
Make GNN Great Again:图神经网络上的预训练和自监督学习

来源:RUC AI Box 本文约6500字,建议阅读13分钟
本文梳理近年来 GNN预训练和自监督学习/对比学习的相关工作。
1 引言
监督标签很难获取:一般来说,GNN 的训练需要充足的任务相关的标签数据,而获取这些标签数据又往往是昂贵且费力的 [6]。例如生物/化学数据上的标签,一般需要专业实验室进行实验以获取 [7, 8]。 GNN 不易训练:传统的 GNN 架构,在面对新任务或者更改了节点/边的特征时,只能重新训练。且一般来说,GNN 的训练需要较大的训练轮数才能达到较好的效果 [9]。
2 GNN + 预训练
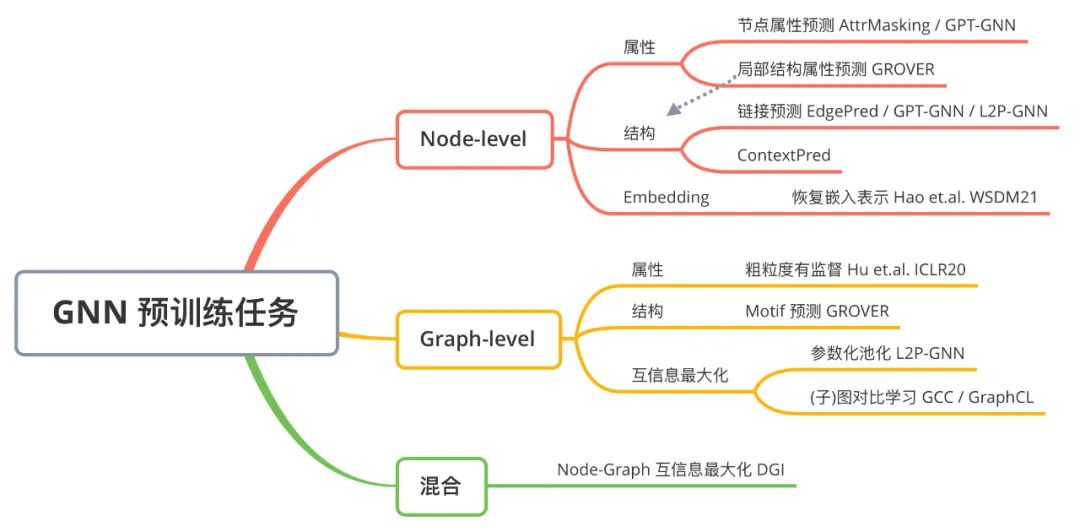
2.1 Strategies for Pre-training Graph Neural Networks [7]
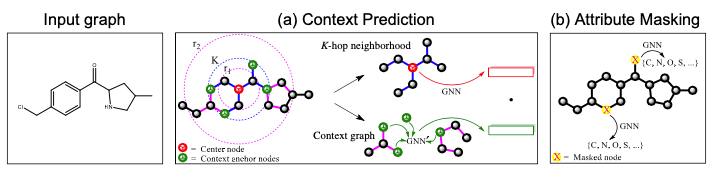
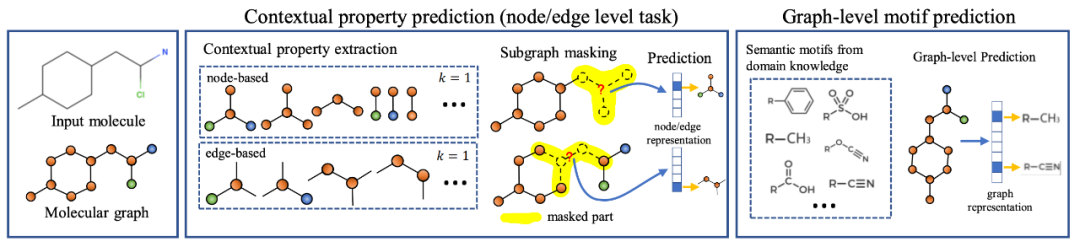
Context Prediction:类似 word2vec [14, 15] 的思想,根据节点的邻居来预测某个节点。对于一个中心节点(Center Node,上图 (a) 红色节点),定义其周围K跳邻居构成的子图为 Neighborhood,定义其r1跳至r2跳之间(可以看成一个环)的节点构成的子图为 Context Graphs。注意
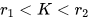 ,这样同一个中心节点对应的 Neighborhood 和 Context Graphs 之间存在节点的共享(上图 (a) 中绿色节点)。Neighborhood 通过正在预训练的 GNN 编码为向量,Context Graphs 则通过一个辅助的 GNN 编码为向量。本任务为,根据 Neighborhood 向量和 Context Graphs 向量,预测这两个子图是否由同一个中心节点生成而来。具体的预训练方法很像 word2vec,也是采用负采样的方法。
,这样同一个中心节点对应的 Neighborhood 和 Context Graphs 之间存在节点的共享(上图 (a) 中绿色节点)。Neighborhood 通过正在预训练的 GNN 编码为向量,Context Graphs 则通过一个辅助的 GNN 编码为向量。本任务为,根据 Neighborhood 向量和 Context Graphs 向量,预测这两个子图是否由同一个中心节点生成而来。具体的预训练方法很像 word2vec,也是采用负采样的方法。Attribute Masking:简略地说即为预测图中点/边的属性(特征)。在预训练的 GNN 后接简单的分类器,随机 Mask 点/边的属性进行预测。比如上图 (b) 中,根据邻居节点预测某个节点的原子序号。
