
【机器学习基础】从Few-shot Learning再次认识机器学习
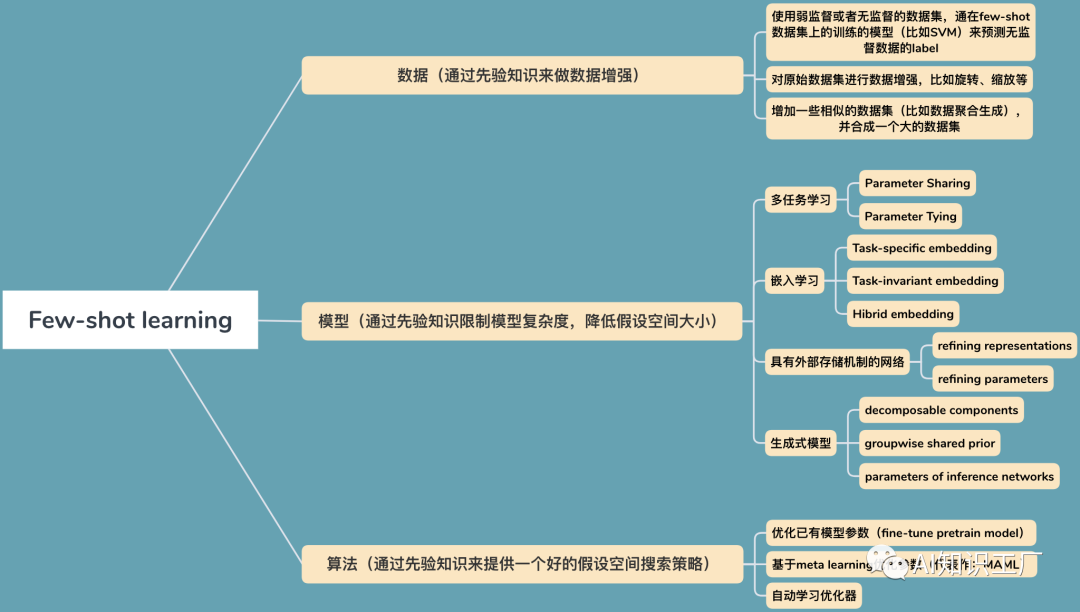
 什么是Few-shot learning
什么是Few-shot learning 
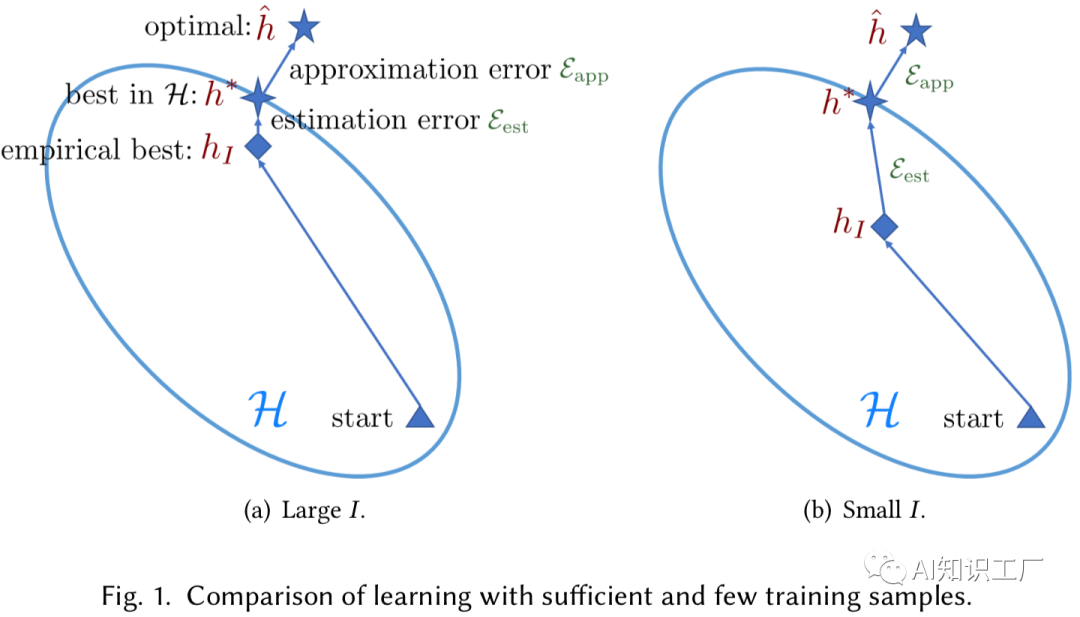
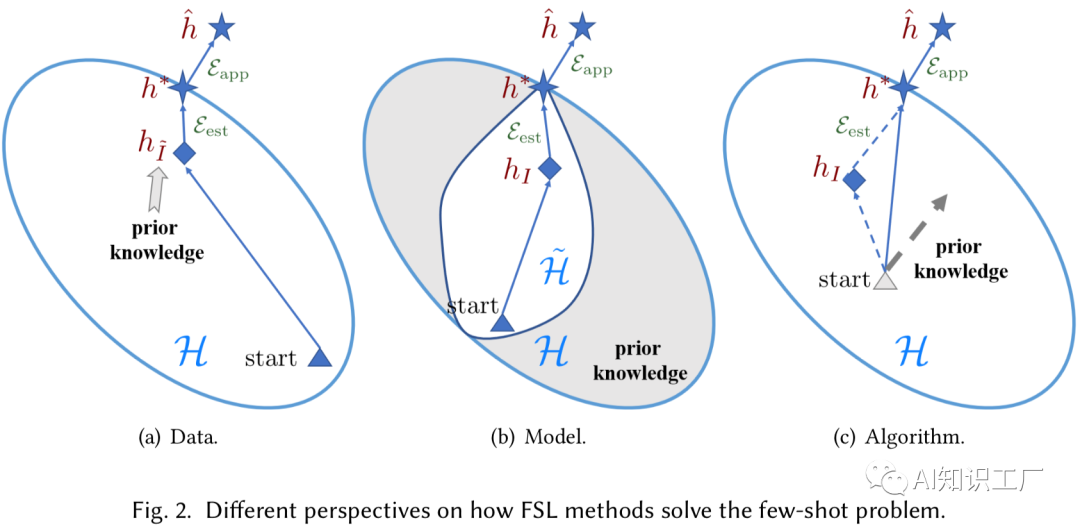
 核 心 问 题
核 心 问 题 是期望风险最小化的最优解,可以理解为百分百没有误差的解,不需要知道假设空间,同时已知所有的数据样本,显然,这个是办不到的。 