
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
本篇记录一下自己项目中用到的keras相关的部分。由于本项目既有涉及multi-class(多类分类),也有涉及multi-label(多标记分类)的部分,multi-class分类网上已经很多相关的文章了。这里就说一说multi-label的搭建网络的部分。之后如果有时间的时候,再说一说cross validation(交叉验证)和在epoch的callback函数中处理一些多标签度量metric的问题。
multi-label多标记监督学习
其实我个人比较喜欢把label翻译为标签。那可能学术上翻译multi-label多翻译为多标记。其实和多标签一个意思。
multi-class 和 multi-label的区别
multi-class是相对于binary二分类来说的,意思是需要分类的东西不止有两个类别,可能是3个类别取一个(如iris分类),或者是10个类别取一个(如手写数字识别mnist)。
而multi-label是更加general的一种情况了,它说为什么一个sample的标签只能有1个呢。为什么一张图片不是猫就是狗呢?难道我不能训练一个人工智能,它能告诉我这张图片既有猫又有狗呢?
其实关于多标签学习的研究,已经有很多成果了。
主要解法是
* 不扩展基础分类器的本来算法,只通过转换原始问题来解决多标签问题。如BR, LP等。
* 扩展基础分类器的本来算法来适配多标签问题。如ML-kNN, BP-MLL等。
