
图神经网络上的预训练模型,思考与总结



点击上方 蓝字关注我们
本文转自人工智能前沿讲习@微信公众号
作者:知乎—荷戟彷徨
地址:https://www.zhihu.com/people/li-xun-huan-47-95
目前,transformer在NLP和CV领域流行已经是一个不争的事实了。在这样的一个既定事实之上,基于pretrain+fine-tuning的思路去进行工业化应用也似乎达成了一种共识。但是,GNN GNN 领域似乎倒还停留在设计更好的图卷积结构这一层面上。于是,便也渐渐有一些论文开始聚焦于如何将transformer在NLP和CV领域的成功移植在graph上,并凭借于此衍生出一些或将产生一定意义的论文。本文便是对这一类论文的一个浅显的总结。

01在图上做预训练模型同传统的transformer有什么区别
在进行对论文的梳理之前,应当先思索一个问题:在图上做预训练模型,和常见的基于自然语言文本去做,二者之间有什么区别呢?
这里面其实有很大的区别,我所想到的有:
1.1 处理的对象(输入)在结构形态上不同
对于NLP中的一个Seqence,当我们限定了它的最大长度之后,便可以使用一个矩阵将该seqence的全部信息进行表达。但是,对于一个图,这个图本身就需要两个矩阵(节点特征构成的矩阵(特征矩阵)与表示节点间连接关系的矩阵(邻接矩阵))。
同时,图存在的问题是,这样的两个矩阵是不定长的,也就是说,这两个矩阵的大小会随着图的变化而变化,而对于Seqence,由于限定了一个maxlength,一个模型可以应付所有不定长的seq。
那么,针对于这个问题,是不是我们也为节点个数限定一个maxnum,问题就迎刃而解了呢?
或许是这样的!也或许不是。seqence具有一种天生的顺序性,甚至在transformer中还研究了【此处需要贴一个网页链接】各种各样的position encoding方式来使得模型的效果更好。但是,想象有一堆节点大小不同的图,如何对每一张图中的所有节点去构筑顺序,这其实是一个很棘手的问题。大概率情况下,训练得到的模型最好应当是不需要这种顺序性的(是吗?)。
1.2 任务不同
当然,粗略的看,NLP的两大任务和graph上的任务有一些共通之处,但是Graph上的任务花样还是要多一点的。虽然这两种东西的任务最终都是可以通过模型输出的embedding做一点变化得到。
在NLP里,主要就是NLU和NLG两大任务。NLG先按下不表【此处放置一个链接】,NLU则是围绕着seqence或token两个级别进行的。常见的NLU任务多以seqence为代表,比如两个句子是否是一个意思,从诸多选项里选出一个答案等等。token级别的任务主要是对seqence的每一个原子进行分类,比如判断一些词的词性、实体识别等。
在Graph中,由于多了一种信息维度,所以任务可以划分为三个层次:节点,边,图。
图上的任务多是理解性的,也就是判断该图属于什么类型。节点层面的就有点类似于token级别的操作了,而边的预测更为复杂一点,但是也没有离开理解的范畴。所以,在图上的任务基本上都是理解性质(也就是预测、分类这种)的,生成性质的工作似乎不是那么惹眼。此处所说的“生成”不是生成一个两个节点,而是生成一张图。这当然或许是因为图太复杂了,或者没有这类需求?
从二者的共通之处出发,就可以察觉到,将transformer移植到graph上是有前途的。但是图本身所依赖的信息同样十分有特色。所以一些pretrian模型不约而同地依据图上需要把握的信息的特点设定了适应于图上的预训练任务中。
1.3 最后一个问题:在图上做预训练模型,主要改进点在哪里?
依照目前的论文来看,主要包括两部分:
1. 模型架构上。也就是说,使用一种固定的预训练GNN结构去处理一类的图。这一部分的工作比较符合NLP里对transformer的改进。
2. 训练任务上。模型的结构仍然是GNN(一般适用于目前常用的所有GNN聚合算法),但是却使用了一些无监督的学习任务去预先对GNN进行训练,之后再进行有监督的训练。这一类工作的创新便是训练任务。
下面的工作将覆盖上述两种类型。
02相关工作
上面啰嗦了好多废话,竟然还没有开始谈论文!
