
零样本/少样本学习介绍及最新进展调研
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者|杨浩
来源 | 知乎
地址 | https://zhuanlan.zhihu.com/p/161233926
本文仅作学术分享,若侵权请联系后台删文处理
损失函数:
二元分类,交叉熵
训练过程:

Matching Networks for One Shot Learning 2016
论文地址:
papers.nips.cc/paper/63
简介:
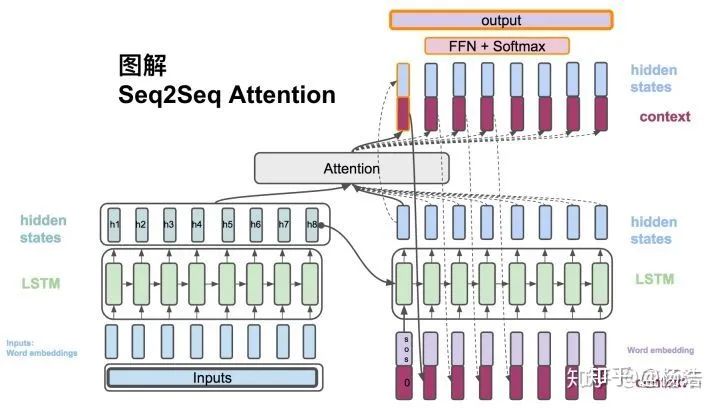
queryset的样本判断是supportset的哪个类别,是个knn的问题,本文训练了一个端到端的类似于nearest neighbor的分类器,思想就是借鉴seq2seq+attention。利用bi-lstm对supportset的样本编码(可能是为了将各个类别的样本作为序列输入到LSTM中,是为了模型纵观所有的样本去自动选择合适的特征去度量),然后queryset的样本进行k步attention编码,取最后一个隐藏层当做编码,最后和之前的supportset的编码做softmax得到类别。
网络结构:
损失函数:
多元,交叉熵。
Prototypical Networks for Few-shot Learning 2017
论文地址:
arxiv.org/pdf/1703.0517
简介:
对于分类问题,原型网络将其看做在语义空间中寻找每一类的原型中心。针对Few-shot的任务定义,原型网络训练时学习如何拟合中心。学习一个度量函数,该度量函数可以通过少量的几个样本找到所属类别在该度量空间的原型中心。测试时,用支持集(Support Set)中的样本来计算新的类别的聚类中心,再利用最近邻分类器的思路进行预测。
算法流程:

距离的度量属于Bregman散度,其中就包括平方欧氏距离和Mahalanobis距离,文中利用了平方欧氏距离。和Prototypical Networks 在few-shot的场景下不同,在one-shot时等价。
损失函数:多元,交叉熵
Relation Network for Few-Shot Learning 2018
论文地址:
arxiv.org/pdf/1711.0602
简介:
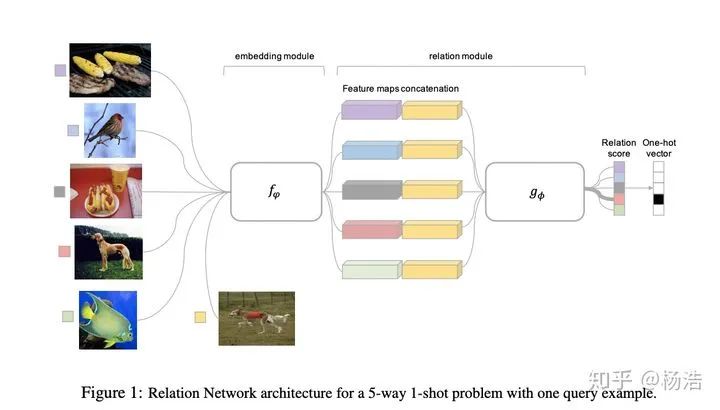
关系网络的做法是将query set的特征表示和support set的特征表示concat一起,然后走mlp网络,最后softmax得到分类结果。当few-shot的情况,将同一类的feature_map进行相加。
网络结构:
Few-Shot Text Classification with Induction Network 2018
论文地址:
arxiv.org/pdf/1902.1048
简介:
总体来说是原型网络变型,其中原型网络借助胶囊网络,一个胶囊网络通过使用执行动态路由的“胶囊”来编码个体和整体之间的内在空间关系从而构成视点不变的知识。
网络结构:
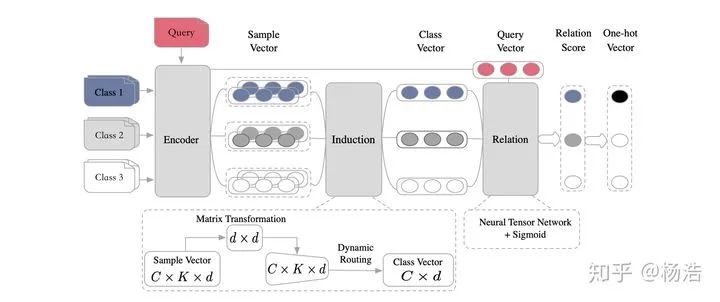
编码器模块:bi-lstm,然后self-attention变成固定长度的向量,ht。
归纳模块:

关系模块:
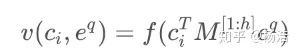
损失函数:回归
Dynamic Memory Induction Networks for Few-Shot Text Classification acl 2020
论文地址:
arxiv.org/pdf/2005.0572
简介:和Few-Shot Text Classification with Induction Network区别是编码模块使用bert-base,增加了pretrained的监督学习阶段。
网络结构:

Pre-trained Encoder:
预训练+监督学习到类别向量,当做memory,后面跟着finetune。
Dynamic Memory Module:
运行memory对supportset的sample进行编码

Query-enhanced Induction Module:
将上步骤生成的supportset的sample编码当做memory,利用queryset的sample,生成类别向量。
Similarity Classifier:

损失函数:多元交叉熵
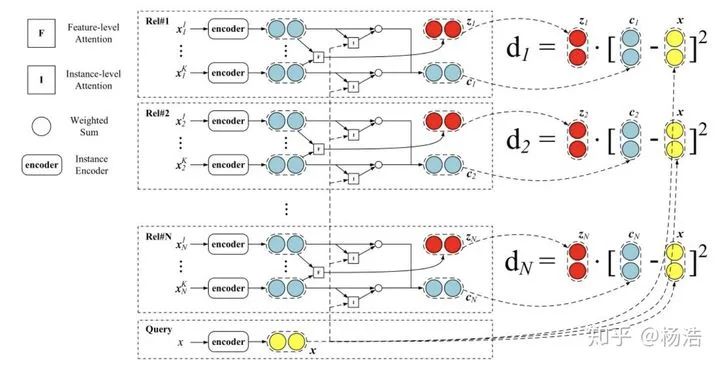
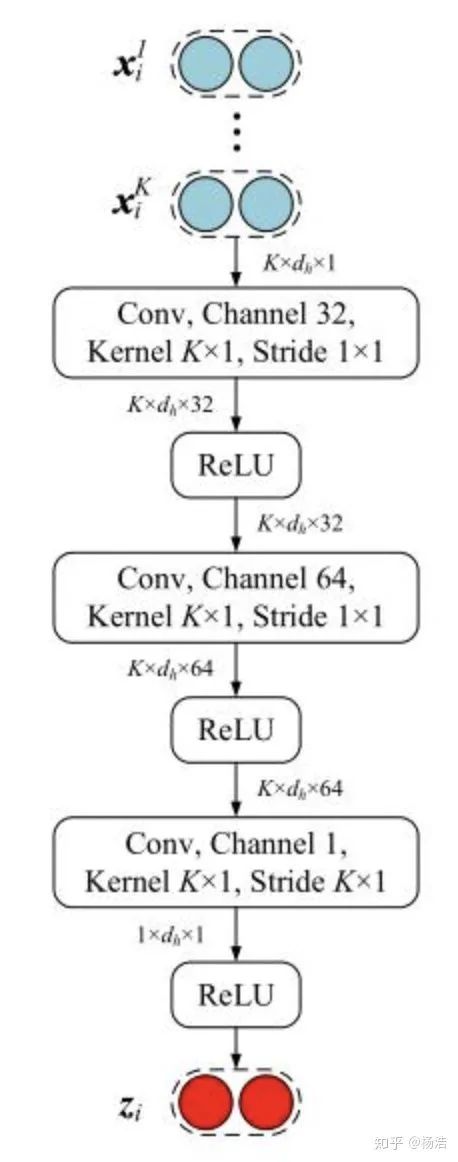
