NLP 预训练家族再思考

本文约3000字,建议阅读6分钟
本文为你介绍使用NLP预训练的新思考。
SpanBERT
MASK策略:连续mask一个片段,而不像BERT一样,随机挑一些token进行mask。咦,谷歌在第二版BERT里就提出了whole word masking,同样是Span mask。那SpanBERT有什么不同呢?
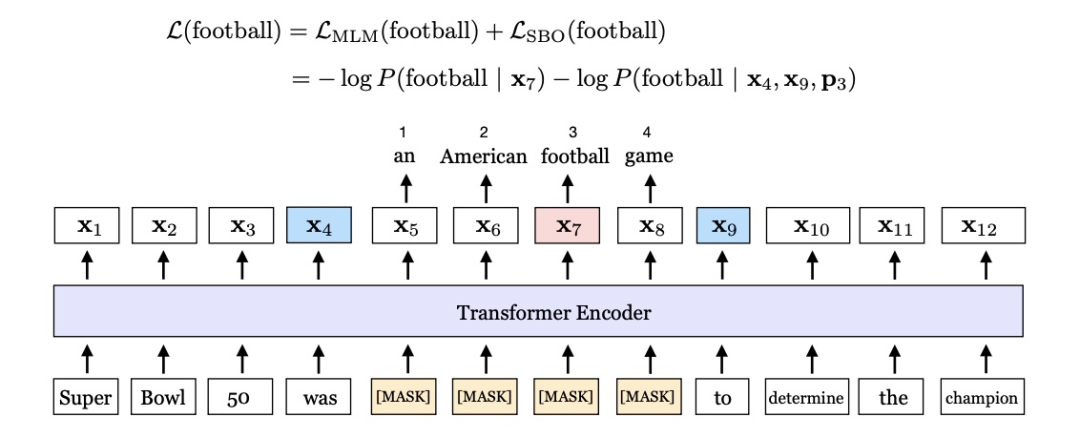
SpanBERT不同在于,首先每轮利用一个几何分布确定Span的长度 ,然后再找一些作为单词开头的token作为mask的start,然后从start token开始连续mask掉 个token,可以看到,「被MASK的Span不一定是一个完整单词的」。经过多轮反复,直到输入的15%token被mask。
SBO训练目标:用被mask的span左右两边的token去把整个span预测出来,这就是SBO(Span Boundary Objective)目标,如图所示,就是用was、to两个token去预测an American football game。作者解释说SBO目标,有助于模型在boundary token存储到span-lvel的信息,或者换句话说,作者希望span的左右两边结尾能更好地总结span的内容。
去掉NSP目标:作者认为两个原因,第一个原因去掉NSP目标让模型能学更长的依赖(如BERT,假如两个segment是从两个文档抽取的,可以认为512个token里面256个token是文档1的,另外256个token是文档2的,那其实能学到的最长文档依赖也就256,假如去掉它,512个token都是来自同一个文档,那模型能学到的最长依赖就是512),第二个原因,两个来自不同文档的片段会造成很大的噪声干扰。
