
小样本学习--概念、原理与方法简介(Few-shot learning)
Few-shot learning (FSL) 在机器学习领域具有重大意义和挑战性,是否拥有从少量样本中学习和概括的能力,是将人工智能和人类智能进行区分的明显分界点,因为人类可以仅通过一个或几个示例就可以轻松地建立对新事物的认知,而机器学习算法通常需要成千上万个有监督样本来保证其泛化能力。原则上我们将FSL方法分为基于生成模型和基于判别模型两种,其中基于元学习的FSL方法值得特别注意。
到目前为止,FSL有一部分比较重要的应用,涵盖了计算机视觉,自然语言处理,音频和语音,强化学习和数据分析等许多研究热点,可以说是一个很有发展前景的方向。
地址:https://zhuanlan.zhihu.com/p/258562899
01
INTRODUCTION
首先,FSL方法预计不会依赖大规模的训练样本,从而避免了某些特定应用中数据准备的高昂成本。 FSL可以缩小人类智能与人工智能之间的距离,这是发展通用类型AI的必经之路。 FSL可以为一项新出现的、可采集样本很少的任务实现低成本,快速的模型部署。
 ,(
,(  , 从联合分布
, 从联合分布  中得出)
中得出) ,使得预期的错误成本
,使得预期的错误成本  达到最小。
达到最小。 表示
表示  的预测值
的预测值  与其实际值
与其实际值  之前的损失Loss 对于我们是未知的,因此因此学习算法实际上旨在最小化经验误差
之前的损失Loss 对于我们是未知的,因此因此学习算法实际上旨在最小化经验误差  。
。 的函数空间
的函数空间  太大,则泛化误差
太大,则泛化误差  会变得很大,因此,很容易出现过拟合。
会变得很大,因此,很容易出现过拟合。
 中包含更多的受监督的样本,那么函数 将会有更多的约束条件,这意味着函数 的空间将会变小,这将会带来一个比较好的泛化效果。相反,如果监督样本的数据集规模减少,自然会导致较差的泛化能力。从本质上讲,每个监督样本形成的约束可以看作是函数 上的归一化,它可以压缩函数 的冗余可选空间,从而减少学习算法的泛化误差。
中包含更多的受监督的样本,那么函数 将会有更多的约束条件,这意味着函数 的空间将会变小,这将会带来一个比较好的泛化效果。相反,如果监督样本的数据集规模减少,自然会导致较差的泛化能力。从本质上讲,每个监督样本形成的约束可以看作是函数 上的归一化,它可以压缩函数 的冗余可选空间,从而减少学习算法的泛化误差。02
OVERVIEW
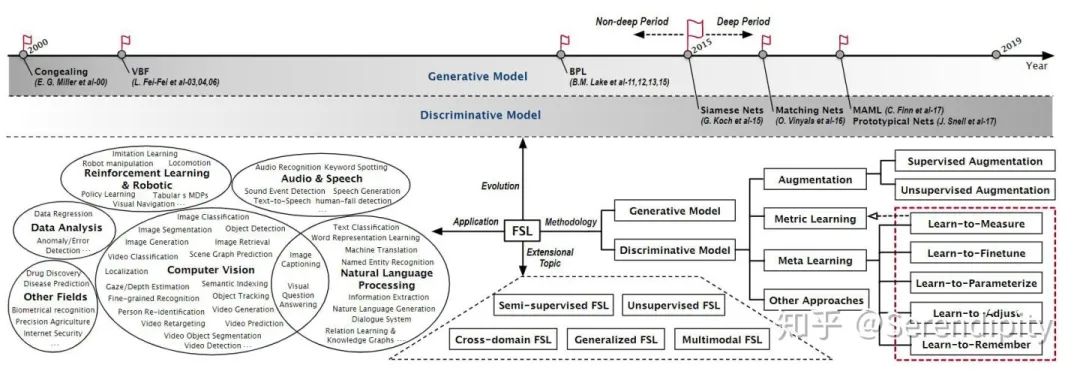
03
相关符号定义
来表示输入数据, 来表示监督信息,  和
和  分别表示输入数据和监督信息的空间。
分别表示输入数据和监督信息的空间。

 的样本
的样本  来自一个特定的域
来自一个特定的域  ,由数据空间
,由数据空间  和边际概率分布
和边际概率分布  组成。
组成。 中有
