
ICML2021 | 深入研究不平衡回归问题

来源:知乎—Yuzhe Yang、深度学习与图网络 https://zhuanlan.zhihu.com/p/369627086 本文约8500字,建议阅读15分钟 本文大体梳理一下数据不平衡这个问题在分类以及回归上的一部分研究现状。
我们提出了一个新的任务,称为深度不平衡回归(Deep Imbalanced Regression,简写为DIR)。DIR任务定义为从具有连续目标的不平衡数据中学习,并能泛化到整个目标范围; 我们同时提出了针对不平衡回归的新的方法,标签分布平滑(label distribution smoothing, LDS)和特征分布平滑(feature distribution smoothing, FDS),以解决具有连续目标的不平衡数据的学习问题; 最后我们建立了五个新的DIR数据集,涵盖了computer vision,NLP,和healthcare上的不平衡回归任务,来方便未来在不平衡数据上的研究。
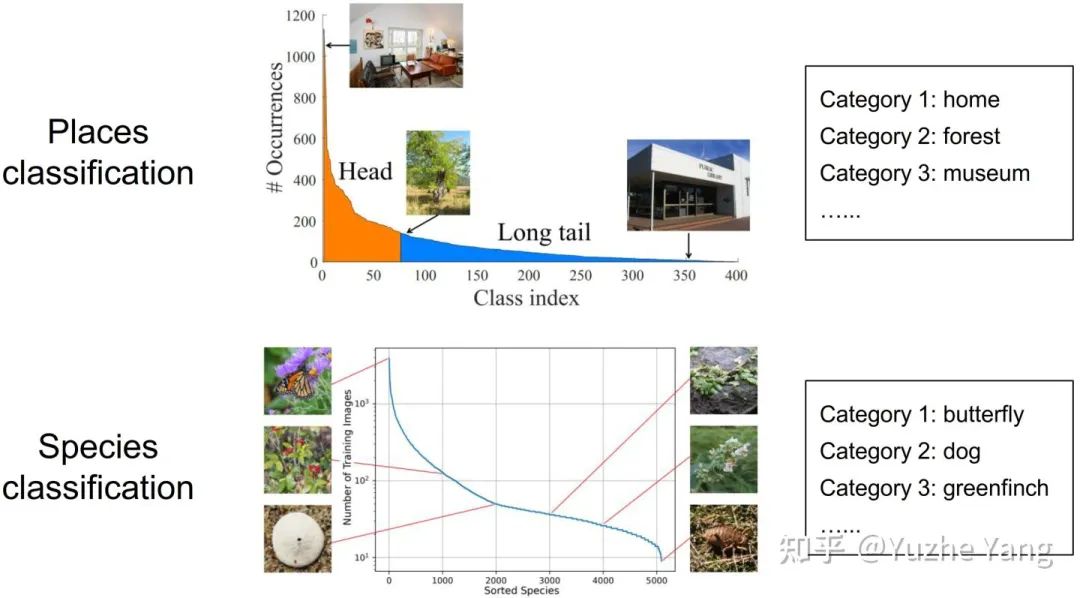