这里不展开了。有兴趣的同学可以自己去研究一下。
keras的multi-label
废话不多说,直接上代码。

稍微解说一下:
* 整个网络是fully connected全连接网络。
* 网络结构是输入层=你的特征的维度
* 隐藏层是500*100,激励函数都是relu。隐藏层的节点数量和深度请根据自己的数量来自行调整,这里只是举例。
* 输出层是你的label的维度。使用sigmoid作为激励,使输出值介于0-1之间。
* 训练数据的label请用0和1的向量来表示。0代表这条数据没有这个位的label,1代表这条数据有这个位的label。假设3个label的向量[天空,人,大海]的向量值是[1,1,0]的编码的意思是这张图片有天空,有人,但是没有大海。
* 使用binary_crossentropy来进行损失函数的评价,从而在训练过程中不断降低交叉商。实际变相的使1的label的节点的输出值更靠近1,0的label的节点的输出值更靠近0。
有了这个结构,就可以run起来一个multi label的神经网络了。这个只是基础中的基础,关于multi-label的度量代码才是我们研究一个机器学习问题的核心。
1. 多标签图像数据集
我们将采用如下所示的多标签图像数据集,一个服饰图片数据集,总共是 2167 张图片,六大类别:
黑色牛仔裤(Black Jeans, 344张)
蓝色连衣裙(Blue Dress,386张)
蓝色牛仔裤(Blue Jeans, 356张)
蓝色衬衫(Blue Shirt, 369张)
