
简单涨点 | Flow-Mixup: 对含有损坏标签的多标签医学图像进行分类(优于Mixup和Maniflod Mixup)
点击上方【AI人工智能初学者】,选择【星标】公众号
期待您我的相遇与进步

本文提出一种用于多标签医学图像分类的新正则化方法:FlowMixup,涨点明显!性能优于Mixup、ERM等方法。
作者单位:浙江大学, 圣母大学
1 、简介
在临床实践中,医学图像解释通常涉及多标签分类,因为患者的犯病的地方往往会出现多种症状或并发症。最近,在医学图像解释上基于深度学习的框架已达到专家级的性能,这其中部分功劳可以归功于大量准确的注释或者说标注。但是,手动注释大量医学图像是不切实际的,而自动注释快速但不精确(可能引入损坏的标签)。
在这项工作中,作者提出了一种新的正则化方法,称为Flow-Mixup,用于带有损坏标签的多标签医学图像分类。Flow-Mixup指导模型捕获每种异常的鲁棒特征,从而帮助有效处理损坏的标签,并可以应用自动注释。
具体地说,Flow-Mixup通过向模型的隐藏状态添加约束来解耦提取的特征。而且,与其他已知的正则化方法相比,Flow-Mixup更稳定,更有效,理论和经验分析所示。对两个心电图数据集和包含损坏标签的胸部X射线数据集进行的实验验证了Flow-Mixup是有效的,并且对损坏的标签不敏感。
这项工作的3个主要贡献:
1、提出了一种用于多标签医学图像分类的正则化方法Flow-Mixup,并证明了Flow-Mixup对已损坏标签的鲁棒性;
2、对Mixup、Manifold-Mixup以及Flow-Mixup进行了比较,表明使用Mixup、Manifold-Mixup会产生“correlation conflicts”现象和“distribution shift”现象。
3、在几个带有损坏标签的多标签医学图像分类数据集上进行了实验,验证了Flow-Mixup优于已知的正则化方法。
2 相关正则化方法
2.1 Mixup
Mixup介绍
Mixup是一种运用在计算机视觉中的对图像进行混类增强的算法,它可以将不同类之间的图像进行混合,从而扩充训练数据集。
Mixup原理
假设
是一个
样本,
是该
样本对应的标签;
是另一个
样本,
是该
样本对应的标签,
是由参数为
,
的贝塔分布计算出来的混合系数,由此可以得到Mixup原理公式为:
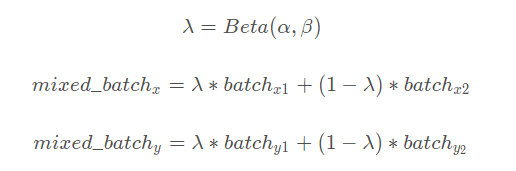
其中
指的是贝塔分布,
是混合后的
样本,
是混合后的
样本对应的标签。
需要说明几点:
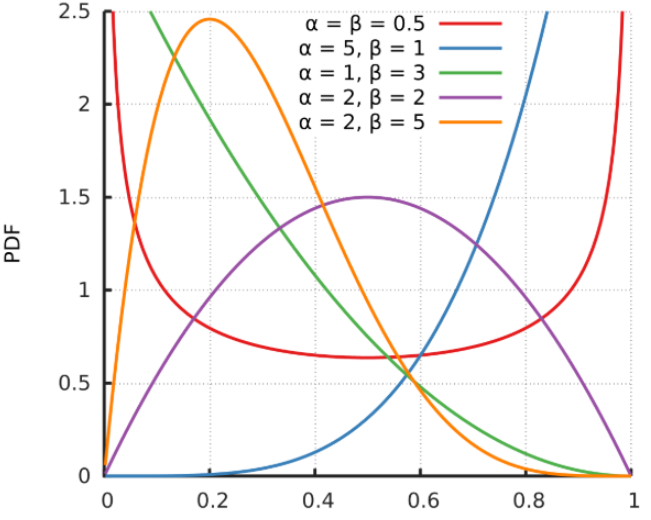
1.在论文作者多组实验中,无论如何设置
,
的值,期望
始终近似为0.5。这可能是由于权重
在每个batch样本都会随机产生,在整个训练过程中会有N个batch,权重在N个batch中期望近似为0.5。所以作者认为产生
与
样本混合权重
的Beta分布参数
时,算法效果相对较好。Beta分布如下图:
2.