2.1 GPT-GNN 生成式GNN模型
Hu, Ziniu, et al. "Gpt-gnn: Generative pre-training of graph neural networks." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
GPT名声在外,以至于大家忘了这是一个通用的缩写:Generative Pre-Training,也就是生成式预训练。所以,这篇工作的亮点不必多说,肯定就是借用类似于GPT的训练思路去训练GNN模型了。
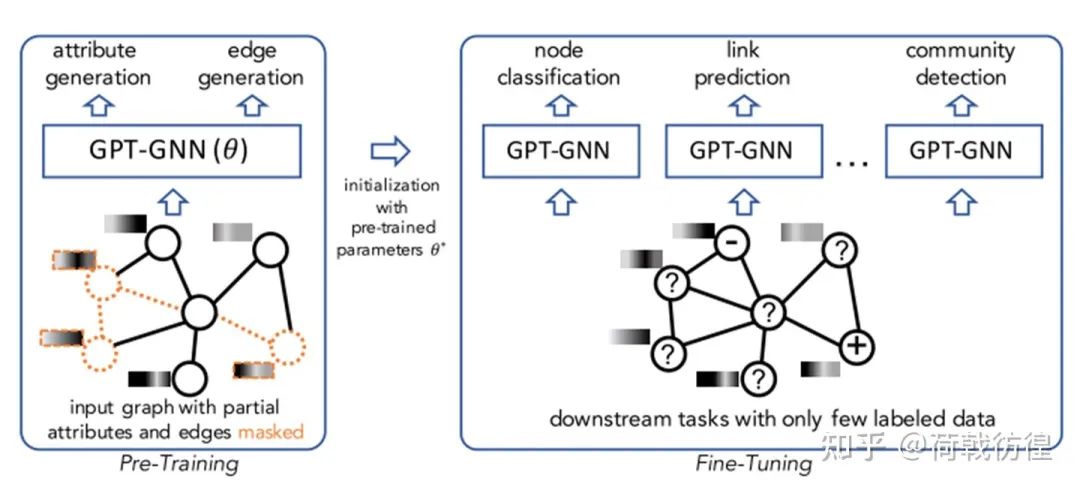
我们先看看论文中讲的故事:首先,这篇论文处理的对象是一种规模特别大的图(节点规模在10^8,边的规模在10^9),如Open Academic Graph(学术引用), Amazon Review Recommendation data等。在这么一类的图中,由于一张图本身的规模特别大,所以其实图的数量就很少——只有一个。并且,在这么一张图中,绝大多数的节点都是没有标签的,只有少量的节点有标签。
下图展示了这样一种预训练模型的用途——相当于一种上游的预训练,以获得一个相对而言更好的起始模型结果。
