
利用OpenCV 基于Inception模型图像分类
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:opencv学堂
要介绍Inception网络结构首先应该介绍一下NIN(Network in Network)网络模型,2014年新加坡国立大学发表了一篇关于计算机视觉图像分类的论文,提到采用了一种新的网络结构NIN实现图像分类,该论文的第二作者颜水成毕业于北京大学数学系,现任360人工智能研究院院长与首席科学家。NIN主要思想是认为CNN网络中卷积滤波是基于线性滤波器实现的,抽象能力不够,所以一般是用一大堆filter把所有特征都找出来,但是这样就导致网络参数过大,论文作者提出通过MLP(多个权重阶层组成+一个非线性激活函数)对输入区域通过MLP产生一个输出feature map,然后继续滑动MLP窗口,对比如下:
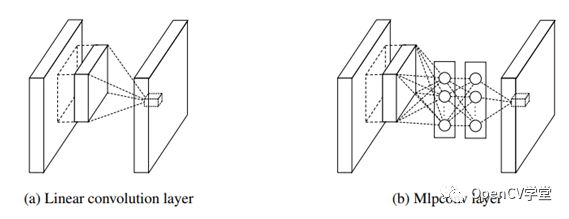
这样做有两个好处,
MLP可以共享参数,减少参数总数
对每个局部感受野神经元实现更加复杂计算,提升能力
论文中提到NIN网络完整结构如下:
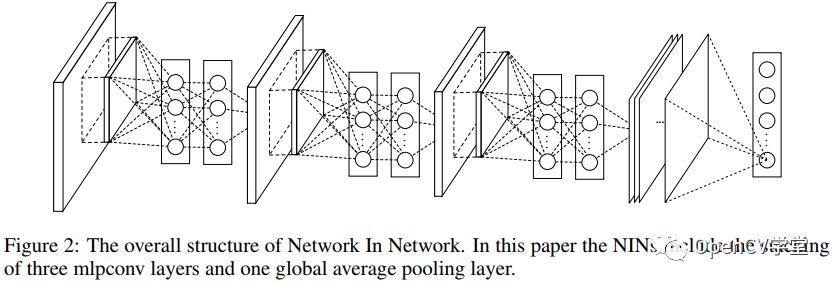
包含了三个MLP卷积层与一个全局池化层。
受到这篇文章的影响与启发,谷歌在2014也提出一个新的网络模型结构Inception网络也就是大家熟知v1网络,其主要贡献在于实现了NIN网络层数的增加,并且在训练各个网络时候为了提高收敛,考虑中间层的输出与最终分类错误。只是中间层不同,最初inception网络的中间层为:
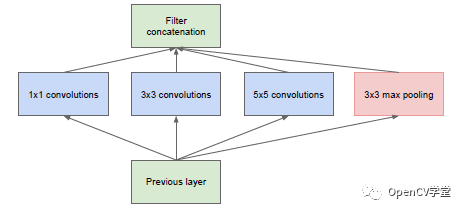
后来发现3x3与5x5的卷积计算耗时很长,而且输出导致卷积厚度增加,如果层数过度将导致卷积网络不可控制,于是就在3x3与5x5的卷积之前分别加上1x1的卷积做降维,修改后的结构如下:
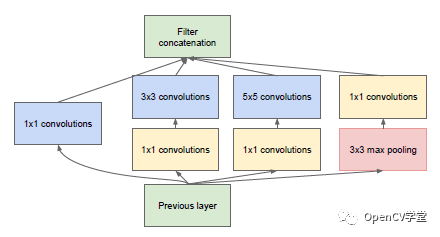
最终得到v1版本的网络结构如下:
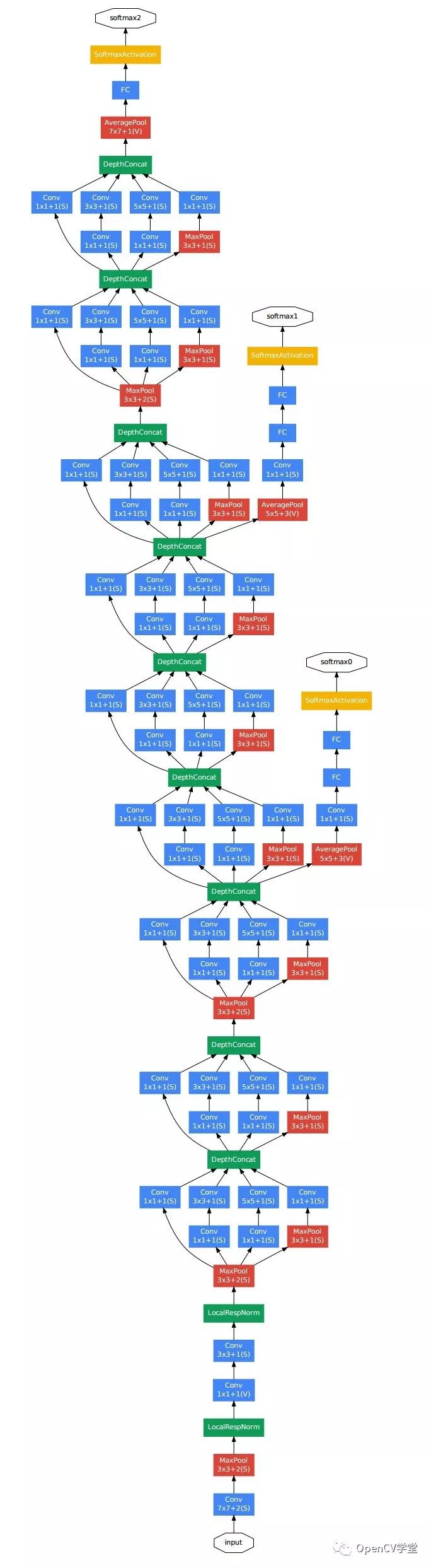
于是在v1的基础上作者继续工作,加入了BN层,对大于3x3的卷积用一系列小的卷积进行替代,比如7x7可以被1x7与7x1替代两个小卷积核,5x5可以被1x5与5x1两个小卷积核替代,这样就得到Inception v2的版本。于是作者继续对此网络结构各种优化调整,最终又得到了Inception v3版本
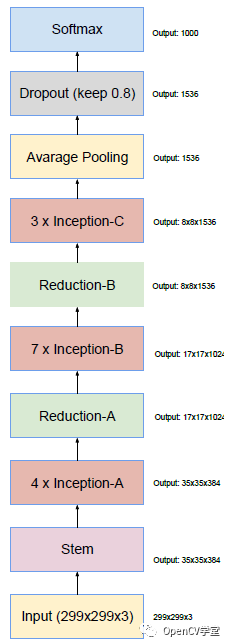
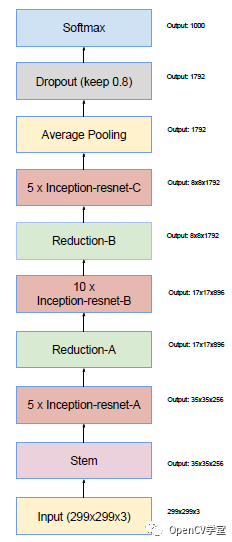
Inception v4一个最大的改动就是引入了残差网络结构,对原有的网络结构进行优化,得到v1与v2的残差版本网络结构,最终得到一个更加优化的v4模型,完整的v4结构:
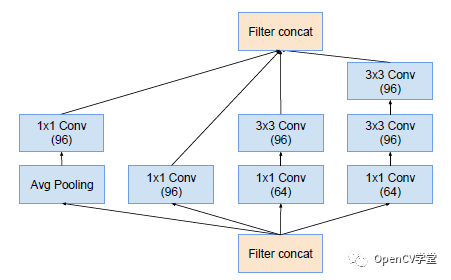
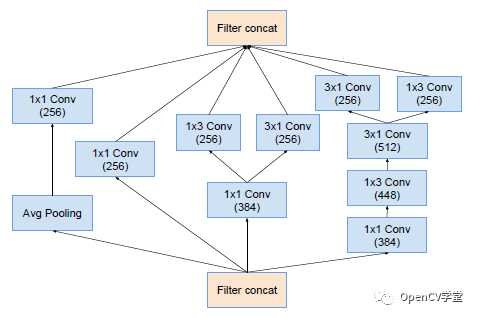
对应的Block A、B、C结构如下:Inception-A
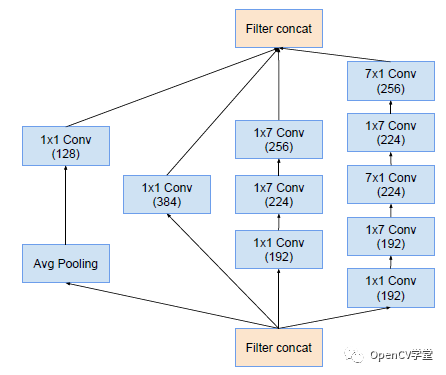
Inception-B
Inception-C
v1模型加残差网络结构
下载Inception预训练网络模型
使用OpenCV DNN模块相关API加载模型
运行Inception网络实现图像分类 完整的代码实现如下:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <iostream>
/******************************************************
*
* 作者:贾志刚
* QQ: 57558865
* OpenCV DNN 完整视频教程:
* http://edu.51cto.com/course/11516.html