与
没有太多的限制,当
=1时,就是两张图片样本混合;当
>1时,便是2个
图片样本两两对应混合。此外,
与
可以是同一批样本,也可以是不同批样本。一般在代码实现过程中,两个
图片是同一批样本,唯一不同的是,
是原始
图片样本,而
是对
在
维度进行shuffle后得到的。
Mixup代码实现
mixup代码实现部分如下:
import numpy as np
import torch
import torch.nn as nn
from loss.focal import FocalLoss
LOSS=FocalLoss()
def criterion(batch_x, batch_y, alpha=1.0, use_cuda=True):
'''
batch_x:批样本数,shape=[batch_size,channels,width,height]
batch_y:批样本标签,shape=[batch_size]
alpha:生成lam的beta分布参数,一般取0.5效果较好
use_cuda:是否使用cuda
returns:
mixed inputs, pairs of targets, and lam
'''
if alpha > 0:
#alpha=0.5使得lam有较大概率取0或1附近
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = batch_x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size) #生成打乱的batch_size索引
#获得混合的mixed_batchx数据,可以是同类(同张图片)混合,也可以是异类(不同图片)混合
mixed_batchx = lam * batch_x + (1 - lam) * batch_x[index, :]
"""
Example:
假设batch_x.shape=[2,3,112,112],batch_size=2时,
如果index=[0,1]的话,则可看成mixed_batchx=lam*[[0,1],3,112,112]+(1-lam)*[[0,1],3,112,112]=[[0,1],3,112,112],即为同类混合
如果index=[1,0]的话,则可看成mixed_batchx=lam*[[0,1],3,112,112]+(1-lam)*[[1,0],3,112,112]=[batch_size,3,112,112],即为异类混合
"""
batch_ya, batch_yb = batch_y, batch_y[index]
return mixed_batchx, batch_ya, batch_yb, lam
def mixup_criterion(criterion, inputs, batch_ya, batch_yb, lam):
return lam * criterion(inputs, batch_ya) + (1 - lam) * criterion(inputs, batch_yb)
##########################################################################
#####################修改位置3:train.py文件修改代码如下######################