对于这样的一个问题,其实早有一些无监督的GNN算法可以完成这类任务,比如GAE(Graph Auto-Encoder),Graph SAGE,Graph Infomax等等。但是,这篇论文找到了新的噱头,它使用类比于GPT的方法重新做了一遍。下面的公式是这篇论文的核心思路。可以看出,这个公式和auto-regressive的形式是相当类似的,只不过预测的变量变多了。
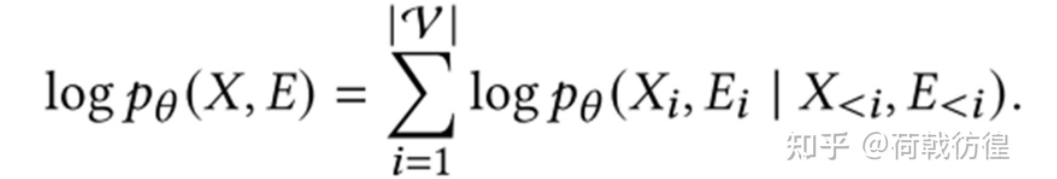
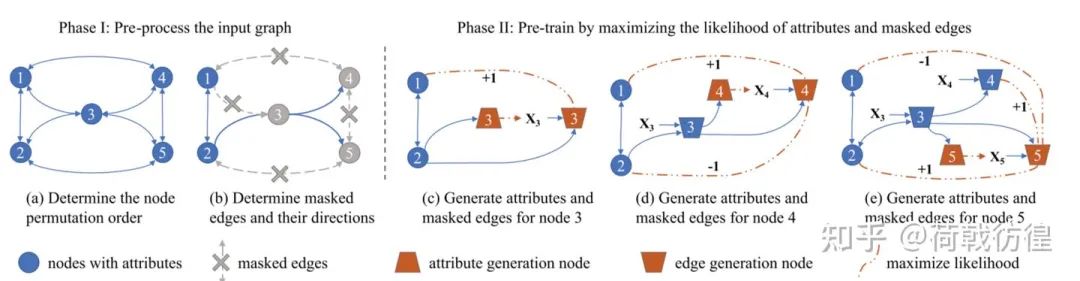
下面详细介绍其过程。图片看不太清楚,现列举文字过程:
1. 对图中的节点排好顺序(这样就形成了类似于文本的seqence);
2. 对于每一个输入节点, 预测它的attribute向量,预测它和前面所有的边的连接关系。需要注意的是,此处的attribute向量是指节点在一开始所保有的向量。比如,在一个论文引用网络里,每篇论文的题目、作者、年份、等等东西所形成的结果。
3. 将预测值和真实值放入损失函数,反向传播。
这样一个过程应当如何实现呢?
一种类似于朴素贝叶斯的想法是,假设边的预测和节点的预测是彼此独立的。这样,下面的公式
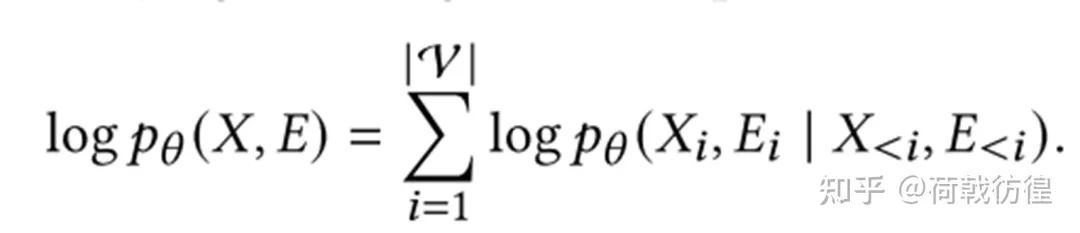
就变成了下面的公式
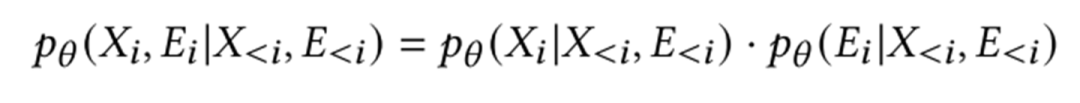
