
多标签图像分类综述
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转载自:言有三

图像分类作为计算机视觉领域的基础任务,经过大量的研究与试验,已经取得了傲人的成绩。然而,现有的分类任务大多是以单标签分类展开研究的。当图片中有多个标签时,又该如何进行分类呢?本篇综述将带领大家了解多标签图像分类这一方向,了解更具难度的图像分类。
随着科学技术的进步与发展,图像作为信息传播的重要媒介,在通信、无人驾驶、医学影像分析、航天、遥感等多个领域得到了广泛的研究,并在国民社会、经济生活中承担着更加重要的角色。人们对图像研究的愈发重视,也促使计算机视觉领域迎来了蓬勃发展的黄金时代。
作为计算机视觉领域的基础性任务,图像分类是目标检测、语义分割的重要支撑,其目标是将不同的图像划分到不同的类别,并实现最小的分类误差。经过近30年的研究,图像分类已经成功应用至社会生活的方方面面。如今,在我们的生活中随处可见——智能手机的相册自动分类、产品缺陷识别、无人驾驶等等。
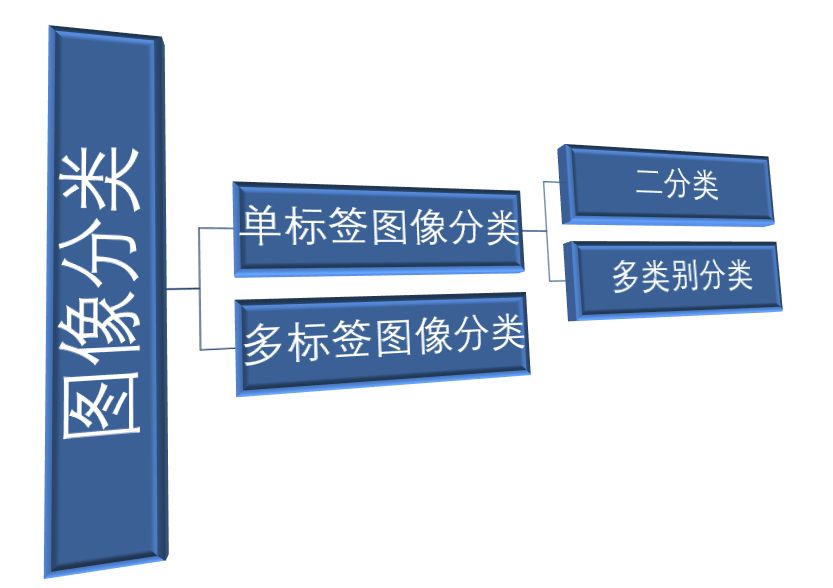
根据分类任务的目标不同,可以将图像分类任务划分成两部分:(1)单标签图像分类;(2)多标签图像分类。
单标签图像分类是指每张图片对应一个类别标签,根据物体类别的数量,又可以将单标签图像分类划分成二分类、多类别分类。如下图所示,可以将该图的标签记为海洋,通过单标签图像分类我们可以判定该图像中是否含有海洋。
然而,现实生活中的图片中往往包含多个类别的物体,这也更加符合人的认知习惯。我们再来观察下图,可以发现图中不仅包含海洋,还包括了海豚。多标签图像分类可以告知我们图像中是否同时包含这些内容,这也能够更好地解决实际生活中的问题。

机器学习算法主要包括两个解决思路:
(1) 问题迁移,即将多标签分类问题转化为单标签分类问题,如将标签转化为向量、训练多个分类器等;
(2) 根据多标签特点,提出新的适应性算法,包括ML-KNN、Ranking SVM、Multi-label Decision Tree等。现对其中具有代表性的算法进行总结。
2.1 问题迁移
问题迁移方法的主要思想是先将多标签数据集用某种方式转换成单标签数据集,然后运用单标签分类方法进行分类。该方法有可以包括基于标签转换和基于样本实例转换。
2.1.1 基于标签转换
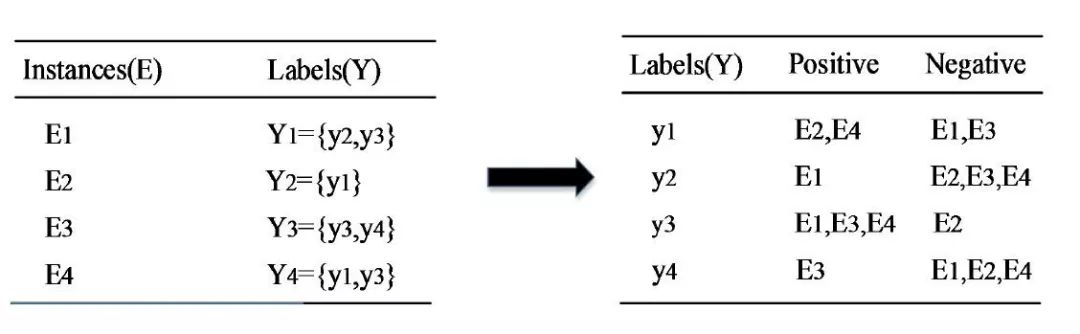
针对每个标签,将属于这个标签的所有实例分为一类,不属于的分为另一类,将所有数据转换为多个单标签分类问题(如下图)。典型算法主要有Binary Relevance和Classifier Chain两种。
2.1.2 基于样本实例转换
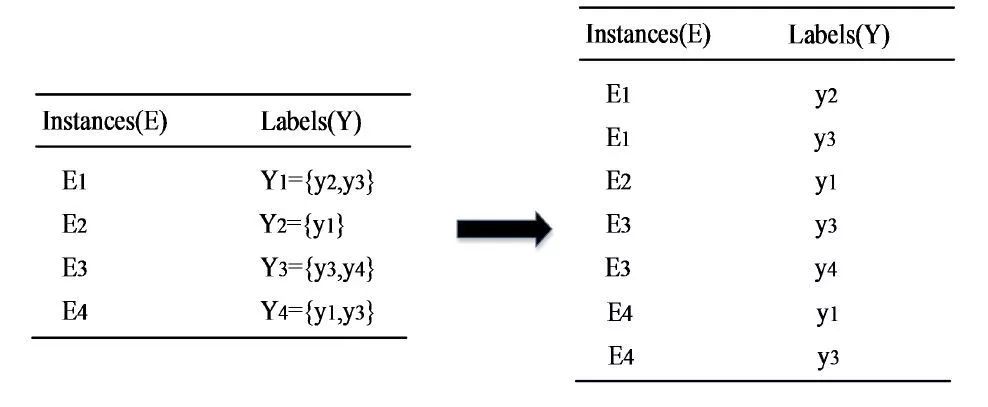