Supervised Property Prediction:有时数据中会包含一些容易获得的粗粒度(coarse-grained)图级别标签,本任务即为有监督的图级别标签预测。
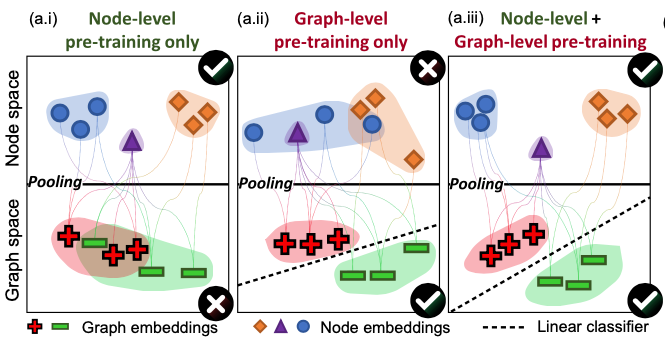
本文对应的代码实现中,先进行 Node-level 预训练,再基于 Node-level 的模型进行 Graph-level 的预训练,最后使用下游任务的数据集进行 Fine-tuning; 同时进行本文的两种 Node-level 预训练任务会使效果下降; 实验数据集中 out-of-distribution 指的是,下游任务的 test 和 train+valid 的分布是不同的。但预训练的时候其实是会使用下游任务的 test 中的全部图结构,以及部分粗粒度标签。为了避免数据泄漏,应保证 test 中用来评测的具有细粒度标签的图的集合,和用于有监督预训练的具有粗粒度标签的图的集合,相互正交。
2.2 GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training [16]
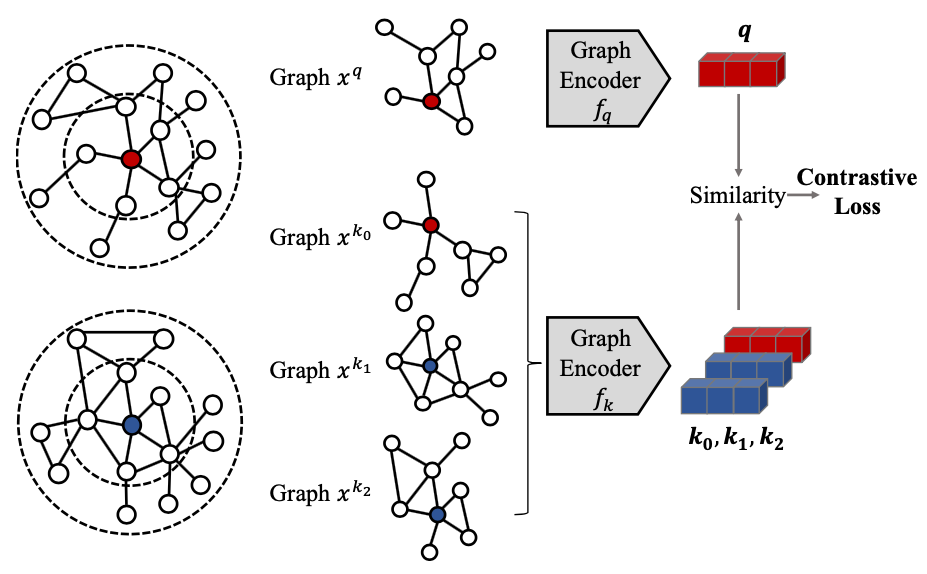
2.3 GPT-GNN: Generative Pre-Training of Graph Neural Networks [6]
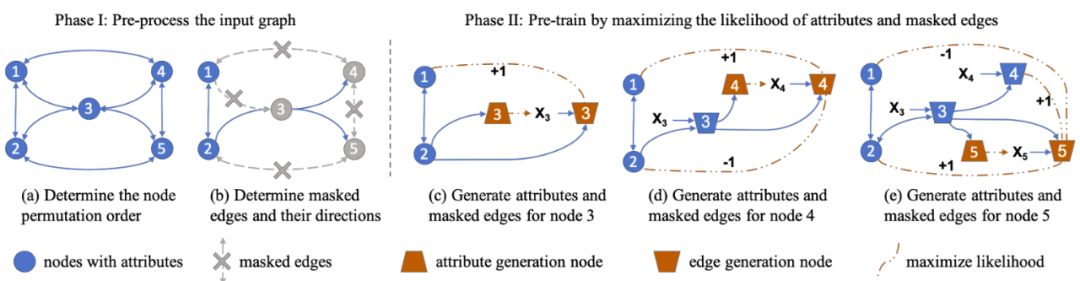
2.4 More Pre-training GNN Papers
Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation [17]
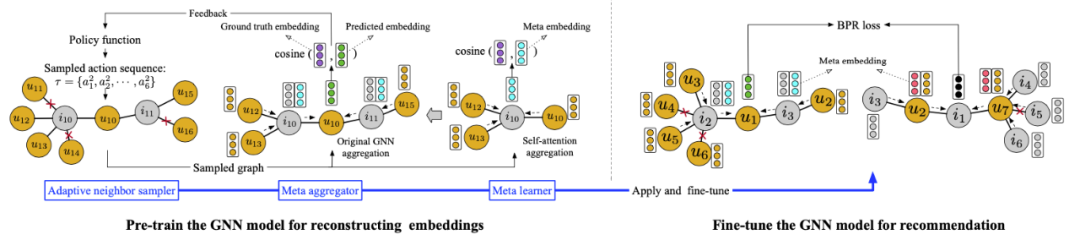
Learning to Pre-train Graph Neural Networks [19]
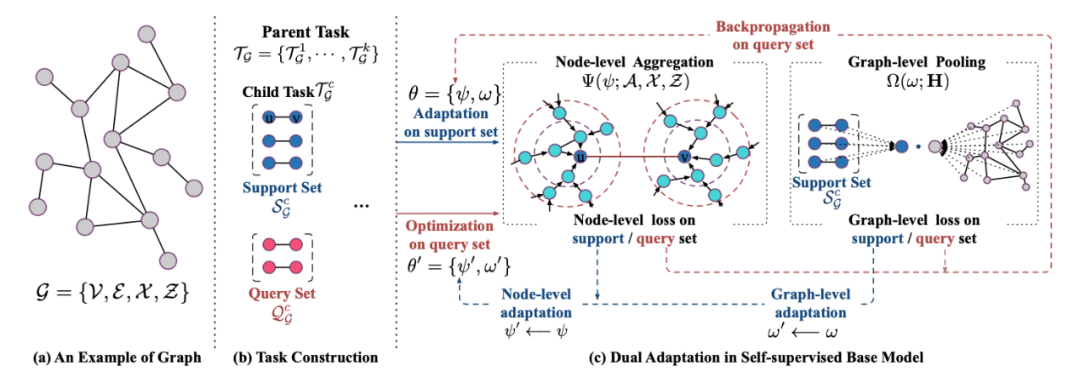
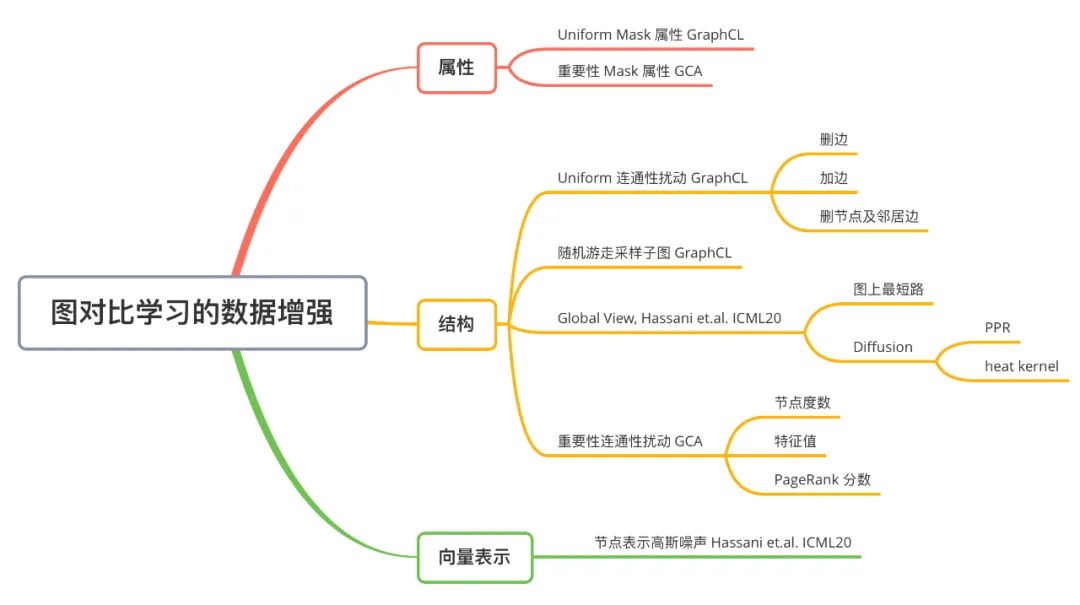
Graph Contrastive Learning with Augmentations [8]
