
BERT预训练模型系列总结(上)
导读:本文主要针对大规模预训练模型BERT及基于BERT的优化模型进行总结,让大家快速学习了解Bert模型的核心,及优化模型的核心改进点。
优化模型主要为RoBERTa、ALBERT、MacBERT。当然,基于预训练模型还有很多,复旦大学邱锡鹏教授发表过一篇NLP预训练模型综述,从多个角度对当前的预训练模型进行了分析,这里附上综述的论文链接:https://arxiv.org/pdf/2003.08271.pdf。
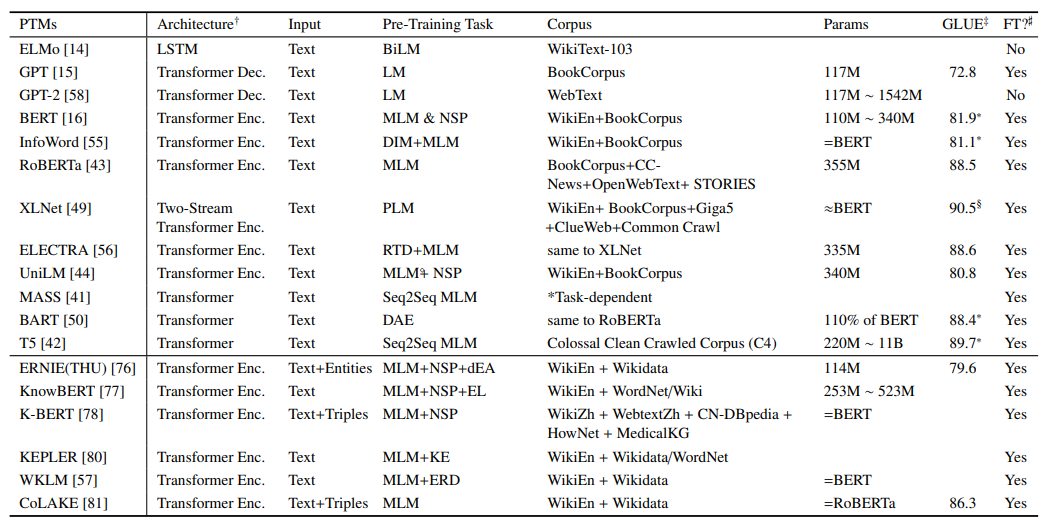

首先我们先来总结下BERT模型,BERT的全名是Bidirectional Encoder Representations from Transformers,是由Devlin等人在2018年提出的,其主要结构是Transformer的encoder层,其包括两个训练阶段,预训练与fine-tuning。
BERT论文链接:https://arxiv.org/pdf/1810.04805.pdf。下面我们从模型的输入输出、预训练任务及下游任务来进行介绍。
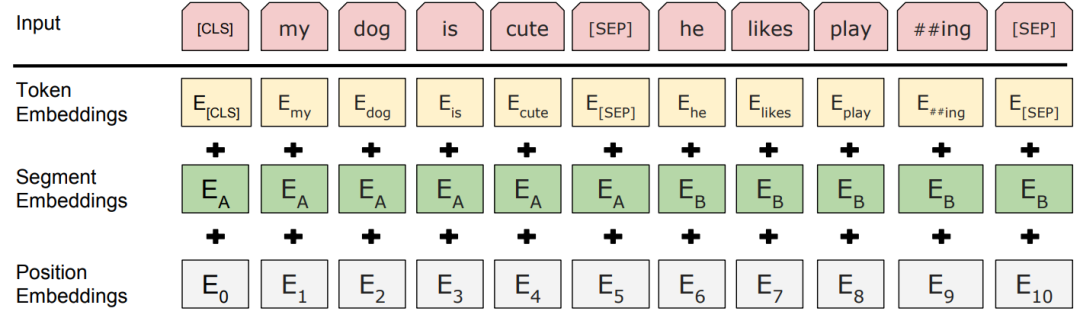
BERT模型的输入主要包含三部分,分别是
① token embedding词向量
② segment embedding段落向量
③ position embedding位置向量。
这里简单说下BERT输入与Transformer的区别:
Transformer的输入只包含两部分,token embedding词向量和position encoding位置向量,且position encoding用的是函数式(正余弦函数),BERT的position embedding位置向量是参数式(可学习的),且segment embedding段落向量用于区分两个句子(第一个句子为0,第二个句子为1)。
需要注意的就是,【CLS】和【SEP】,【CLS】为句首向量,【SEP】为句中和句尾向量。
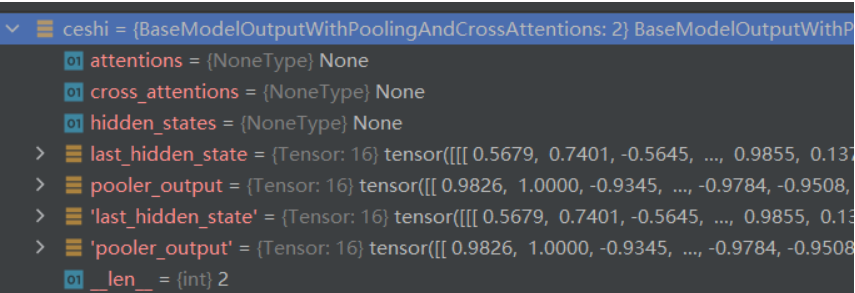
BERT模型的输出为每个token对应的向量,在代码中通常包含last_hidden_state和pooler_output。
last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态。
pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的,这个输出不是对输入的语义内容的一个很好的总结,对于整个输入序列的隐藏状态序列的平均化或池化通常更好。(【CLS】—> Linear —>tanh函数 )
