地址:https://zhuanlan.zhihu.com/p/142057964
本文充其量算个原创,如果综(pin)述(cou)也算的话。网上有一些关于零样本学习的讨论,但都有其局限性,不全面或者太学术,我学习之后,对其进行加工,加上我自己的的理解,然后对后来想要了解零样本学习的同学,可能会有帮助,至少能节省点时间。相比于网上的各种五花八门的介绍,我争取做到更全面,更通俗。为什么我开始研究零样本学习?是个巧合。之前我没听说过,上个学期,在一次组会上,听一个师姐做汇报,讲她关于小样本学习的研究。听了介绍,我瞬间被吸引,很感兴趣,但平时忙于上课,也一直没去深入了解,(懒)。直到前几天,在某文章里看到零样本学习,这次我有时间了!于是,就深入了解了下(看了几篇文献hhhh)。本人水平有限,难免疏漏,还请读者多多指正。01
(1)深度学习(deep learning)已经在各个领域取得了广泛的应用,例如在图像分类问题下,其准确率目前可以达到不错的成绩。然而,deep learning是一种data hungry的技术,高的准确率建立在预先给模型“喂了”大量的数据,即,需要大量的标注样本才能发挥作用,大多数方法是通过有标签的训练集进行学习,侧重于对已经在训练中出现过标签类别的样本进行分类。然而在现实场景中,许多任务需要对模型之前从未见过的实例类别进行分类,这样就使得原有训练方法不再适用。因为,现实世界中,有很多问题是没有这么多的标注数据的,或者获取标注数据的成本非常大。所以,我们思考,当标注数据量比较少时、甚至样本为零时,还能不能继续?我们将这样的方法称为小样本学习Few-Shot Learning,相应的,如果只有一个标注样本,称One-Shot Learning,如果不对该类进行样本标注学习,就是零样本学习Zero-Shot Learning.(2)人类学习的过程包含了大量零样本学习的思路,也就是说一个小孩子从来没见过一些类别的东西,在家长和老师的描述之后,他也能在一堆图片里找出那件东西。在2016 年中国计算机大会上,谭铁牛院士指出,生物启发的模式识别是一个非常值得关注的研究方向,“比如人识别一个动物(并不需要看到过该动物),只需要一句话的描述就能识别出来该动物”,比如被广泛引用的人类识别斑马的例子:假设一个人从来没有见过斑马这种动物,即斑马对这个人来说是未见类别,但他知道斑马是一种身上有着像熊猫一样的黑白颜色的、像老虎一样的条纹的、外形像马的动物,即熊猫、老虎、马是已见类别。那么当他第一次看到斑马的时候, 可以通过先验知识和已见类,识别出这是斑马。人类通过语义知识作为辅助信息,识别了未见类,零样本学习也正是基于这样的思想、基于人类学习过程,进行算法的研究。
02
零样本学习zero-shot learning,是最具挑战的机器识别方法之一。2019年冀中等人在综述文章中将零样本分类的定义分为广义和狭义两种:零样本分类的技术目前正处于高速发展时期, 所涉及的具体应用已经从最初的图像分类任务扩展到了其他计算机视觉任务乃至自然语言处理等多个相关领域. 对此, 本文将其称为广义零样本分类. 相应地, 我们将针对图像分类任务的零样本分类任务称为狭义零样本分类。在冀中和 WEI WANG的文章中,零样本学习均被视为迁移学习的一个特例。零样本学习中,源特征空间是训练样本的特征空间和目标特征空间是测试样本的特征空间,这两者是相同的。但是源标注空间和目标标注空间分别是可见类别和未见类别,两者是不同的。因此零样本学习属于异质迁移学习(heterogeneous transfer learning)。一个最通俗的例子就是在本文第1部分里提得到的斑马的例子。零样本学习的实现与另外两个研究领域密不可分,其一是表征学习(representation learning),其二是度量学习(metric learning)。表征学习是指通过对数据进行变换从而提取数据中的有效信息的一种学习方式,涉及到人工智能相关的诸多领域,如信号处理、目标识别、自然语言处理,以及迁移学习等。度量学习通常建立在表征学习的基础之上,其本质是根据不同的任务,根据特定空间中的数据,自主学习出针对某个特定任务的距离度量函数,目前已被广泛应用于诸多计算机视觉相关的任务, 如人脸识别、图像检索、目标跟踪、多模态匹配等。对于零样本学习,在获取到合适的数据表征空间之后,则需要对跨模态样本间的距离度量进行学习,目的是保证嵌入到语义空间后样本间的语义相似度关系得以保持。综上所述,零样本学习可以看作是在进行表征学习和度量学习的基础上,通过借助辅助信息(属性或文本) 实现跨模态知识的迁移,从而完成可见类信息到未见类信息推断的迁移学习过程。03