Self-Supervised Graph Transformer on Large-Scale Molecular Data [21]
3 GNN + 自监督
3.1 Deep Graph Infomax [4]
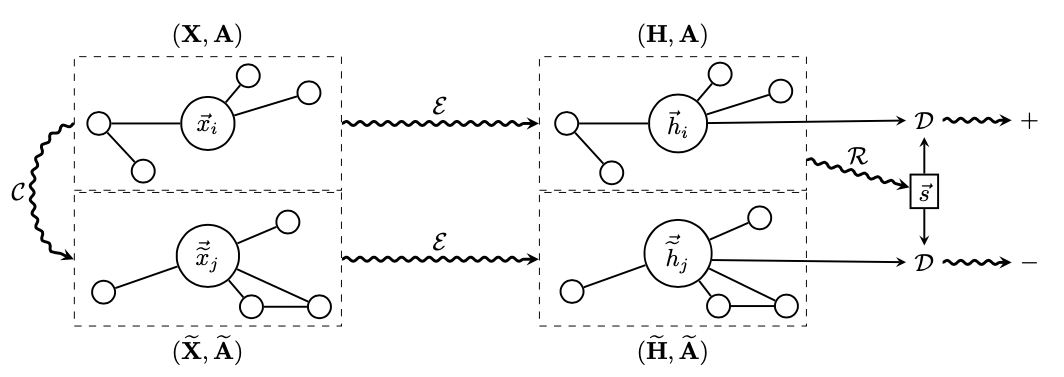
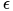 为 GNN Encoder,根据图结构将节点编码为H,节点表示经过一个 Read-out 函数可汇总为图表示向量
为 GNN Encoder,根据图结构将节点编码为H,节点表示经过一个 Read-out 函数可汇总为图表示向量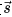 。同时,我们对原图进行扰动,并将扰动过的图经过相同的 GNN Encoder 得到扰动后的节点向量
。同时,我们对原图进行扰动,并将扰动过的图经过相同的 GNN Encoder 得到扰动后的节点向量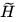 。通过 DecoderD,我们应使图表示与原图的节点表示H更接近,并使图表示与扰动图的节点表示更疏远。本文在较为传统的 Transductive 数据集 Cora、Citeseer、Pubmed 和 Inductive 数据集 Reddit 和 PPI 上进行实验,以验证 DGI 框架的通用性与有效性。注意本工作是将图表示与节点表示做对比,是 Node-Graph 模式的。
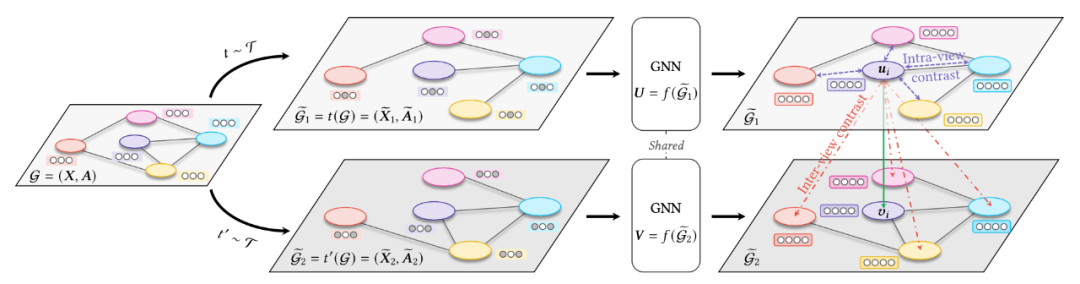
。通过 DecoderD,我们应使图表示与原图的节点表示H更接近,并使图表示与扰动图的节点表示更疏远。本文在较为传统的 Transductive 数据集 Cora、Citeseer、Pubmed 和 Inductive 数据集 Reddit 和 PPI 上进行实验,以验证 DGI 框架的通用性与有效性。注意本工作是将图表示与节点表示做对比,是 Node-Graph 模式的。3.2 Graph Contrastive Learning with Augmentations [8]
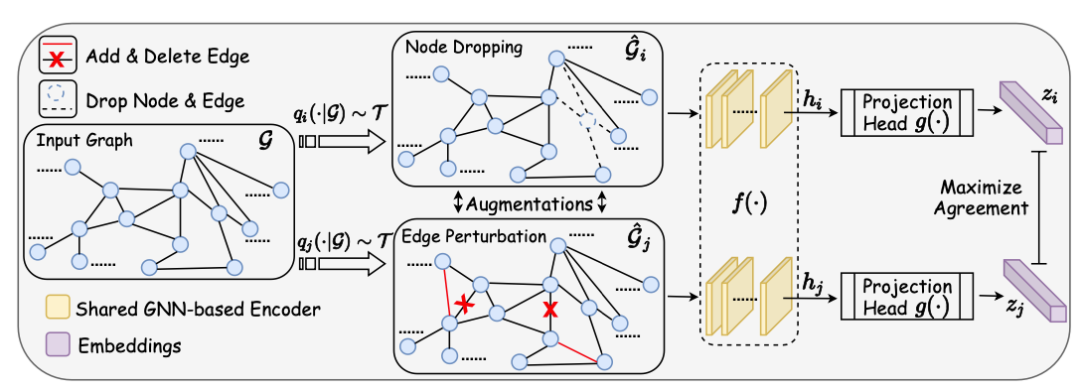
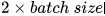 的 View 组成。这样同一个 batch 中,由相同的图增强得到的 View 互相之间为正例,不同的图增强得到的 View 互相之间为负例。对一个 batch 内的 View 均过一下 GNN Encoder(上图中的