中有  个任务类,每个类只有
个任务类,每个类只有  (非常小,例如1、5)个样本,即
(非常小,例如1、5)个样本,即  =
=  ,这也称为C-way,K-shot任务。目的是产生一个目标预测函数
,这也称为C-way,K-shot任务。目的是产生一个目标预测函数  ,该函数可以对
,该函数可以对  中的待预测样本进行预测。根据之前的分析,很难用少量的 建立高质量的模型。
中的待预测样本进行预测。根据之前的分析,很难用少量的 建立高质量的模型。
 中包括足够的类别和归属该类别的根据以往的经验收集的样本
中包括足够的类别和归属该类别的根据以往的经验收集的样本  中不包含任务 中的样本类别。即,
中不包含任务 中的样本类别。即,  ,但 和
,但 和  中的数据都来自同一领域,也就是说,
中的数据都来自同一领域,也就是说, 相关的历史数据,包括离线或公开标记的数据中获取我们需要的辅助数据集 ,尤其是在当今的大数据时代。
相关的历史数据,包括离线或公开标记的数据中获取我们需要的辅助数据集 ,尤其是在当今的大数据时代。04
什么是模型并行?FSL问题定义
的包含少量可用的有监督信息的数据集 和与 不相关的辅助数据集 ,小样样本学习的目标是为任务 构建函数 ,该任务的完成利用了 中很少的监督信息和 中的知识,完成将输入映射到目标的任务。 不相关的术语表示 和 中的类别是正交的,即  。如果 覆盖了 中的任务,即
。如果 覆盖了 中的任务,即  ,则FSL问题将崩溃为传统的大样本学习问题。 中包含一部分无标签数据,或者
,则FSL问题将崩溃为传统的大样本学习问题。 中包含一部分无标签数据,或者  的情况。
的情况。05
两类FSL方法的区别与联系
或者条件概率分布  作为预测的模型,即判别模型。判别方法关心的是对给定输入 ,应该预测什么样的输出 。
作为预测的模型,即判别模型。判别方法关心的是对给定输入 ,应该预测什么样的输出 。 ,然后求出后验概率分布 作为预测的模型,即生成模型。这里以朴素贝叶斯为例,我们要求的目标可以通过:
,然后求出后验概率分布 作为预测的模型,即生成模型。这里以朴素贝叶斯为例,我们要求的目标可以通过:


 称为条件概率(class-conditional probability),或称为“似然”(likelihood),
称为条件概率(class-conditional probability),或称为“似然”(likelihood),  称为先验(prior)概率。
称为先验(prior)概率。  是用于归一化的"证据"因子。对于给定样本 。证据因子 与类标记无关,因此估计 的问题就转化为如何基于训练数据来估计先验 和似然 。
是用于归一化的"证据"因子。对于给定样本 。证据因子 与类标记无关,因此估计 的问题就转化为如何基于训练数据来估计先验 和似然 。1)仅需要有限的样本。节省计算资源,需要的样本数量也少于生成模型。
