一定要看完,一定要看完,一定要看完,重要的事情说三遍!!!首先申明本人并不是在研究这个领域有着深入研究的“专家”,如果文中有讲解不对的地方,还请各位大佬留言批评指正。当我看完 《Generalizing from a few examples: A survey on few-shot learning》 这篇文章的时候,我对于机器学习又有了一种新的认知,与其说它让我理解了什么是Few-shot learning,不如说它让我明白了如何更好地处理机器学习问题,不论是科研还是在实际应用当中(可以说是所有其它模型算法),都可以从文章指出的三个角度去考虑:数据、模型、算法。有人也许会说,是个人都知道从这三个角度去入手,问题是怎么样从这三个角度入手,依据是什么,做什么改进,文章对于少样本场景下解释的非常清晰,我认为思考问题的思维方式和角度很重要!!!
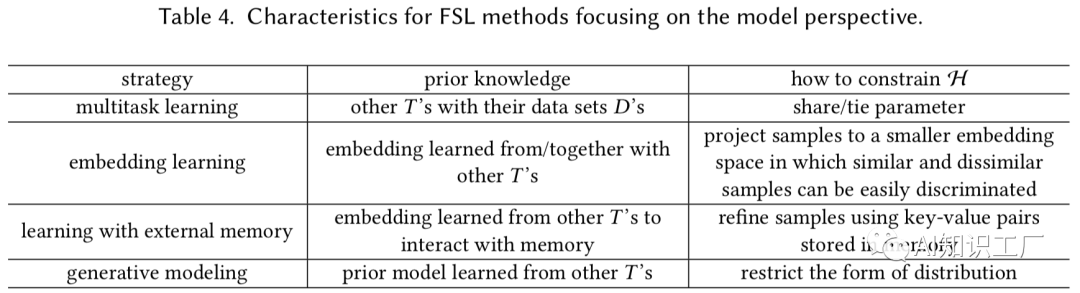
Task-Invariant Embedding Model则是先在大规模相似数据集中学习一个通用的embeddingfunction,然后在测试的时候直接用于当前任务的训练集(few shot training set)和测试集(test example set)嵌入,并做相似性判别。代表网络有Match network。
Hybrid Embedding Model
尽管Task-Invariant Embedding Model可以应用于新任务,且计算成本较低,但它们不利用当前任务的特定知识,并且当特定任务的样本非常少的时候,只利用Task-Invariant Embedding不太合适。为了缓解这个问题,混合嵌入模型(Hybrid Embedding Model)通过中的特定于任务的信息来适应从先验知识中学到的通用Task-Invariant Embedding Model,并通过学习将中提取的信息作为输入并返回一个embedding来作为embedding function f函数的参数。
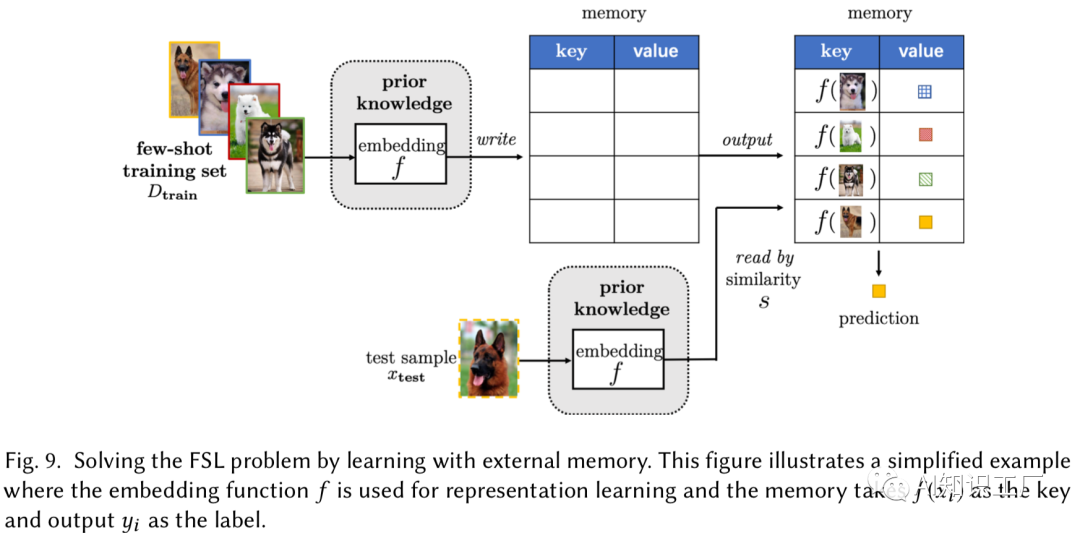