if torch.cuda.is_available() and DEVICE.type=="cuda": #add
inputs, targets = inputs.cuda(), targets.cuda()
else:
inputs = inputs.to(DEVICE)
targets = targets.to(DEVICE).long()
if cfg['USE_MIXUP']:
inputs, targets_a, targets_b, lam = mixup.mixup_data(
inputs,targets,cfg["MIXUP_ALPHA"], torch.cuda.is_available())
#映射为Variable
inputs, targets_a, targets_b = map(Variable, (inputs,targets_a,targets_b))
#抽取特征,BACKBONE为粗特征抽取网络
features = BACKBONE(inputs)
#抽取特征,HEAD为精细的特征抽取网络
outputs = mixup.mixup_criterion(HEAD, features, targets_a, targets_b, lam)
loss = mixup.mixup_criterion(LOSS, outputs, targets_a, targets_b, lam)
else:
features = BACKBONE(inputs)
outputs = HEAD(features, targets)
loss = FocalLoss(outputs, labels)
2.2 Manifold Mixup
基于Mixup,后续涌现出一些很棒的工作。Manifold mixup通过对Hidden States进行插值,取得了优于Mixup的效果。
Maniflod Mixup的具体流程如下:
1、随机选网络的某一层第k层(包括输入层);
2、传2个Batch的数据给网络,前向传播到第k层,得到隐藏表征hidden reprense
和
;
3、使用Mixup:
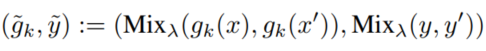
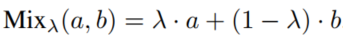
4、继续前向传播直至得到输出;
5、计算损失和梯度:
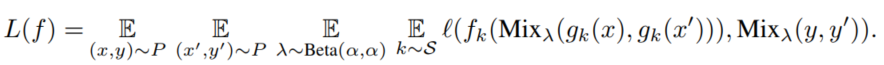
def mixup_process(out, target_reweighted, lam):
indices = np.random.permutation(out.size(0))
out = out*lam + out[indices]*(1-lam)
target_shuffled_onehot = target_reweighted[indices]
target_reweighted = target_reweighted * lam + target_shuffled_onehot * (1 - lam)
#t1 = target.data.cpu().numpy()
#t2 = target[indices].data.cpu().numpy()