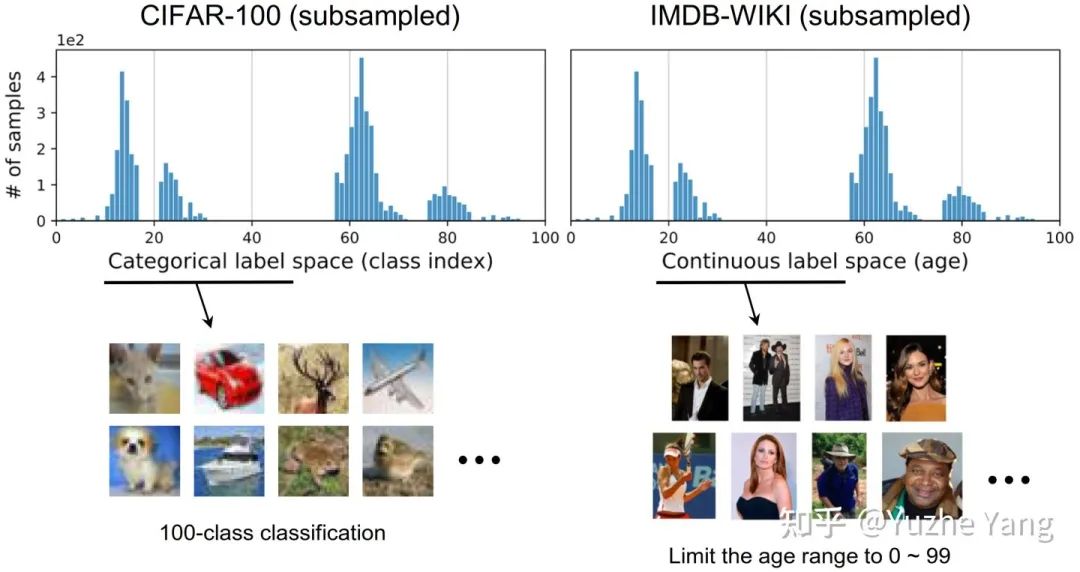
现有的不平衡学习方案主要考虑的数据类型是具有categorical index的目标值,也即目标值是不同的类别,如地点分类、物种分类。其目标值属于不同类别,且不同类之间有一个硬性的边界,不同类别之间没有重叠。

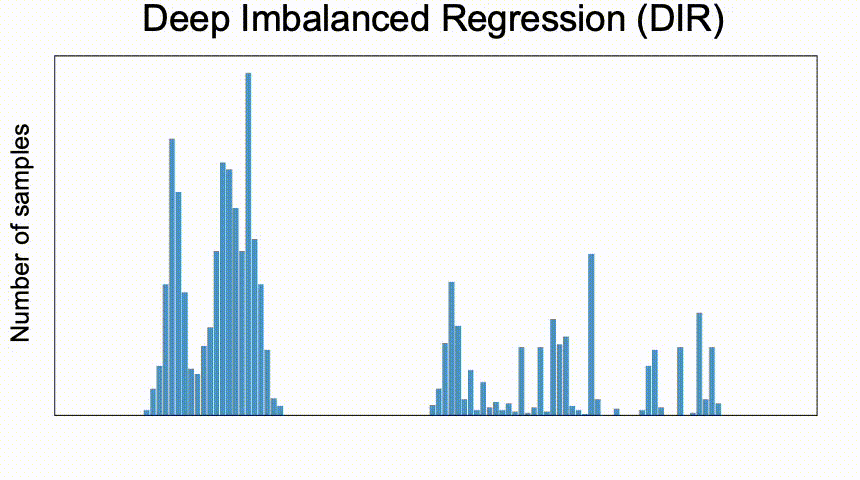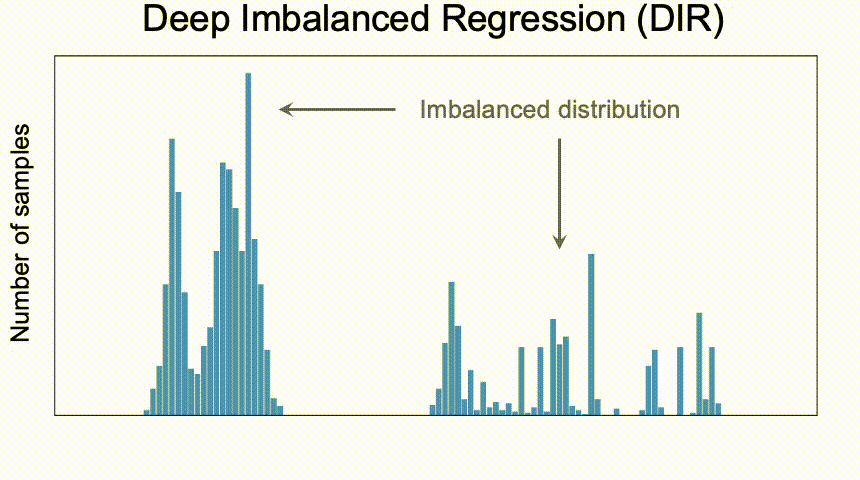