
零样本学习 Zero-Shot Learning 入门
上一篇介绍了零样本学习的基本概念,本篇来谈谈基本方法和面临的挑战。首先通过一个示例对零样本学习问题有个更具体的认识,然后了解一下两类基本方法,最后谈谈零样本学习问题中遇到的一些挑战。有了这些内容,相信对零样本学习会有一个较完整的初步印象,为深入理解更多算法细节做好准备。
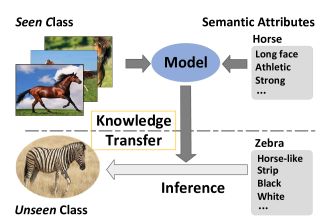
首先看一下零样本学习涉及的主要数据,
1、已知类:模型训练时用到的带类别标签的图像。 2、未知类:模型测试、训练时不知道类别标签的图像。 3、辅助信息:对已知类和未知类图像的描述/语义属性/词嵌入等信息。该信息充当了已知类和未知类之间的桥梁。
已知类和未知类是针对模型来说的,已知类表示模型在训练时是知道的,用到了它的图像和类别标签;模型训练时没有用到未知类数据或者用到了图像但不涉及它的类别(否则就没有模型什么事了!)。
1举例说明
先来看一个具体的数据样例 (图像, 标签, 语义属性),
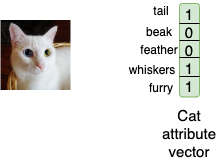
在图 1. 展示的例子中,图像为 cat,辅助信息
请注意,在本文中,我们将此向量 cat,dog 等。
同样,
组织一下,可以写成,
上面的表达式意思为: 已知类数据的集合由图像
另外还有由
其中,
2两类基本方法
本文主要介绍两种基本方法: 基于嵌入的方法和基于生成模型的方法。
〄基于嵌入的方法
基于嵌入的方法的主要目标是使用投影函数将图像特征和语义属性映射到一个公共的嵌入空间,该投影函数是使用深度网络学习的。共同的嵌入空间可以是视觉特征空间、语义空间或重新学习的中介空间。
大多数基于嵌入的方法都使用语义空间作为公共嵌入空间。在训练期间,目标是使用来自已知类的数据学习从视觉空间(即图像特征)到语义空间(即词向量/语义嵌入)的投影函数。由于神经网络可以用作函数逼近器,因此投影函数自然可以选用深度网络来学习。
在测试阶段,将未知类图像特征输入到前面训练好的网络里,获得相应的语义嵌入。然后在语义属性空间中进行最近邻搜索,以找到与网络输出最接近的匹配项。最后,将与最接近的语义嵌入相对应的标签预测为输入图像特征的输出标签。
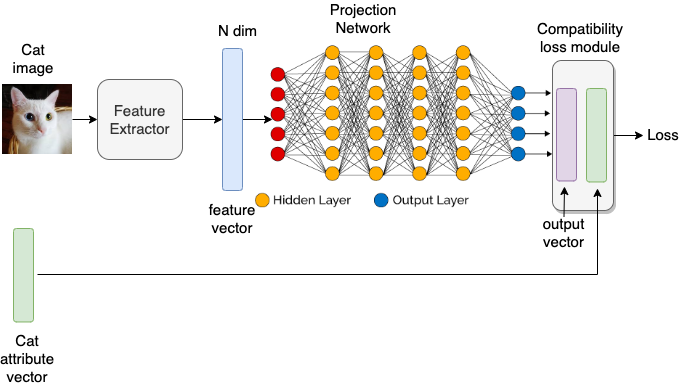
图 2. 展示的是基于嵌入的零样本学习方法的流程框图。首先将输入图像通过特征提取器网络(通常是深度神经网络),以获取图像的 N 维特征向量。此特征向量充当我们主投影网络的输入,而主投影网络又输出 D 维输出向量。目的是学习投影网络的权重/参数,以便从视觉空间中的 N 维输入映射到语义空间中的 D 维输出。损失函数用于度量 D 维输出与真实语义属性之间的误差。然后就是训练网络的权重,使 D 维输出尽可能接近真实语义属性。
