
Few-shot Learning 小白入门笔记
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

知乎作者受限玻尔兹曼机
https://zhuanlan.zhihu.com/p/396593319
编辑|人工智能前沿讲习
https://www.bilibili.com/video/BV1V44y1r7cx
01




02


03



04
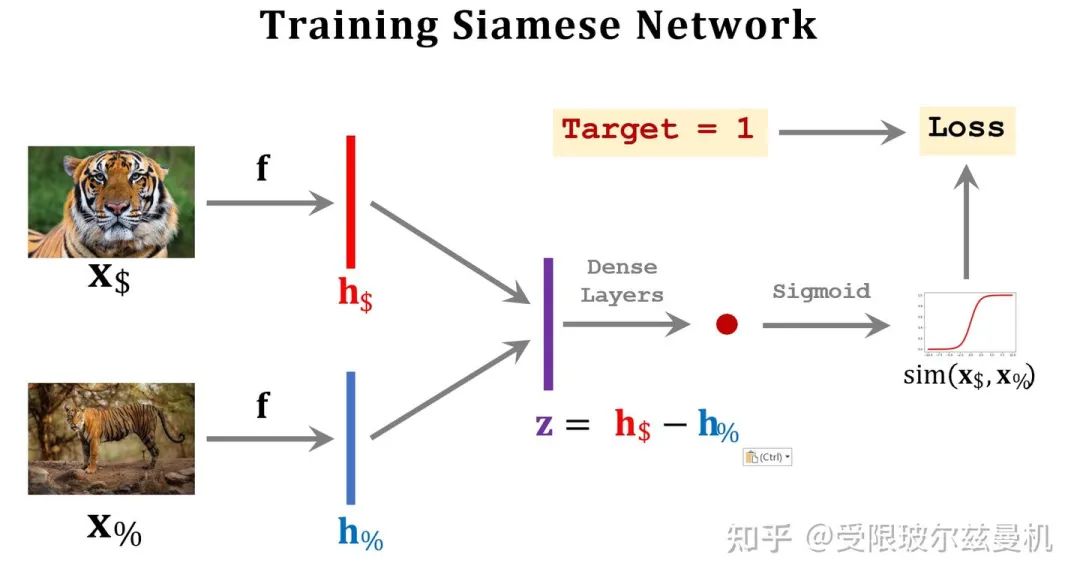
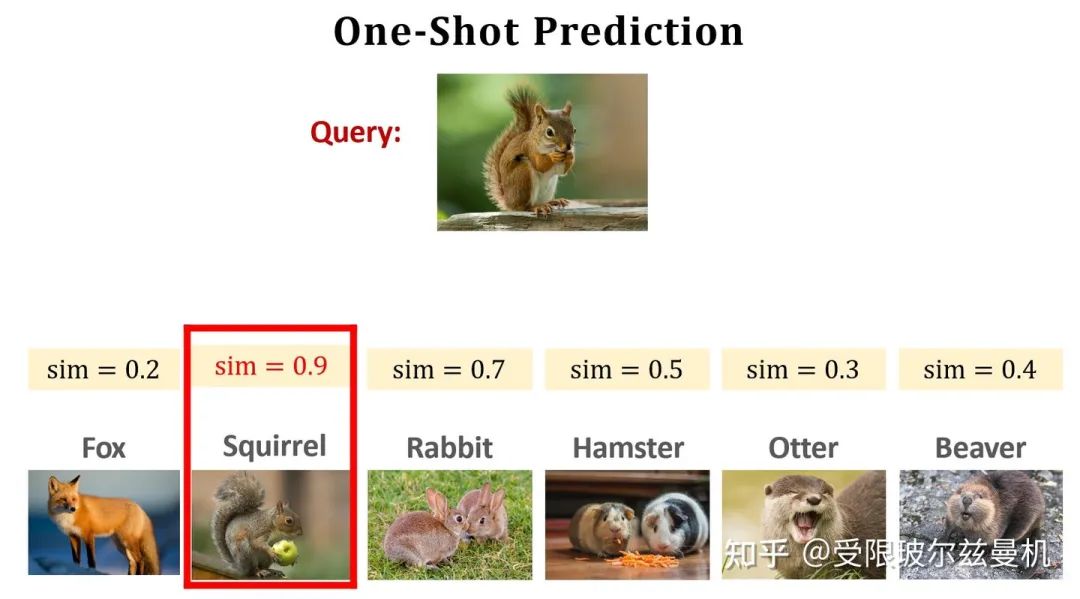
Learning Pairwise Similarity Scores