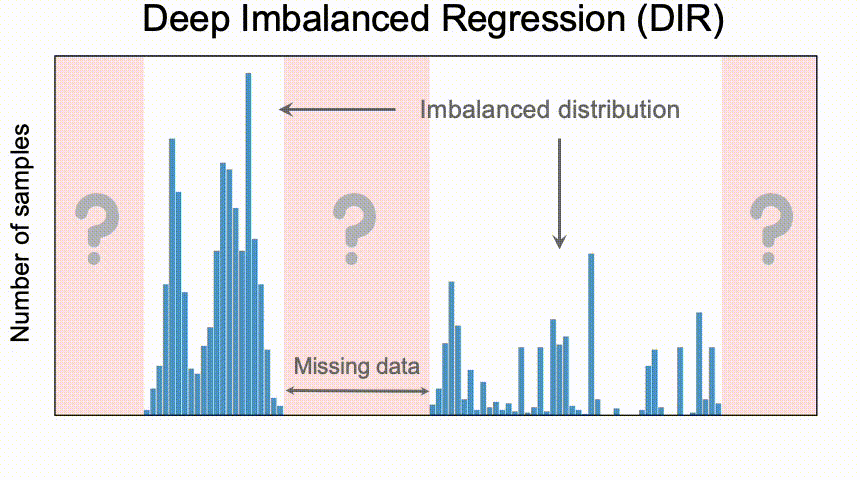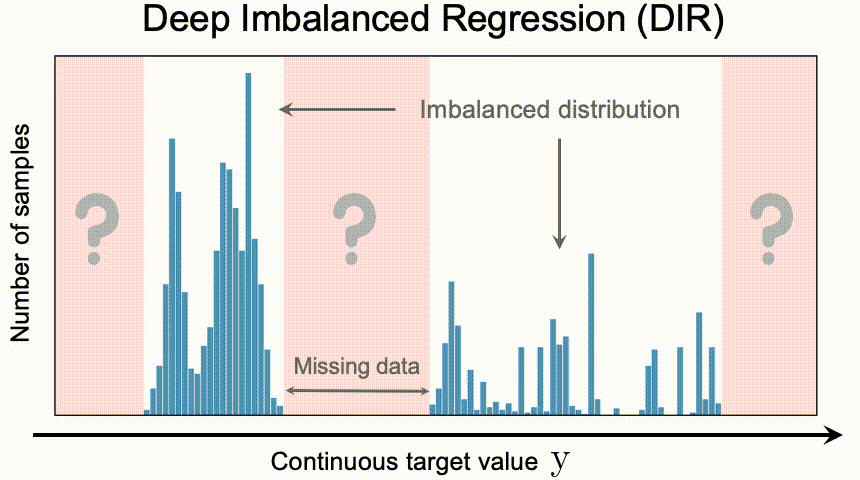
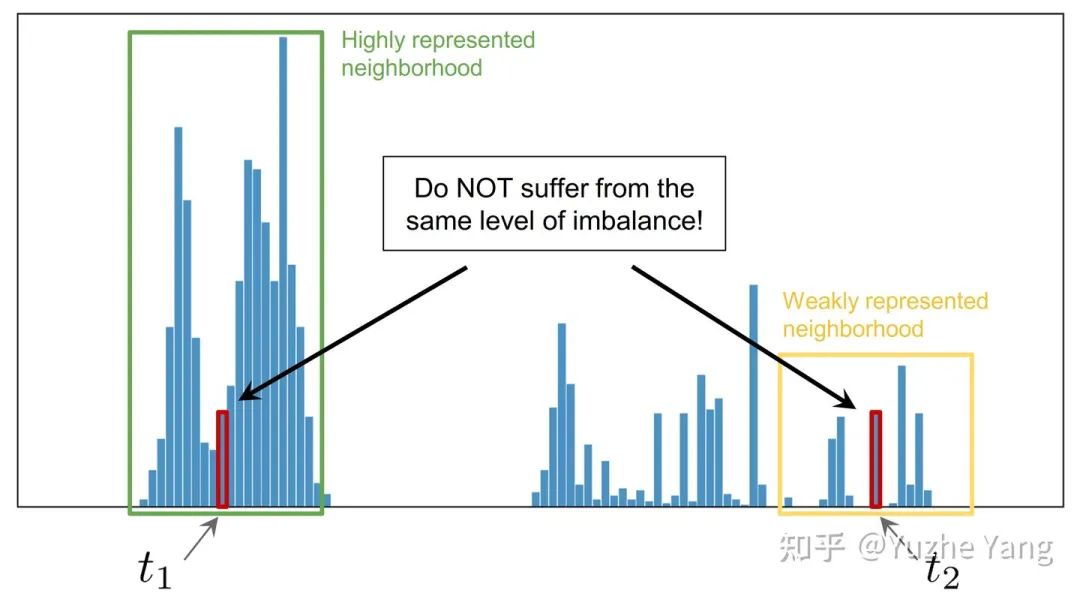
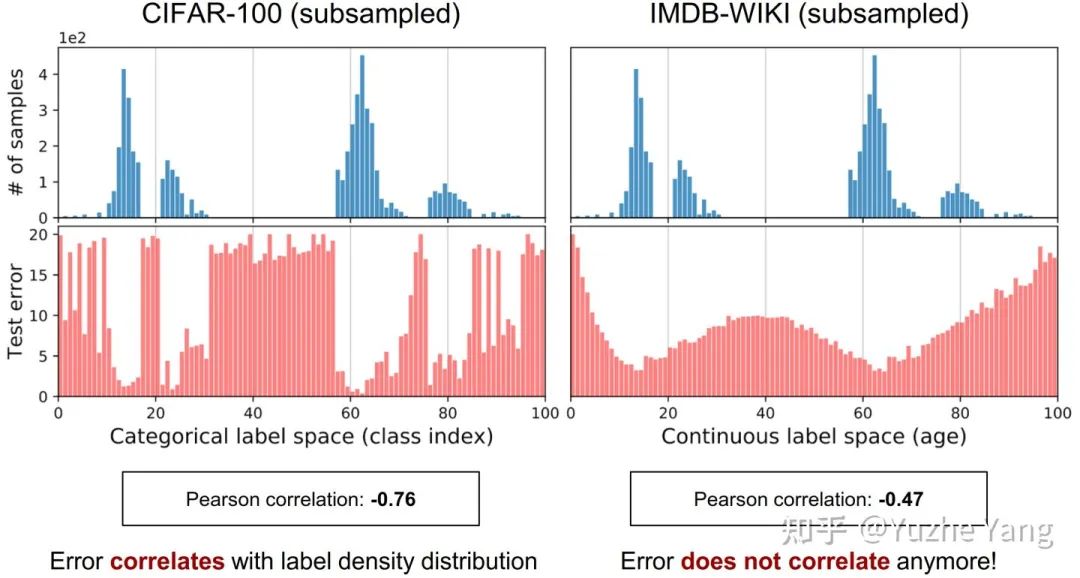
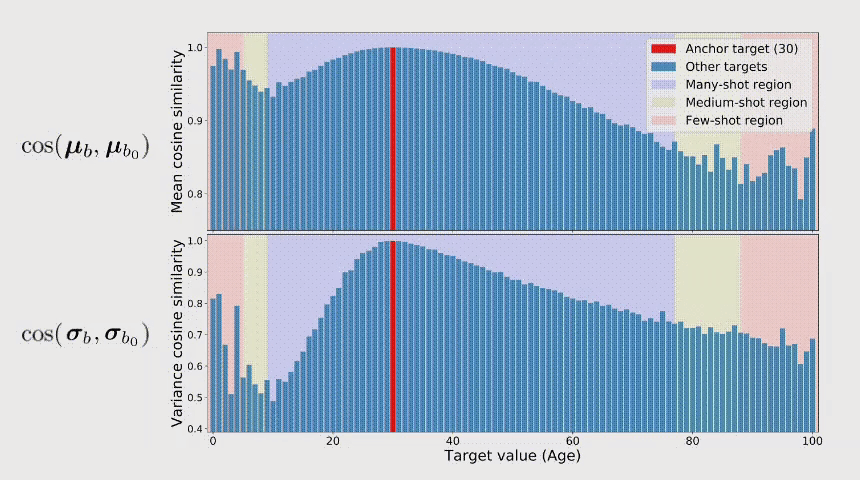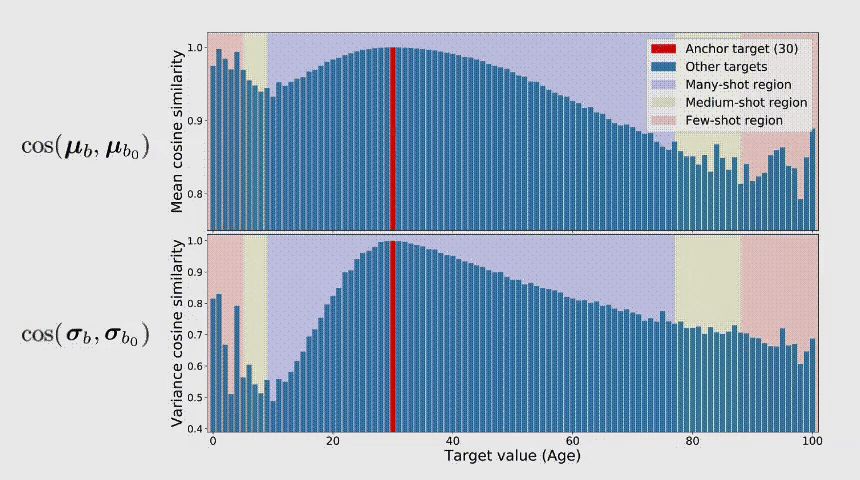