消融实验
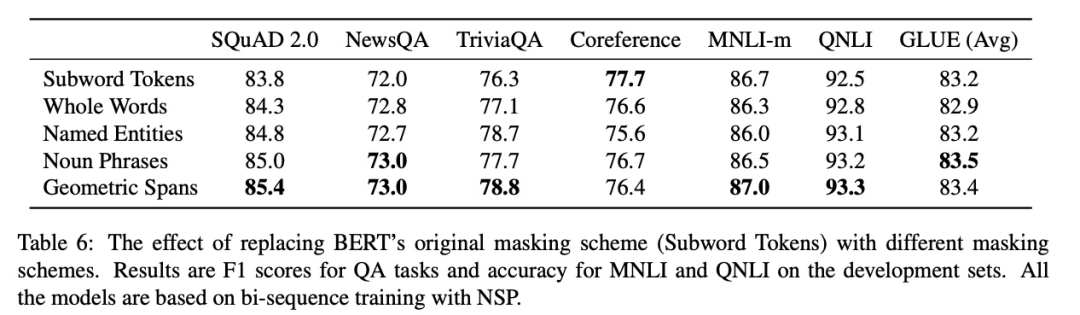
Subword Tokens:同原生BERT一样,随机选token进行mask Whole Words:同第二版BERT一样,采用whole word masking; Named Entities:一半是whole word masking,一半是实体词,直到15%的token被mask; Noun Phrases:一半是whole word masking,一半是名词短语,直到15%的token被mask; Geometric Spans:即SpanBERT。
辅助函数
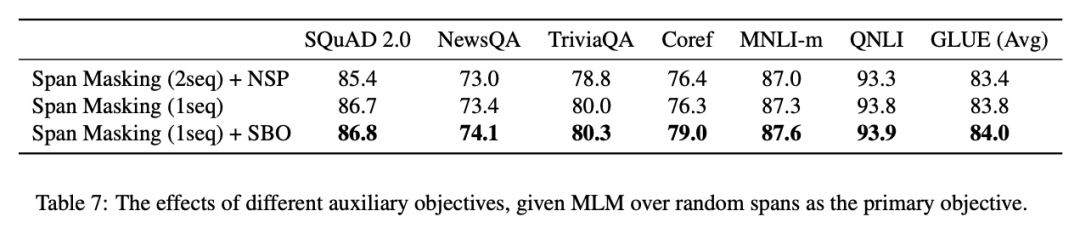
从实验结果可以看到,去到NSP任务,采样的时候从单个文档得到segment,增加SBO任务都能带来效果的提升。
MPNet
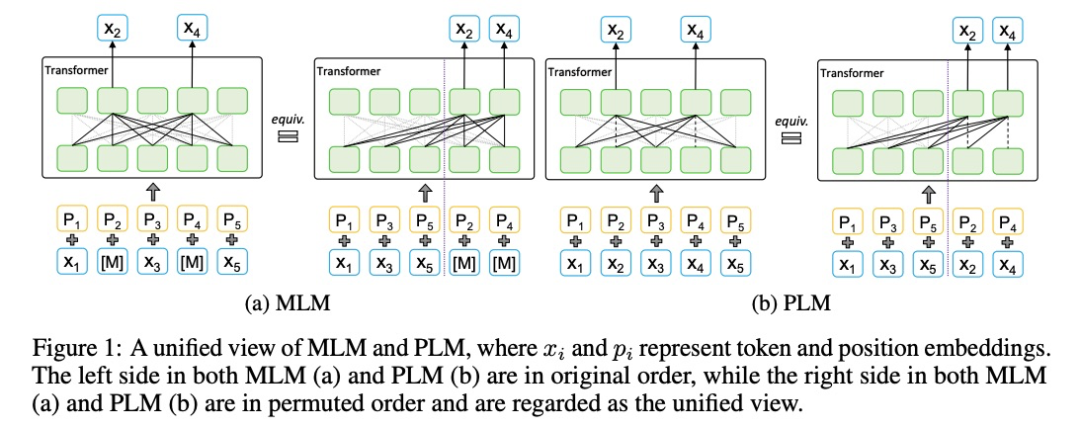
Output Dependency:BERT被mask掉的token之间是相互独立的,在预测的时候并没有利用到之间的关系。举个论文里的例子,【The, task, is, sentence, classification】,假如sentence、classification是两个被mask的token,在预测classification时,我们是不能利用上sentence的信息的,然而,假如给出前一个token为sentence的情况下,模型能更好地预测当前token为classifcation。