Zero-Shot Learning 这一问题和概念的提出,源于2009年Lampert在CVPR上发表的Learning to Detect Unseen Object Class by Between-Class Attribute Transfer这一篇文章。同样是这一年,Hinton等在NIPS也上发表了一篇Zero Shot Learning with Semantic Output Codes的文章。这算得上零样本学习开宗明义的文章,所以先介绍这两篇。Lampert在论文中所提到的Between-Class Attribute Transfer,通常我们做有监督学习的思路,是实现数据的特征空间到数据标签之间的映射,而这里,我们利用数据特征预测的却是样本的某一属性。类间属性迁移应用到上文提到的斑马案例,见下图: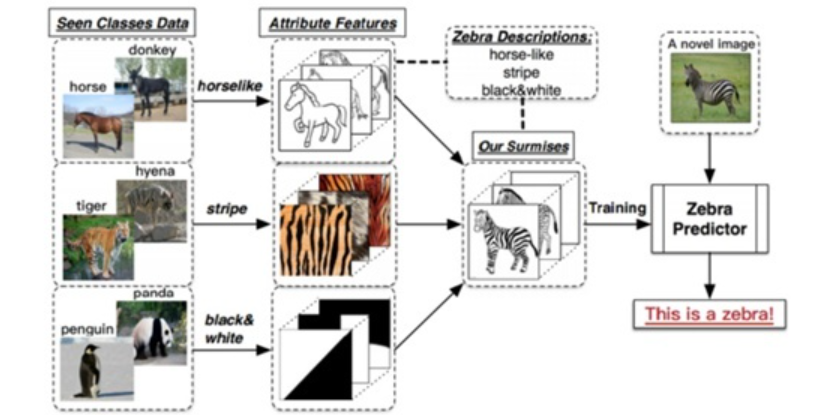
Between-Class Attribute Transfer的核心思想在于:虽然物体的类别不同,但是物体间存在相同的属性,提炼出每一类别对应的属性并利用若干个学习器学习。在测试时对测试数据的属性预测,再将预测出的属性组合,对应到类别,实现对测试数据的类别预测。Lampert在该论文中给出了两种属性预测的结构:DAP和IAP。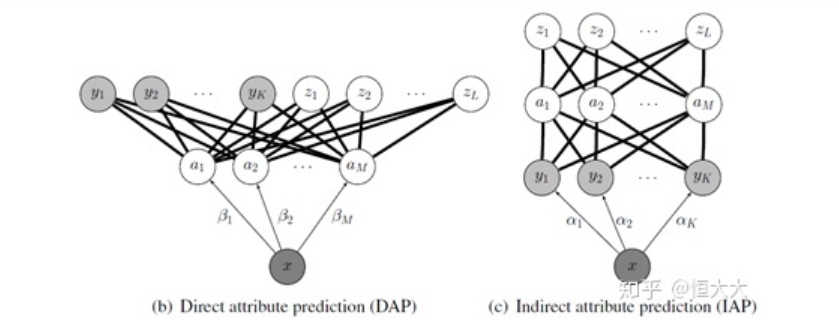
直接属性预测 Direct attribute prediction (DAP)这一方法先将数据从特征空间映射到中间层的属性向量层,属性向量层的标签是通过收集来的每一类特征的总结,比如是否有尾巴,有几只脚等等,通过利用数据预测属性,再通过属性映射到标签来实现对于未知类别的预测,这一方法也是接受和应用最为广泛的一种。间接属性预测 Indirect attribute prediction (IAP)这一方法使用了两层标签,属性层作为中间层,在实际中使用较少,这里不多做介绍Hinton等在2009年的Zero-shot learning with semantic output codes这篇论文里,提到的语意输出编码方式,思想其实与DAP的思路类似,也是在之前的特征空间与标签之间增加了一层,这里增加的一层不再是数据本身的属性,而是标签本身的编码,说简单点就是NLP里面的词向量(word2vec),通过将标签进行词向量的编码,利用模型基于数据矩阵对编码进行预测,得到结果之后,通过衡量输出与各个类别词向量之间距离,判别样本的类别。简单说就是,该论文里使用词向量来实现零样本学习。如果我们将原先的表示类别的词(马、熊猫、老虎等)编码为词向量,那么我们就可以用距离来衡量一个未知的词向量的归属。将训练标签编码为词向量,基于训练数据和词向量训练学习器。测试时输入测试数据,输出为预测的词向量,计算预测结果与未知类别词向量的距离,数据距离最近的类别。(所以未知类别的词向量在此是已知的)由以上两个模型,我们可以总结出一个零样本学习的简单模式: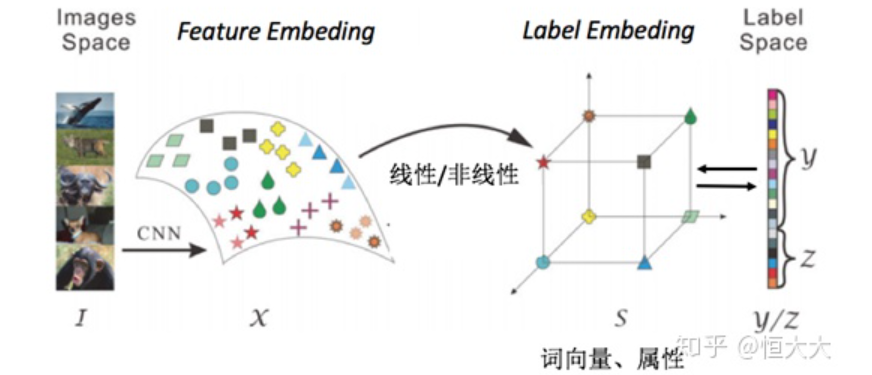
上图中,images space和label space分别为初始的图像空间和标签空间,在零样本学习中,一般会通过一些方法将图片映射到特征空间中,这个空间称为feature embedding ;同样的标签也会被映射到一个label embedding 当中,学习feature embedding 和label embedding 中的线性或非线性关系用于测试时的预测转化取代之前的直接由images space 到 label space的学习。冀中等在文献[4]中,将零样本学习的发展分为两个阶段,上文我们介绍的属于第一阶段,即提出阶段,这个阶段主流的研究思路是,利用“浅层视觉特征+ 属性+ 传统机器学习方法” 的分析模式;第2 阶段的时间大致为2013-2019 年, 称为发展阶段,这个阶段的主流研究思路是利用“深度视觉特征+ 属性/词向量+ 传统机器学习方法” 的分析模式。在这一阶段,受益于深度学习技术的发展,特别是CNN模型、Word2Vec的提出,零样本学习得到了较快的发展。