这种方法是将多标签实例分解成多个单标签实例。如下图所示。实例E3对应标签y3和y4,则通过分解多标签方法法将E3分解成单独选中标签y3和y4的实例,然后对每一个标签作单独预测。
2.2 适应性方法
如上文所述,新的适应性算法是根据多标签分类的特殊性,改进现有的单标签分类算法,主要包括以下三种:
2.2.1 ML-KNN

ML-KNN由传统的KNN算法发展而来。首先通过KNN算法得到样本最接近的K个邻近样本,然后根据K个邻近样本的标签,统计属于某一标签的邻近样本个数,最后利用最大后验概率原则(MAP)决定测试样本含有的标签集合。
2.2.2 Rank SVM

Rank SVM是在SVM的基础上,加入Ranking Loss损失函数和相应的边际函数作为约束条件,并扩展目标函数而提出的一种多标签学习算法。该算法的简要思路是:首先定义函数s(x)是样本x的标签集的规模大小,然后定义rk(x)=wkTx+bk,如果求得的rk(x)值在最大的s(x)个元素(r1(x),...rQ(x))之间,则认为该样本x选中该标签k,否则就没被选中。在求解过程中定义新的排序函数rk(x)-rl(x)≥1,其中k表示被样本x选中的标签,l表示没有被选中的标签,并基于这个新的排序函来大间隔分类器,同时最小化Ranking Loss,从而推导出适合多标签分类的目标函数和限制条件。
2.2.3 Multi-label Decision Tree

该算法采用决策树技术处理多标签数据,利用基于多标签熵的信息增益准则递归地构建决策树。树形结构包括非叶结点、分支、叶节点。决策树模型用于分类时,特征属性用非叶节点表示,特征属性在某个值域上的输出用非叶节点之间的分支表示,而类别则用叶节点存放。
计算思想如下:首先计算每个特征的信息增益,挑选增益最大的特征来划分样本为左右子集,递归下去,直到满足停止条件,完成决策树的构建。对新的测试样本,沿根节点遍历一条路径到叶子节点,计算叶子节点样本子集中每个标签为0和1的概率,概率超过0.5则表示含有该标签。当遍历所有路径到底不同的叶节点之后,则可判断涵盖的所有标签信息。
除了上述三类主要算法外,还包括诸多以单标签分类进行改进的算法,在此不再赘述。
深度学习的发展带动了图像分类精度的大幅提升,神经网络强大的非线性表征能力可以在大规模数据中学习到更加有效的特征。近年来,多标签图像分类也开始使用深度学习的思想展开研究。
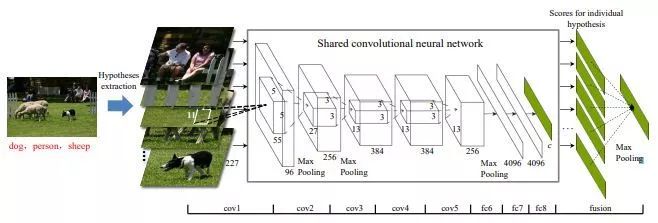
魏云超等在程明明教授提出的BING理论基础上,提出了Hypotheses-CNN-Pooling。首先对每张图片提取含有标签信息的候选区域(如上图中的Hypotheses Extraction过程),然后将每个候选区域送入CNN进行分类训练,最后利用cross-hypothesis max-pooling融合所有候选区域的分类结果,从而得到多个标签信息完整的图片。
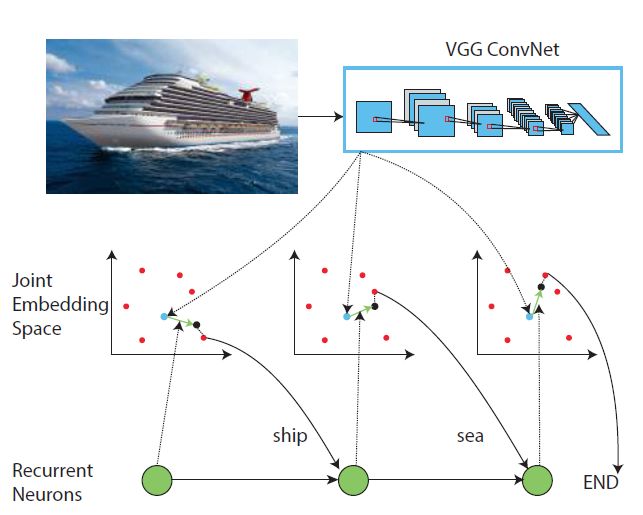