#print (np.sum(t1==t2))
return out, target_reweighted
class PreActResNet(nn.Module):
def __init__(self, block, num_blocks, initial_channels, num_classes, per_img_std= False, stride=1):
super(PreActResNet, self).__init__()
self.in_planes = initial_channels
self.num_classes = num_classes
self.per_img_std = per_img_std
#import pdb; pdb.set_trace()
self.conv1 = nn.Conv2d(3, initial_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.layer1 = self._make_layer(block, initial_channels, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, initial_channels*2, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, initial_channels*4, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, initial_channels*8, num_blocks[3], stride=2)
self.linear = nn.Linear(initial_channels*8*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def compute_h1(self,x):
out = x
out = self.conv1(out)
out = self.layer1(out)
return out
def compute_h2(self,x):
out = x
out = self.conv1(out)
out = self.layer1(out)
out = self.layer2(out)
return out
def forward(self, x, target= None, mixup=False, mixup_hidden=False, mixup_alpha=None):
#import pdb; pdb.set_trace()
if self.per_img_std:
x = per_image_standardization(x)
if mixup_hidden:
layer_mix = random.randint(0,2)
elif mixup:
layer_mix = 0
else:
layer_mix = None
out = x
if mixup_alpha is not None:
lam = get_lambda(mixup_alpha)
lam = torch.from_numpy(np.array([lam]).astype('float32')).cuda()
lam = Variable(lam)