〄基于生成模型的方法
基于嵌入的方法的主要缺点是它们存在偏差和域移位的问题。这意味着,由于投影函数是在训练期间仅使用已知类学习得来的,因此它将偏向于将已知类标签作为输出进行预测。另外,也不能保证学习的投影函数会在测试时正确地将未知类图像特征正确地映射到相应的语义空间。这是由于这样一个事实,即深度网络仅在训练过程中学会了将已知类的图像特征映射到语义空间,并且可能无法在测试时对新颖的未知类正确地执行相同的操作。
为了克服这个缺点,有必要让零样本分类器在已知类和未知类的所有图像上训练。由此引出基于生成模型的方法。生成方法旨在为未知类使用语义属性生成图像特征。一般是用一个条件生成对抗网络来实现的,该条件生成对抗网络生成以特定类的语义属性为条件的图像特征。
图 3. 显示了一个典型的基于生成模型的零样本学习方法的框图。与基于嵌入的方法类似,我们使用特征提取网络获取 N 维特征向量。首先,将属性向量输入到生成模型中,生成器生成一个以属性向量为条件的 N 维输出向量。训练生成模型,使合成特征向量尽量逼近原始 N 维特征向量。
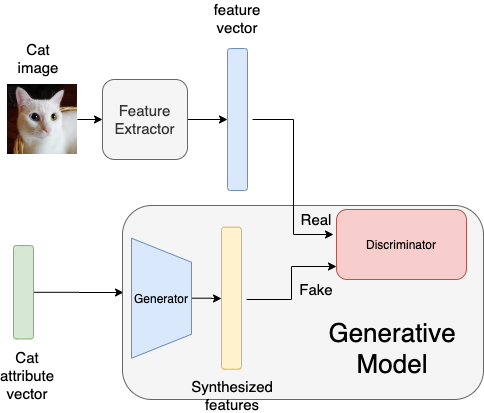
一旦训练好生成模型,我们将冻结生成器的参数,并将未知类的属性向量输入生成模型,以生成未知类的图像特征。现在,由于我们有了已知类的图像特征(从数据集中)和未知类的图像特征(由生成器生成),我们可以训练一个简单的分类器,该分类器将图像特征作为输入并输出相应的类别标签,如图 4. 所示。
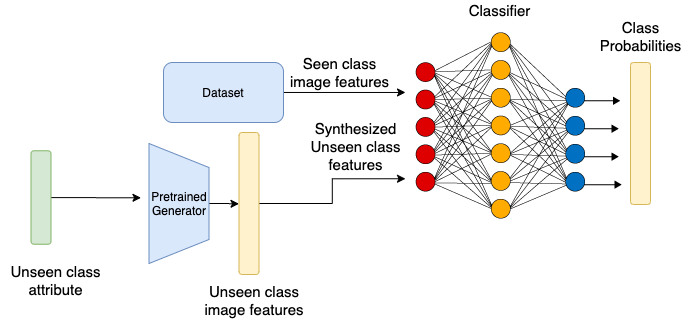
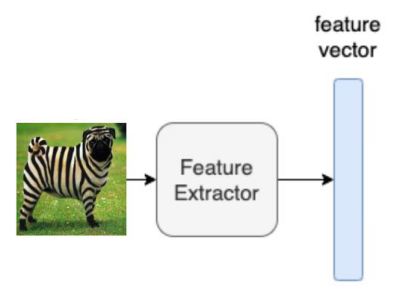
那么问题来了,当给模型输入一张未知类的图像,模型如何判断它的类别呢?根据刚才这个分类器,得让模型知道图像的特征向量才能分类。而生成网络是输入属性向量,输出图像特征,因此是反方向的。那么如何得到图像的特征向量呢?我们往回看,可以发现在图 3. 中有一个特征提取网络。对,就是它了,如图 5. 所示。
〄小结
拿到一张图像,模型怎么分类?可以想办法提取出图像的语义向量或者视觉特征向量,分别对应上面的两种方法: 基于嵌入的方法和基于生成模型的方法。
有了语义向量,第一种方法在语义空间用最近邻搜索答案,但是这个语义空间来自已知类,所以对于识别未知类效果如何会打一个问号。
有了生成模型生成的视觉特征向量,第二种方法再训练一个根据视觉特征的分类器。那么问题来了,这种方法会有什么问题呢?比如,已知类有很多图像,都具有可见的图像特征,而对于未知类来说却只有语义信息,那么会引发什么问题呢?
