
GNN教程:与众不同的预训练模型!
0 引言
虽然 GNN 模型及其变体在图结构数据的学习方面取得了成功,但是训练一个准确的 GNN 模型需要大量的带标注的图数据,而标记样本需要消耗大量的人力资源,为了解决这样的问题,一些学者开始研究Graph Pre-training的框架以获取能够迁移到不同任务上的通用图结构信息表征。
在NLP和CV领域中,学者已经提出了大量的预训练架构。比如:BERT(Devlin et al., 2018)和VGG Nets (Girshick et al., 2014),这些模型被用来从未标注的数据中学习输入数据的通用表征,并为模型提供更合理的初始化参数,以简化下游任务的训练过程。
后台回复【GNN】进图神经网络交流群。
这篇博文将向大家介绍图上的预训练模型,来自论文Pre-Training Graph Neural Networks for Generic Structural Feature Extraction 重点讨论下面两个问题:
GNNs 是否能够从预训练中受益? 设置哪几种预训练任务比较合理?
1 预训练介绍
本节将向大家介绍什么是模型的预训练。对于一般的模型,如果我们有充足的数据和标签,我们可以通过有监督学习得到非常好的结果。但是在现实生活中,我们常常有大量的数据而仅仅有少量的标签,而标注数据需要耗费大量的精力,若直接丢掉这些未标注的数据也很可惜。因此学者们开始研究如何从未标注的数据中使模型受益。
一个简单的做法是我们自己为这些未标注数据"造标签",当然这些标签和我们学习任务的最终标签不一样,否则我们也不用模型学习了。举个简单例子,比如我们想用图神经网络做图上节点的分类,然而有标签的节点很少,这时候我们可以设计一些其他任务,比如利用图神经网络预测节点的度,节点的度信息可以简单的统计得到,通过这样的学习,我们希望图神经网络能够学习到每个节点在图结构中的局部信息,而这些信息对于我们最终的节点分类任务是有帮助的。
在上面的例子中,节点的标签是我们最终想要预测的标签,而节点的度是我们造出来的标签,通过使用图神经网络预测节点的度,我们可以得到1)适用于节点度预测的节点embedding 2)适用于节点度预测任务的图神经网络的权重矩阵,然后我们可以1)将节点embedding接到分类器中并使用有标签的数据进行分类学习 2)直接在图神经网络上使用有标签的数据继续训练,调整权重矩阵,以得到适用于节点分类任务的模型。
以上就是预训练的基本思想,下面我们来看图神经网络中的预训练具体是如何做的。
2 GCN 预训练模型框架介绍
如果我们想要利用预训练增强模型的效果,就要借助预训练为节点发掘除了节点自身embedding之外的其他特征,在图数据集上,节点所处的图结构特征很重要,因此本论文中使用三种不同的学习任务以学习图中节点的图结构特征。通过精心设计这三种不同任务,每个节点学到了从局部到全局的图结构特征,这三个任务如下:
边重建:首先mask一些边得到带有噪声的图结构,训练图神经网络预测mask掉的边; Centrality Score Ranking:通过对每个节点计算不同的 Centrality Score,其中,包括:Eigencentrality, Betweenness, Closeness和 Subgraph Centrality;然后,通过各个 Centrality Score 的排序值作为label训练 GCN; 保留图簇信息:计算每个节点所属的子图,然后训练 GNNs 得到节点特征表示,要求这些节点特征表示仍然能保留节点的子图归属信息。
整个预训练的框架如下图所示,首先从图中抽取节点的结构特征比如(Degree, K-Core, Clustering Coefficient等),然后将这些结构特征作为embedding来学习设定的三个预训练任务,label使用的是从图中抽取的各个任务对应的label,最后得到节点embedding表征接到下游的学习任务中。
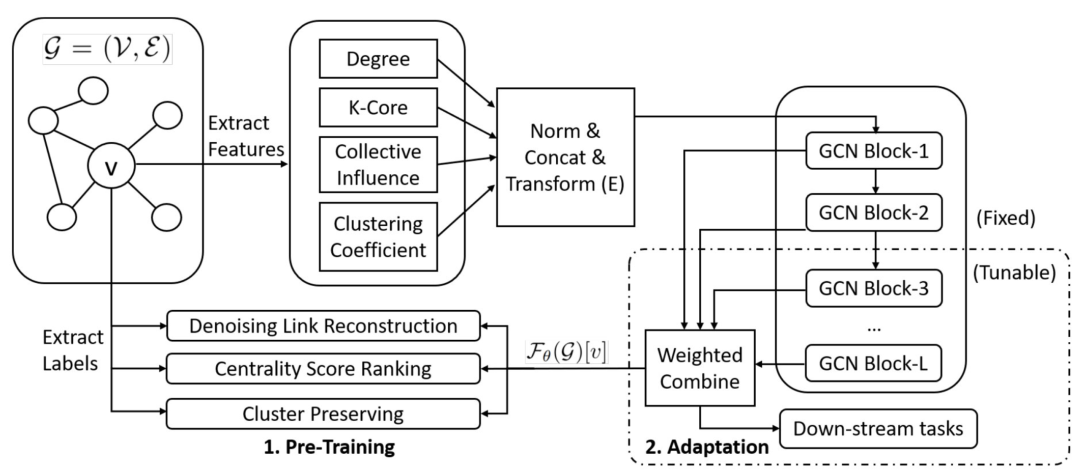
图注:应用 GCN 作为子模块的图预训练框架
2.1 预训练任务介绍
任务 1:边重建
任务 1 的思路是这样的,首先,随机删除输入图 中一些已存在的边以获得带有噪声的图结构 ;然后, GNN 模型使用
作为输入,记作编码器,学习到的表征信息输入到 NTN 模型中,NTN 模型是一个解码器,记作,以一对节点的embedding作为输入,预测这两个节点是否相连:其中, 和 采用二元交叉熵损失函数进行联合优化:
通过边重建任务,预训练的GNN能够学习到节点embedding的一种较为鲁棒的表示,这种表示在含有噪声或者边信息部分丢失的图数据中很有效。
任务 2:Centrality Score Ranking
作为图的重要指标之一,Centrality Score 能够根据节点位于图中的结构角色来衡量节点的重要性。通过预训练 GNN来对节点的各种 Centrality Score 进行排序,GNN便能够捕获每个节点位于图中的结构角色。论文中,作者主要用了如下4中Centrality Score:
Eigencentrality:从高分节点对邻居贡献更多的角度衡量节点的影响,它描述了节点的在图中的'hub'角色,和PageRank非常类似。 Betweenness 衡量某节点位于其他节点之间的最短路径上的次数,他描述了节点在整个图中的 'bridge' 角色; Closeness 衡量某节点与其他节点间的最短路径的总长度,他描述了节点在整个图中的 'broadcaster' 角色。 Subgraph Centrality 衡量某节点对所有子图的参与度(到所有子图最近路径长度的和),他描述了节点在整个图中的'motif'角色。
以上四种Centrality Score描述了节点在整个图中所承担的不同角色,因此,通过这四种Centrality Score的学习任务节点的embedding能够标注不同粒度的图结构信息。
但是,由于Centrality Score在不同尺度的图之间无可比性,因此,需要利用Centrality Score的相对次序作为任务学习的标签。也就是说,对于节点对 和 Centrality Score ,他们间的相对次序记作 ,解码器 通过 估计排序。利用(Burges et al., 2005)所定义的成对排序方法,由以下公式估计排名的概率:
最后,我们通过下式优化每一个Centrality Score 的 和 :
通过Centrality Score Ranking任务,预训练的GNN能够学习到图中的每一个节点在全局中起到的作用。
任务 3:保留图簇信息
作为图的重要指标之一,子图结构意味着簇内部节点的连接更加密集而簇间的节点连接稀疏。假设图中节点属于个不同的簇 ,并且存在指示函数 来告知给定节点是否属于簇 。这个指示函数可以通过程序的算法得到,比如联通子图算法。然后我们预训练 GCN 以学习特定的节点表示,要求该表示能在一定程度上保留节点所属簇信息。
大致做法如下,首先,使用一个基于注意力机制的aggregator来获取簇信息的表示:
然后,使用NTN模型作为一个解码器来评估节点属于簇的可能性:
节点属于簇的概率可表示为:
最后,通过以下方法进行对 和 进行优化:
通过保留图簇信息的预训练任务,GNN能够学习到将图中的节点嵌入到可以保留对应簇信息的表示空间中。
本节小结
在此做一个小结,我们设计了边重建、Centrality Score Ranking、保留图簇信息三种图预训练任务,这三个任务能够生成节点embedding对图结构的局部到全局表示,有利于下游的学习任务。
2.2 应用于下游任务
通过上面所提到的带有 、 和 的三种任务上的预训练能够捕GNN来为图中节点生成结构相关的通用表征。接下去,我们可以将这些表征用于下游的任务,主要有两种应用方式:
作为额外特征:前面我们说到了,预训练GNN后学习到的节点表征与图的结构信息相关,那么这些表征可以结合节点自身的embedding作为节点新的embedding参与下游模型中。 微调(Fine Tuning,FT):预训练GNN后我们不仅得到节点的表征,还得到了GNN的网络参数,这些参数也和图结构学习息息相关,那么我们可以通过在预训练模型之后添加一个与下游任务相关的输出层,以根据特定任务对预训练模型参数进行微调。
本节小结
在此做一个小结,利用 2.1 节所提到方法预训练模型,使预训练模型能够从局部到全局上捕获图结构信息的不同属性,然后将预训练模型在特定的任务中做微调,最终应用于该特定任务中。举个例子,2.1 节所提到的训练预训练模型过程好比我们在高中阶段所学习的语、数、英、物、化、生等基础学科,主要用于夯实基础知识;而2.2节所提到的预训练模型在特定任务中的特征提取和微调过程,相当于我们在大学期间基于已有的基础知识,针对所选专业进行进一步强化,从而获得能够应用于实际场景的作用技能。