if target is not None :
target_reweighted = to_one_hot(target,self.num_classes)
if layer_mix == 0:
out, target_reweighted = mixup_process(out, target_reweighted, lam=lam)
out = self.conv1(out)
out = self.layer1(out)
if layer_mix == 1:
out, target_reweighted = mixup_process(out, target_reweighted, lam=lam)
out = self.layer2(out)
if layer_mix == 2:
out, target_reweighted = mixup_process(out, target_reweighted, lam=lam)
out = self.layer3(out)
if layer_mix == 3:
out, target_reweighted = mixup_process(out, target_reweighted, lam=lam)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
if target is not None:
return out, target_reweighted
else:
return out
然而,由于“correlation conflicts”现象和“distribution shift”现象,这两种方法由于混淆忽略了异常之间的特征相关性,因此都不太适合多标签分类,而Manifold Mixup在训练中往往是不稳定的。因此本文提出了一种用于多标签医学图像分类的Flow-Mixup方法,避免了Mixup和Manifold Mixup的缺点。
3 Flow-Mixup
3.1 Flow-Mixup概述
在本文中提出了一种新的正则化方法Flow-Mixup,用于多标签医学图像的分类。考虑到深度学习分类器
,其中
是一个非线性函数,
是一个线性函数。采用Flow-Mixup的正向训练过程有以下几个步骤:
首先,在训练前选择隐藏状态s将模型分为非线性部分和线性部分
、
,
为模型输出。
其次,将数据(例如图像)转发到选定的隐藏状态,并将一个新的混合模块应用到隐藏状态的特征(混合模块如下图所示)。
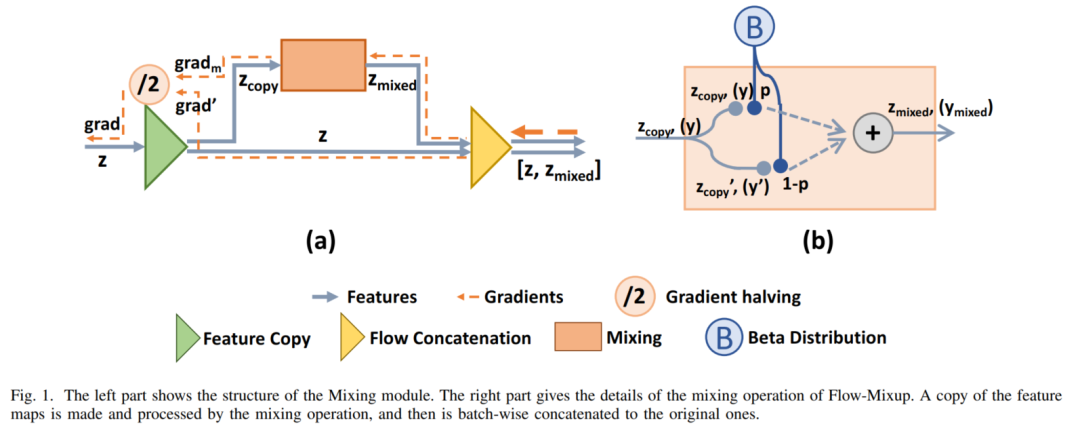
最后,经过Mixing module的处理后,该特征继续进行前向传播,直到输出。在Mixing module中,Flow-Mixup将模型的前端部分限制为学习非线性函数,其余部分为线性函数。
在处理多标签医学图像时,非线性函数提取异常特征时,模型的线性函数会将异常特征投影到标签空间。当非线性部分的输出被输入到线性部分时,非线性部分的约束被保持,而线性部分要求其输入位于线性可分空间。不同于Mixup,特殊的Mixing module引入了额外的Flow维度,从而允许在一个模型中同时使用几个Mixing module。
3.2 Mixing Module