3. Learning with External Memory Learning with External Memory是从训练样本 中提取知识,并存储在外记忆中(在这里就是在一个用大量类似的数据训练的具有外部存储机制的网络上,用具体task的样本来更新外部记忆库)。每个新的样本,用从内存中提取的内容进行加权平均表示,然后将其用作简单分类器(例如softmax函数)的输入进行预测。这就限制了 只能用内存中的内容来表示,因此从本质上减少了假设空间的大小。由于每个都被定义为从内存中提取的值的加权平均值,因此内存中key-value对的质量很重要。
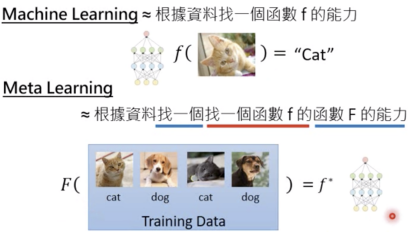
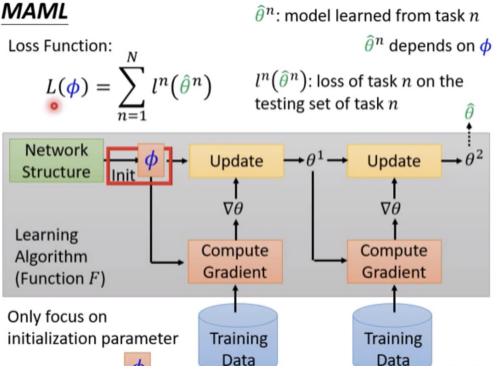
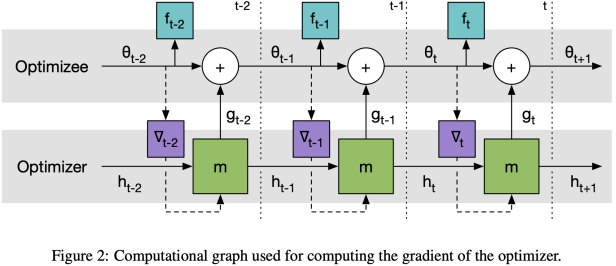
总 结 文章在少样本情况下,对于如何利用先验知识,找到假设空间中的最优解,训练出一个好的模型的方法描述的很清楚、很清晰,是值得反复品味的综述性好文。文章根据机器学习误差理论,先后从数据、模型、算法三个角度进行不同层次的先验知识嵌入,总体上来说就是如何利用相似且较大的数据集,如何初始化一个好的模型参数,以及如何找到一个好的优化策略,不光是在few shot learning 领域内可以这样思考,其实我们在实际科研和工作中遇到类似的问题,也可以从这三个方面去考虑,就拿我们非常熟悉的BERT预训练语言模型,难道不就是这个道理吗?参考文献[1] Wang, Yaqing, et al. "Generalizing from a few examples: A survey on few-shot learning." ACM Computing Surveys (CSUR) 53.3 (2020): 1-34.[2] https://www.cnblogs.com/jiangxinyang/p/12163215.html FSL(小样本学习)综述[3] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//International Conference on Machine Learning. PMLR, 2017: 1126-1135.[4] Andrychowicz, Marcin, et al. "Learning to learn by gradient descent by gradient descent." arXiv preprint arXiv:1606.04474 (2016).