Hybrid attention-based prototypical networks for noisy few-shot relation classification 2019
简介:
先前研究论证了距离函数的选择会影响这个网络的能力。小样本数据集意味着特征是稀疏的,简单的欧式距离能力不足。虽然特征空间是稀疏的,但总会有些维度有更强的区分能力,所以需要特征层面的注意力机制,将该类别下面的sample多次卷积得到特征attention。
网络结构:
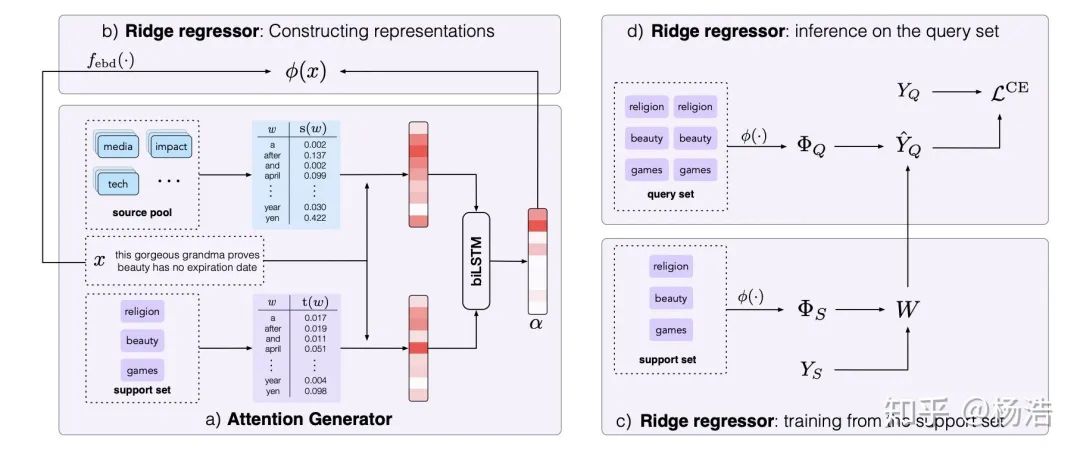
Few-shot text classification with distributional signatures 2019
论文地址:
arxiv.org/pdf/1908.0603
简介:
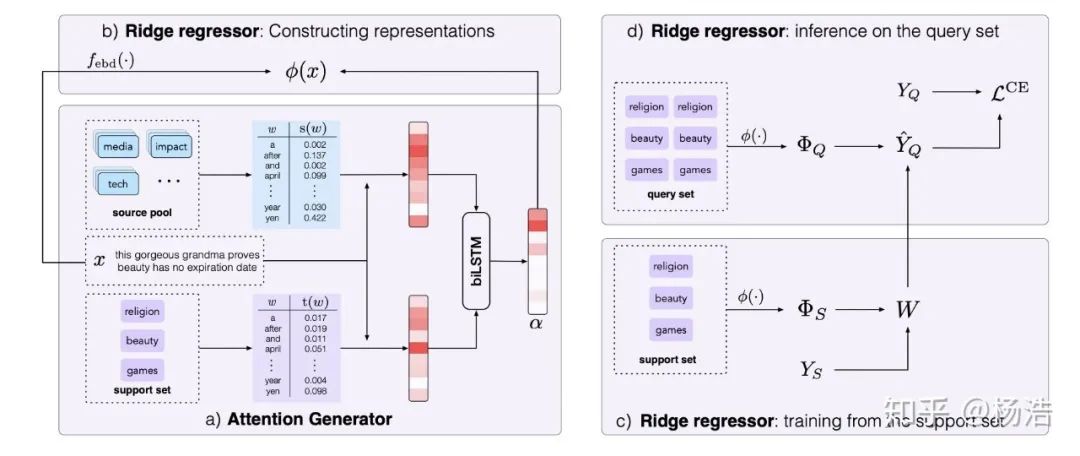
本文提出的方法可以很好地找到最重要的词,从而判断正确的类别,实现就是attention。增加了source pool,具体地,在元学习训练时,对每个训练段,我们把所有没被选择的类的数据作为source pool;在元学习测试阶段,source pool包括所有类的训练数据。
网络结构:
对于岭回归器,我们首先得到样本的表示:
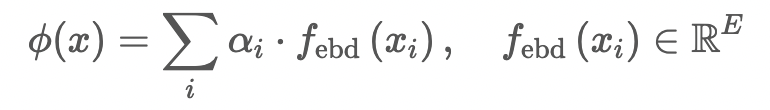

