
神经网络压缩方法:模型量化的概念简介

来源:DeepHub IMBA 本文约3200字,建议阅读6分钟
本文为你介绍如何使用量化的方法优化重型深度神经网络模型。
在过去的十年中,深度学习在解决许多以前被认为无法解决的问题方面发挥了重要作用,并且在某些任务上的准确性也与人类水平相当甚至超过了人类水平。如下图所示,更深的网络具有更高的准确度,这一点也被广泛接受并且证明。
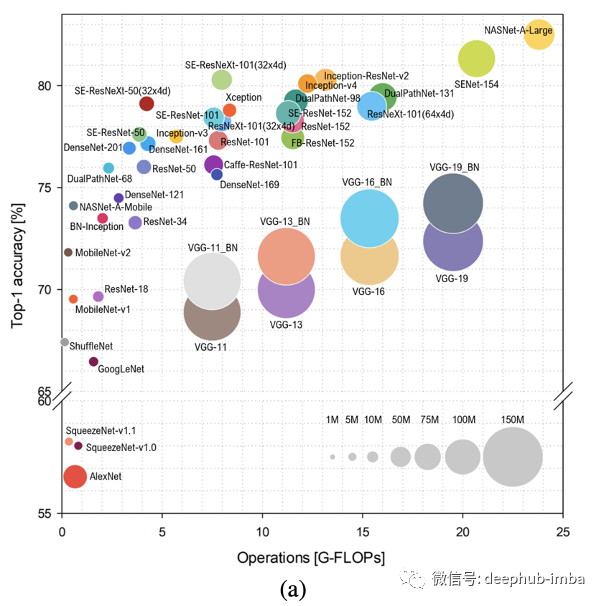
更长的推理时间 更高的计算要求 更长的训练时间
模型压缩方法
什么是量化?


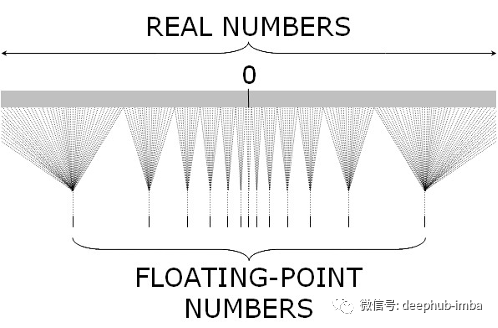
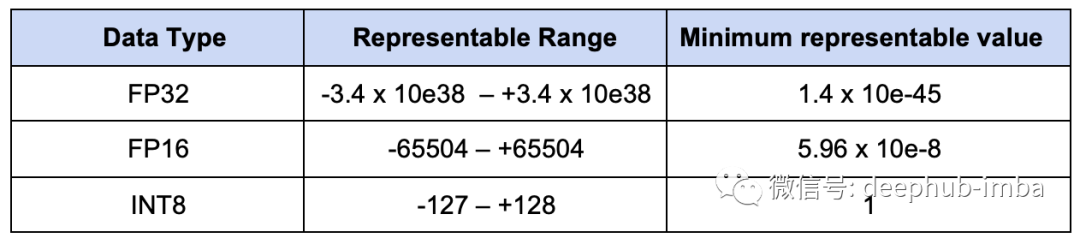
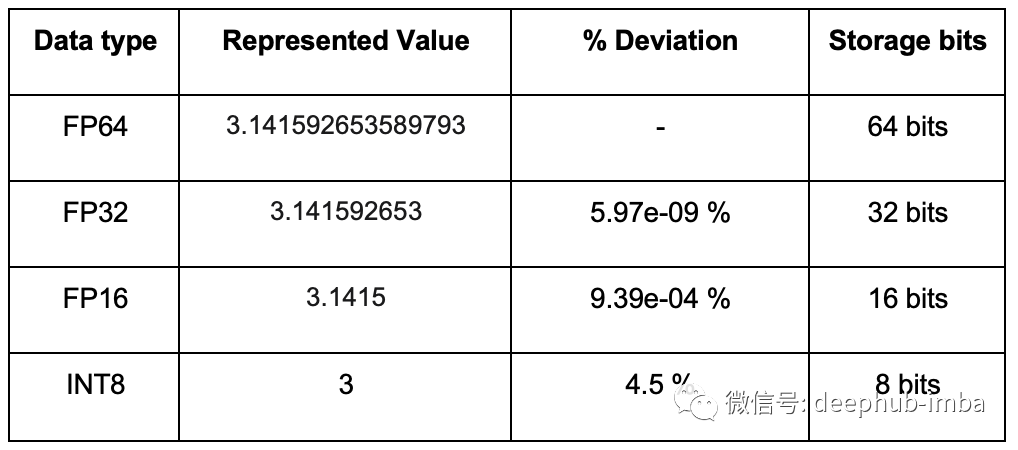
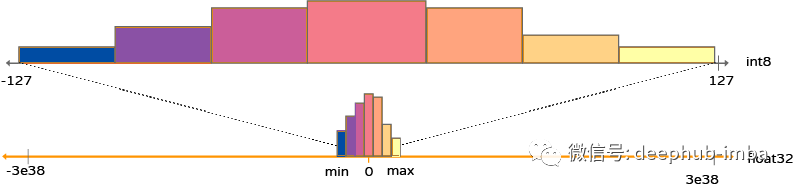