的 View 组成。这样同一个 batch 中,由相同的图增强得到的 View 互相之间为正例,不同的图增强得到的 View 互相之间为负例。对一个 batch 内的 View 均过一下 GNN Encoder(上图中的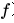 ),得到节点的表示向量
),得到节点的表示向量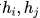 等。再经过非线形映射层g后,得到的图表示向量之间即可根据先前约定的正负例关系,计算对比学习的损失函数。在经过自监督的训练后,GNN Encoder 被保留,而非线形映射层被遗弃。
等。再经过非线形映射层g后,得到的图表示向量之间即可根据先前约定的正负例关系,计算对比学习的损失函数。在经过自监督的训练后,GNN Encoder 被保留,而非线形映射层被遗弃。Node Dropping:随机删除图中的节点及与之相连的边; Edge Perturbation:随机增加 / 删除图中一定比例的边; Attribute Masking:随机 Mask 节点的属性; Subgraph:使用随机游走算法得到的子图(假设图的语义信息可以较大程度上被局部结构保留);
3.3 Contrastive Multi-View Representation Learning on Graphs [24]
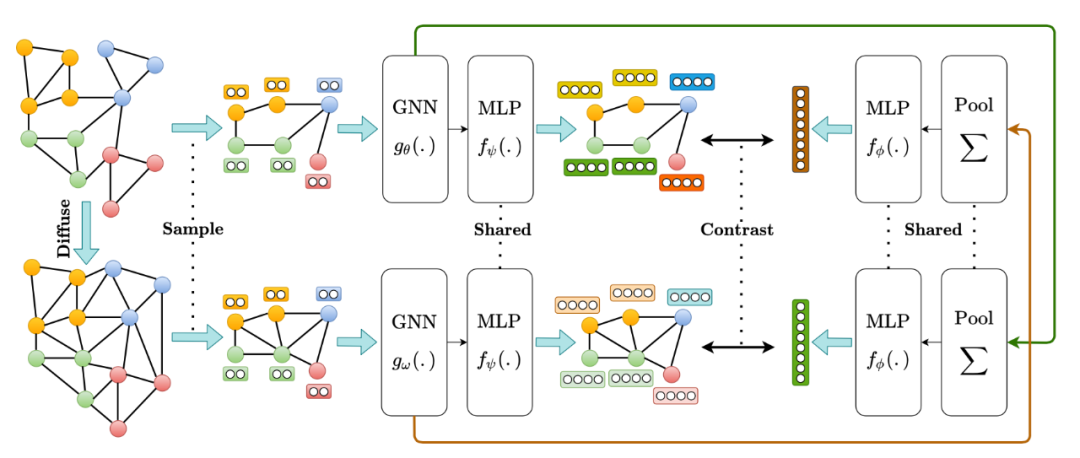
3.4 More Self-supervised GNN (Graph Contrastive Learning) Papers
Graph Contrastive Learning with Adaptive Augmentation [26]
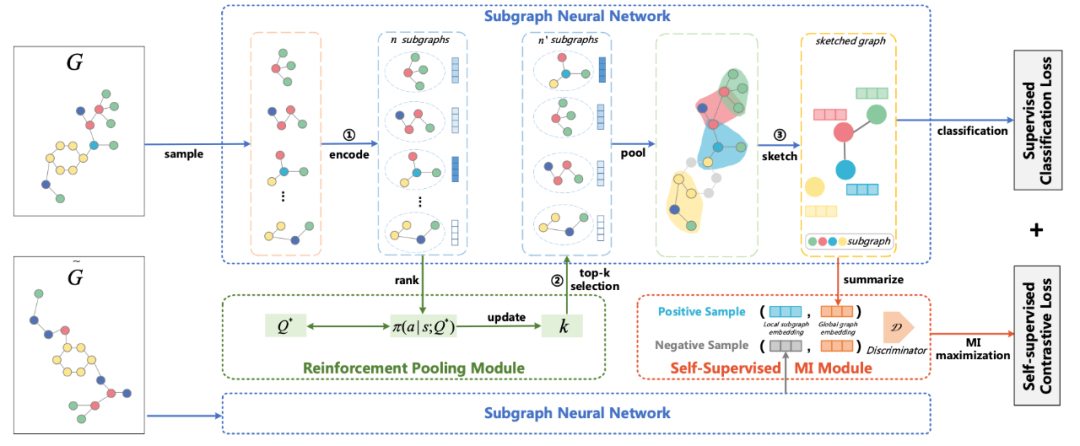
SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism [27]
4 总结与讨论
预训练的核心为迁移能力,即经过预训练的 GNN 参数能否快速、准确地迁移至新的下游任务上,而自监督学习一般会固定经过训练的节点/图表示向量。对于预训练方法 / 模型的迁移能力,现有工作基本以经验性地实验验证为主,而理论分析较少; 预训练时可以利用容易获取的粗粒度标签作为监督信号,而自监督学习一般不使用监督信号。但是如何平衡预训练过程中的无监督任务和有监督任务,以及它们如何对模型的迁移能力产生影响的,目前也较为缺少相关研究。