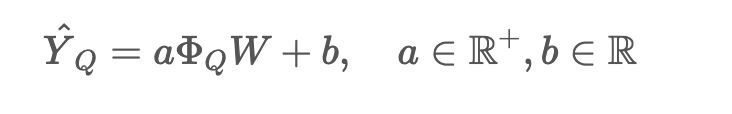
损失函数:交叉熵
Diversity Transfer Network for Few-Shot Learning AAAI2020
论文地址:
arxiv.org/pdf/1912.1318
网络结构:
输入有三种图,Query Image和 Support Image就是标注的episode设置,在此基础上额外加了一组Reference Image,它由H组类别相同的图片对组成。那么首先这些所有的图都会过一个Feature Extractor进行特征提取(特征会经过Norm),然后一组Reference Image 图片对的输出feature会相减和Support Image的feature再相加送入到一个Generator里面进行encoding,那么作者认为这个Encoding之后的feature和原始的support image的feature表征的是同一类物体(毕竟相同类别的两张图相减了嘛),作者通过这样的操作把intra-class的diversity显式的encode到网络的训练过程中,希望模型可以学习到这种多样性,至于meta class的分类就和protonet一样了, 只是proxy的计算是H个encoding的feature再加上原始的support image的feature取平均。

Cross Attention Network for Few-shot Classification
论文地址:
papers.nips.cc/paper/86
简介:提出了cross attention ,其实就是两个sample的embedding之间进行attention
网络结构:
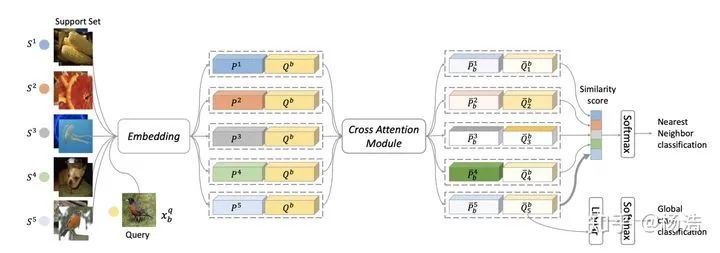
其中Cross Attention Module:

2. optimizers-base learning(优化器改进)
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 2017
论文地址:
arxiv.org/pdf/1703.0340
简介:
support set参与第一次参数更新。这里的参数更新并没有直接作用于原模型,我们可以理解为先copy了一下模型,用来计算新参数。利用第一轮更新后的参数,通过query set计算第二轮梯度,这一轮的梯度才是模型真正用于更新参数的梯度。至于这样的方法,为什么比“直接使用theta在各个task上的loss之和来做梯度下降”效果更好,这里有两篇论文从理论或数学上做了一些对MAML的分析。事实上,“直接使用theta在各个task上的loss之和来做梯度下降”相当于直接做transfer learning,思路和预训练imagenet类似,只能最小化在across tasks的经验风险,不能做到task-specific。
arxiv.org/pdf/1803.0299
researchgate.net/public
算法流程:

Reptile: a Scalable Metalearning Algorithm
简介:
maml有对梯度二阶求导,Reptile是一种一阶MAML。
论文地址:
d4mucfpksywv.cloudfront.net
算法流程:

Model-agnostic meta-learning for relation classification with limited supervision. 2019
论文地址:
aclweb.org/anthology/P1
简介:MAML改进,其实就是Reptile
算法流程:

Adaptive Cross-Modal Few-shot Learning 2019
论文地址:
arxiv.org/pdf/1902.0710
简介:
图文和视频多模融合,conbine通过系数(自适应混合系数,其实就是文本侧的embeddng通过sigmod得到的),整体利用原型网络。
网络结构:

Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification
论文地址:aclweb.org/anthology/P1
简介:
首先对queryset的每一个instance和support的所有instance成词级别的embedding矩阵,做交互attention,最后将attention结果和原来的矩阵进行拼接,降为原来维度。求class embedding和原型网络不通的是每一个类的权重是由queryset的实例attention得到的,然后得到class embedding,关系网络做matchclass,得到结果。
网络结构:

3. models-base learning(模型结构改进)
Meta-Learning with Memory-Augmented Neural Networks 2016
论文地址:
web.stanford.edu/class/
简介:
针对传统基于梯度的神经网络处理one-shot时,遇到新的数据需要重新学习参数,不能高效快速地适应新数据,此论文提出的模型可以快速编码和检索以往数据。
网络结构:
使用序列输入,每个输入伴随上一个标记,防止模型仅仅学到映射关系
在不同数据集间,标记被打乱,迫使模型必须学到保留一些样本信息,供下次检索使用


Meta Networks 2017
论文地址:
arxiv.org/pdf/1703.0083
简介:
Meta Networks跟MANN类似,也有一个外部的记忆模块。三个主要过程:meta information的获取、以及fast weight的生成和slow weight的优化,由base learner和meta learner共同执行。
算法流程:

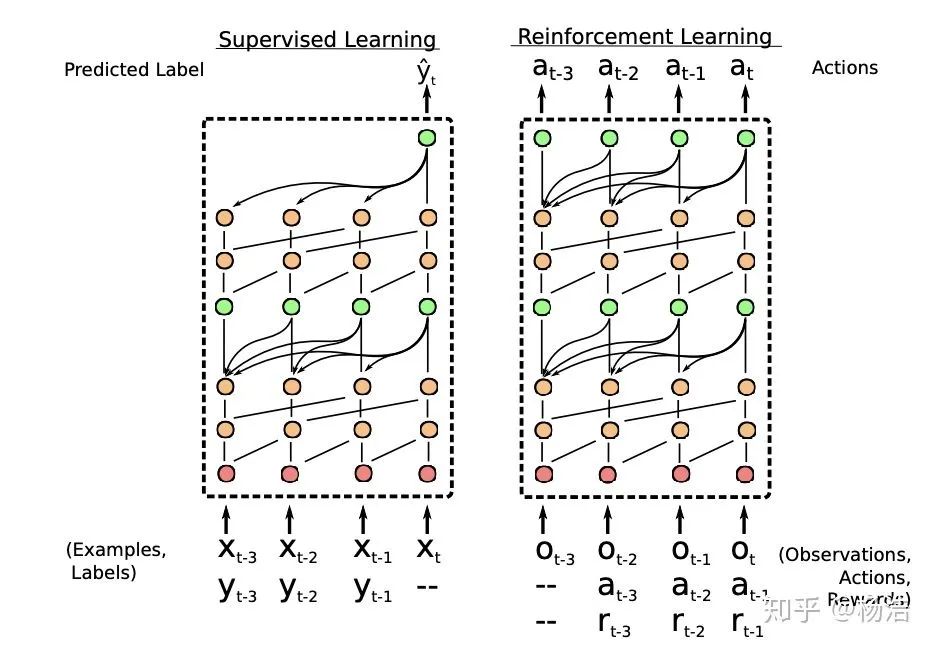
A Simple Neural Attentive Meta-Learner 2018
论文地址:
arxiv.org/pdf/1707.0314
简介:
将meta-learning形式化为一个序列到序列的问题,使用一种新的时序卷积(TC)和注意力机制(Attention)的组合。通过将 TC 层与 Attention 层交错,SNAIL可以高效的利用过去的经验,并且不限制其可以有效使用的经验量。通过在多个阶段使用注意力端到端训练的模型中的,SNAIL它可以利用时序卷积层在过去收集的经验中了解要挑选特定的信息片段。模型的输入序列是由带标签的少量样本和一个需要预测的样本组成,它可以从序列中利用用要预测的样本之前的有先验信息或标签信息来对序列的最后一个样本预测,有一种消息传递的思想。
模型结构:
TC:
由一系列空洞卷积组成,这些dense block的膨胀率 R
呈指数级增长
ATT:
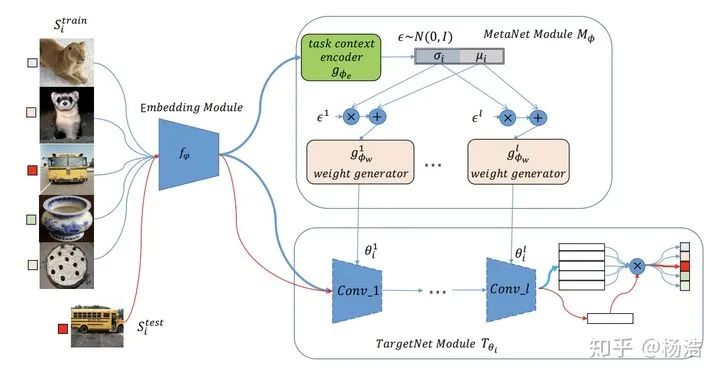
LGM-Net: Learning to Generate Matching Networks for Few-Shot Learning
论文地址:
arxiv.org/pdf/1905.0633
简介:model-based方法,训练网络(bilstm)生成match network的参数
网络结构:
Few-Shot Representation Learning for Out-Of-Vocabulary Words
论文地址:aclweb.org/anthology/P1
简介:
对预训练的词表,统计出现次数较多的词当训练样本,本质是一个回归问题(将OOV的上下文和细粒度特征同时作为输入,输入它的近似词向量,使得这个近似词向量与它的在嵌入空间中“应该”的真实词向量比较接近),maml解决小样本过拟合点的问题。每一轮训练结束,更新训练oov。
网络结构:

Metagan: An adversarial approach to few-shot learning 2018
论文地址:papers.nips.cc/paper/75
简介:
MetaGAN算法能够从有标签和无标签的例子中学习推断特定于任务的数据分布,在有监督和半有监督的情况下,证明了MetaGAN在流行的小样本图像分类基准上的有效性
算法流程:
loss:
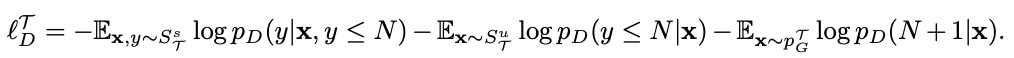
判别器:可以是关系网络
生成器:
将supportset的所有sample encode成vector,在加上随机扰动。
Few-shot learning with graph neural network 2017
论文地址:
arxiv.org/pdf/1711.0404
简介:
利用图卷积获取sample表示之间的高阶特征组合,几层代表几阶邻居。图模型小样本学习的目的是将标签信息从有标签的样本传播到无标签的查询图像。这种信息传播可以形式化为对输入图像和标签确定的图形模型的后验推理。
网络结构:

标签one-hot形式拼接
图神经网络:
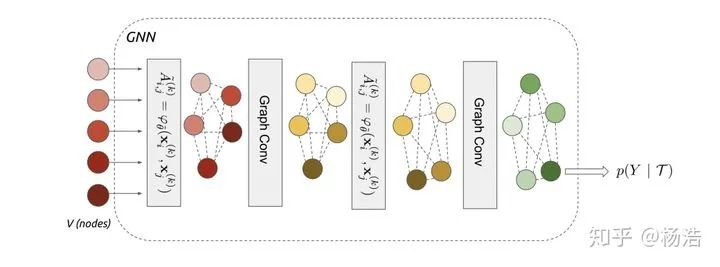
图卷积:
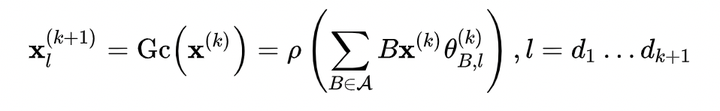
梳理论文发展思路,仅仅个人观点:
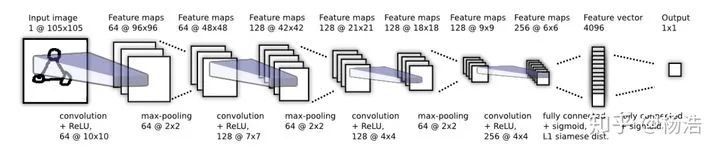
1.Siamese Neural Networks for One-shot Image Recognition 2015
之前的小样本学习方案需要特定的先验知识先验知识或者特定的推理过程,不具有通用性、鲁棒性且算法较为复杂(例如在Omniglot数据集上,之前的方法HBPL就要借助字母的顺序)需要寻找一个通用的算法。 借助神经网络进行自动化的特征提取,神经网络具有很多层的非线性能够捕捉到输入空间中的不变性(投影到一个度量空间,相当于压缩模型假设空间)。 第一个将深度卷积孪生网络用来解决One-Shot Learning问题,训练好孪生网络以后,不需要经过再训练即可用于One-Shot Learning任务。
2.Matching Networks for One Shot Learning 2016
目前一个标准的小样本学习方法是训练一个线性分类器比如svm,但是这需要对模型参数优化,需要训练样本。另一个非参数的方法是利用knn,可以立即使用最近邻居对新类进行分类,而无需进行任何优化,但是依赖于度量的选择,比如l2等。 核心想法:训练一个end-to-end最邻近分类器(attention用到了cos距离)。
3.Prototypical Networks for Few-shot Learning 2017
借鉴matching network解决one-shot,原型网络解决few-shot问题,根据zero-shot的方法,构建对于类别的高level表示,通过相同类别的样本embedding相加解决(减少bais),最后使用欧几里得距离判断类别。 通过以往工作和本文实验得出,使用欧几里得距离来作为距离度量会明显的优于使用余弦距离作为距离度量。 以往的实验发现,在训练和测试时保持相同的episode设置往往会得出较好的结果。例如,我们在测试时期望使用5-way-1-shot的方式,那么我们训练时就要使得episode的设置为Nc为5、Ns为1,其中Nc代表从episode中选择的类别的个数,Ns代表每个类别中被选择为支持样例的个数。然而,在我们的实验中发现,使用比测试时更高的Nc(“way”)对模型是有益的。
4.Learning to Compare: Relation Network for Few-Shot Learning 2018
针对小样本情况学习一个end-to-end模型,让模型学会比较,感觉像是mn和pn的结合,mn适用one-shot(对于每个类别多个样本没法解决),pn适用few-shot(还需要指定度量方式)
5.Few-Shot Text Classification with Induction Network 2018