深度学习中的量化
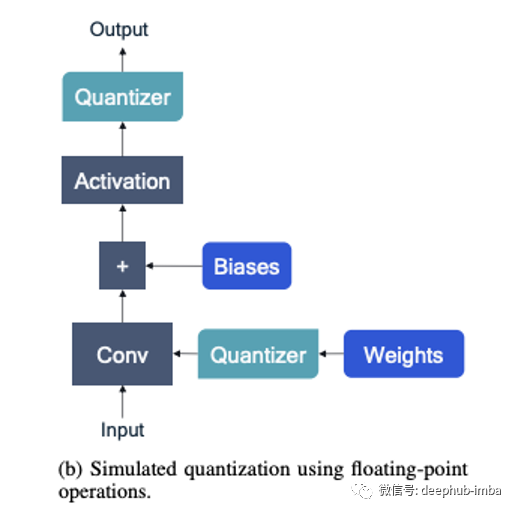
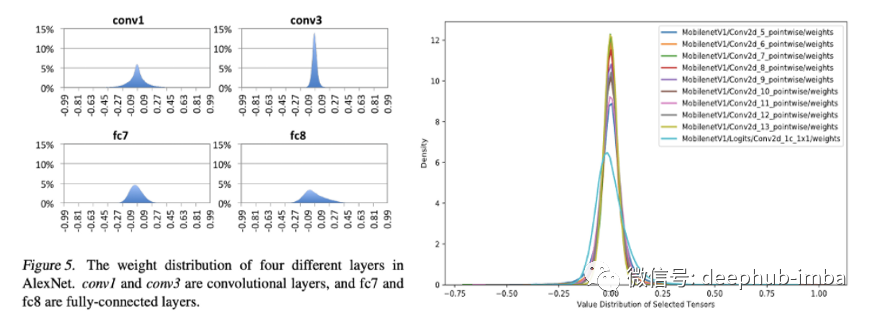
量化类型
训练后量化:在模型完全训练后执行 量化感知训练:训练是在量化约束下完成的



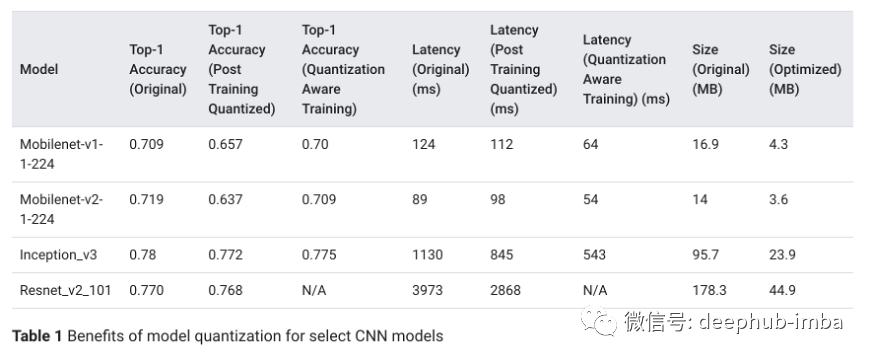
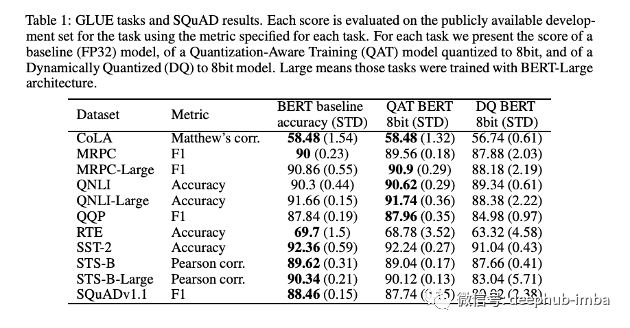
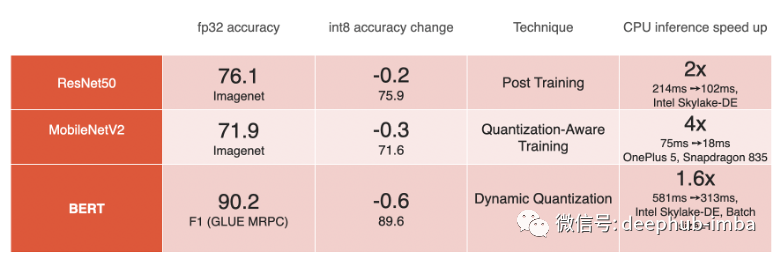
模型的基准测试
总结
评论