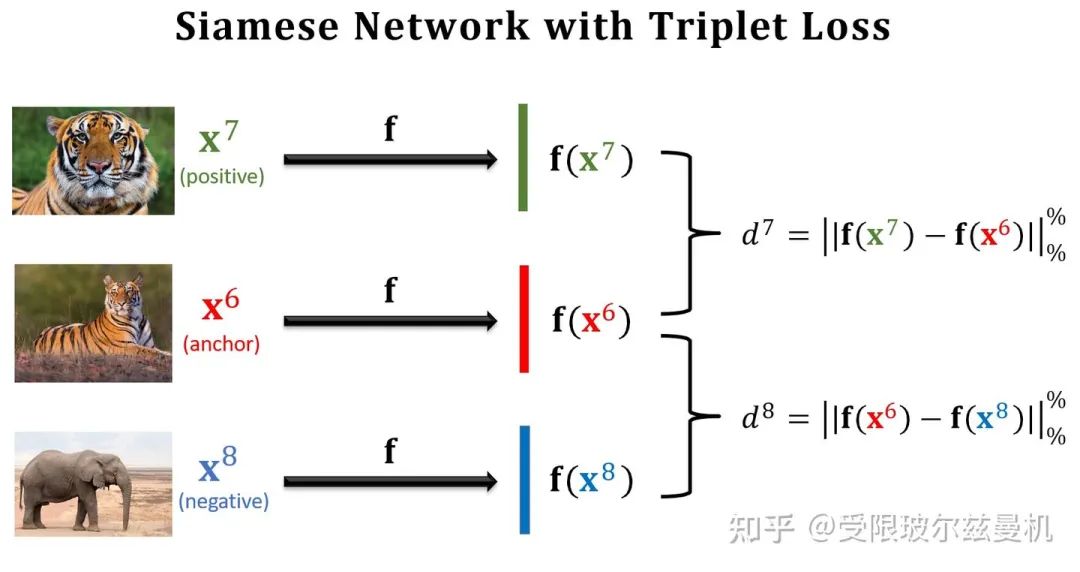
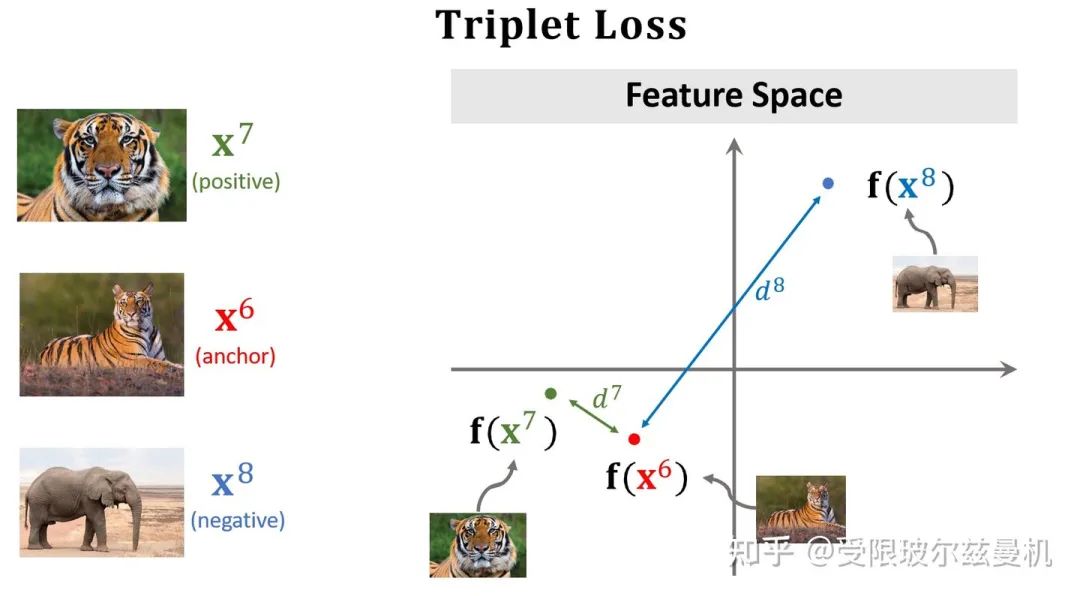
Triplet Loss