本质解决类别向量有偏问题。之前pn求类别向量的话。因为每个类别的样本数量比较少,容易产生噪音,导致类别向量有偏。通过引入Induction模块,将同类别下的样本进行交互,根据交互后的权重来求得class-wise类别向量,使得类别泛化能力更强。
6.Dynamic Memory Induction Networks for Few-Shot Text Classification 2020
本质还是解决怎么学习更好的类别向量的问题,类别向量表示在不同Meta task之间切换时候容易丢失主要的信息,可以利用记忆增强来解决。 由于同种类别的不同样本是多样性的,导致很难学到一个稳定的类别表示向量,通过quert_set和support_set的交互可以缓解此问题。
7.Hybrid attention-based prototypical networks for noisy few-shot relation 2019
为了解决few-shot learning 中易受噪声实例影响这一问题(由于任务的背景是在few-shot学习中,用来计算类原形的样本数量往往很少。如果出现错误实例或者是和常规句子语义偏差较大的正确实例的话,对于类原形的影响是非常的巨大),该论文提出了一种基于原形网络的混合attention网络。该模型设计了实例级别和特征级别的attention机制,分别的突出模型中关键样本实例和关键特征。 instance level attention: 普通的protype network针对支撑集中各个样本进行直接平均,作者认为这样会噪声特别大,因此引入加权平均的思想(利用实例attention来选择support集中最有价值的样本,来缓解噪声样本对模型的影响)。 feature level attention: 原始的prototype network直接利用简单的欧氏距离作为距离函数,而本文作者认为在利用支撑集中样例对测试样例进行分类时,某些feature可能对分类至关重要,因此在feature这个层级也要考虑注意力机制(利用特征attention来突出特征空间中重要的特征维度,来缓解特征稀疏问题),具体做法对同类样本做三次卷积得到。
8.Few-shot text classification with distributional signatures 2020
不同Meta task之间切换时候容易丢失主要的信息,例如有些词汇对于当前类别比较重要,但是对于其他类别不是很重要。为了解决这个问题,通过引入tf-idf等信息。
9.Cross Attention Network for Few-shot Classification 2019
训练集和测试集的类别是不重合的,在一部分类别上进行训练,然后在另一部分类别中测试。这样存在一个问题:在训练阶段识别的是人和椅子,在测试阶段实际预测的是窗帘,由于窗帘在训练阶段没有出现过,因此在预测的时候通常把注意力放在了人和椅子上面,注意力很难在目标物体上。针对这个问题,论文中提出了CAN(cross attention network)。 针对样本非常少的问题,引进直推式推理算法去缓解小样本问题,将一些无标签的但是置信度较高的样本加入到训练样本中。
10.Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 2017
在高容量的分类器中的基于梯度的优化算法需要 在大量样本上进行大量的迭代步骤 以取得良好的表现。为了解决利用先验知识优化给定假设空间中最优假设的搜索的问题,提出一种用于元学习的简单模型和与任务无关的算法,该算法可训练模型的参数,寻找一个模型的初始值,以使少量的梯度更新可快速学习新任务。不会扩展学习参数的数量(lstm),也不会需要对模型空间进行约束(孪生网络)。
11.Optimization as a model for few-shot learning 2017