Input Consistency:解决Output Dependency的方法就是采用像XLNet这种PLM(permutation language model)。但PLM也有问题,当预测当前token时,PLM是没有其它待预测token的位置信息的,拿上面的例子举例,当模型开始预测sentence classification前,PLM是不知道有两个待预测词的,作者把PLM的这种缺陷称为Input Consistency问题,因为在实际下游任务中,输入时,是能知道所有token的内容和位置信息的。
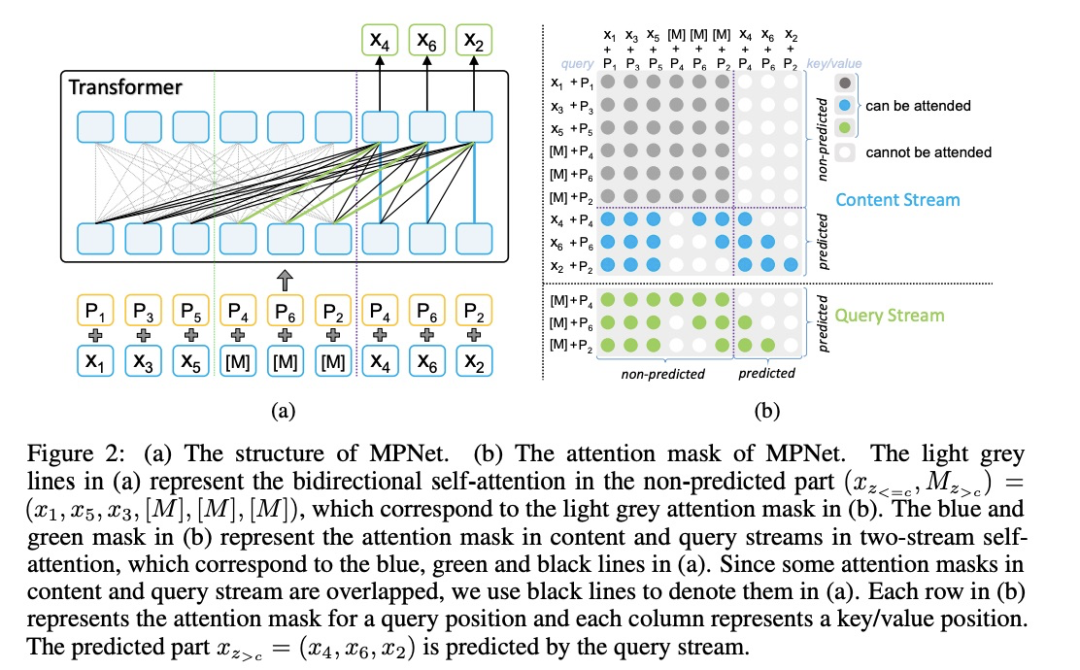
去掉position compensation,此时MPNet退化成PLM,效果下降了0.6-2.3个点,证明了position compensation的有效性以及MPNet优于PLM;
去掉permutation操作,但采用双向流建模待预测token之间的依赖关系,效果下降了0.5-1.7个点,证明了permutation的有效性;
去掉permutation和output dependency,此时MPNet退化成BERT,效果下降0.5-3.7个点,证明了MPNet优于BERT。
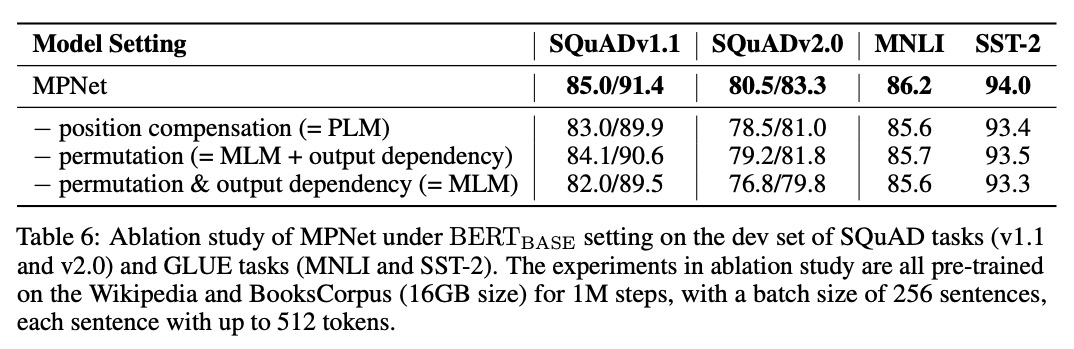
MASS
任务是「给定一个句子,从里面抽取一个片段,encoder端输入被抽取片段后的句子,docoder输出预测该片段」。
只预测被mask的token,而不是预测出原序列,可以让encoder端更好地学习到unmasked的token,同时能让decoder端从encoder端提取更有用的信息;
我个人理解是,假如现在decoder要预测的是完整序列,那当预测 时,模型能看到decoder之前预测的token,即 ,但模型看不到 ,这样的好处是,鼓励模型从encoder端提取有用的信息,而不是过分关注于docoder端之前预测出的token对当前token的影响