通常用output[0]表示上面的last_hidden_state,output[1]表示的是pooler_output。
如果 return_dict = False,就会返回一个元组(tuple);
如果 return_dict = True,就会返回一个字典,包含下面几部分。
BERT模型的预训练任务主要包含两个, 一个是MLM(Masked Language Model),一个是NSP(Next Sentence Prediction),BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加。
Masked Language Model 可以理解为完形填空,随机mask每一个句子中15%的词,用其上下文来做预测。
而这样会导致预训练阶段与下游任务阶段之间的不一致性(下游任务中没有【MASK】),为了缓解这个问题,会按概率选择以下三种操作:
例如:my dog is hairy → my dog is [MASK]
80%的是采用[mask],my dog is hairy → my dog is [MASK]
10%的是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的保持不变,my dog is hairy -> my dog is hairy
Next Sentence Prediction可以理解为预测两段文本的蕴含关系(分类任务),选择一些句子对A与B,其中50%的数据B是A的下一条句子(正样本),剩余50%的数据B是语料库中随机选择的(负样本),学习其中的相关性。
前面提到序列的头部会填充一个[CLS]标识符,该符号对应的bert输出值通常用来直接表示句向量。
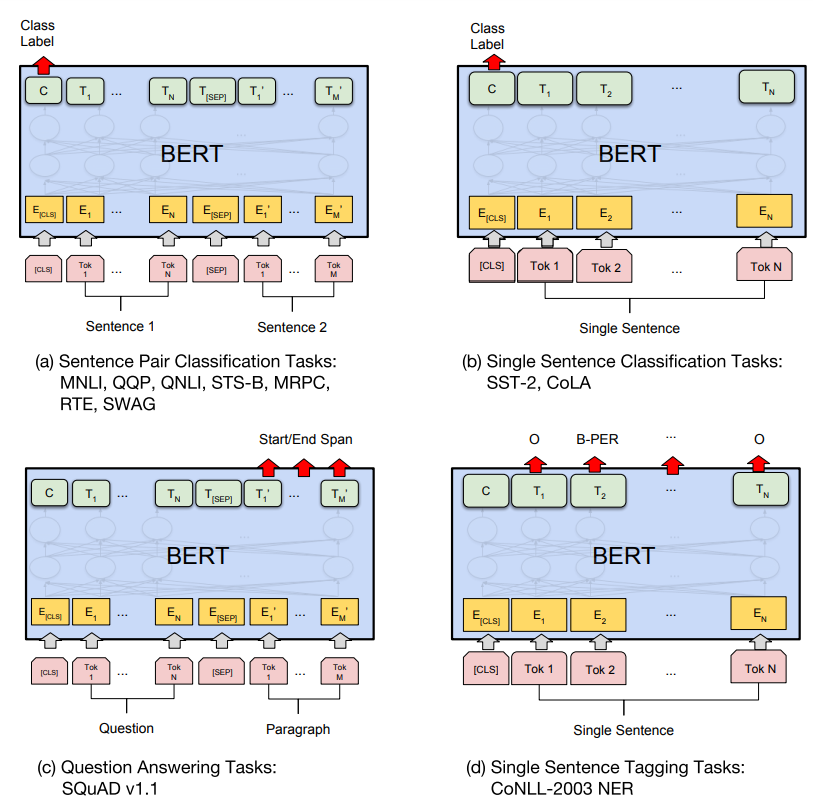
BERT模型在经过大规模数据的预训练后,可以将预训练模型应用在各种各样的下游任务中。使用方式主要有两种:一种是特征提取,一种是模型精调。
特征提取:仅使用BERT提取输入文本特征,生成对应上下文的语义表示,来进行下游任务的训练(BERT本身不参与训练);
模型精调:利用BERT作为下游任务模型基底,生成文本对应的上下文语义表示,并参与到下游任务的训练。
常见的下游任务有四种:单句文本分类、句子对文本分类、阅读理解和序列标注等。
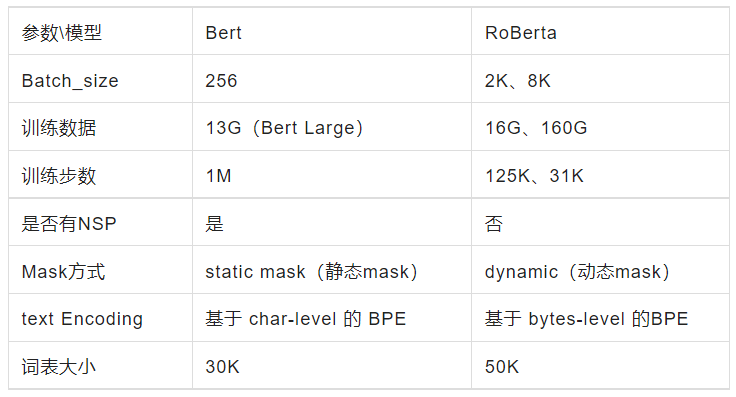
RoBERTa的全名是Robustly OptimizedBERT Pre-training Approach,对BERT模型进行了优化,在BERT的基础上引入了动态掩码技术,同时舍弃了 NSP任务,同时采用了更大规模预训练数据,并以更大的批次和BPE词表训练了更多的步数。ROBERTa模型论文链接:https://arxiv.org/pdf/1907.11692.pdf。