CNN具有强大的语义信息提取能力,而RNN则可以建立信息之间的关联。根据这一理论观点,Jiang Wang等提出了CNN-RNN联合的网络结构。首先利用CNN对输入图像进行训练,得到相应的特征,然后将图片对应的特征投影到与标签一致的空间中,在该空间利用RNN进行单词的搜索训练。该算法充分考虑了类别之间的相关性,可以有效对图像中具有一定关系的标签进行识别。
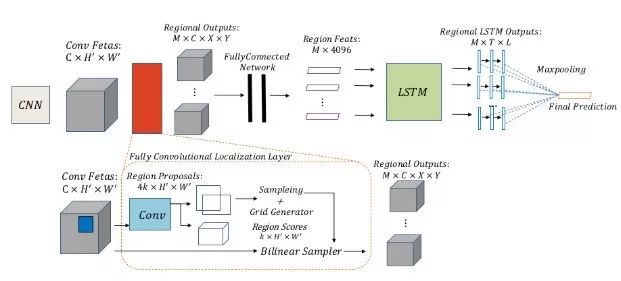
在CNN-RNN结构的基础上,后续文章又加入Regional LSTM模块。该模块可以对CNN的特征进行导向处理,从而获取特征的位置信息,并计算位置信息和标签之间的相关性。在上文的结果上进一步考虑了特征、位置和标签之间潜在的依赖关系,可以有效计算图片中多个标签同时存在的可能性,并进行图片的分类。
最近,诸多基于image-level进行弱监督分割研究的文章,充分利用了多标签分类网络的信息。其主要思想是将标签统一处理为向量形式,为每幅图片构建一个维度为1xN的矩阵标签(如[0,0,0,1,1,0]形式),并采用专门的损失函数(Hanming loss、Ranking loss等)进行训练。这一方法成功地将多标签的复杂问题,转化为单标签问题,从而可以利用传统的分类网络进行训练。
多标签图像分类的相关算法仍然层出不穷,但不论是基于机器学习还是基于深度学习的算法,都有其优势和不足,如何根据实际应用需求选用合适的算法,才是我们应当关注的重点内容。
单标签分类中通常采用准确率(Precision),召回率(Recall)、F值(F-measure)和AUC曲线对分类结果进行评价。然而,在多标签分类中一个图片与多个标签同时关联,其复杂程度远远高于单标签分类。因此,在继承单标签分类评价指标的基础上,许多关于多标签分类的评价指标也被提出。在这里只介绍多标签分类常用的指标,有关单标签分类的指标不再赘述。
4.1 平均准确率(AP)和平均准确率均值(mAP)
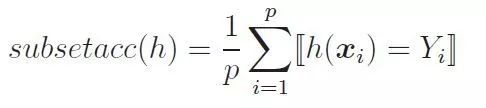
同单标签分类一样,当一张图片中的所有标记均预测正确时,准确率才可以置1,否则置零。每个类别下的标签分别进行计算后,取其平均值即可获得平均准确率,对所有平均准确率取均值即可获得平均准确率均值。平均准确率可以衡量模型在每个类别的好坏程度,而平均准确率均值则衡量的是在所有类别的好坏程度。
4.2 汉明距离
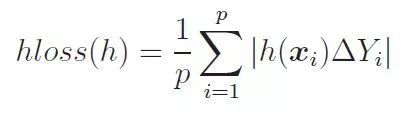
将预测的标签集合与实际的标签集合进行对比,按照汉明距离的相似度来衡量。汉明距离的相似度越高,即汉明损失函数越小,则模型的准确率越高。
4.3 1-错误率
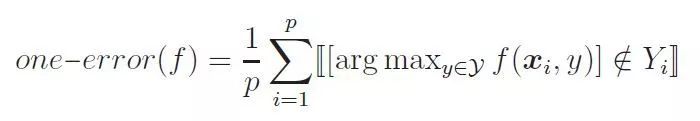