是在假设空间 下期望风险最小化的最优解。显然,这个解相对于 存在一定的误差。 是在假设空间 下经验风险最小化的最优解。显然,这个解相对于 还存在一定的误差。
 解 决 方 法
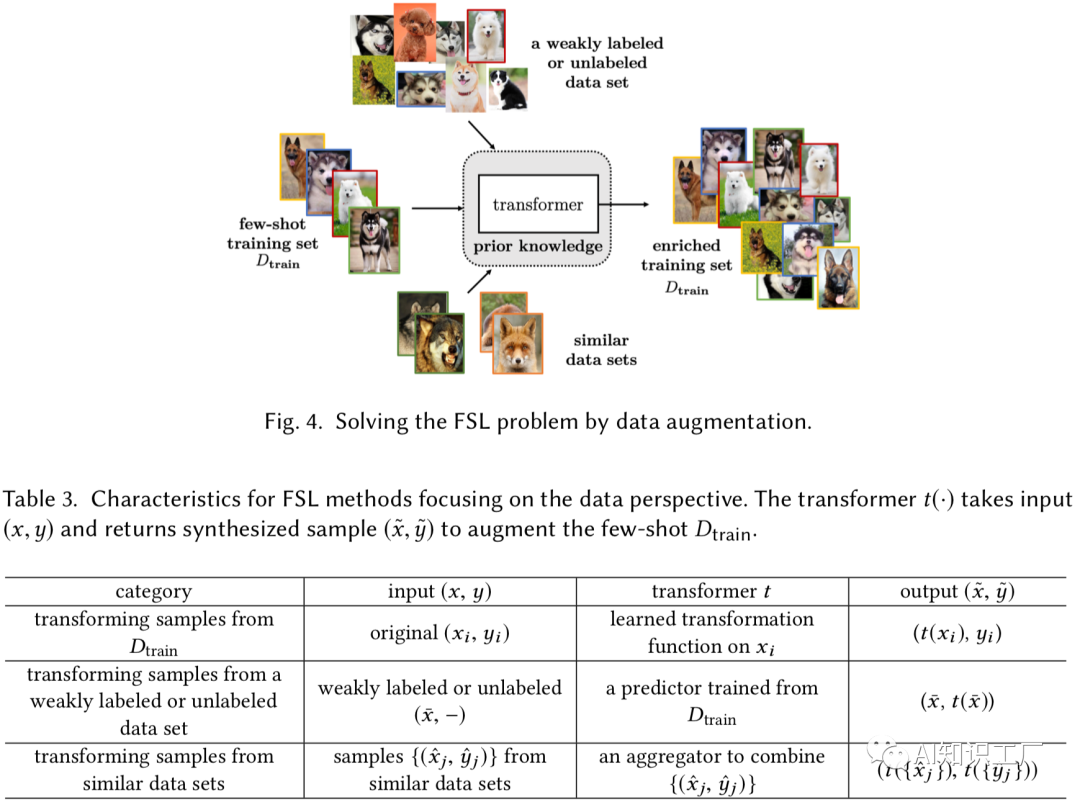
解 决 方 法 使用弱监督或者无监督的数据集
使用一些无监督或者弱监督的数据集,并在few data上training过的模型(比如SVM等简单的分类模型)进行预测,形成“有监督”的数据集,以此来扩充数据集。
对原始数据集进行数据增强
使用一些数据增强的手段,对数据进行扩增,比如图像的几何变换或者其它一些数据转换的方式用于数据增强等等。