梯度优化算法无法在几步之内完成优化,特别是非凸问题,各种超参的选取无法保证收敛的速度。不同任务随机初始化会影响任务收敛到好的解上。尽管迁移学习能缓解这个问题,但新数据与原始数据偏差较大时,迁移学习的性能就会大大降低。LSTM内部的更新非常类似于梯度下降的更新,因此利用LSTM的结构训练一个meta-learner模型,用于学习另一个神经网络的参数,既学习优化参数规则,也学习权重初始化。 元学习优化器能够在给定一系列分类器在训练集的梯度和损失下,为分类器生成一系列更新,从而使分类器达到较好的表现。每一步迭代t,基于lstm的元学习器都接受到分类器传来的梯度,损失等信息,元学习器基于此计算学习率和忘记门的值,并返回给分类器要更新的参数的值,每迭代T步,分类器的损失在测试集上计算出来返回给元学习器,用来训练元学习器,更新元学习器的参数。元学习器既考虑一个任务的短期记忆,同时也考虑全部任务的长期记忆。 一是SGD的优化方法在非凸情况下表现得不好,同行需要大量迭代才有好的结果。第二是,对于不同的数据集。网络的每次训练都得随机初始化参数。虽然迁移学习通过预训练能缓解这个问题,但是由于模型任务目标的分散,迁移学习的优势也不明显。因此迫切需要一个通用的初始化方法,使得在训练不同数据集时有一个较好的开始点而不是随机初始化参数。
12.One-shot Learning with Memory-Augmented Neural Networks 2016
标准深度神经网络缺乏不断学习或不断学习新概念的能力,而不会忘记或破坏以前学习的模式。
针对小样本问题,传统的基于梯度的网络需要大量的数据去学习,通常需要经过大量广泛的迭代训练。当给模型输入新数据时,模型必须低效的重新学习其参数从而充分的融入新的信息,并不会造成较大的干扰影响。具有增强记忆能力的网络结构,例如NTMs具有快速编码新信息的能力,因此能消除传统模型的缺点。这里,我们证明了记忆增强神经网络(具有快速吸收新数据知识的能力,并且能利用这些吸收了的数据,在少量样本的基础上做出准确的预测。
13.Meta Networks 2017
深度神经网络在大量应用中表现出了巨大的成功,但是需要大量的数据,此外标准的深度神经网络缺乏不断学习或不断学习新概念而不会忘记或破坏以前学习的模式的能力。 MetaNet由两部分组成:基学习器(Base Learner)和带有额外记忆模块的元学习器(Meta Learner)。学习也在连个分离的空间内进行,基学习器在输入任务空间,而元学习在与任务无关的元空间,基学习器向元学习提供一种由高阶的元信息构成的反馈,用于解释他在当前任务空间内的状况。此外,MetaNet的权重还涉及不同的时间尺度:快速权重(Fast Weight)和慢速权重(Slow Weight),在训练过程中,快速权重是利用另一个网络根据梯度信息生成的,而慢速权重则需要利用SGD方法进行更新得到。
14.Knowledge Guided Metric Learning for Few-Shot Text Classification 2020
人类能从相关的任务知识来学习新的任务,我们使用知识图谱来自模仿人类知识,辅助更好的学习。
15.Prototype Rectification for Few-Shot Learning 2019
传统的原型网络是将support集里面每个类的所有样本的特征的平均作为该类的原型representation,通过query集合的特征representation与support集中每个类别的原型representation进行欧式距离计算,在经过softmax得出最后所属类别。简单的求平均会产生很大的bias,因此提出了对原型网络进行修正,从两个角度:intra-class bias和cross-class bias。 Intra-Class Bias:类似于半监督,将置信度高的样本加入。Cross-Class Bias:指support集中的平均样本特征与query集中的平均样本特征间存在差异,对每个归一化的query 数据加上这个差异。
16.Hierarchical Attention Prototypical Networks for Few-Shot Text Classification 2019
原型网络因为样本少而带来噪音的影响,提出层次attention原型网络,从特征,词和实例不同的角度缓解这个问题。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!