3算法性能评估指标
大多数图像识别模型都使用 Top-1 准确率作为评估指标。但是,用于零样本识别模型的评估方式与用于普通图像分类模型的评估方式不同。
为了评估零样本学习算法的性能,我们改用每类 Top-1 的平均准确率。用简单的话来说,这意味着我们分别找到每个类别的识别准确率,然后在所有类别上取平均值。这样的做法就兼顾了稀疏类和密集类。数学上,对于具有 N 个类的一个类别集合
在广义零样本学习的情况下,我们的目标是在 已知类
4零样本学习的挑战
为了更深入地理解零样本学习的各类方法,需要了解零样本学习到底有哪些挑战性问题。这些挑战在决定模型的性能时起着重要作用。也只有弄清楚了问题所在,才能更好地挑选、使用甚至推动零样本学习方法。
〄域漂移
简而言之,域偏移是指训练数据和测试数据分别来自两个不同分布引起的问题。这个问题在零样本学习中始终发挥重要作用,模型训练时遇到的已知类的分布与模型测试时遇到的未知类的分布并不相同。由于我们的深层网络在训练期间仅使用已知类来学习,因此在测试时如果碰到来自训练数据的分布以外的未知类的话,模型的性能可能会很差。
举个夸张一点的例子,如训练集里面全是动物,而测试集里面全是电子产品,可想而知,这种情况让零样本学习模型情何以堪。
〄偏见 Bias
在零样本学习中,模型在训练过程中只能访问已知类的 (图像, 标签) 对,而没有未知类的图像可用。这使得模型在测试时更倾向于将已知类作为预测结果,这点对模型来说似乎是与生俱来的。这很关键,尤其是对于广义 ZSL 来说,因为它允许测试图像可以是来自已知类或者未知类。由于模型偏向于已知类,因此它经常将未知类的图像错误地判断为已知类别之一,这显然会大大降低模型性能。
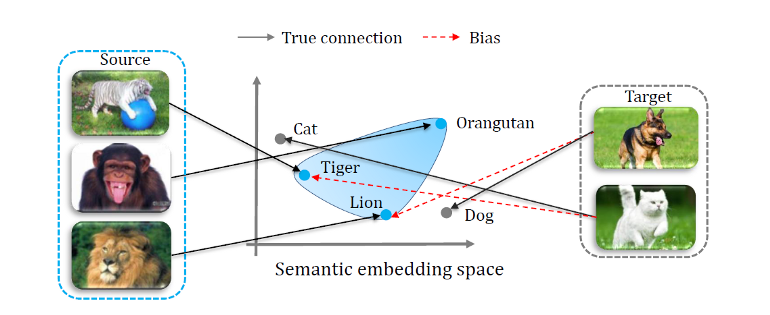
〄跨域知识迁移
在训练零样本学习模型时,已知类有视觉图像特征,而对于未知类则只有语义信息。但是,在测试时,我们需要从未知类中识别视觉特征。因此,模型在从语义空间到视觉空间的知识迁移方面的性能将在零样本学习中起到关键作用。
例如,让我们假设我们的模型在训练过程中看到了棕熊,但没有看到北极熊。在测试时,要识别北极熊,模型需要先将北极熊的白色毛皮属性变换到视觉特征空间中,然后将其与棕熊的视觉特征合并,以正确识别北极熊的图像。
〄语义损失
在训练时,模型在已知类上学习分类本领,某些属性/特征可能无法帮助其区分已知类而被忽视。但是在测试时,那些被忽略的特征可能有助于区分未知类。