2)能清晰的分辨出多类或某一类与其他类之间的差异特征,准确率往往较生成模型高。
3)由于直接学习
,而不需要求解类别条件概率,所以允许我们对输入进行抽象(比如降维、构造等),从而能够简化学习问题。2)没有生成模型的优点。
3)黑盒操作: 变量间的关系不清楚,不可视。
1)生成给出的是联合分布
,不仅能够由联合分布计算后验分布(反之则不行),还可以给出其他信息,比如可以使用 来计算边缘分布。如果一个输入样本的边缘分布很小的话,那么可以认为学习出的这个模型可能不太适合对这个样本进行分类,分类效果可能会不好,这也是所谓的异常值检测(outlier detection)。
来计算边缘分布。如果一个输入样本的边缘分布很小的话,那么可以认为学习出的这个模型可能不太适合对这个样本进行分类,分类效果可能会不好,这也是所谓的异常值检测(outlier detection)。2)生成模型收敛速度比较快,即当样本数量较多时,生成模型能更快地收敛于真实模型。
3)生成模型能够应付存在隐变量的情况,比如混合高斯模型就是含有隐变量的生成方法。
1)联合分布能够提供更多的信息,但也需要更多的样本和更多计算,尤其是为了更准确估计类别条件分布,需要增加样本的数目,而且类别条件概率的许多信息是我们做分类用不到,因而如果我们只需要做分类任务,就浪费了计算资源。
06
基于判别模型的方法
 ,在该标准下,相似样本对可以获得较高的相似度得分,而非相似对则获得较低的相似度得分。
,在该标准下,相似样本对可以获得较高的相似度得分,而非相似对则获得较低的相似度得分。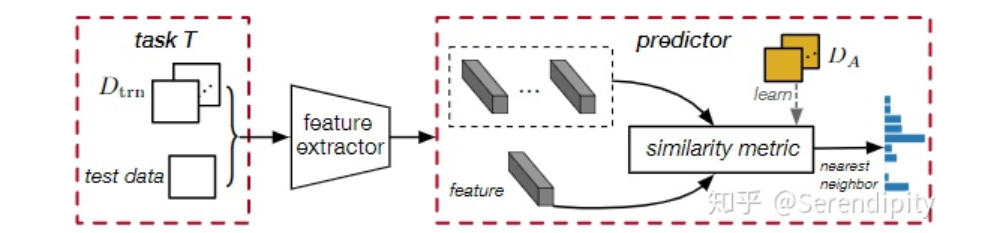
创建相似性度量并将其推广到任务 的新颖类中。相似度度量可以是简单的距离测量,复杂的网络或其他可行的模块或算法,只要它们可以估计样本或特征之间的相似度即可。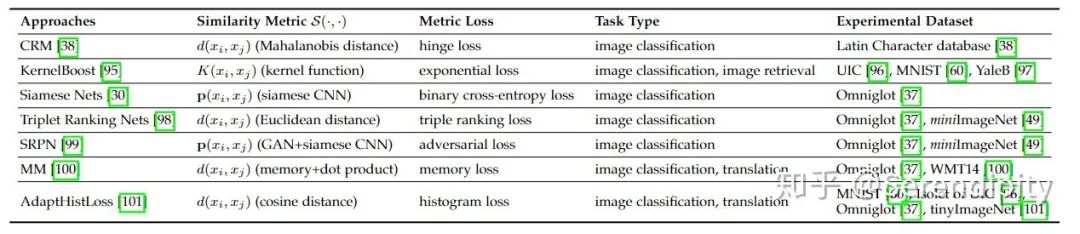
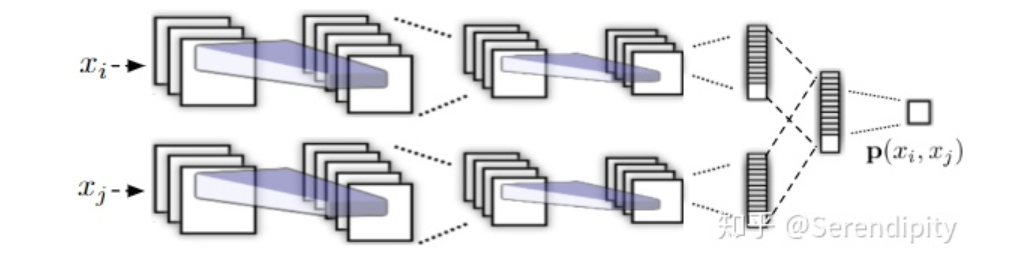
 作为输入,并且将它们在顶层的输出进行计算,以输出单个成对相似度
作为输入,并且将它们在顶层的输出进行计算,以输出单个成对相似度 。
。
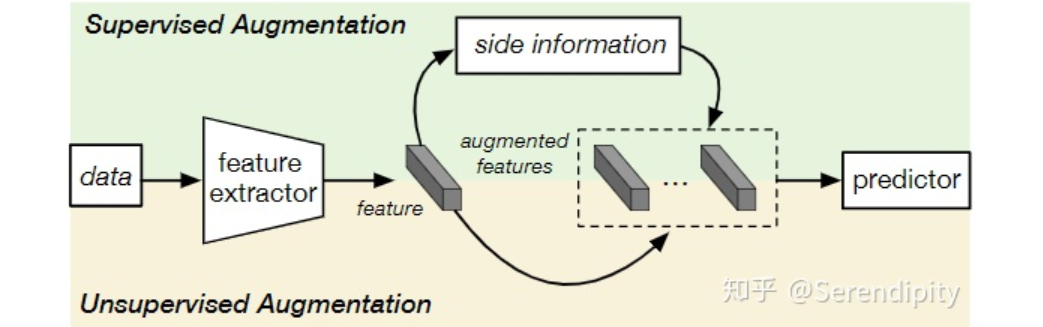
中训练样本的特征级增强。根据数据的扩充是否依赖于外部信息(例如语义属性,词向量属性等),可以将现有的基于扩充的FSL方法进一步分为有监督和无监督两类。 为特征空间,
为特征空间,  为辅助信息空间。通过这些方法学习到的扩增
为辅助信息空间。通过这些方法学习到的扩增  本质上是 与 之间的映射关系,尽管它们在映射方向和映射模块上有所不同,总结如下图所示。
本质上是 与 之间的映射关系,尽管它们在映射方向和映射模块上有所不同,总结如下图所示。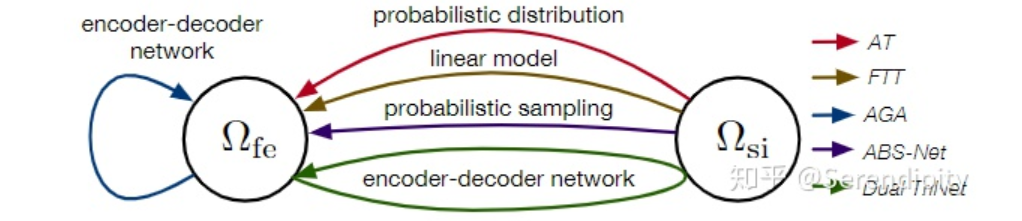
,然后通过其他FSL方法学习增强的  .