*
********************************************************/
using namespace cv;
using namespace cv::dnn;
using namespace std;
String labels_txt_file = "D:/android/opencv_tutorial/data/models/inception5h/imagenet_comp_graph_label_strings.txt";
String tf_pb_file = "D:/android/opencv_tutorial/data/models/inception5h/tensorflow_inception_graph.pb";
vector<String> readClassNames();
int main(int argc, char** argv) {
Mat src = imread("D:/vcprojects/images/twocat.png");
if (src.empty()) {
printf("could not load image...\n");
return -1;
}
namedWindow("input", CV_WINDOW_AUTOSIZE);
imshow("input", src);
vector<String> labels = readClassNames();
Mat rgb;
cvtColor(src, rgb, COLOR_BGR2RGB);
int w = 224;
int h = 224;
// 加载网络
Net net = readNetFromTensorflow(tf_pb_file);
if (net.empty()) {
printf("read caffe model data failure...\n");
return -1;
}
Mat inputBlob = blobFromImage(src, 1.0f, Size(224, 224), Scalar(), true, false);
inputBlob -= 117.0; // 均值
// 执行图像分类
Mat prob;
net.setInput(inputBlob, "input");
prob = net.forward("softmax2");
// 得到最可能分类输出
Mat probMat = prob.reshape(1, 1);
Point classNumber;
double classProb;
minMaxLoc(probMat, NULL, &classProb, NULL, &classNumber);
int classidx = classNumber.x;
printf("\n current image classification : %s, possible : %.2f", labels.at(classidx).c_str(), classProb);
// 显示文本
putText(src, labels.at(classidx), Point(20, 20), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);
imshow("Image Classification", src);
imwrite("D:/result.png", src);
waitKey(0);
return 0;
}
std::vector<String> readClassNames()
{
std::vector<String> classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
输入原图:

测试结果:

关键是速度很快,比VGG快N多,基本秒出结果!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~