红色连衣裙(Red Dress,380张)
红色衬衫(Red Shirt,332张)
因此我们的 CNN 网络模型的目标就是同时预测衣服的颜色以及类型。

项目代码和数据集 获取方式:
关注微信公众号 datayx 然后回复 多标签分类 即可获取。
AI项目体验地址 https://loveai.tech
2. 多标签分类项目结构
整个多标签分类的项目结构如下所示:
├── classify.py
├── dataset
│ ├── black_jeans [344 entries
│ ├── blue_dress [386 entries]
│ ├── blue_jeans [356 entries]
│ ├── blue_shirt [369 entries]
│ ├── red_dress [380 entries]
│ └── red_shirt [332 entries]
├── examples
│ ├── example_01.jpg
│ ├── example_02.jpg
│ ├── example_03.jpg
│ ├── example_04.jpg
│ ├── example_05.jpg
│ ├── example_06.jpg
│ └── example_07.jpg
├── fashion.model
├── mlb.pickle
├── plot.png
├── pyimagesearch
│ ├── __init__.py
│ └── smallervggnet.py
├── search_bing_api.py
└── train.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
简单介绍每份代码和每个文件夹的功能作用:
search_bing_api.py :主要是图片下载,但本文会提供好数据集,所以可以不需要运行该代码;
train.py :最主要的代码,处理和加载数据以及训练模型;
fashion.model :保存的模型文件,用于 classify.py 进行对测试图片的分类;
mlb.pickle:由 scikit-learn 模块的 MultiLabelBinarizer 序列化的文件,将所有类别名字保存为一个序列化的数据结构形式
plot.png :绘制训练过程的准确率、损失随训练时间变化的图
classify.py :对新的图片进行测试
三个文件夹:
3. 基于 Keras 建立的网络结构
本文采用的是一个简化版本的 VGGNet,VGGNet 是 2014 年由 Simonyan 和 Zisserman 提出的,论文–Very Deep Convolutional Networks for Large Scale Image Recognition。
这里先来展示下 SmallerVGGNet 的实现代码,首先是加载需要的 Keras 的模块和方法:

接着开始定义网络模型–SmallerVGGNet 类,它包含 build 方法用于建立网络,接收 5 个参数,width, height, depth 就是图片的宽、高和通道数量,然后 classes 是数据集的类别数量,最后一个参数 finalAct 表示输出层的激活函数,注意一般的图像分类采用的是 softmax 激活函数,但是多标签图像分类需要采用 sigmoid 。