[5] https://blog.csdn.net/senius/article/details/84483329 Learning to learn by gradient descent by gradient descent - PyTorch实践

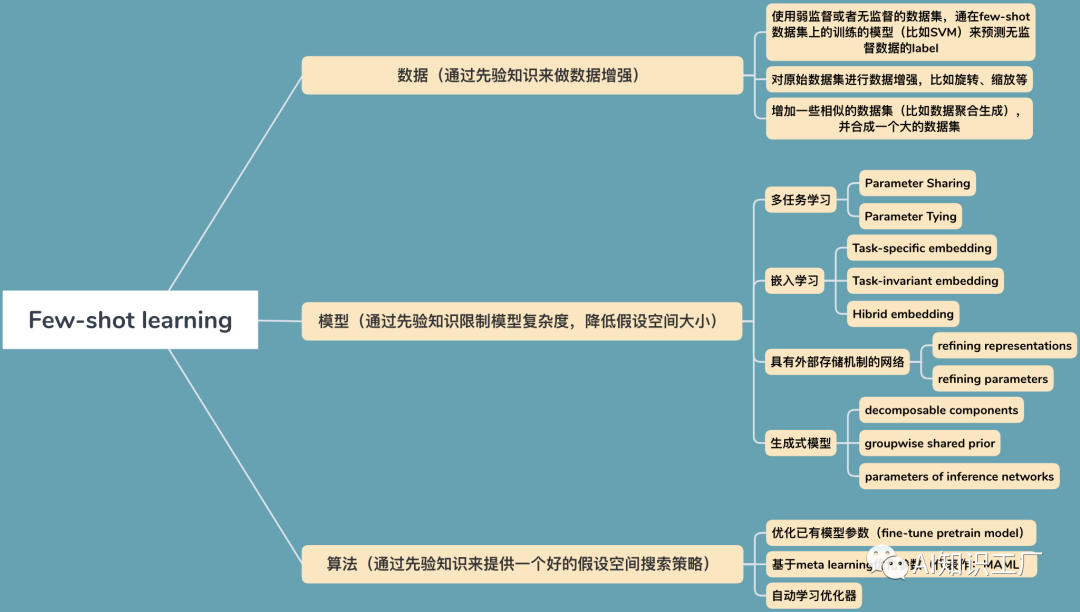
 什么是Few-shot learning
什么是Few-shot learning 
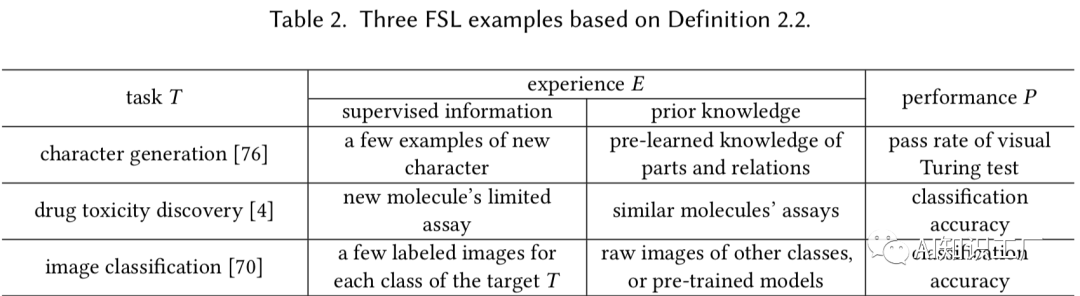