原始静态mask:
BERT中是准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这是原始静态mask,即单个静态mask,这是原始 BERT 的做法。
修改版静态mask:
在预处理的时候将数据集拷贝 10 次,每次拷贝采用不同的 mask(总共40 epochs,所以每一个mask对应的数据被训练4个epoch)。这等价于原始的数据集采用10种静态 mask 来训练 40个 epoch。
动态mask:
并没有在预处理的时候执行 mask,而是在每次向模型提供输入时动态生成 mask,所以是时刻变化的。
RoBERTa 模型在 Bert 模型基础上的调整:
训练时间更长,Batch_size 更大,(Bert 256,RoBERTa 8K)
训练数据更多(Bert 16G,RoBERTa 160G)
移除了 NPL(next predict loss)
动态调整 Masking 机制
Token Encoding:使用基于 bytes-level 的 BPE
简单总结如下:
NLP高级小班
七月在线开设的最新一期【NLP高级小班】现已迭代至第十期,考虑到市面上几乎所有课程都是以讲技术、讲理论为主,很少有真正带着学员一步步从头到尾实现企业级项目的高端课程,为了让大家更好的在职提升,本期继续由大厂技术专家手把手带你实战大厂项目。

且七月的讲师大多数为国内外知名互联网公司技术骨干或者顶尖院校的专业大牛,在业界有很大的影响力,学员将在这些顶级讲师的手把手指导下完成学习。
在新的一期里,为了夯实基础,改进了技术阶段的课程内容,并增加了每两周一次考试,力求让每位同学都深刻理解NLP的各大模型、理论和应用。
▋五大阶段
分别从NLP基础技能、深度学习在NLP中的应用、Seq2Seq文本生成、Transformer与预训练模型、模型优化等到新技术的使用,包括且不限于GPT、对抗训练、prompt小样本学习等。

▋实训项目
提供文本分类、机器翻译、问答系统、FAQ问答机器人、知识图谱、聊天机器人等项目实战、聊天机器人中的语义理解、文本推荐系统,以及一个开放式项目;
▋标准流程
环境配置与特征工程、模型构建与迭代优化、模型评估与优化上线;
▋就业辅导
学员在完成项目进入就业阶段后,BAT等大厂技术专家会一对一进行简历优化(比如将集训营项目整理到简历中)、面试辅导(比如面试常见考点/模型/算法),和就业老师一起进行就业推荐等等就业服务。
机会永远留给提前做好准备的人!如果你想从事推荐方向的工作,想在最短时间内成长为行业中高级人才,进入知名互联网公司,扫码(或联系七月在线任一老师)咨询课程详情!
戳↓↓“阅读原文”查看课程详情!