增加一些相似的数据集(比如数据聚合生成)
该策略通过从相似但数量较大的数据集中聚合和调整输入-输出对来扩充数据集。聚合权值通常基于样本之间的某种相似性度量。
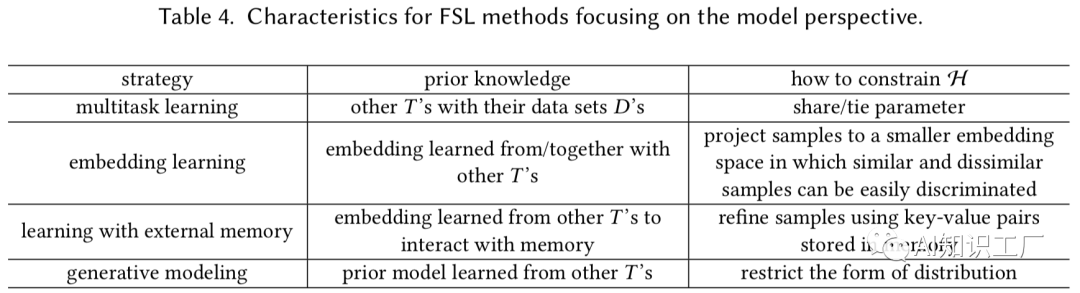
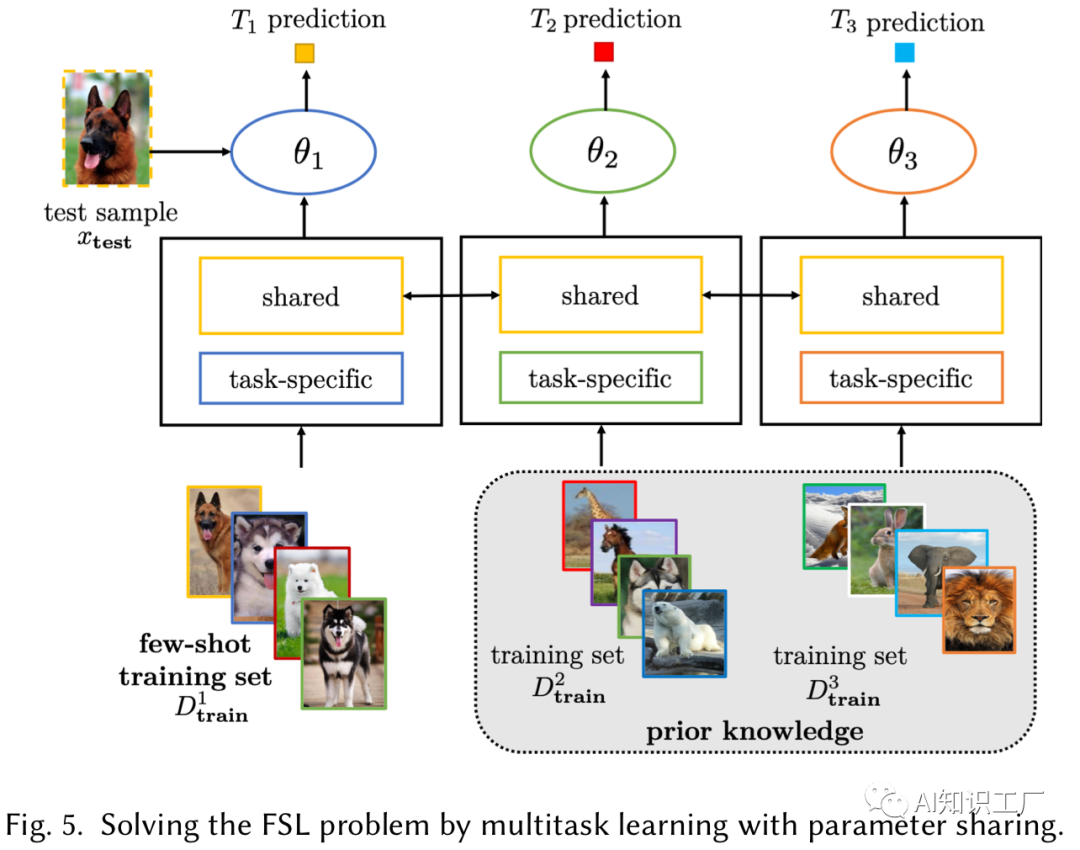
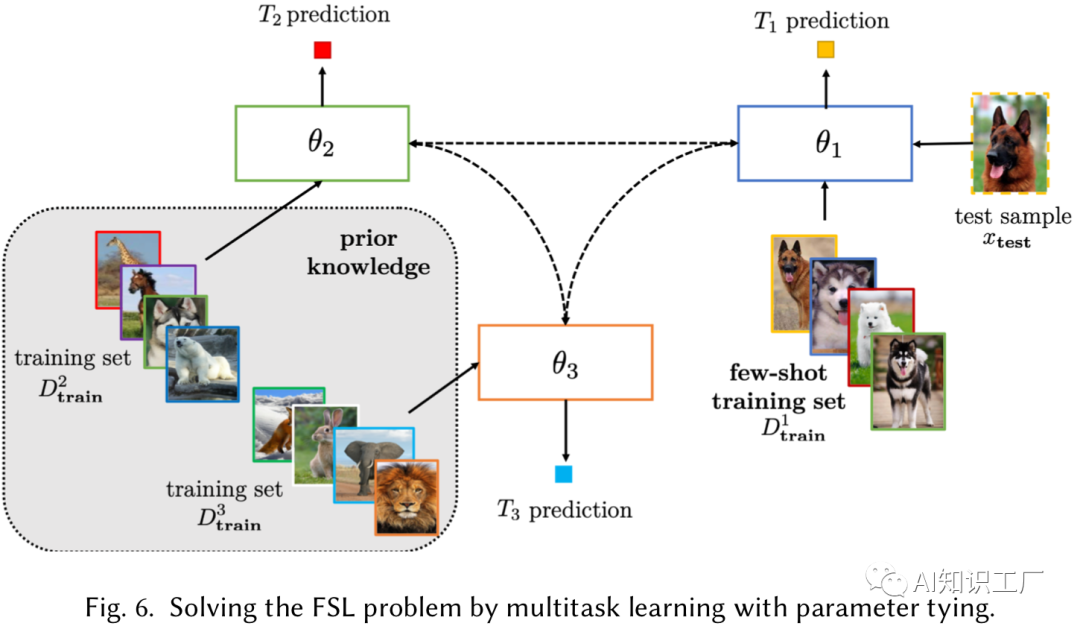
Parameter Sharing(可以是数据相同任务不同,也可以是数据和任务都不同,但是数据具有领域性等等)