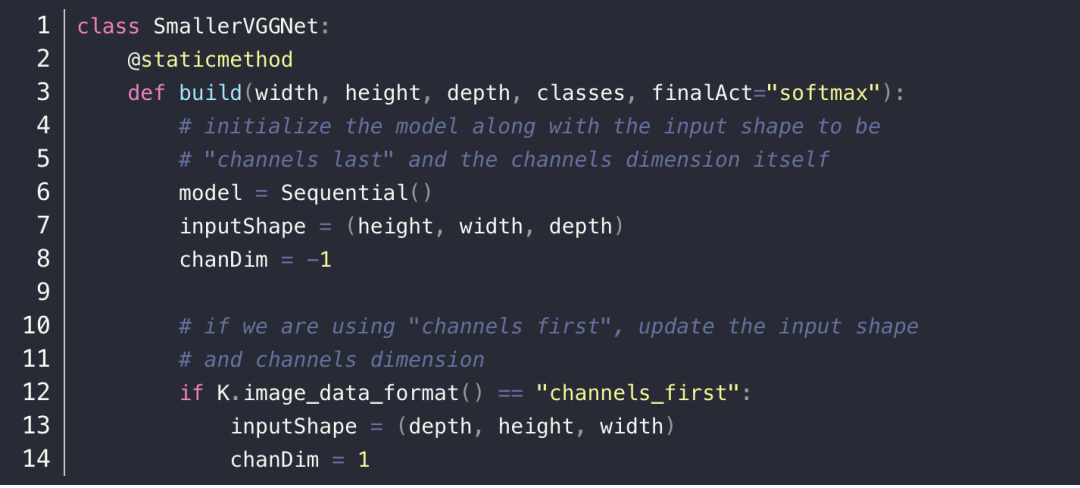
接着,就开始建立网络模型了,总共是 5 层的卷积层,最后加上一个全连接层和输出层,其中卷积层部分可以说是分为三个部分,每一部分都是基础的卷积层、RELU 层、BatchNormalization 层,最后是一个最大池化层(MaxPoolingLayer)以及 Dropout 层。
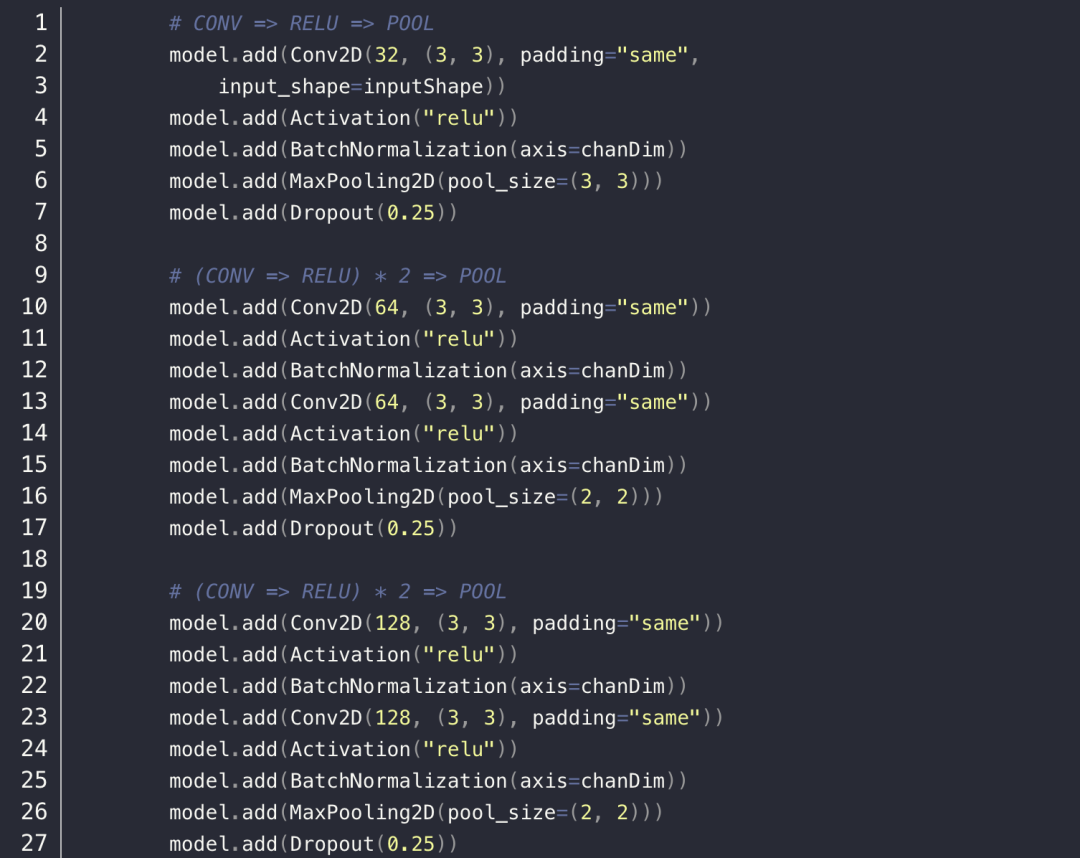

4. 实现网络模型以及训练
现在已经搭建好我们的网络模型SmallerVGGNet 了,接下来就是 train.py 这份代码,也就是实现训练模型的代码。
首先,同样是导入必须的模块,主要是 keras ,其次还有绘图相关的 matplotlib、cv2,处理数据和标签的 sklearn 、pickle 等。
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras.preprocessing.image import img_to_array
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.model_selection import train_test_split