但是,这样的做法肯定是不好的,因为在图里,连接关系非常重要。因此,论文里对之进行了折衷:能否暴露一部分连接关系,然后去推断其他的连接关系,最终给出属性的预测。
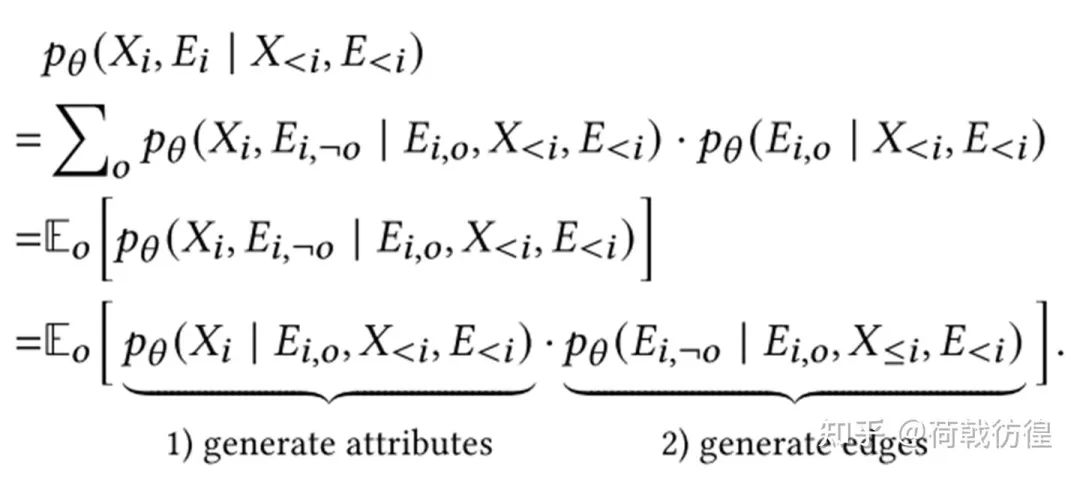
上面的公式大约是用全概率公式、概率密度的数学期望推出来的。
具体的实现上是这个样子的:使用某一种GNN(如GAT)作为encoder,选择一种合适的decoder(如MLP),然后基于下列的损失函数进行训练。训练完成后,Decoder舍弃,GNN就训练完成了。
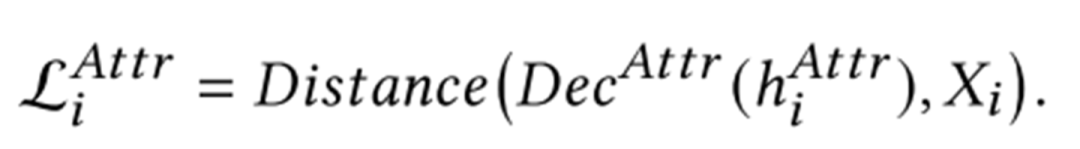
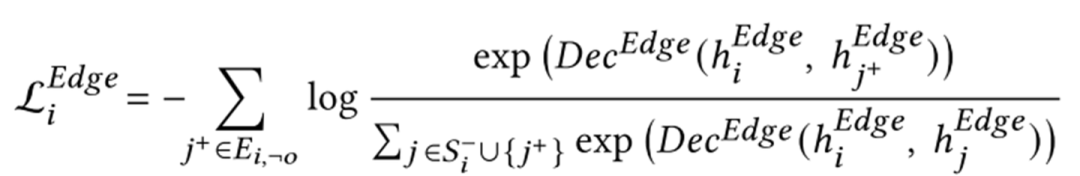
最后关心一下实验。下表展示了加入这种预训练任务前后的效果提升。
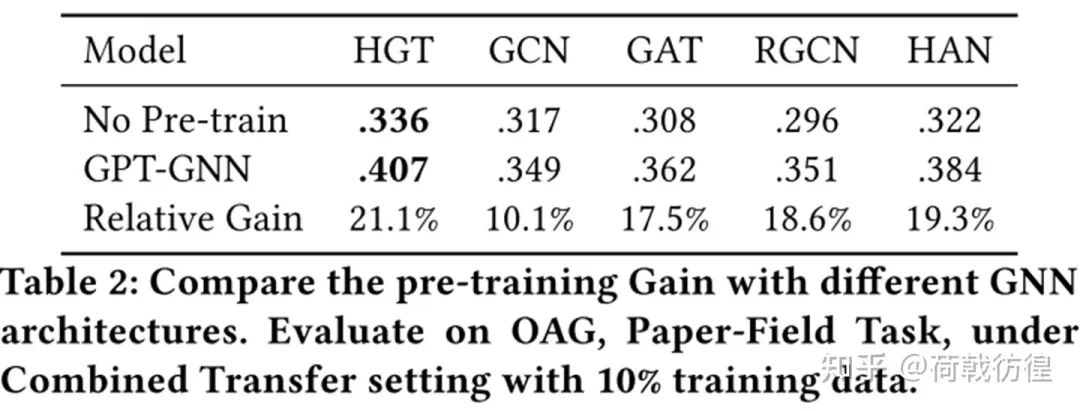
当然,这是在训练数据很少的前提之下。
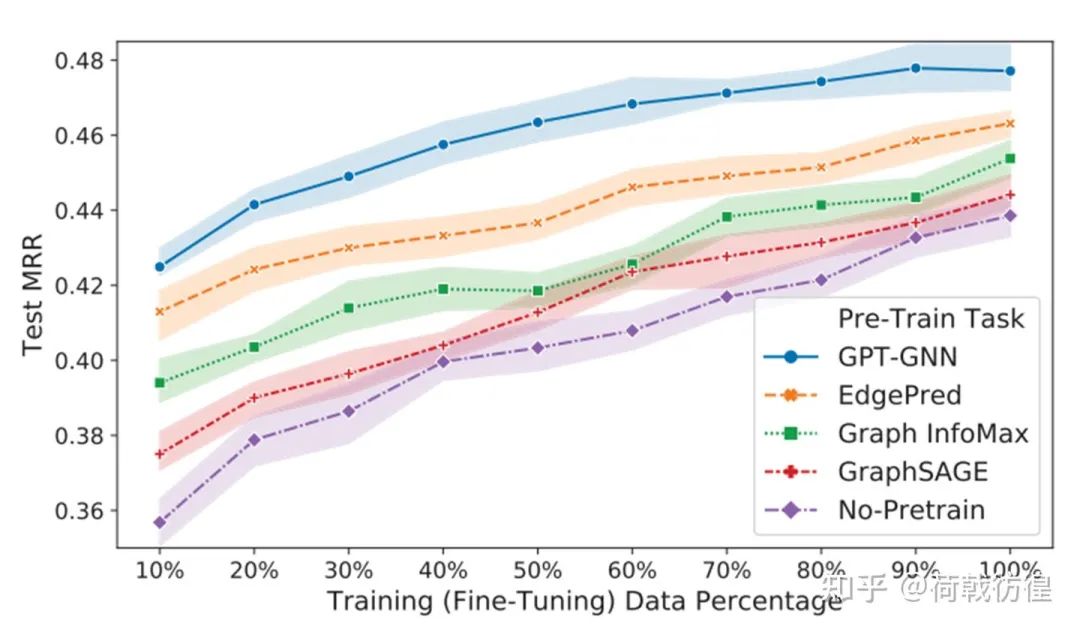
上图展示了相对于其他的一些无监督学习方法,GPT-GNN的效果。
2.2 基于对图的理解来设计任务
Hu, Weihua, et al. "Strategies for Pre-training Graph Neural Networks." arXiv preprint arXiv:1905.12265 (2019). ICLR 2020 Stanford University