 核 心 问 题
核 心 问 题 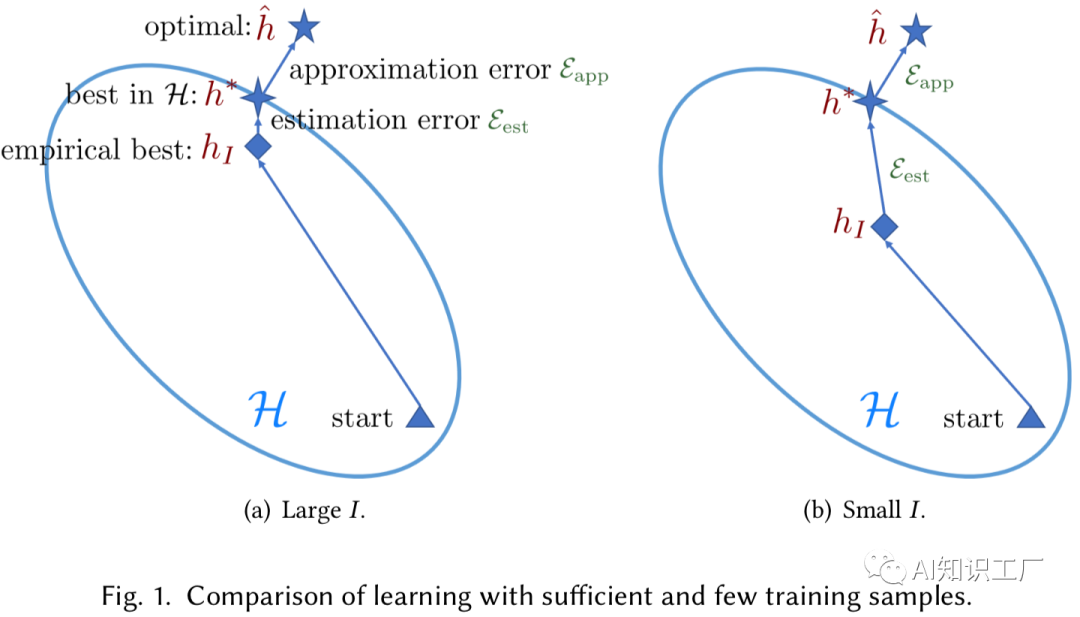
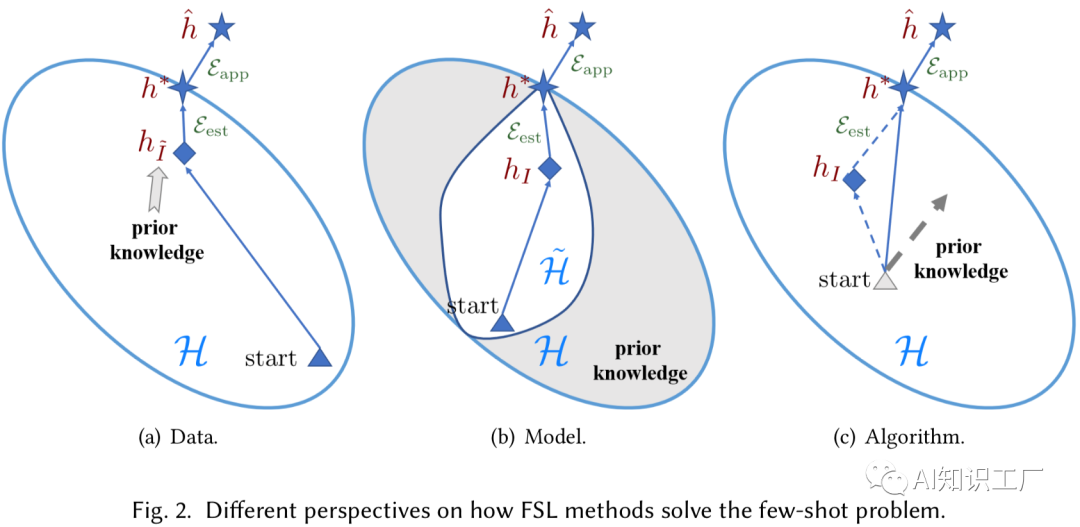
 解 决 方 法