from pyimagesearch.smallervggnet import SmallerVGGNet
import matplotlib.pyplot as plt
from imutils import paths
import numpy as np
import argparse
import random
import pickle
import cv2
import os
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
注意,这里需要提前安装的第三方模块包括 Keras, scikit-learn, matplotlib, imutils, OpenCV,安装命令如下:
pip install keras, scikit-learn, matplotlib, imutils, opencv-python
当然,还需要安装 tensorflow ,如果仅仅采用 CPU 版本,可以直接 pip install tensorflow ,而如果希望采用 GPU ,那就需要安装 CUDA,具体教程可以看看如下教程:
https://www.pyimagesearch.com/2017/09/27/setting-up-ubuntu-16-04-cuda-gpu-for-deep-learning-with-python/
接着,继续设置命令行参数:

这里主要是四个参数:
然后,设置一些重要的参数,包括训练的总次数 EPOCHS 、初始学习率 INIT_LR、批大小 BS、输入图片大小 IMAGE_DIMS :
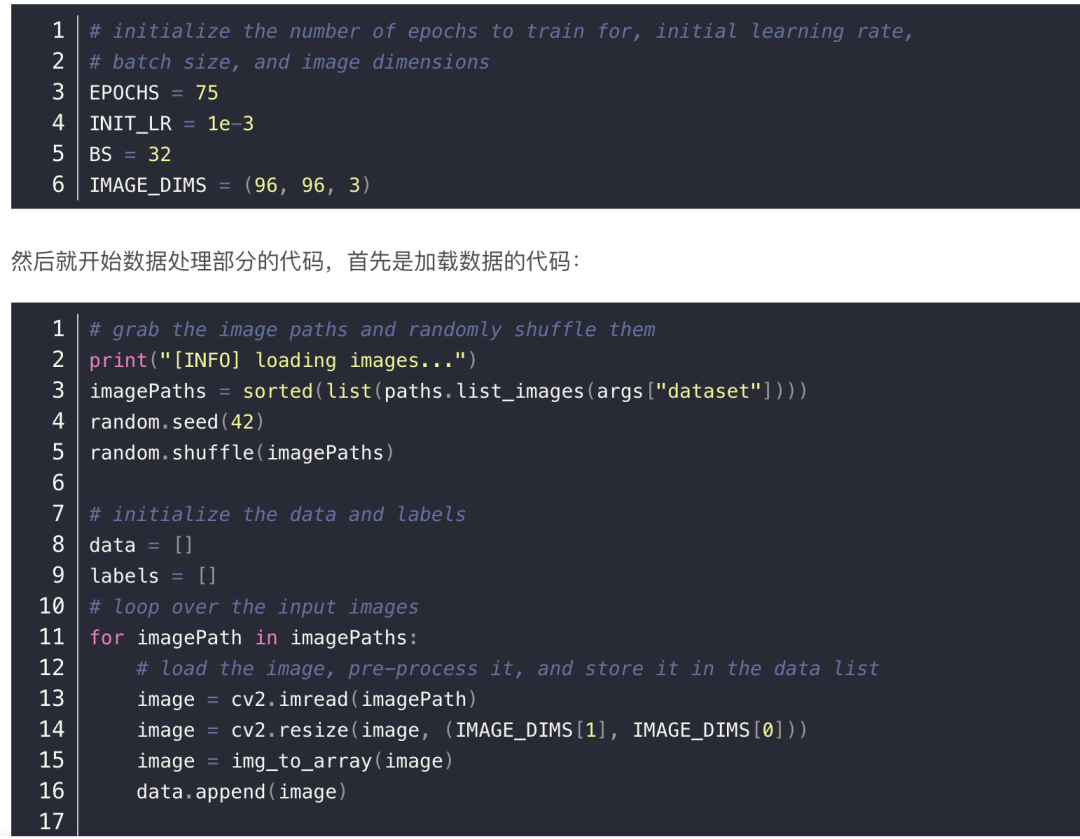
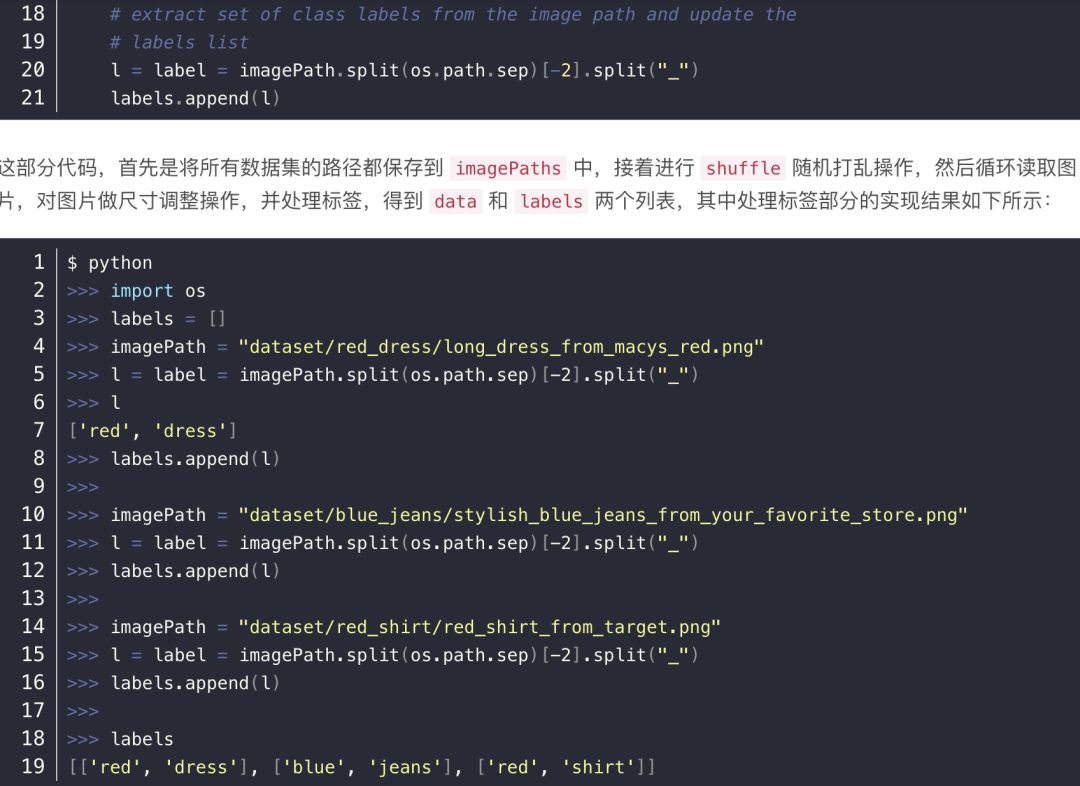
因此,labels 就是一个嵌套列表的列表,每个子列表都包含两个元素。
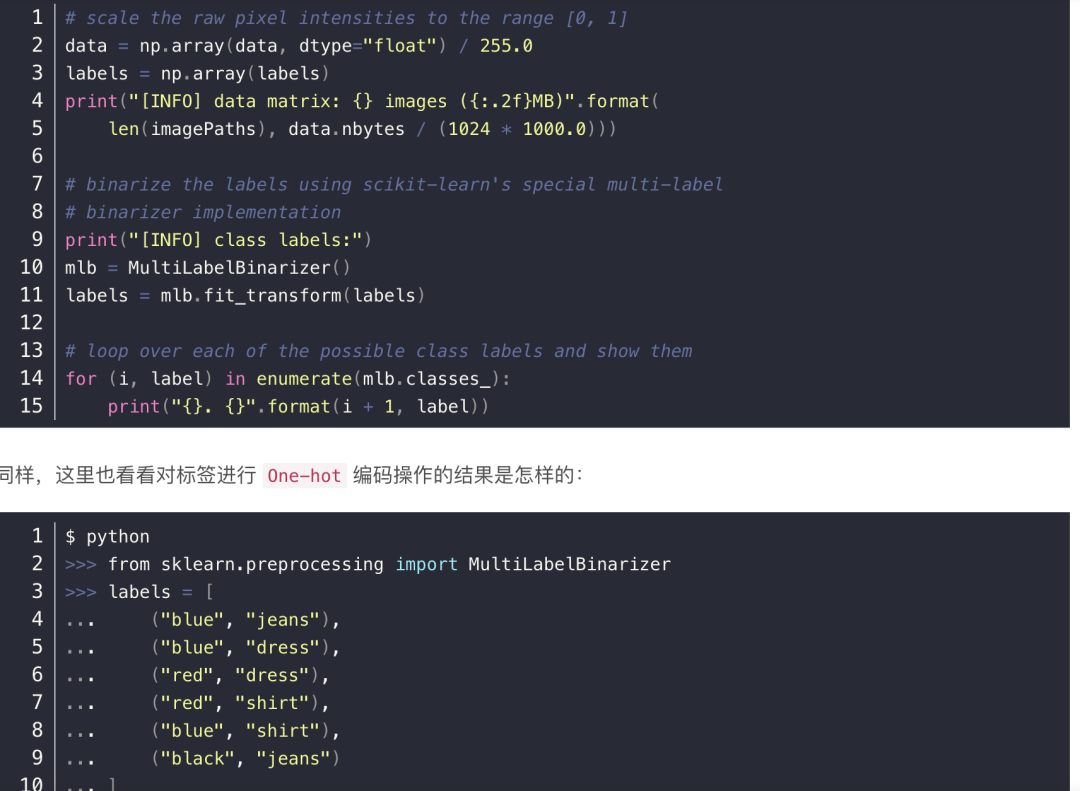
然后就是数据的预处理,包括转换为 numpy 的数组,对数据进行归一化操作,以及采用 scikit-learn 的方法 MultiLabelBinarizer 将标签进行 One-hot 编码操作:

训练集和测试集采用scikit-learn 的方法 train_test_split ,按照比例 8:2 划分。
然后就是初始化模型对象、优化方法,开始训练:
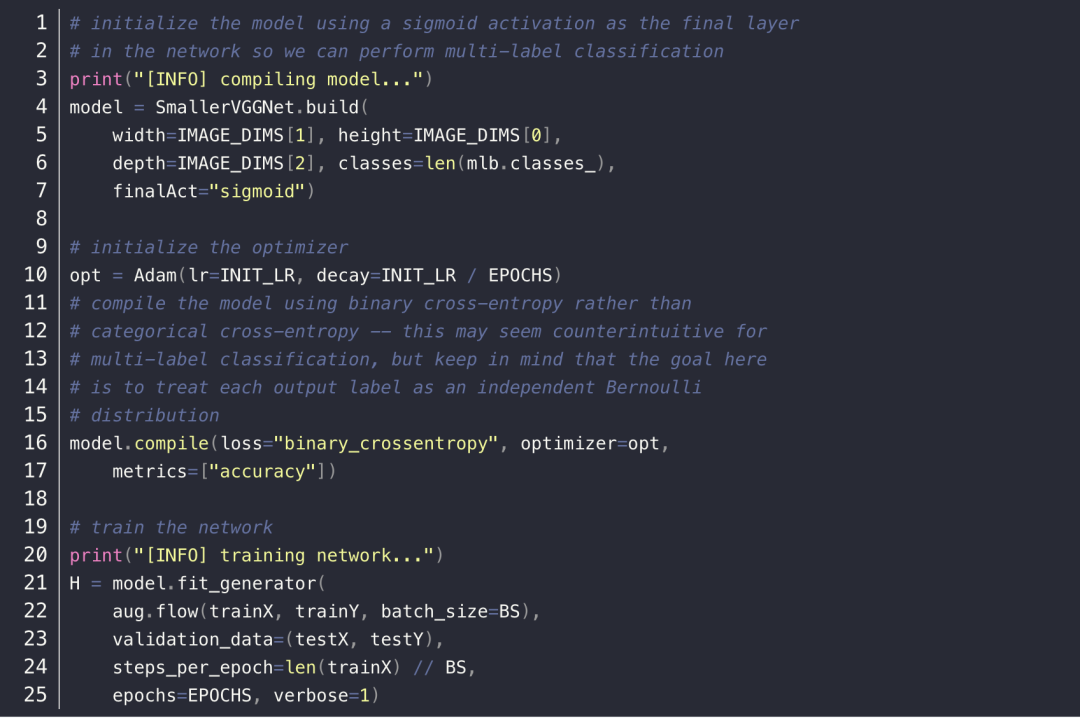
这里采用的是 Adam 优化方法,损失函数是 binary cross-entropy 而非图像分类常用的 categorical cross-entropy,原因主要是多标签分类的目标是将每个输出的标签作为一个独立的伯努利分布,并且希望单独惩罚每一个输出节点。
最后就是保存模型,绘制曲线图的代码了:
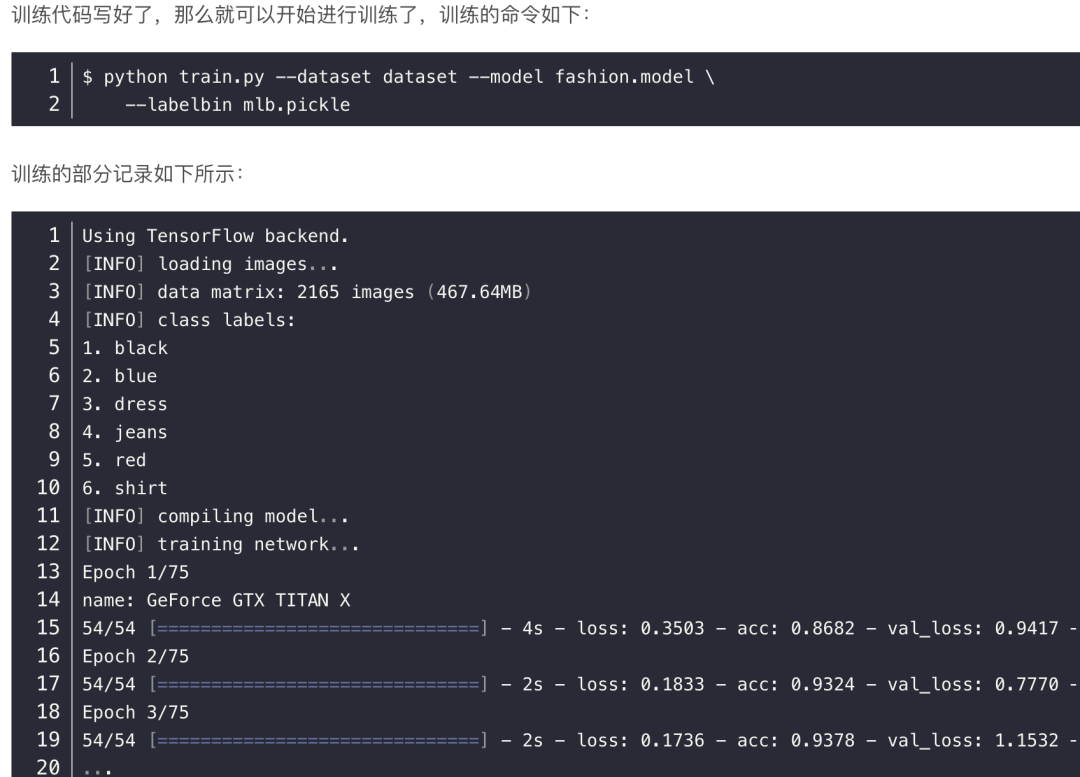
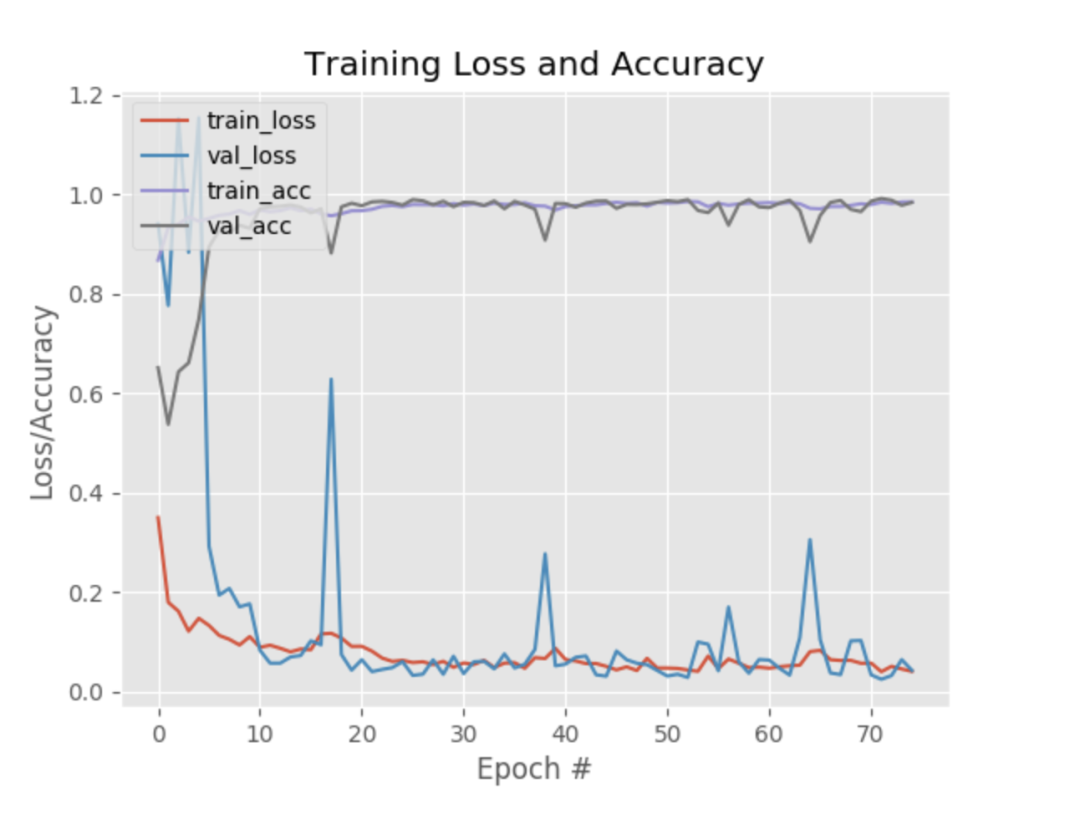