在进行后续的介绍之前,不得不澄清一下,此处的图已经不再是上篇论文中所看到的“一场大图”了,而变成了一些相对而言比较小的图,如化学分子式等。与之带来的转变就是,图的数量也开始增多,因此,一些对图的理解也变成了任务之一。
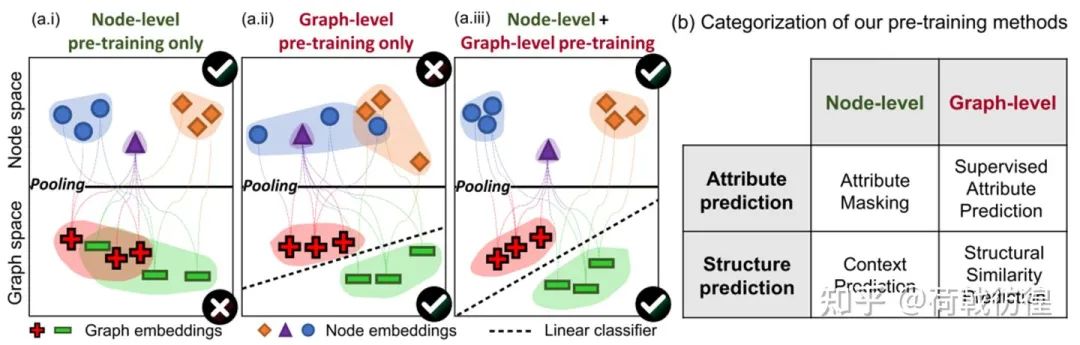
这篇论文所侧重的也是预训练任务的设计。其讲故事的思路是这个样子的:对于图上的任务,主要包括节点层面和图层面两种。而这两种任务恰恰在训练上容易造成一方很好另一方很差的情形。比如说,在上图左示例的样子,当只使用节点层面的预训练方法的时候,在图空间上的表示就不是很好;而在仅仅使用图层面的预训练任务时,节点层面的表示也不会很好。最好的方法是,同时进行两个层面的训练。
本着上述原则,作者对预训练方法进行了分类。从层面上来看,自然就是包括之前所说的节点层面和图层面。论文中主要包括了四个任务。但是,可以看出来,图层面的两个任务应该都是有监督的。因此,论文里着重笔墨的是节点层面的两个任务(好哇!绕了一圈,工作还是只在节点层面!)。下面依次介绍之。
1. Attribute Masking。这个任务显然是依照BERT等模型的masking想出来的。