1-错误率用来计算预测结果中排序第一的标签不属于实际标签集中的概率。其思想相当于单标签分类问题中的错误率评价指标。1-错误率越小,说明预测结果越接近实际标签,模型的预测结果也就越好。
4.4 覆盖率
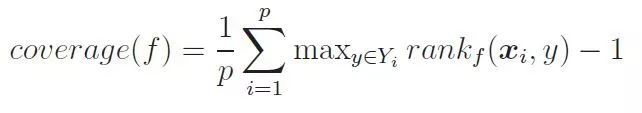
覆盖率用来度量“排序好的标签列表”平均需要移动多少步数,才能覆盖真实的相关标签集合。对预测集合Y中的所有标签{y1,y2,… yi … yn}进行排序,并返回标签yi在排序表中的排名,排名越高,则相关性越差,反之,相关性越高。
4.5 排序损失
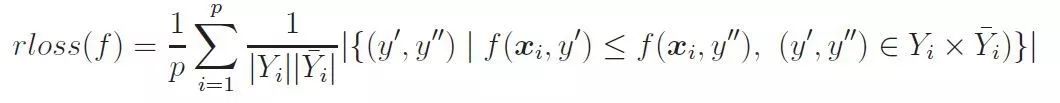
排序损失计算的是不相关标签比相关标签的相关性还要大的概率。
高质量的数据集是图像分类的基础,更是关键所在。随着人们对数据质量的重视程度越来越高,如今已有诸多完备的多标签图像分类数据集。
5.1 Pascal VOC
Pascal VOC数据集的主要任务是在真实场景中识别来自多个类别的目标。该数据集共有近两万张图片,共有20个类别组成。Pascal VOC官方对每张图片都进行了详细的信息标注,包括类别信息、边界框信息和语义信息,均保存在相应的xml格式文件中。通过读取xml文件中的
5.2 COCO
COCO(Common Objects in Context)数据集由微软公司赞助搭建。该数据集包含了91个类别,三十余万张图片以及近二百五十万个标签。与Pascal VOC相类似,COCO数据的标注信息均保存在图片对应的json格式文件中。通过读取json文件中的annotation字段,可以获取其中的category_id项,从而获取图片中的类别信息。同一json文件中包含多个category_id项,可以帮助我们构建多标签信息。COCO数据集的类别虽然远远大于Pascal VOC,而且每一类包含的图像更多,这也更有利于特定场景下的特征学习。
除了上述两个个主流数据集之外,比较常用的还包括ImageNet数据集、NUS-WIDE数据集。近年来,诸多公司、科研机构也提出了诸多全新的数据集,如ML-Images等。这些标注完善的数据,为多标签图像分类的研究提供了有力的支持,同样也为图像处理领域的发展做出了巨大贡献。
(1) 多标签图像分类的可能性随着图片中标签类别的增加呈指数级增长,在现有的硬件基础上会加剧训练的负担和时间成本,如何有效的降低信息维度是面临的最大挑战。
(2) 多标签分类往往没有考虑类别之间的相关性,如房子大概率不会出现老虎、海洋上不太可能出现汽车。对于人类来说,这些均是常识性的问题,但对于计算机却是非常复杂的过程,如何找到类别之间的相关性也能够更好的降低多标签图像分类的难度。
古语有云:“纸上得来终觉浅,绝知此事要躬行”,理论知识的学习必须通过实践才能进一步强化,想亲身体会算法细节还需要认真实战。
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~