在训练结束后,训练集和测试集上的准确率分别是 98.57% 和 98.42 ,绘制的训练损失和准确率折线图图如下所示,上方是训练集和测试集的准确率变化曲线,下方则是训练集和测试集的损失图,从这看出,训练的网络模型并没有遭遇明显的过拟合或者欠拟合问题。
5. 测试网络模型
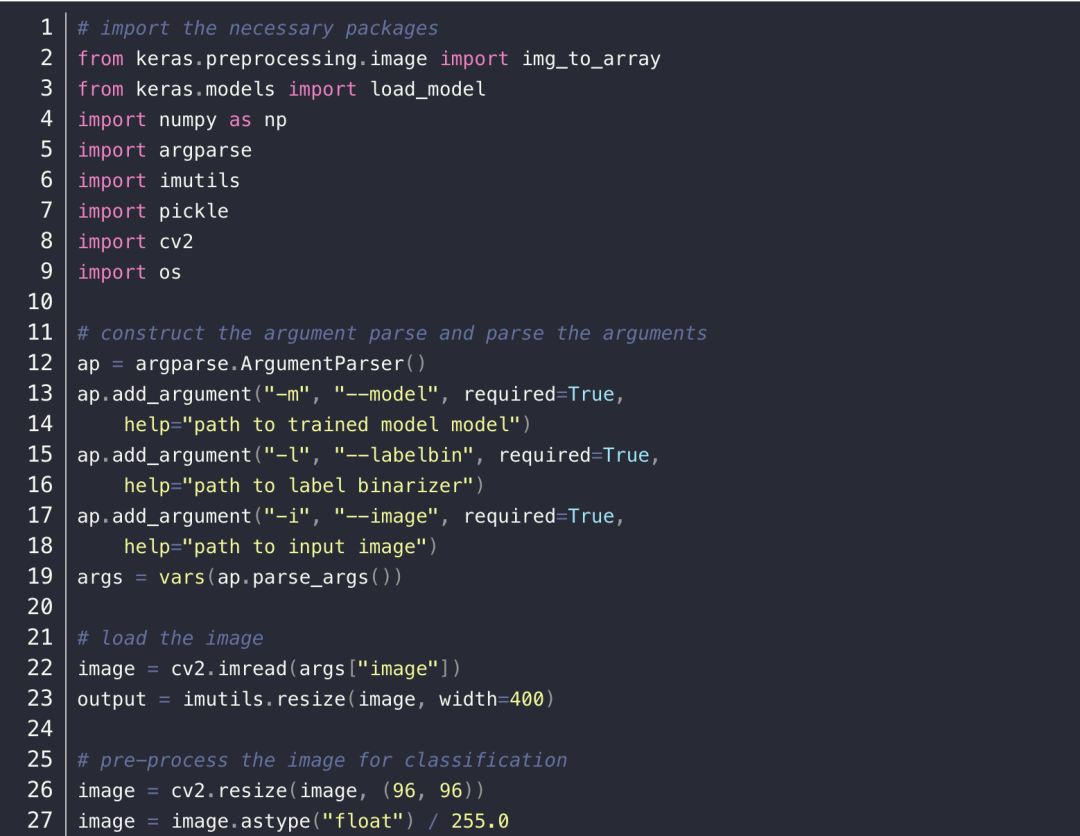
训练好模型后,就是测试新的图片了,首先先完成代码 classify.py ,代码如下:



其他的样例图片都可以通过相同的命令,只需要修改输入图片的名字即可,然后就是其中最后一张图片,是比较特殊的,输入命令如下所示:
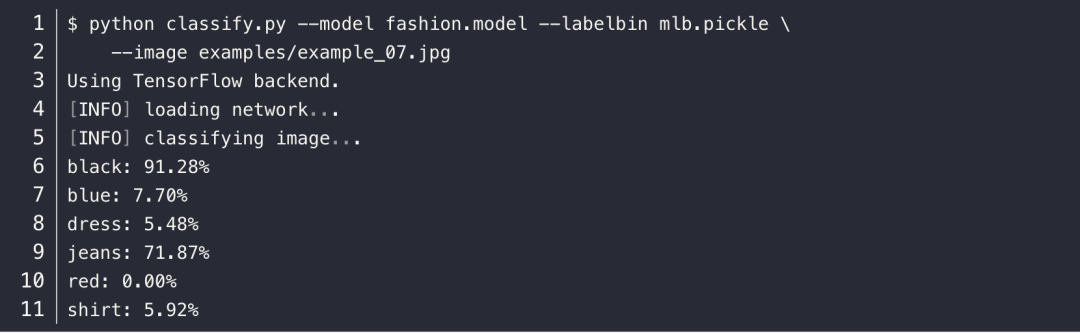
展示的结果,这是一条黑色连衣裙,但预测结果给出黑色牛仔裤的结果。

这里的主要原因就是黑色连衣裙并不在我们的训练集类别中。这其实也是目前图像分类的一个问题,无法预测未知的类别,因为训练集并不包含这个类别,因此 CNN 没有见过,也就预测不出来。
6. 小结
本文介绍了如何采用 Keras 实现多标签图像分类,主要的两个关键点:
输出层采用 sigmoid 激活函数,而非 softmax 激活函数;
损失函数采用 binary cross-entropy ,而非 categorical cross-entropy。
原文地址
https://www.pyimagesearch.com/2018/05/07/multi-label-classification-with-keras/
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