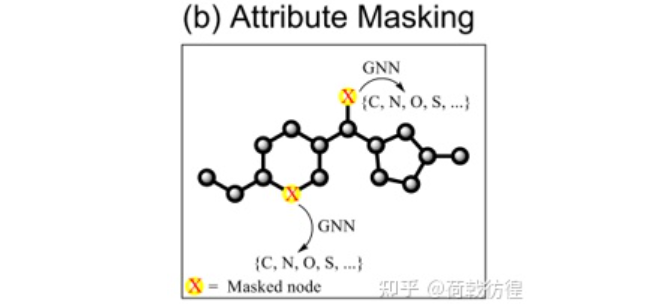
如上图所示,在一个化学分子式里随机遮挡住若干个原子,然后让GNN去猜被遮挡住的原子是什么,以此来构成自监督学习任务。
2. context prediction。这个在归类时被归为了structure prediction。其基本做法是这样的:选取指定节点的k阶邻居节点,并依照他们生成一些图结构,这些图结构的表示同GNN提取的中心节点的表示被要求尽可能的相似,也就是:
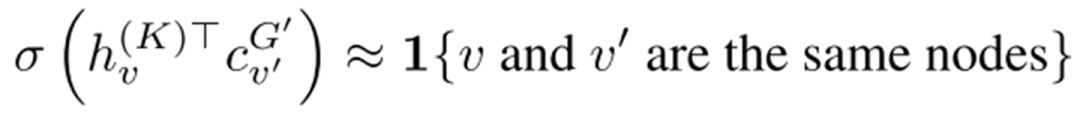
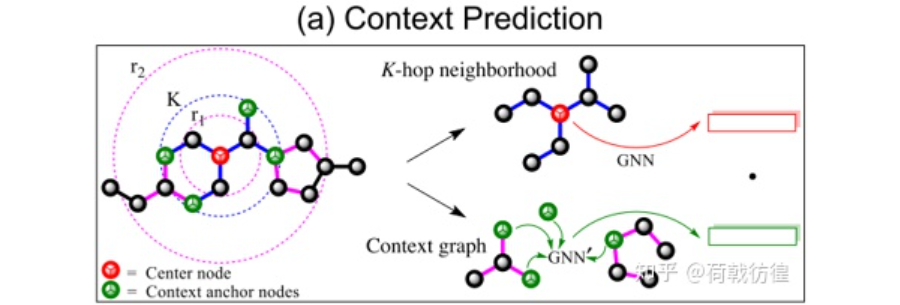
作者同样给出了是否使用这类预训练方式时,产生的增益可以有多少:

总结一下上述两篇论文的工作,可以发现:他们都是设计了一些新的训练任务,而非提出了一种新的GNN模型。那么,有没有一些工作是从模型结构上去做改进的呢?下面以一篇论文作此代表。
2.3 Graph Transformer
Rong, Yu, et al. "Self-Supervised Graph Transformer on Large-Scale Molecular Data." Advances in Neural Information Processing Systems 33 (2020). THU, Tencent AI.
