
为什么回归问题用MSE?
最近在看李沐的实用机器学习课程,讲到regression问题的loss的时候有弹幕问:“为什么要平方?”
如果是几年前学生问我这个问题,我会回答:“因为做回归的时候的我们的残差有正有负,取个平方求和以后可以很简单的衡量模型的好坏。同时因为平方后容易求导数,比取绝对值还要分情况讨论好用。”
极大似然估计MLE

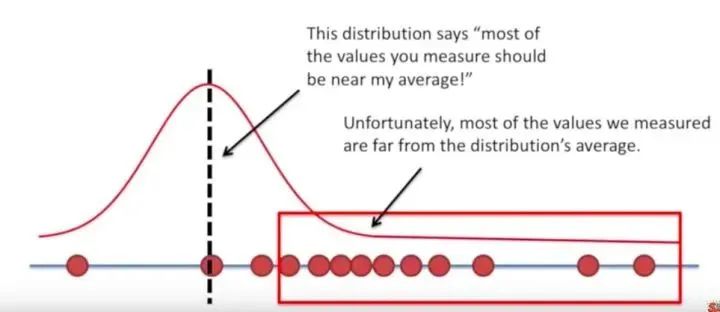
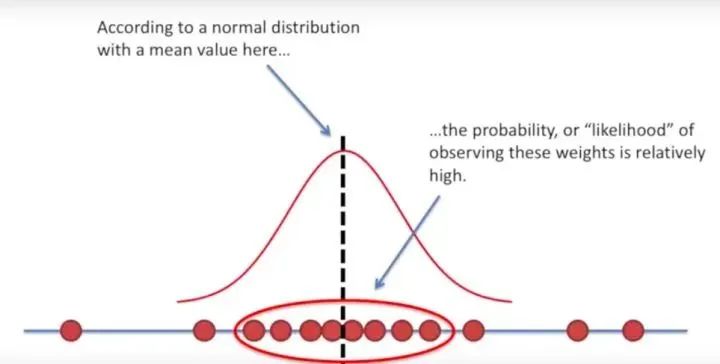
回归问题
总结

参考资料
REFERENCE
[1] CC思SS:回归模型中的代价函数应该用MSE还是MAE
https://zhuanlan.zhihu.com/p/45790146
[2] 在回归问题中,为何对MSE损失的最小化等效于最大似然估计?
https://www.zhihu.com/question/426901520
[3] https://link.zhihu.com/?target=https%3A//towardsdatascience.com/where-does-mean-squared-error-mse-come-from-2002bbbd7806
[4] https://link.zhihu.com/?target=https%3A//towardsdatascience.com/mse-is-cross-entropy-at-heart-maximum-likelihood-estimation-explained-181a29450a0b
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》
评论