Pretraining and Finetuning
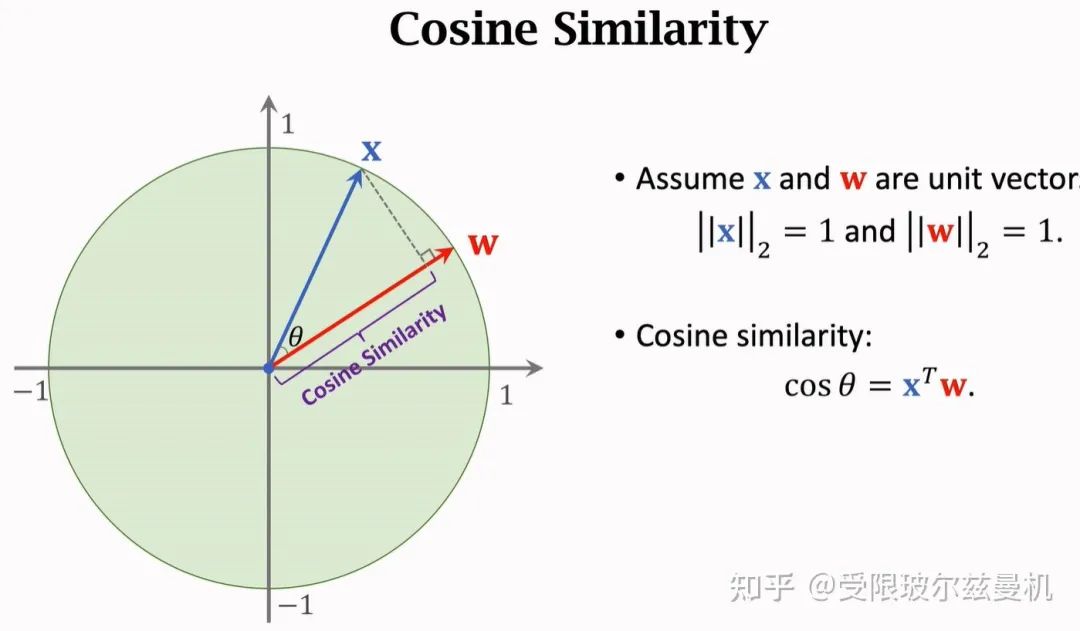
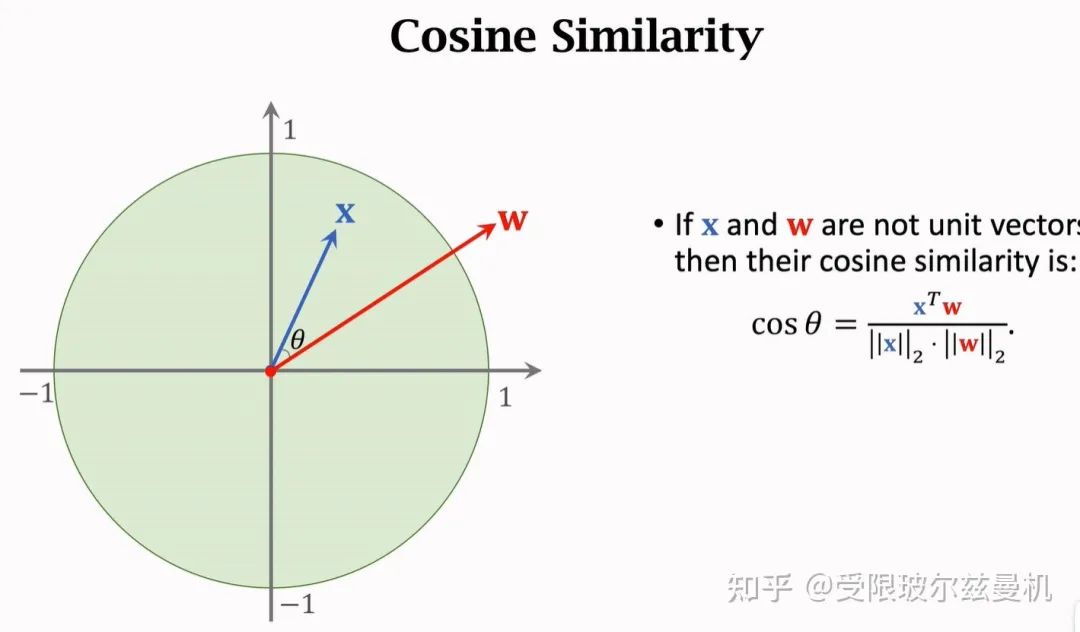

