
细腻度图像分类MACNN
一、MACNN介绍
细粒度识别通常包括两个问题:区域定位和基于区域的细粒度特征学习。传统的方法都是独立的解决这两个问题,却忽略了两者是可以相互促进的。论文作者认为两者是相互关联的,即初始的区域定位能够学到细粒度特征,反过来能够促进生成更加精细的区域定位,于是作者提出了MACNN,它能够以一种相互促进的方式来进行区域定位和基于区域的细粒度特征学习。
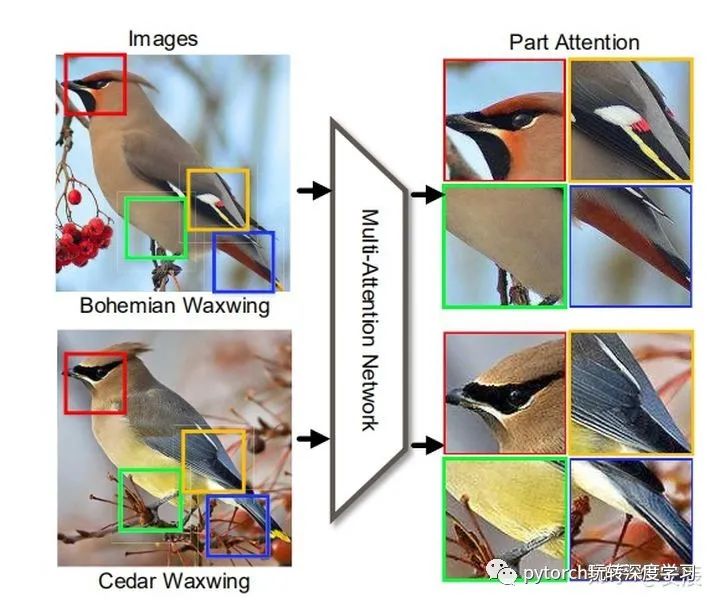
二、MACNN的结构
MACNN包括:convolution、channel grouping 、part classifification sub-networks
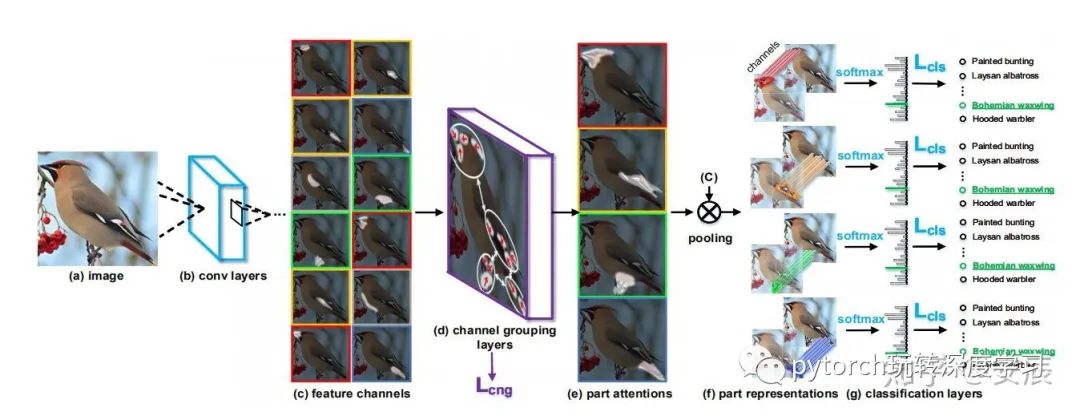
如上图所示,MACNN首先以一张Full Image作为输入,经过convolution层后,生成了feature map,大家应该知道,每一个feature channel 代表了原图中的某一个部分,也就是会对原图中的某一个部分产生峰值响应,即上图(c)中有12个feature channel,每一个feature channel上都有白色的区域,那个就是峰值响应。channel grouping要做的事就是把这些峰值响应区域相邻的channel给放在一块,也就是把上图(c)中颜色相同的channel放在一块,最后生成(f),至于怎么生成(f),后续会有讲解,可以看到在(f)中会有四个不同的区域,我们要对每个区域进行分类,所以使用part classifification sub-networks对每一个part进行分类,这就是MACNN的网络结构。
三、MACNN采用的方法
首先给出一张图片X,我们提取这张图片基于区域的特征,所以把这张图片喂到卷积神经网络中提取特征,即:W ∗ X,这里的∗代表卷积、池化、激活一系列操作,W代表卷积层的所有参数,最后得到的conv layers的大小为w × h × c,w代表宽度,h代表高度,c代表通道数。
由于我们要对channel进行分组,我们设定要将channel分为N组,那么就需要N个channel layers,为了能够使channel grouping优化,论文中采用FC层来完成通道分组操作,对于N个part,则有F(·) = [f1(·), ..., fN (·)]。每一个f(.)的输入都是卷积层的feature map,公式为:
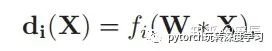
结果为权重向量:
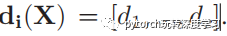
这里得到的结果为一个vector,个数为特征图的通道数,代表的是什么含义呢?代表的就是第j(1<j<c)个通道是否属于第i个part,如果在,则  =1,反之为0,当然只是接近于1或者0,因为只有在理想情况下才是等于1或者0。