例如利用同领域内的其它数据做task(通常这些数据会比较多),在做Multitask learning的时候,不同task之间共享相关层的参数,而在task-specific层和classification层对于特定的任务不做共享,这样做就能利用先验知识缩小假设空间。
Parameter Tying
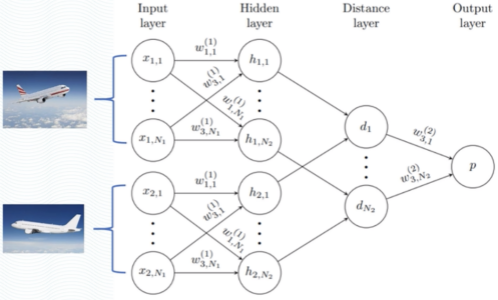
Task-Specific Embedding Model
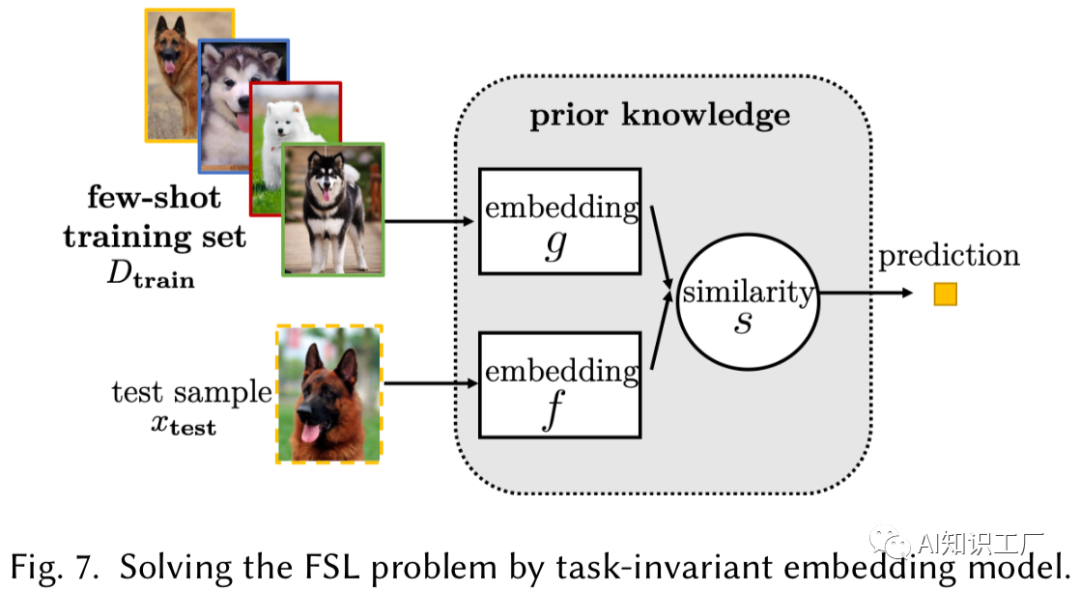
Task-Invariant Embedding Model