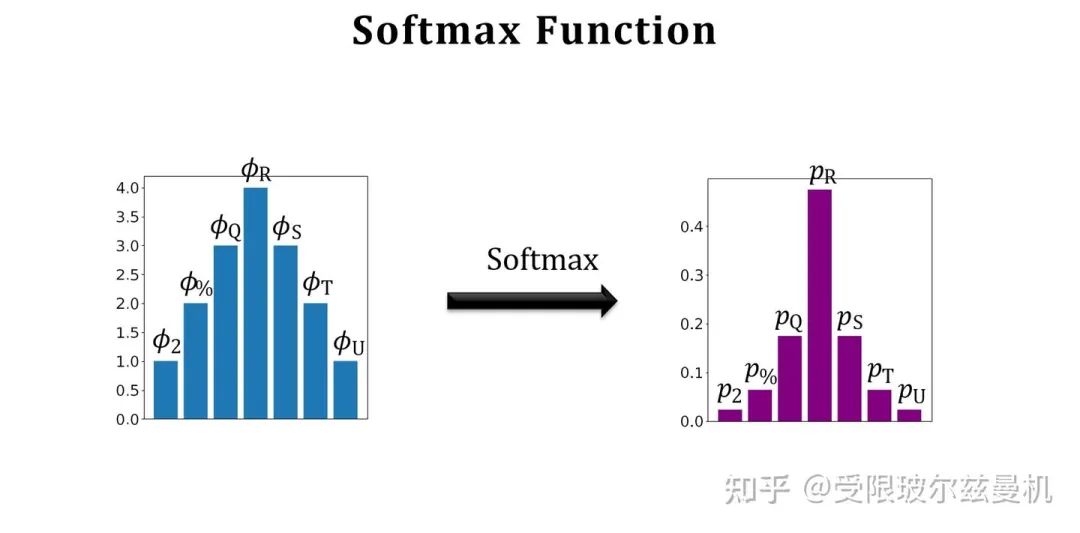
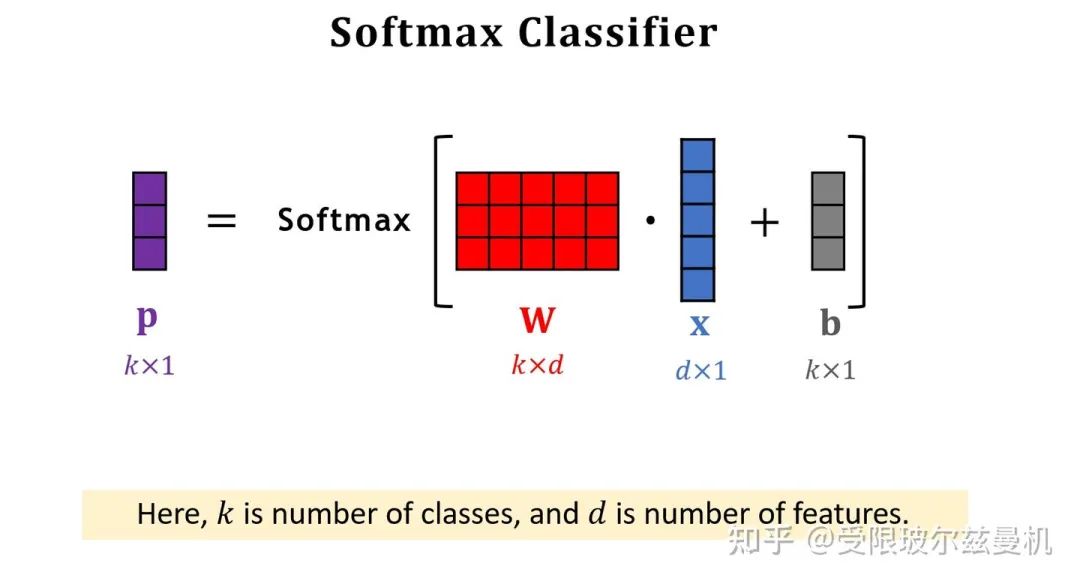

