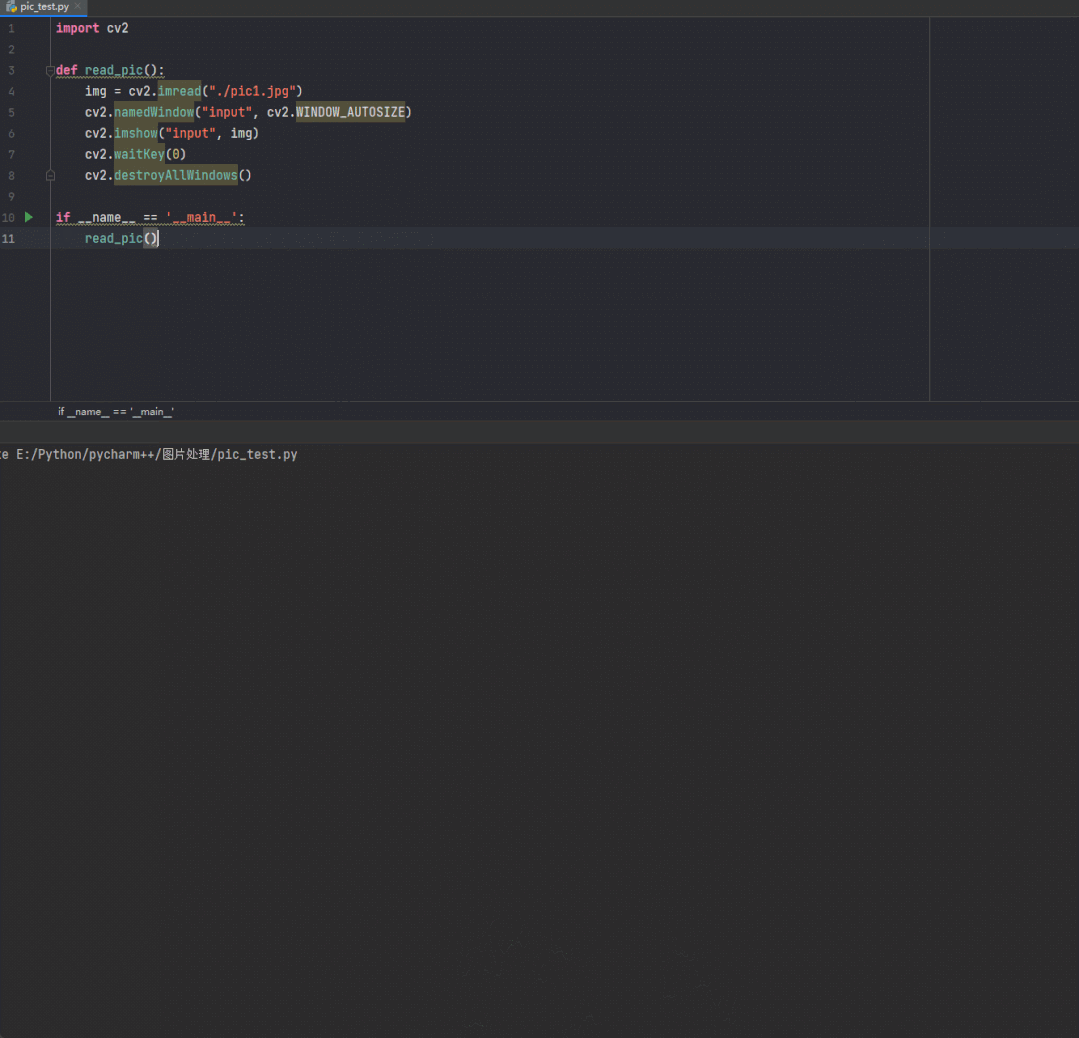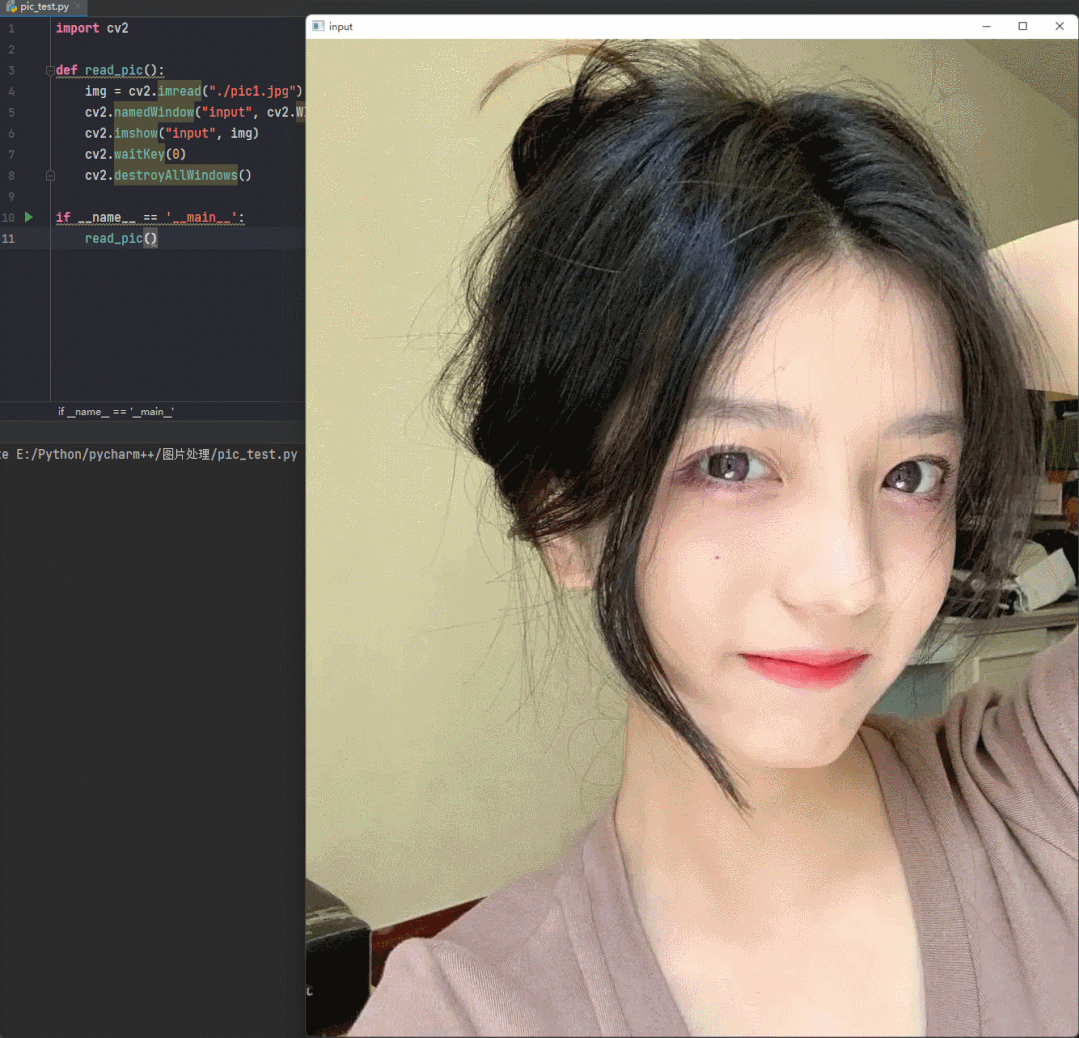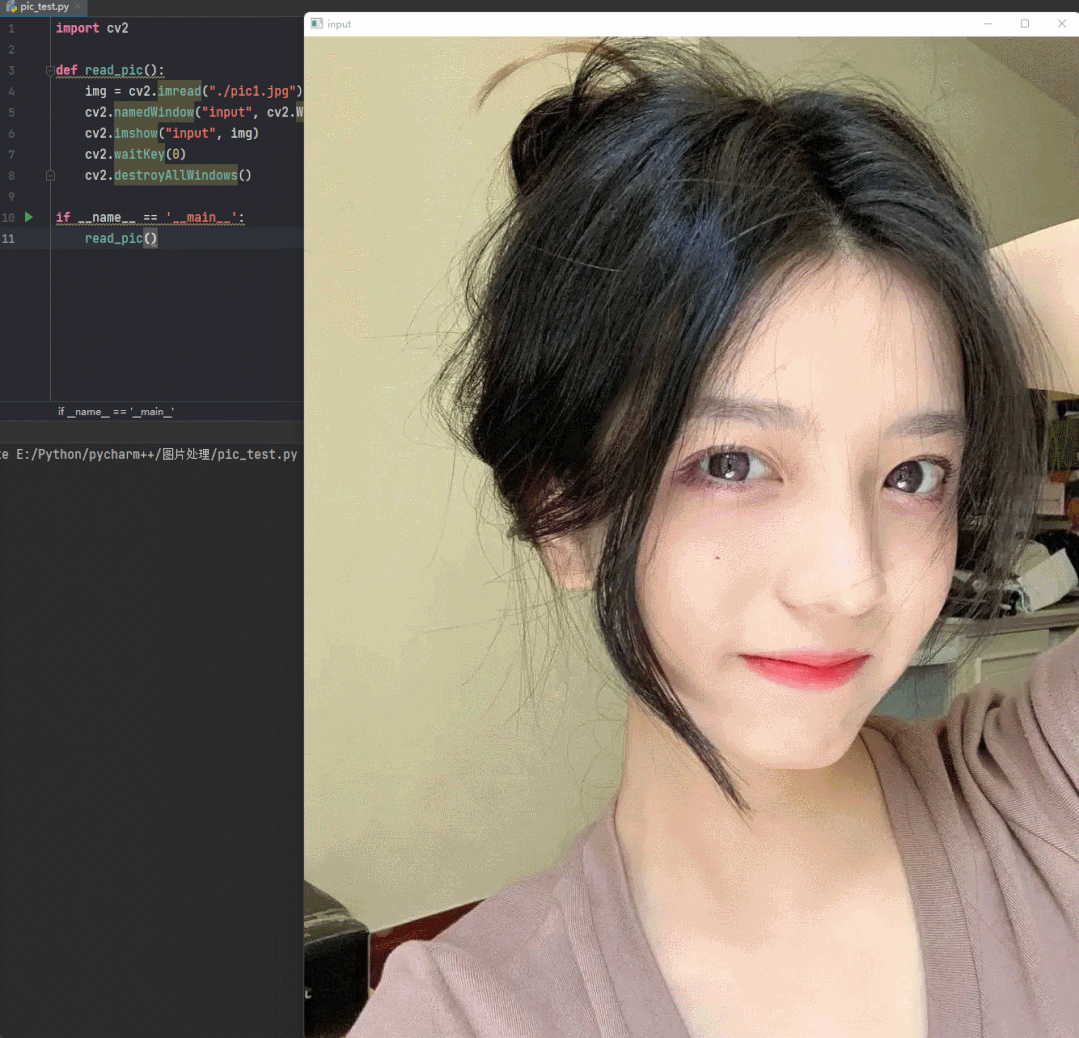
在保持图片细节不变的前提下,把图片放大或者缩小。
其中img 是图片对象,img.shape 表示图片的形状大小,分别是高、宽、通道数。
# 获取图片尺寸
img = cv2.imread("./pic1.jpg")
h, w, ch = img.shape
print(h, w, ch)
'''
1240 960 3
'''# 获取图片尺寸
img = cv2.imread("./pic1.jpg")
h, w, ch = img.shape
print('原图尺寸:', h, w, ch)
new_h = int(h / 2)
new_w = int(w / 2)
res = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_LINEAR)
cv2.imwrite('./half_pic1.jpg', res)