在深度学习模型中,图像的张量一般有4个维度:batch维度、channel维度、width和height维度。本文提出的Flow-Mixup引入了一个新的维数,称为Flow维数。如图1左图所示,假设原特征z在经过Mixing Module处理前的Flow维数为1,则Mixing Module的输出
的Flow维数为2。Flow大小通过特征连接操作增加。在特征馈送到Mixing Module后,第1步是复制这些特征。然后,对特征拷贝进行Mixing处理,然后沿着Flow维串接成原始特征。Mixing Module的正向过程定义为:
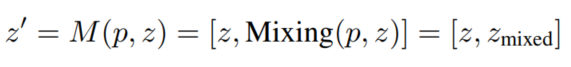
其中,Mixing操作
将一个特征副本
变换为2个小副本
,并对其采用标准Mixing,如图1右侧所示:
和
是通过对
进行随机索引Shuffle得到的。p从beta分布pB(α,α)中随机抽样,
是控制Mixing度的超参数。
表示流向级联,导致Flow size增大。根据式(2),将特征z转换为具有双流量大小的
。由于在前向传播过程中Flow大小增加了1倍,Mixing Module在后向传播过程中应将梯度减半,以保持梯度的大小。混合模的反向传播定义为:
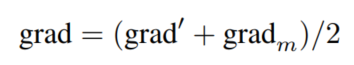
其中
表示原始特征的梯度,
表示混合特征的梯度(如图1所示)。这样,Mixing Module可以同时应用于几种隐藏状态,同时保留原始特征,如图2(b)所示。
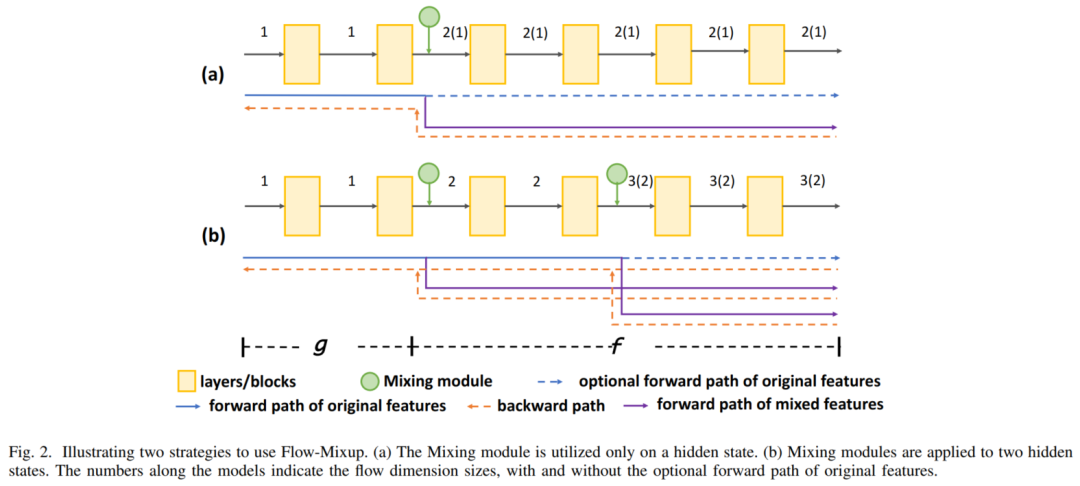
注意,正则化方法不能完全限制后续层为线性函数,因此应用几个Mixing Module有助于加强线性约束。在实现中,如果隐藏状态是最后一种状态(图2(b))或只有一种状态(图2(a))应用Mixing Module,则可选择计算原始特征向输出层的前向传播。如果原始特性没有前向传播,Mixing Module则退化为普通的Mixup操作:
在正向传播计算
和在反向传播
。
4. 方法对比
4.1 与Mixup对比
正如在以前的工作中所讨论的,异常的特征可以是相关的,可能不是线性可分的。换句话说,异常的内在相关性可能与Mixup的线性约束相冲突。因此,用Mixup正则化训练多标签图像分类器可能会导致性能下降。
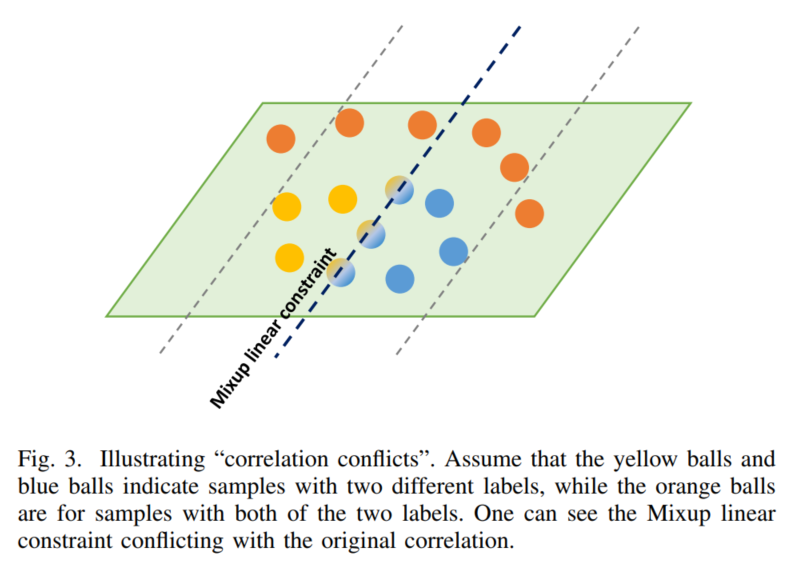
如图3所示,在将数据流形映射到满足Mixup线性约束的低维空间后,由于2类的边界不能处理这2类的数据,就会发生“Correlation conflicts”现象。与此相反,在Flow-Mixup中,异常的相关特征可以首先被非线性函数解耦为异常特有的特征,这些特征存在于线性可分空间中。
4.2 与Maniflod Mixup对比
Maniflod Mixup允许在训练过程中应用Mixup操作几个隐藏的状态。然而,这种Mixup操作不能同时进行。Maniflod Mixup在每次训练迭代中随机选择其中一种隐藏状态进行Mixing操作,因此存在以下2个缺点:
1、每次迭代的参数更新都会影响最终的参数。因此,很难确切地知道数据混合应用到一个隐藏状态的程度,由于Mixing操作是用概率来融合的。因此,也很难确定Mixing操作的超参数。
2、由于训练条件到隐藏状态(是否使用混合操作)是多变的,因此训练过程是不稳定的,存在“Distribution shift”现象。