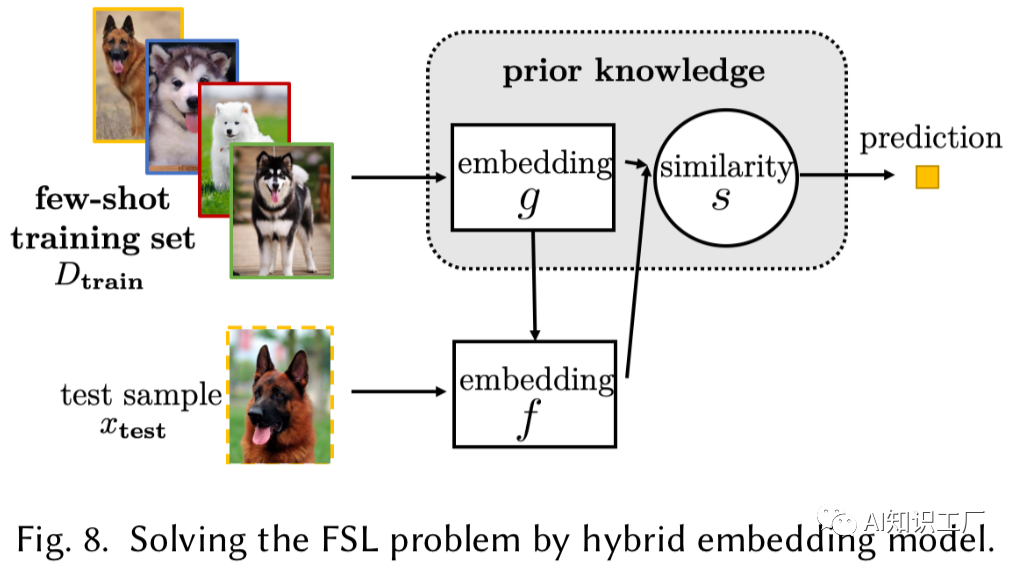
Hybrid Embedding Model
 总 结
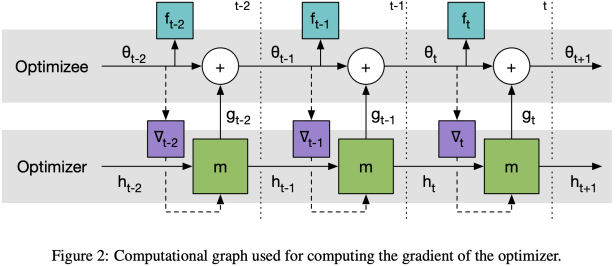
总 结 [5] https://blog.csdn.net/senius/article/details/84483329 Learning to learn by gradient descent by gradient descent - PyTorch实践
往期精彩回顾
本站qq群704220115,加入微信群请扫码:
评论