5 资源汇总
5.1 论文列表
awesome-self-supervised-gnn: https://github.com/ChandlerBang/awesome-self-supervised-gnn
5.2 预训练 GNN 数据集
蛋白质关系图(Hu et.al. ICLR 2020 [7]) [stanford.edu]http://snap.stanford.edu/gnnpretrain/data/bio_dataset.zip [GoogleDrive] https://drive.google.com/drive/folders/18vpBvSajIrme2xsbx8Oq8aTWIWMlSgJT?usp=sharing [百度网盘] https://pan.baidu.com/s/1Yv6dN7F1jgTSz9-nU1eN-A(解压码:j97n) 化学分子图(Hu et.al. ICLR 2020 [7]) [stanford.edu] http://snap.stanford.edu/gnn-pretrain/data/chem_dataset.zip PreDBLP(Lu et.al. AAAI 2020 [19]) [GoogleDrive] https://drive.google.com/drive/folders/18vpBvSajIrme2xsbx8Oq8aTWIWMlSgJT?usp=sharing [百度网盘] https://pan.baidu.com/s/1Yv6dN7F1jgTSz9-nU1eN-A(解压码:j97n) Open Academic Graph (OAG, Hu et.al. KDD 2020 [6]) [GoogleDrive]https://drive.google.com/open?id=1a85skqsMBwnJ151QpurLFSa9o2ymc_rq
Reference
[1]: Thomas N. Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. ICLR 2017.
[2]: William L. Hamilton and Rex Ying et.al. Inductive Representation Learning on Large Graphs. NIPS 2017.
[3]: Petar Veličković et.al. Graph Attention Networks. ICLR 2018.