“Distribution shift”是指客观特征分布发生变化。理想情况下,在隐藏状态上使用Mixing操作将限制特征存在于线性可分空间。然而,Maniflod Mixup不断将约束改变为隐藏状态,导致训练过程不稳定,性能下降。
为了观察模型训练中出现的“Distribution shift”现象,作者比较CIFAR-10训练集上的特征分布,如图所示:
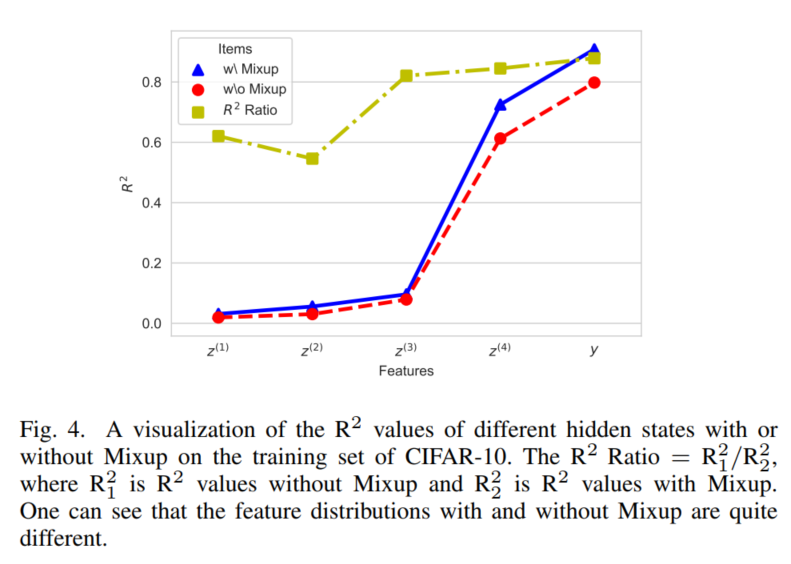
在CIFAR-10的训练集上使用Mixing和不Mixing训练PreAct-ResNet-32模型。然后收集每个残差块的输出和模型输出。为了避免对分类结果的影响,对每个块输出和模型输出的收集特征使用k-means聚类算法(划分为k=10个类)。然后计算
的平均值(类似于方差分析中的
)来观察特征分布。
,其中SSI为簇内平方和,SST为总平方和。
表示来自群间方差的总方差的百分比。
越高,簇的边界越清晰。定义如下:
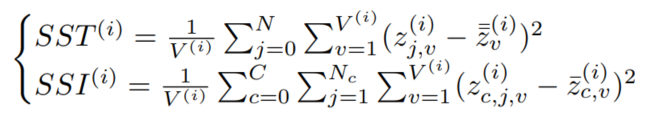
其中C为簇个数,N为图像个数,
为属于第C个簇的图像个数。
是第j幅图像在第
隐藏状态下的特征。
表示一个数据在第i个隐藏状态下的特征尺寸,即
,其中D、H、W分别为通道、高和宽。
和
分别表示第
个隐藏状态下的数据平均特征和第
个簇在第
个隐藏状态下的数据平均特征。
从图4可以看出,使用Mixup学习到的特征的
明显高于没有进行任何Mixing操作的特征。因此,在使用Manifold Mixup时,由于Mixing和不Mixing的客观特征分布有很大的不同,因此会产生“Distribution shift”现象。
5 实验
作者在ChestX-ray14数据集和阿里巴巴天池云大赛的2个心电图记录数据集上进行实验。
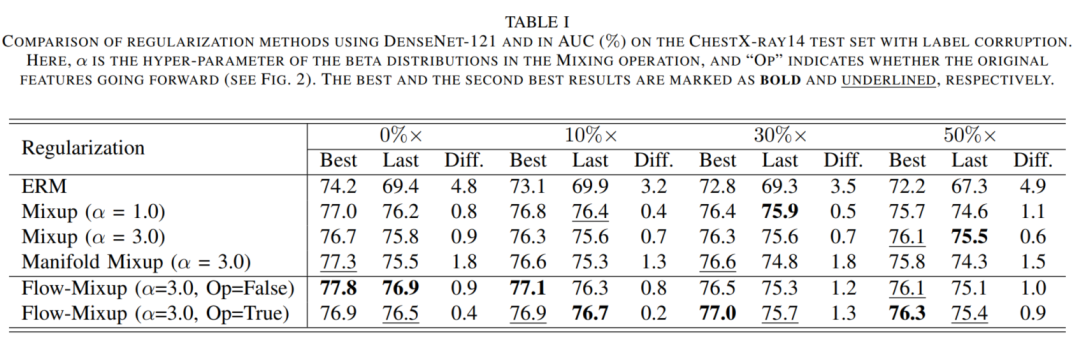
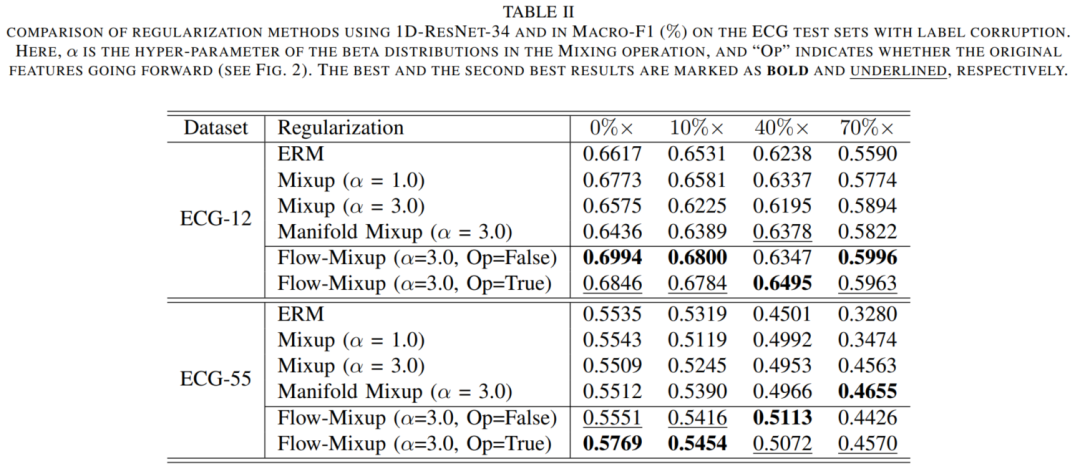
实验结论:
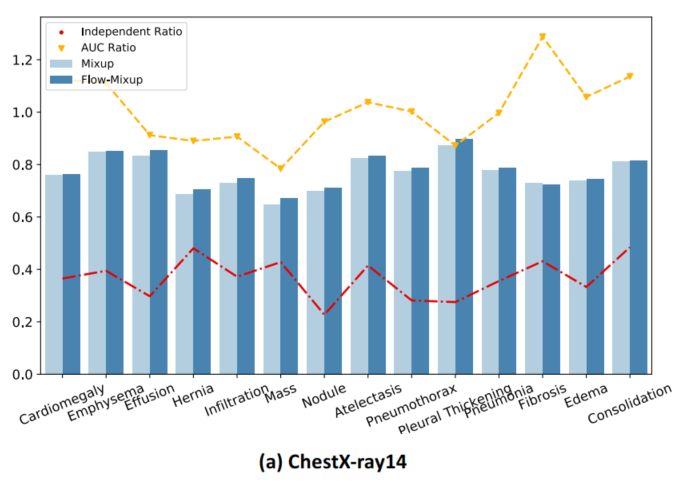
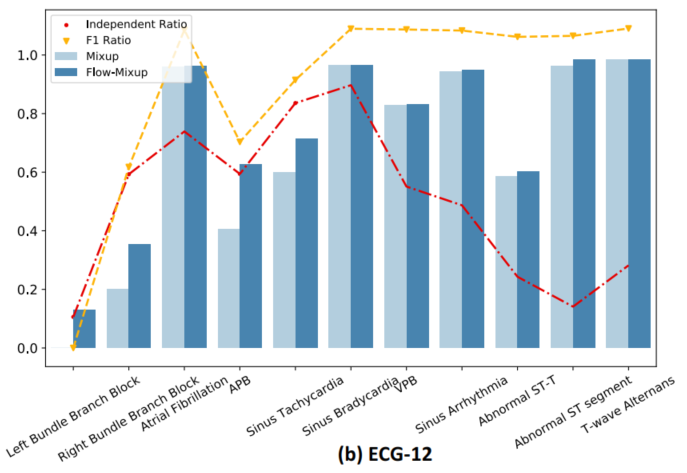
在CXR分类中最好表现、ECG分类的最佳表现。可以看出,Flow-Mixup在处理不同程度的标签损坏方面优于其他正则化方法。同时与其他正则化方法相比,Flow-Mixup方法的性能验证了Flow-Mixup方法的性能。
6 参考
[1].https://blog.csdn.net/sinat_36618660/article/details/101633504
[2].Manifold Mixup: Better Representations by Interpolating Hidden States
[3].Flow-Mixup: Classifying Multi-labeled Medical Images with Corrupted Labels
原文获取方式,扫描下方二维码
回复【Flow-Mixup】即可获取论文与源码
声明:转载请说明出处
扫描下方二维码关注【AI人工智能初学者】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!!!
点“在看”给我一朵小黄花呗![]()