这篇论文的工作对象同样也是化学分子相关的图。对于这样的图,论文没有再去使用GNN做处理,而是直接上了transformer。是的,就是直接上了transformer。
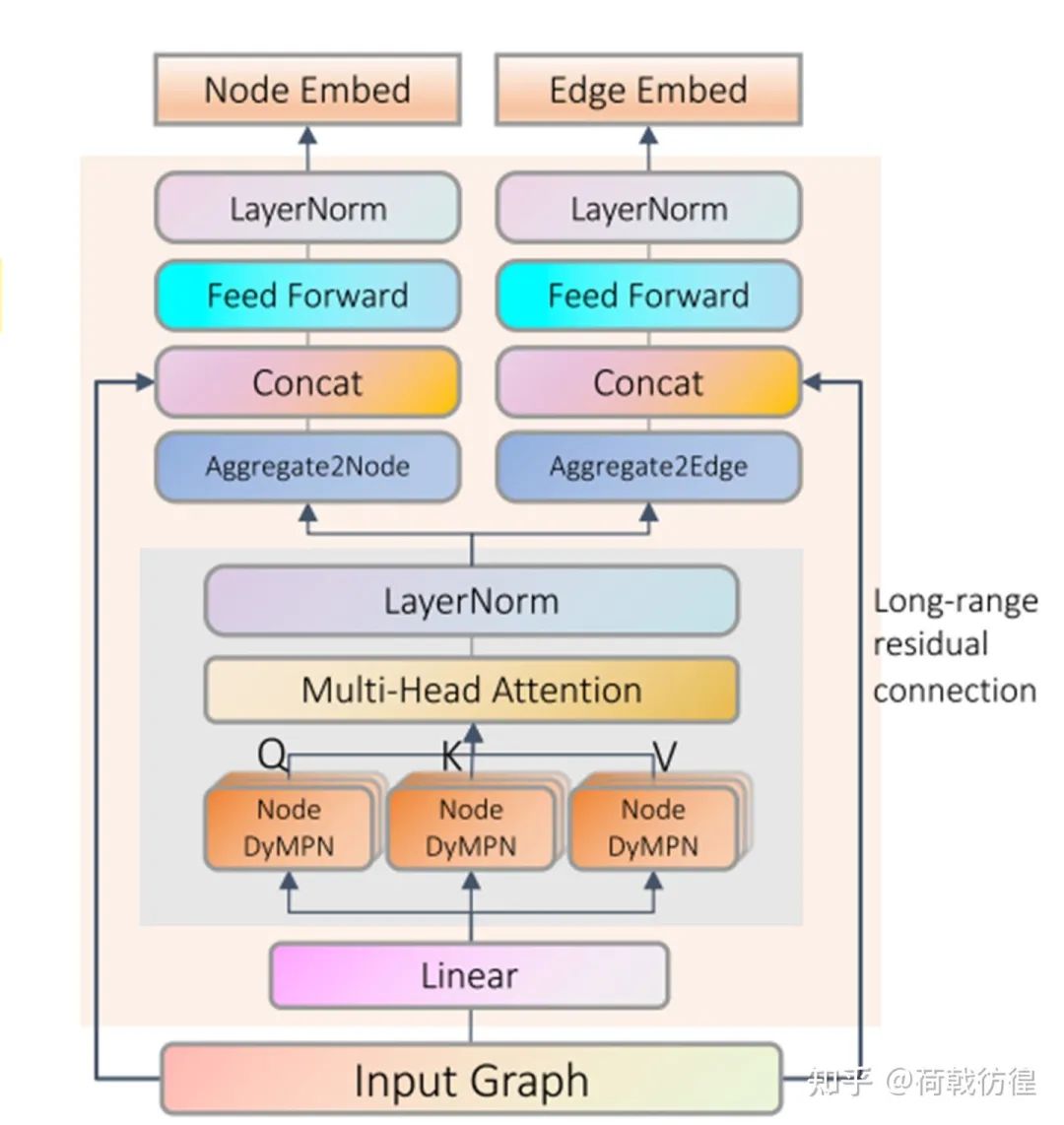
如上图所示,把一张图变成一个序列(具体的变动方法其实在GPT-GNN里已经讲过)之后,就可以进行类似于transformer layer的处理了。当然,作者还是做了一些微调。主要包括:
1. 生成QKV的方式。在transformer里,此处直接使用了一个线性映射。而在此处,则增加了一个聚合的过程:
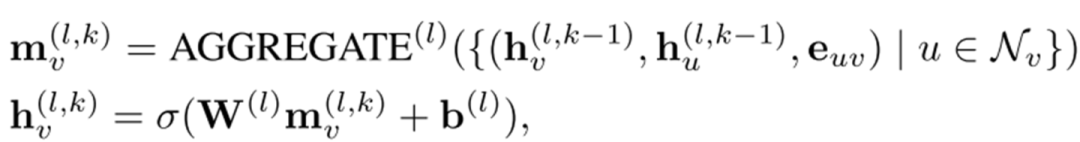
2. long-range residual connection。据说是为了解决over smoothing问题,这……
无论如何,这样的一个模型总归是完成了对transformer的最基本的处理了。那么,如何对之进行任务的设计呢?