[4]: Petar Veličković et.al. Deep Graph Infomax. ICLR 2019.
[5]: Keyulu Xu and Weihua Hu et.al. How Powerful are Graph Neural Networks? ICLR 2019.
[6]: Ziniu Hu et.al. GPT-GNN: Generative Pre-Training of Graph Neural Networks. KDD 2020.
[7]: Weihua Hu and Bowen Li et.al. Strategies for Pre-training Graph Neural Networks. ICLR 2020.
[8]: Yuning You and Tianlong Chen et.al. Graph Contrastive Learning with Augmentations. NeurIPS 2020.
[9]: Jiaxuan You et.al. Design Space for Graph Neural Networks. NeurIPS 2020.
[10]: Jacob Devlin et.al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
[11]: Ross Girshick et.al. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR 2014.
[12]: Kun Zhou and Hui Wang et.al. S3 -Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. CIKM 2020.
[13]: Kaiming He et.al. Momentum contrast for unsupervised visual representation learning. CVPR 2020.
[14]: Tomas Mikolov et.al. Distributed Representations of Words and Phrases and their Compositionality. NIPS 2013.
[15]: Tomas Mikolov et.al. Efficient Estimation of Word Representations in Vector Space. ICLR 2013.
[16]: Jiezhong Qiu et.al. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training. KDD 2020.
[17]: Bowen Hao et.al. Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation. WSDM 2021.
[18]: Xiangnan He et.al. Neural Collaborative Filtering. WWW 2017.
[19]: Yuanfu Lu et.al. Learning to Pre-train Graph Neural Networks. AAAI 2021.
[20]: Jian Tang et.al. LINE: Large-scale Information Network Embedding. WWW 2015.
[21]: Yu Rong and Yatao Bian et.al. Self-Supervised Graph Transformer on Large-Scale Molecular Data. NeurIPS 2020.
[22]: R Devon Hjelm et.al. Learning deep representations by mutual information estimation and maximization. ICLR 2019.
[23]: Ting Chen et.al. A Simple Framework for Contrastive Learning of Visual Representations. ICML 2020.
[24]: Kaveh Hassani and Amir Hosein Khasahmadi. Contrastive Multi-View Representation Learning on Graphs. ICML 2020.
[25]: Johannes Klicpera et.al. Diffusion Improves Graph Learning. NeurIPS 2019.
[26]: Yanqiao Zhu and Yichen Xu et.al. Graph Contrastive Learning with Adaptive Augmentation. WWW 2021.
[27]: Qingyun Sun et.al. SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism. WWW 2021.
编辑:于腾凯
校对:林亦霖