解 决 方 法 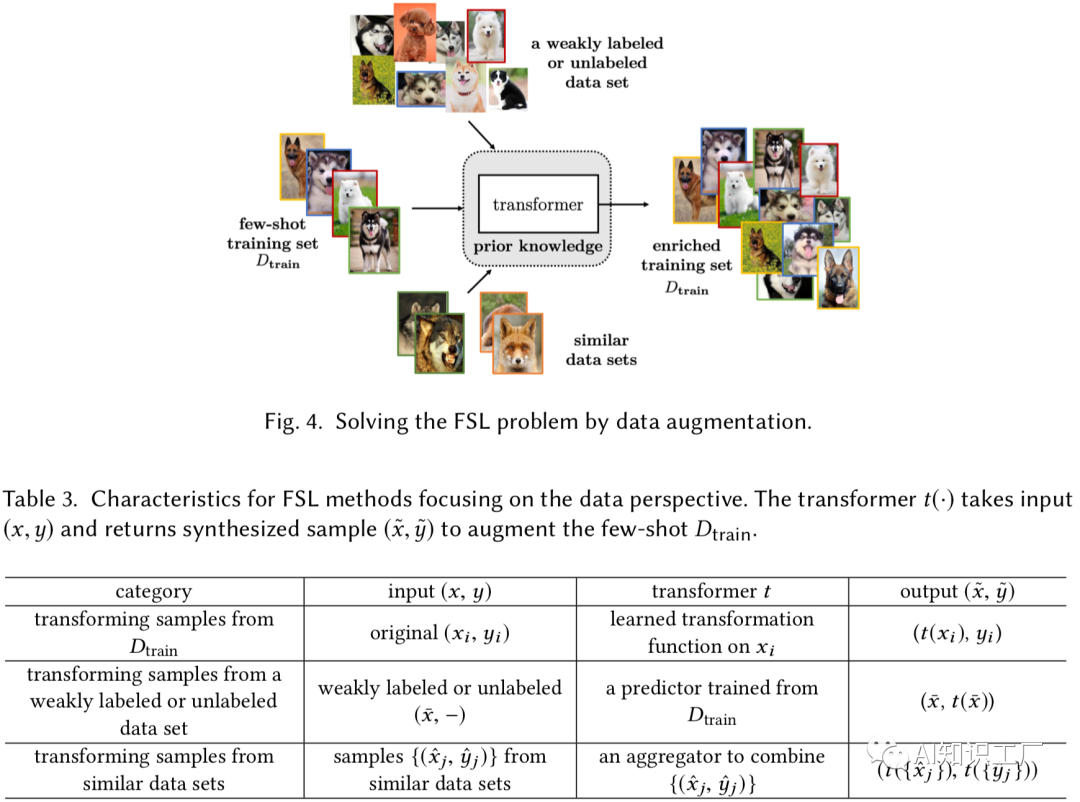
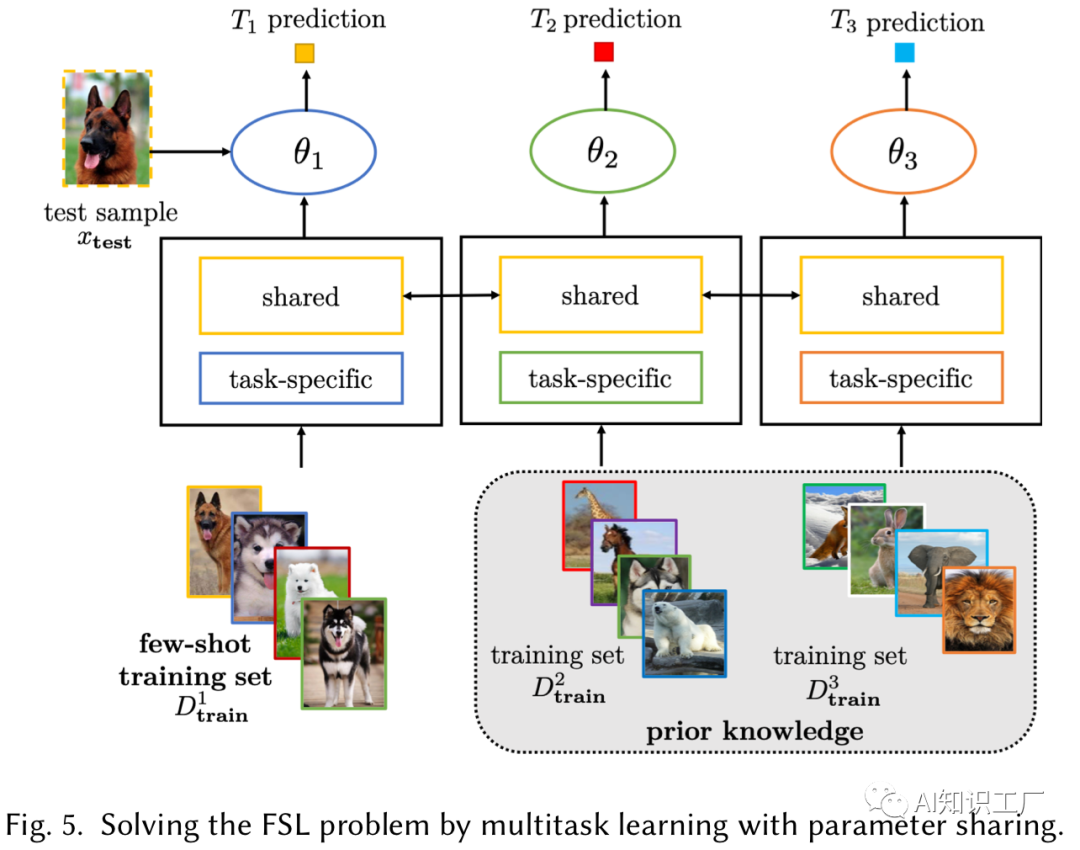
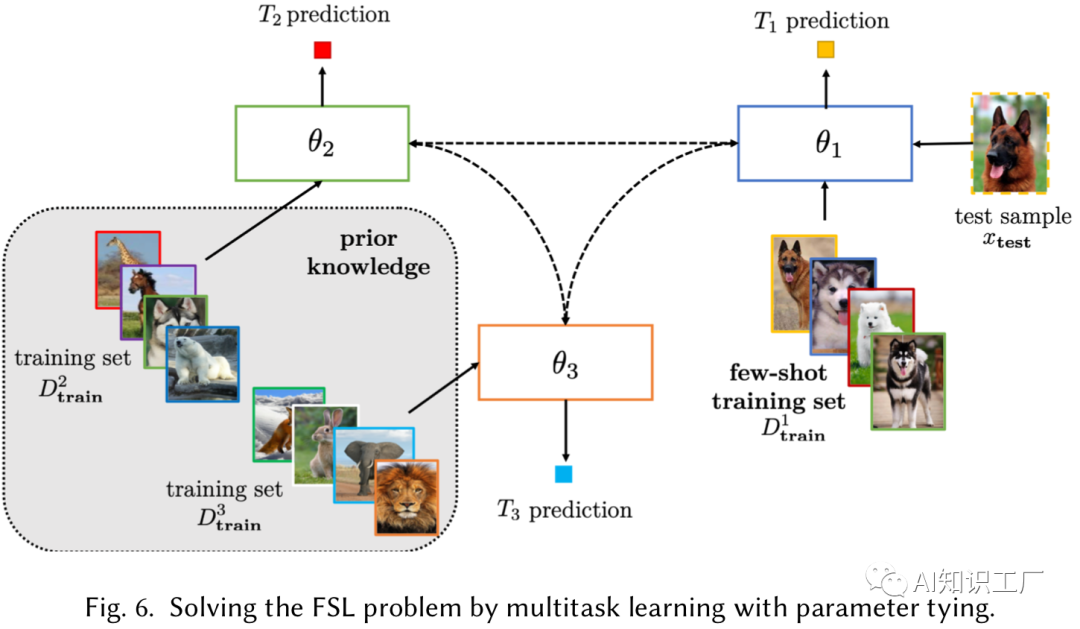