抽取一个片段而不是抽取离散的token,可以让模型学习到更好的语言模型建模能力,也即更适用于NLG任务。


消融实验
Study of Dfferent k:就是被mask的fragment长度为原序列的百分之多少比较好,作者的实验证明,50%是最好的。就是假如一个句子有100个token,最好选择连续的50个token作为待预测的fragment。
Ablation Study of MASS:作了两个比较实验,证明MASS预训练任务的有效性
Discrete:对离散的token进行mask,而不是连续的span;
feed:decoder的输入端是原句子序列,而不只是fragment。

BART
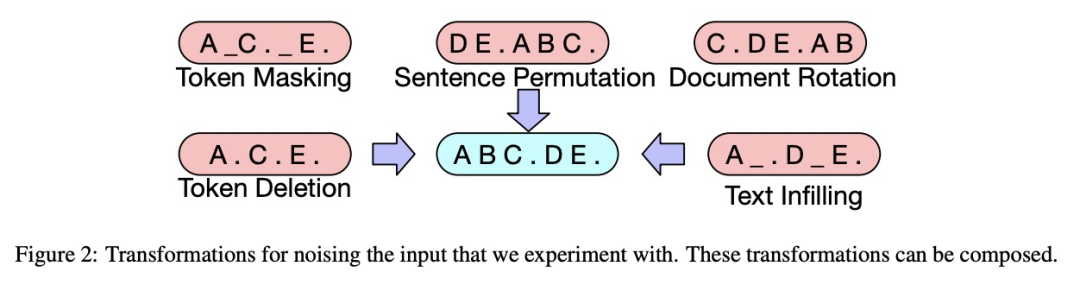
用一个任意的noising function去破坏原句子序列; decoder端目标是重构原句子序列。
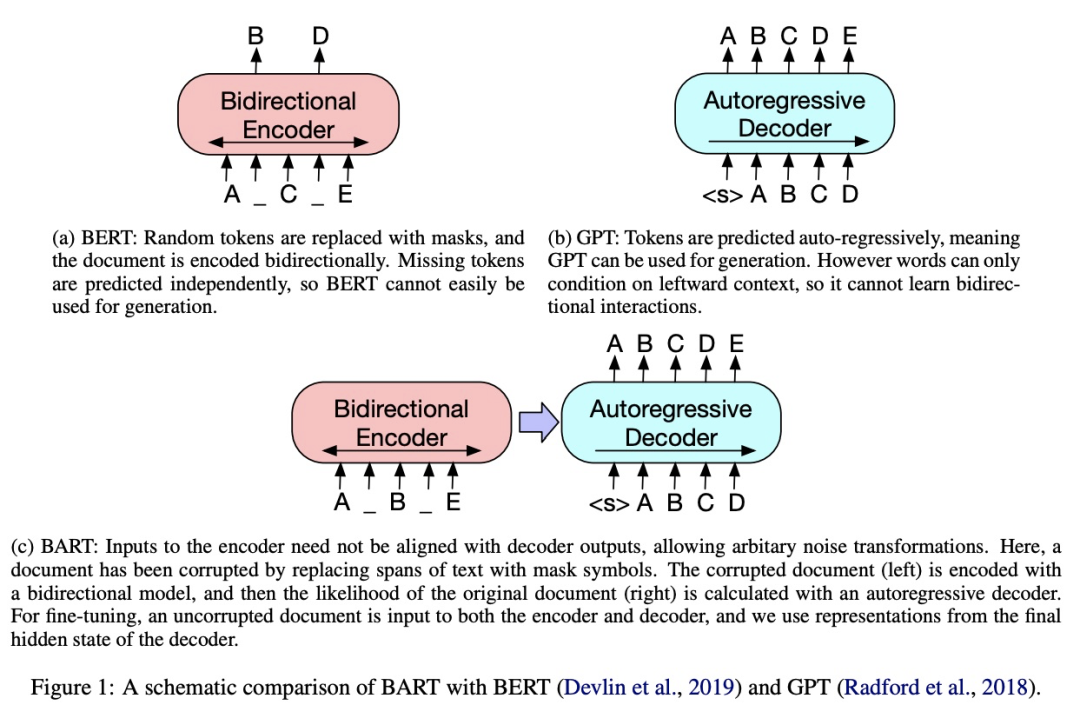
Token Masking:同BERT一样,随机挑选一些token,然后用【MASK】代替; Token Deletion:直接删掉某些token; Text Infilling:对一段连续的span进行mask,与SpanBERT不同的是,这里采用泊松分布决定Span的长度,其次,「连续的Span只会用一个【MASK】进行代替,作者解释是这样有利于模型学会预测这个Span有多少个token」; Sentence Permutation:打乱句子的顺序; Document Rotation:反转整个文档。