篇幅有限,在这里就先介绍Lampert和Hinton的一些思想和做法,这是比较基础的也是一般的方法。其他最新的方法,有空再写一篇新的吧,不然这篇内容写太多了。详见参考文献[5].在零样本学习中, 最为常用的数据集是Animals with Attributes (AwA) 数据集,此外,在零样本学习中广泛应用的属性数据集还有三个: Caltech-UCSD-Birds200-2111(CUB)、Attribute Pascal and Yahoo (aPY) 数据集 以及SUN attribute 数据集。这些数据集很容易下载到。04
从入门到放弃?哈哈哈哈,是的,有一些很难解决的问题在这里。虽然如前文所说,零样本学习仍处于快速发展的阶段,但零样本学习由于其自身方法中存在的问题,这些问题使得零样本学习的研究遇到很大的障碍。这三个障碍分别是广义(泛化)零样本学习(Generalized zero-shot learning)、枢纽化问题(Hubness)、映射域偏移问题(The projection domain shift problem)。下面简单介绍一下这几个问题:在实际的应用中, 目前的零样本学习与现实应用的学习环境,出现了一定程度的矛盾, 这是因为,在零样本学习的假设在测试阶段,只有未见类样例出现。这在实际应用中这种假设是不现实的,往往已见类的样例是现实世界中最为常见的样例,而且,如果在训练阶段已见类样本容易得到、未见类样本难以获取, 那么在测试阶段就也不应只有未见类样例出现。所以, 为了让零样本学习真实的反应实际应用中的样例识别场景, 零样本学习模型应对包括未见类和已见类的所有输入样例进行识别,即大量的已见类样例中夹杂着少量的未见类样例,输入样例的可能类标签大概率属于已见类, 但也有可能属于未见类。如果在测试阶段,模型可以准确识别已见类样例,且可以识别从未见过的未见类样例,那么就认为该模型实现了广义零样本学习 。由于模型在训练时,只使用了已见类样本进行训练, 且已见类的先验知识也更加丰富,这就导致已见类模型占主导地位。所以在测试时,模型会更加倾向于对未见类样例标注为已见类的标签,进而导致识别的准确率和传统零样本学习相比大幅度下跌。枢纽化问题(Hubness) ,并不是ZSL所特有的问题,凡是利用特征子空间的学习模型,在实验中都发现了这个现象。由于目前零样本学习中,最为流行的方法就是将输入样例嵌入到特征子空间中,这就导致了ZSL中的Hubness尤为突出。枢纽化问题是指,将原始空间(如图像特征空间或类标签空间)中的某个元素映射到特征子空间中,得到原始空间中某个元素的在特征子空间中的新表示,这时如果使用K 近邻,可能会有某些原始空间中的无关元素映射到多个测试样本特征空间中表示最近的几个近邻中,而这些无关向量,就称为枢纽(hub)。产生映射域偏移问题的根源在于映射模型较差的泛化能力:模型使用了训练类样本学习由样例特征空间到类标签语义空间的映射,由于没有测试类的未见类样例可以用于训练,因此,在映射测试类的输入样例的时候,就会产生一定的偏差。05
(1) 如果可以使用更好的算法,利用网络上现有的文本内容(例如各个类标签的维基百科),因为网络中的文本内容都是唾手可得的,可以大大减少零样本学习的工作成本,使得零样本学习推广到更多方面。(2) 图像特征映射函数以及语义向量映射函数是零样本学习的核心,可以考虑将语义向量映射至图像特征空间中,或是同时引入这两种映射,可能会得到更好的实验结果。(3) 和单样本、小样本学习结合,构建较为统一的模型。(5) 有研究将零样本学习和强化学习结合,也就是将ZSL的目标设计进强化学习的模型中去,使得agent能够执行在训练阶段未曾传授给它的知识。(6) 更加广泛的应用。除了常见的图像分类和视频事件检测,还可以将零样本学习应用到图像标注、多媒体跨模态检索、视频摘要、情感识别、行人再识别、自动问答、目标检测等不同领域。06