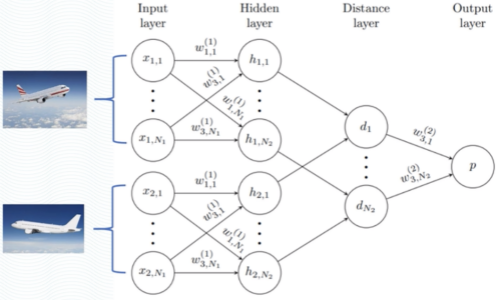
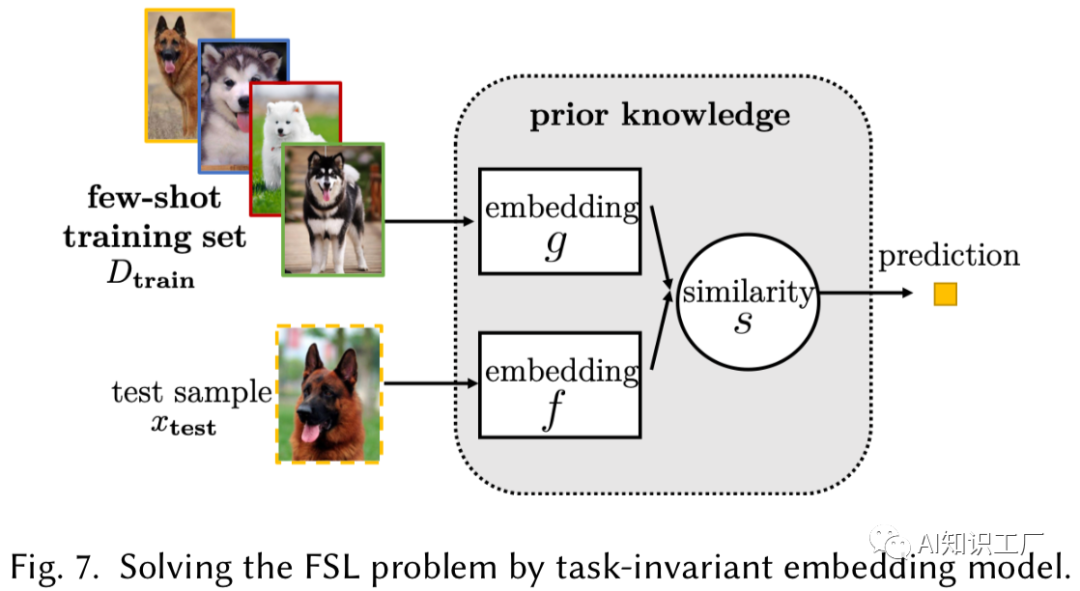
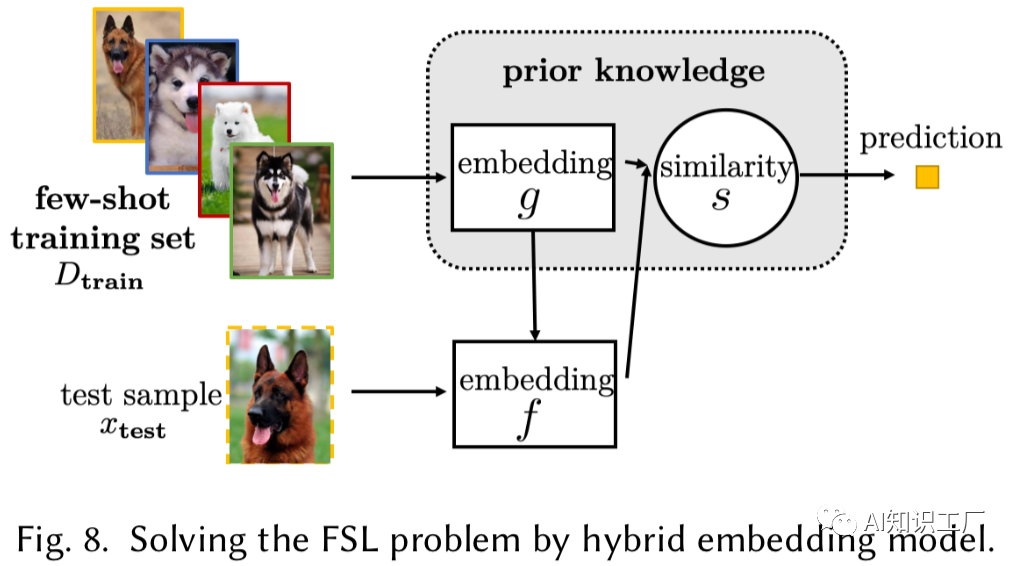
 总 结
总 结