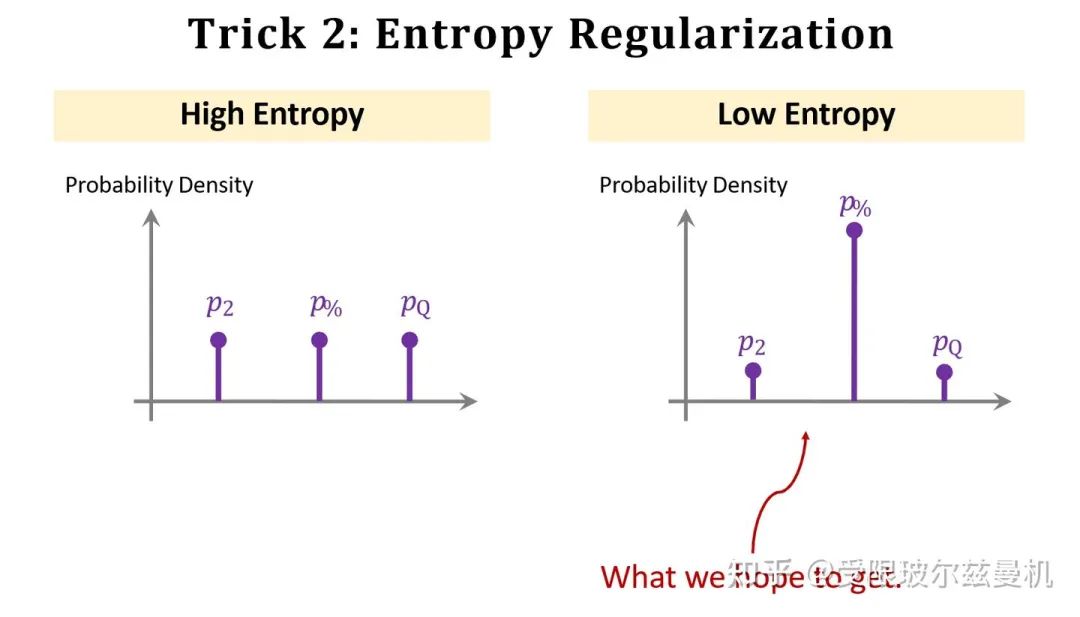
Trick


推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论