# 获取图片尺寸
img = cv2.imread("./half_pic1.jpg")
h, w, ch = img.shape
print('缩半原图尺寸:', h, w, ch)
'''
原图尺寸:1240 960 3
缩半原图尺寸:620 480 3
'''

图片裁剪
把图片的局部形状截取出来,这里我们截取小姐姐图像,按照自己需求去掉前后左右多余边框。
img = cv2.imread("./pic1.jpg")
h, w, ch = img.shape
print(h, w, ch)
# (x0,y0) (x1,y1) 矩阵
x0, y0 = 200, 80
x1, y1 = 880, 960
# img 是一个按行扫描的矩阵
res = img[y0:y1, x0:x1]
print('截取后 H,W=', res.shape[:2])
cv2.imwrite('./pic.jpg', res)
'''
1240 960 3
截取后 H,W= (880, 680)
'''实际效果如下:

图像组合
把两个或者多个图像进行堆叠、拼接。
准备一个原图 pic1.jpg,再准备一个水印图 img.png,目标是把水印贴在人像图的最右下方。
# 读取原始图片
image = cv2.imread('./pic1.jpg')
(h, w) = image.shape[:2]
print("SOURCE", image.shape)
# 读取水印
imgsy = cv2.imread('./img.png')
(h_sy, w_sy) = imgsy.shape[:2]
print("SHUIYIN", imgsy.shape)
# 定义原图片选区
roi = image[h - h_sy:h, w - w_sy:w]
# 原图片选区和水印区融合,让水印透明
for y in range(h_sy):
for x in range(w_sy):
p = imgsy[y, x]
if (p[0], p[1], p[2]) == (0, 0, 0):
imgsy[y, x] = roi[y, x]
cv2.imwrite('./shuiyin+roi.png', imgsy)
# 选区范围设定为融合后的水印
image[h - h_sy: h, w - w_sy: w] = imgsy
cv2.imwrite('./pic_sy.jpg', image)



评论