
图神经网络GNN预训练技术进展概述
来源:图与推荐 本文约2800字,建议阅读5分钟
本文为大家推荐四篇有关于GNN预训练的文章。

Learning to Pre-train Graph Neural Networks Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation GPT-GNN: Generative Pre-Training of Graph Neural Networks Strategies for Pre-training Graph Neural Networks


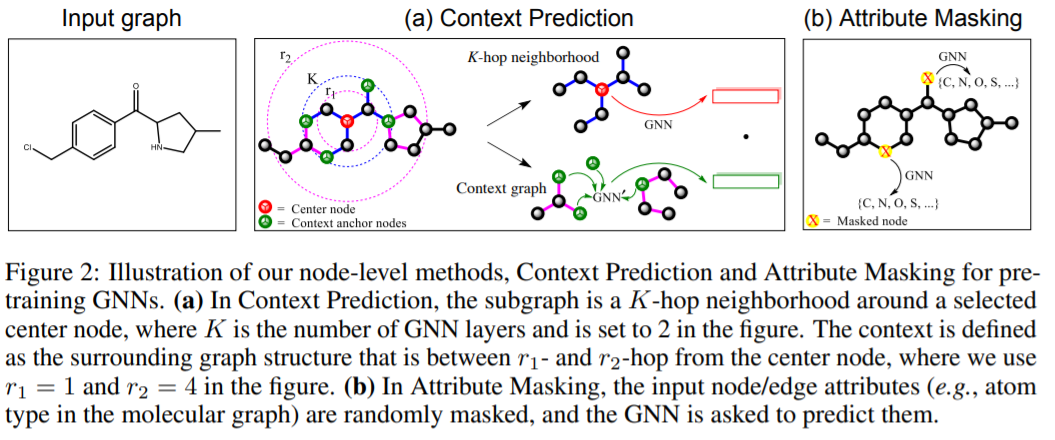



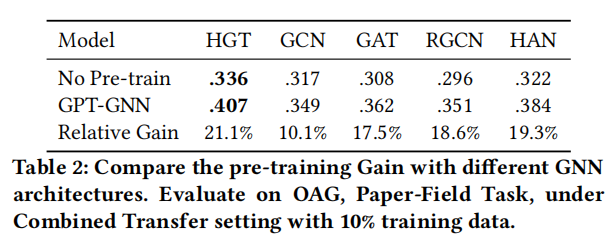

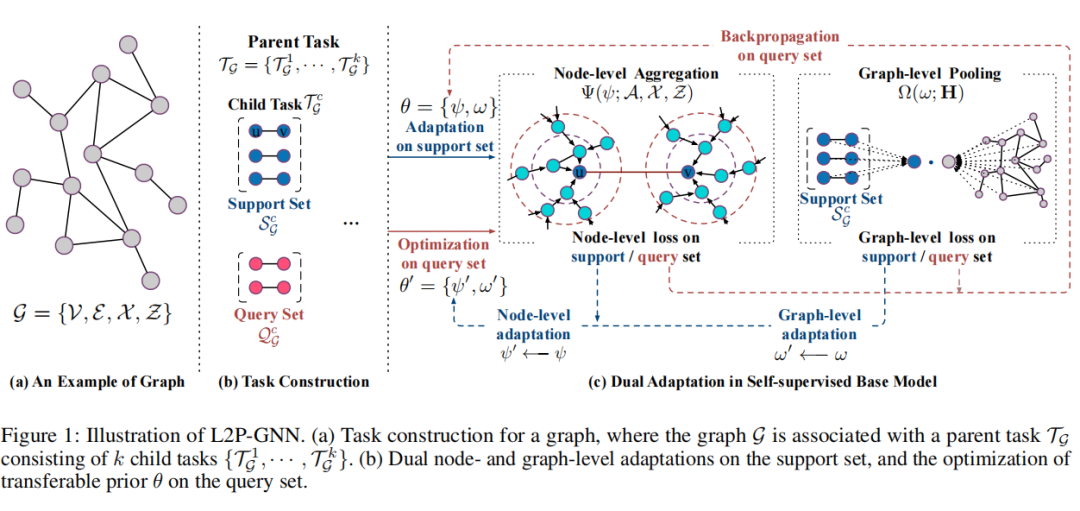
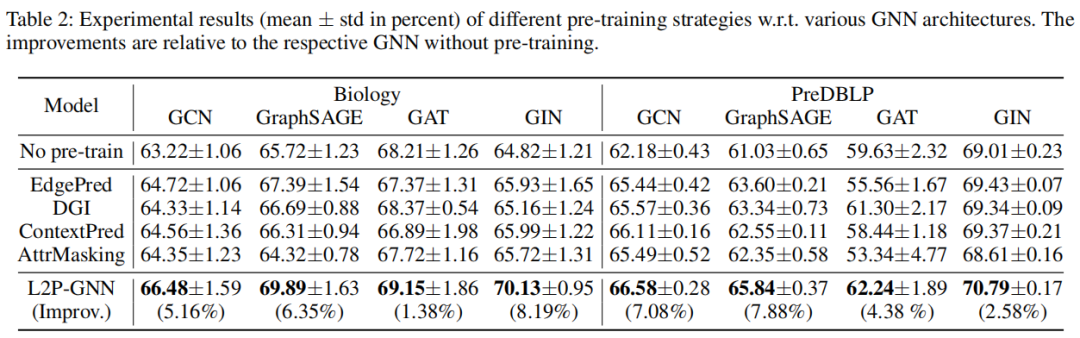


评论