让我们举一个例子来理解这一点。假设在训练时有两个类 – 男性和女性。我们的模型将寻找面部外观,身体结构等特征,以学会区分男女。两条腿这个属性没有帮助它区分男女这两类,因此它可能认为该属性并不重要。但是在测试时,如果未知类之一是狗,那么可想而知,腿的数量这一信息对于模型将其与已知类区分开是非常有用的。
但是,我们的模型已经学会了忽略有关腿数的特征,因为在训练时它并没有起作用。换句话说,模型在训练过程中经历了语义损失。
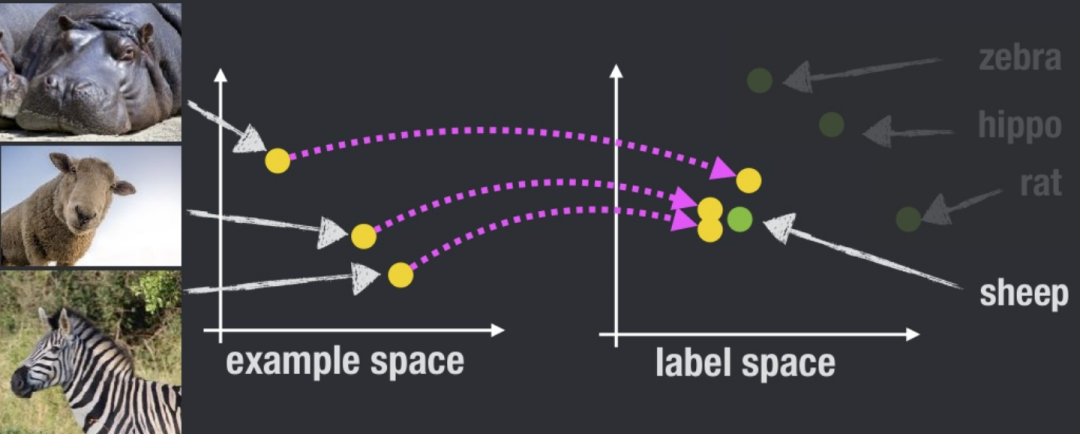
〄Hubness
当将高维向量投影到低维空间时,会出现中心性问题。这样的投影减少了方差,从而导致投影点聚集成中心点。
解决零样本识别问题的最常用方法之一是学习从高维视觉空间到低维语义空间的投影函数。然而,这会导致在语义空间中形成投影中心点,而这些中心点往往更接近于数量占比大的类的语义属性向量。由于在测试时,我们在语义空间中使用最近邻搜索来找到预测类别的,所以 Hubness 问题势必会降低模型的性能。
举个具体栗子,假设下图中的 sheep 是一个中心点,河马、绵羊和斑马的图像转化到语义空间后,搜索到的都是最邻近的 sheep。
总之,零样本学习是一个比较年轻的方向,有前景但面临的挑战也是很大的,弄不好很长时间内都不能发挥实用性。但是可挖掘的空间大,值得深入研究。
⟳参考资料⟲
Zero-Shot Learning: https://en.wikipedia.org/wiki/Zero-shot_learning
[2]Zero-Shot Learning via CCDGM: http://people.duke.edu/~ww107/material/ZSL.pdf
[3]零次学习 Zero-Shot Learning 入门: https://zhuanlan.zhihu.com/p/34656727
[4]Zero-Shot Learning 如何打破零起点的封印: https://www.tmtpost.com/3665596.html
[5]Zero-Shot Learning : An Introduction: https://www.learnopencv.com/zero-shot-learning-an-introduction/