
图像分类:一个更鲁棒的场景分类模型

向AI转型的程序员都关注了这个号???
机器学习AI算法工程 公众号:datayx
目的:寻找一个更鲁棒的场景分类模型,解决图片的角度、尺度、和光照的多样性问题。
数据说明
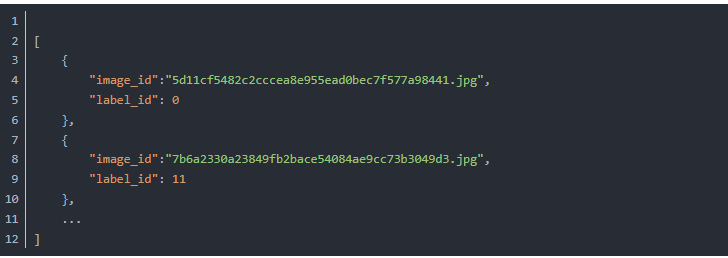
我们提供场景类别标号与场景中英文名称对照,文件结构如下:
数据集,代码运行教程 获取:
关注微信公众号 datayx 然后回复 图像分类 即可获取。
AI项目体验地址 https://loveai.tech
要点概述
支持多个单模型进行集成,可选多种集成方式
支持多种集成方式间的任意组合和自动择优
支持间断训练时权重文件的择优选择
支持
VGG16、VGG19、Resnet50、Inception-V3、Xception、Inception-Resnet-V3模型imgaug图片数据增强库替换Keras自带的图片预处理支持多进程进行图片预处理
这里对总结一下比赛期间遇到的问题,踩的坑等做个总结。
数据增强很重要!
Keras自带的图片增强远远不够的,这里选择了imgaug这个图片数据增强库,直接上图,这种效果是目前的Keras望尘莫及的,尽可能最大限度利用当前有限的数据集。提高1~3个百分点
尽可能高效使用CPU!
训练任务交给GPU去做,新添加的imgaug图片处理方式之后,一个Epoch在1050Ti上耗时90mins+,排查发现大部分时间都在进行图片数据增强处理,于是将该部分的处理替换为多进程方式。时间从90mins降到30mins左右
标准化很重要!
先计算出整体训练集的mean和std,然后在训练阶段的输入数据以mean和std进行高斯化处理(参mean_var_fetcher.py)提高0.5~1.0个百分点
Fine-tune别绑太紧!
这点尤为重要!Fine-tune时松太开,可能导致训练耗时,也可能导致机器带不动;绑太紧可能导致Fixed的权重参数扼制了模型的学习能力。建议是在机器能扛得住的基础下,尽可能松绑多一些。提高2~5个百分点
模型选择很重要!
糟糕的模型训练几天几夜,可能赶不上优势模型训练几个epoch。VGG16=>Xception提高5~8个百分点
Loss降不下去时尝试调低LR!
降不下去就调小,调下的幅度一般是5倍、10倍左右。提高1~3个百分点
TensorbBoard监视训练状态!
尽可能使用Tensorflow提供的Tensorboard可视化工具,方便从宏观把控训练过程。
适度过拟合是良性的!
训练过程中一直没有过拟合,要从两方面考虑:
模型太简单,拟合能力不足,这时要考虑增强网络复杂度
数据增强程度太大,学不到某些特征
模型集成!
单模型没有什么提升空间时,要尝试将多个单模型进行集成。集成的方式可以选择投票法、均值法、按照模型Acc加权法等等。提高0.5~1.5个百分点
预测数据增强!
为了确保预测结果的准确性,可以将待预测结果进行水平翻转(或随机裁取patch等)处理,将这多张孪生图片进行预测,最终结果取多个结果的均值。提高0.25~1.0个百分点
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码