l CADA-VAE: Edgar Schönfeld, Sayna Ebrahimi, Samarth Sinha, Trevor Darrell, Zeynep Akata. “Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders.” CVPR (2019). [pdf] [code]l GDAN: He Huang, Changhu Wang, Philip S. Yu, Chang-Dong Wang. “Generative Dual Adversarial Network for Generalized Zero-shot Learning.” CVPR (2019). [pdf] [code]l DeML: Binghui Chen, Weihong Deng. “Hybrid-Attention based Decoupled Metric Learning for Zero-Shot Image Retrieval.” CVPR (2019). [pdf] [code]l LisGAN: Jingjing Li, Mengmeng Jin, Ke Lu, Zhengming Ding, Lei Zhu, Zi Huang. “Leveraging the Invariant Side of Generative Zero-Shot Learning.” CVPR (2019). [pdf] [code]l DGP: Michael Kampffmeyer, Yinbo Chen, Xiaodan Liang, Hao Wang, Yujia Zhang, Eric P. Xing. “Rethinking Knowledge Graph Propagation for Zero-Shot Learning.” CVPR (2019). [pdf] [code]l Tristan Hascoet, Yasuo Ariki, Tetsuya Takiguchi. “On Zero-Shot Learning of generic objects.” CVPR (2019). [pdf] [code]l AREN: Guo-Sen Xie, Li Liu, Xiaobo Jin, Fan Zhu, Zheng Zhang, Jie Qin, Yazhou Yao, Ling Shao. “Attentive Region Embedding Network for Zero-shot Learning.” CVPR (2019). [pdf] [code]l Zero-shot Knowledge Transfer via Adversarial Belief Matching.[code]: https://github.com/polo5/ZeroShotKnowledgeTransferl Transductive Zero-Shot Learning with Visual Structure Constraint.[code]: https://github.com/raywzy/VSCl Instance Credibility Inference for Few-Shot Learning论文地址:https://arxiv.org/abs/2003.11853代码:https://github.com/Yikai-Wang/ICI-FSL07
[1] Lampert C H , Nickisch H , Harmeling S . Learning to detect unseen object classes by between-class attribute transfer[C]// 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009.[2] https://blog.csdn.net/weixin_40400177/article/details/103538438[3] https://blog.csdn.net/qq_42671132/article/details/103688468[4] 冀中, 汪浩然, 于云龙, 等. 零样本图像分类综述: 十年进展[J]. 中国科学: 信息科学, 2019 (10): 5.[5] 张鲁宁, 左信, 刘建伟. 零样本学习研究进展[J]. 自动化学报, 2020, 46(1): 1-23.
猜您喜欢:
超110篇!CVPR 2021最全GAN论文汇总梳理!
超100篇!CVPR 2020最全GAN论文梳理汇总!
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
 下载APP
下载APP