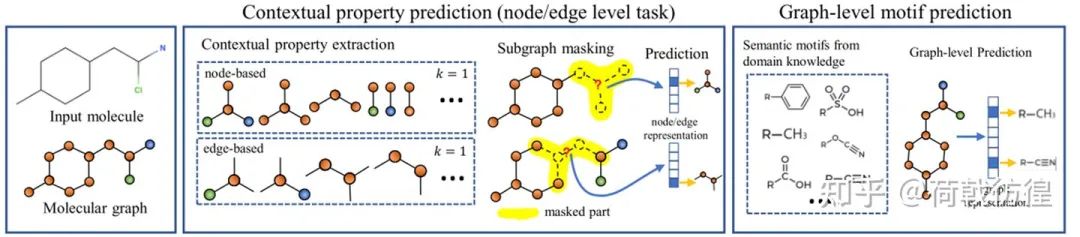
此处的任务设计主要包括两个,都更多的体现在结构性上。下面分别对之进行简单介绍。
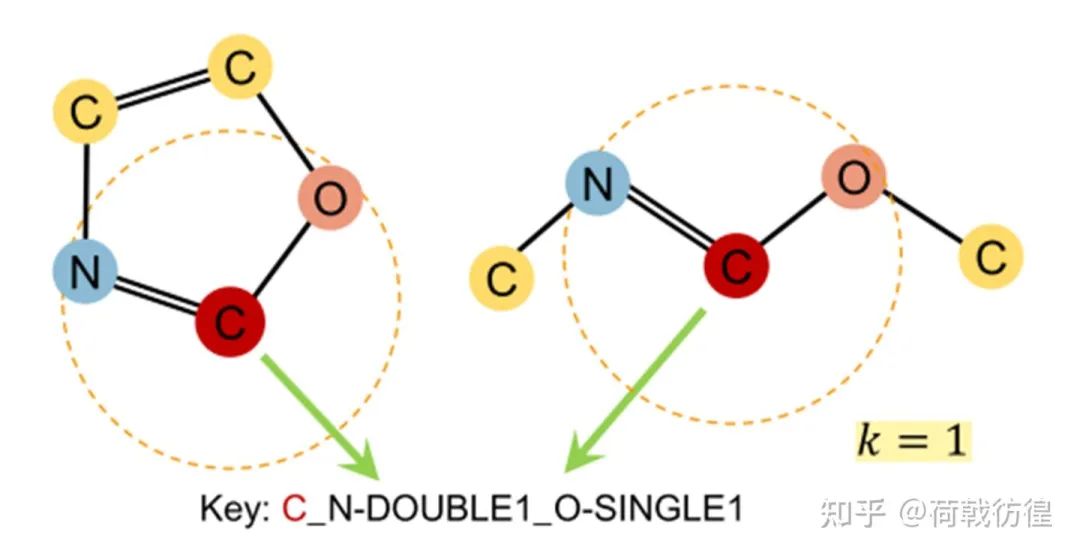
1. contextual Property Prediction。这个和上一篇论文中的结构预测很相似,但是预测的题目从一个类似于回归的问题变成了分类问题。如上图所示,对于我们的目标节点C,我们要预测他的contextual property,就是说,预测出来它和其它的节点以哪些方式连接,连接了几个。比如图中所示,就是1个2键的N和一个1键的O。
2. graph level motif prediction。这个是图层次上的任务,这个任务要做的事是预测一个图里有哪些基本的化学分子式构成单元。相当于是一个多标签分类任务。可以发现,这个任务明显是有监督的,但是,论文中说存在一些软件可以自动地检测得到所需要的表情,于是乎这个任务就变成无监督的了。
相关实验就不贴了。。
03 其他的一些参考论文
Pre-training GNN, ICLR'20
Gcc, KDD'20
DeepWalk(KDD14),
LINE(KDD15),
Node2Vec(KDD16)