.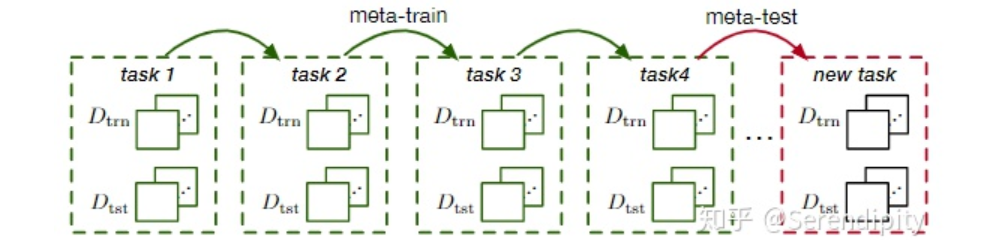
构建的监督任务  中,以学习如何适应未来的相关任务。
中,以学习如何适应未来的相关任务。  定义任务分配,这表明所有任务都来 自并遵循相同的任务范式,例如,所有任务都是C-ways,K-shot问题。
定义任务分配,这表明所有任务都来 自并遵循相同的任务范式,例如,所有任务都是C-ways,K-shot问题。 上测试,其元测试标签空间与元训练期间的标签空间不相交。
上测试,其元测试标签空间与元训练期间的标签空间不相交。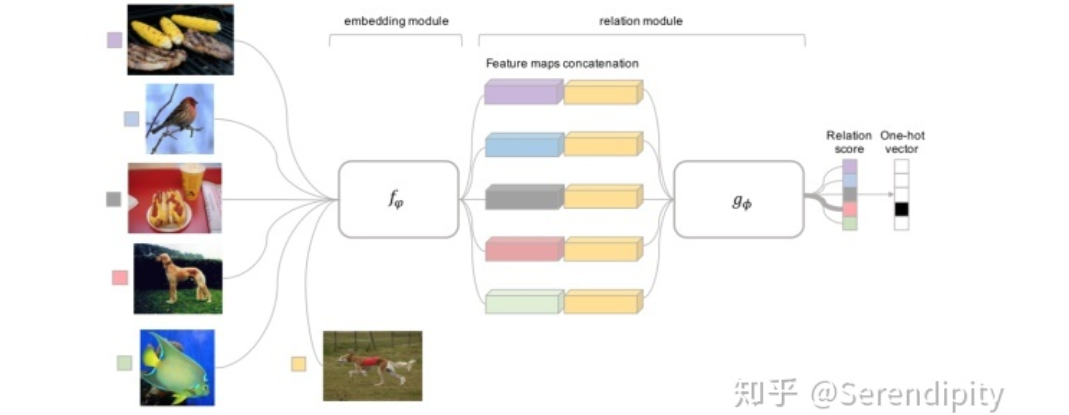
 ,也就是sample set和query set来模拟测试时的support set和testing set。我们可以使用训练集来生成巨量的模拟任务,从而在meta层面上训练整个关系网络。随后,我们在运用数据集
,也就是sample set和query set来模拟测试时的support set和testing set。我们可以使用训练集来生成巨量的模拟任务,从而在meta层面上训练整个关系网络。随后,我们在运用数据集  来对网络进行调整,以期待让其实现小样本学习的任务,在少量数据集 上实现准确分类。元学习的目标就是通过学习大量的任务,从而学习到内在的元知识,从而能够快速的处理新的同类任务,这和少样本学习的目标设定是一样的。
来对网络进行调整,以期待让其实现小样本学习的任务,在少量数据集 上实现准确分类。元学习的目标就是通过学习大量的任务,从而学习到内在的元知识,从而能够快速的处理新的同类任务,这和少样本学习的目标设定是一样的。07
总结
使学习系统能够从少量样本中学习,对于机器学习和人工智能的进一步发展至关重要,本文对小样本学习(FSL)的概念、原理和方法进行了简要的解释,并且将FSL方法进行了归类解释,随后会更新一些关于文中谈到的FSL方法和相关原理解释。
PS:感谢 @白小鱼 @Curry @鱼遇雨欲语与余 三位大佬的答疑解惑,对萌新异常友善
本文学习笔记参考文献:
https://arxiv.org/pdf/2009.02653.pdf
评论