=1,反之为0,当然只是接近于1或者0,因为只有在理想情况下才是等于1或者0。
得到了权重向量之后,我们就可以生成attention map,公式如下:
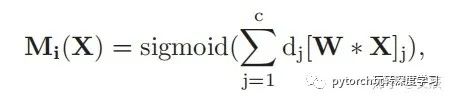
这里的  代表的是第j个通道的特征,然后乘以一个标量,这个是什么意思呢?意思就是把属于相同区域的通道给累加起来从而获取更加丰富的信息,然后经过sigmoid函数得到一个probablity,仔细品一品看看是不是这个道理。
代表的是第j个通道的特征,然后乘以一个标量,这个是什么意思呢?意思就是把属于相同区域的通道给累加起来从而获取更加丰富的信息,然后经过sigmoid函数得到一个probablity,仔细品一品看看是不是这个道理。
有了attention map之后,我们开始生成part representation,公式如下:
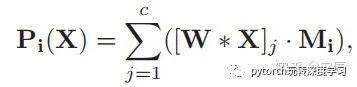
这里的 代表的是第j个通道的特征,然后逐元素相乘  ,代表的只是对于某一个part来说,某一个像素属于这个part的probability,也之所以作者做了一下归一化(通过所有元素的和)。
,代表的只是对于某一个part来说,某一个像素属于这个part的probability,也之所以作者做了一下归一化(通过所有元素的和)。
得到了part representation之后就可以通过part classifification sub-networks对每一个part进行分类啦。
四、MACNN损失函数
MACNN损失函数如下:
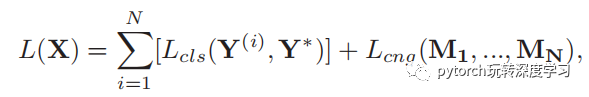
其中前面一部分就是我们常见的分类损失,后一部分的公式如下:
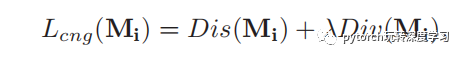
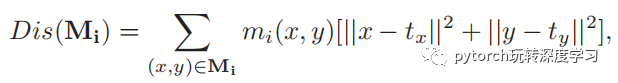
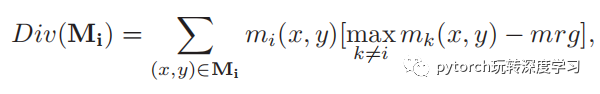
其中Dis()可以使得part内变得更加聚集,Div()可以使得part间变得更加分散,这样可以使得channel尽可能的只存在于某一个part中,另外,通过存在多个part,能够使得在部分区域被遮挡的情况下,仍然能够通过其他的part进行分类,增加了分类网络的泛化性。
作者的优化思路是基于上面两个损失函数进行的,这两个损失函数相互加强,不断迭代。先固定住图二(b)、(g)部分的参数,使用Lcng优化channels grouping部分。然后固定住channels grouping的参数,然后使用Lcls对(b)、(g)部分进行优化。这样不断迭代,直到两个损失值都不再变化。