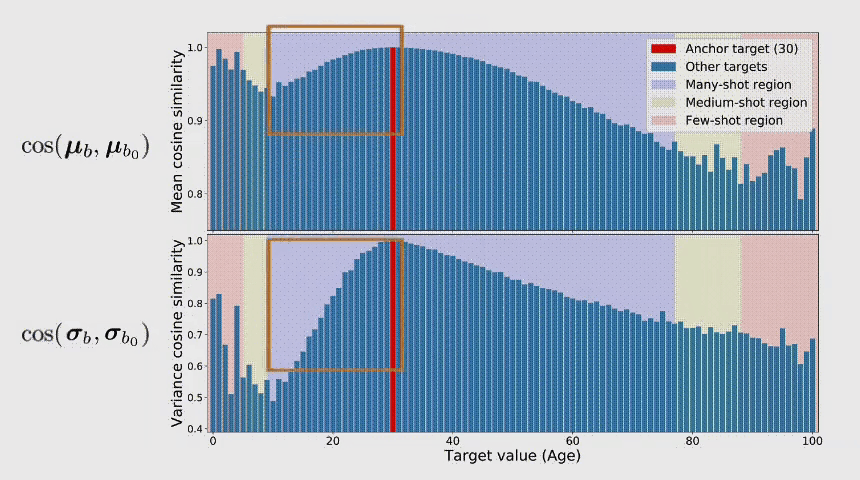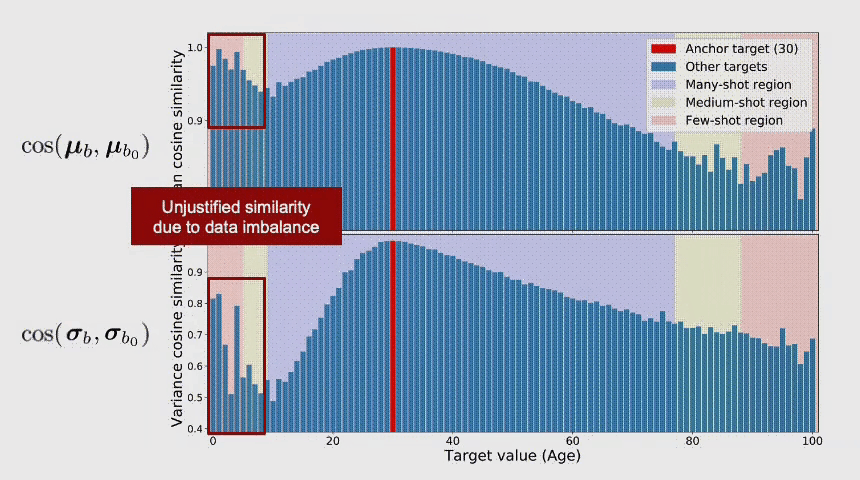
连续标签在不同目标值之间的距离是具有意义的,此距离会进一步指导我们该如何理解这个连续区间上的数据不平衡的程度。图中t1和t2在训练数据中具有同样的数量,而因t1位于一个具有高密度数据的邻域中,t2位于一个低密度数据的邻域中,那么t1和t2并不具有相同程度的数据不平衡。
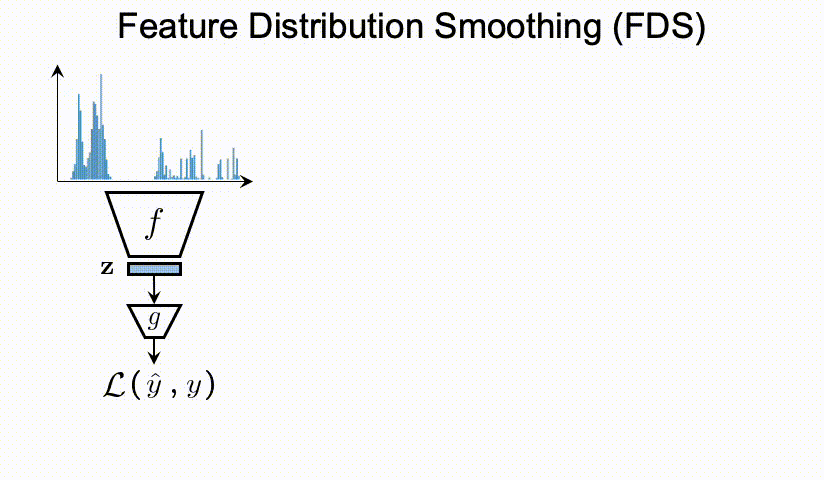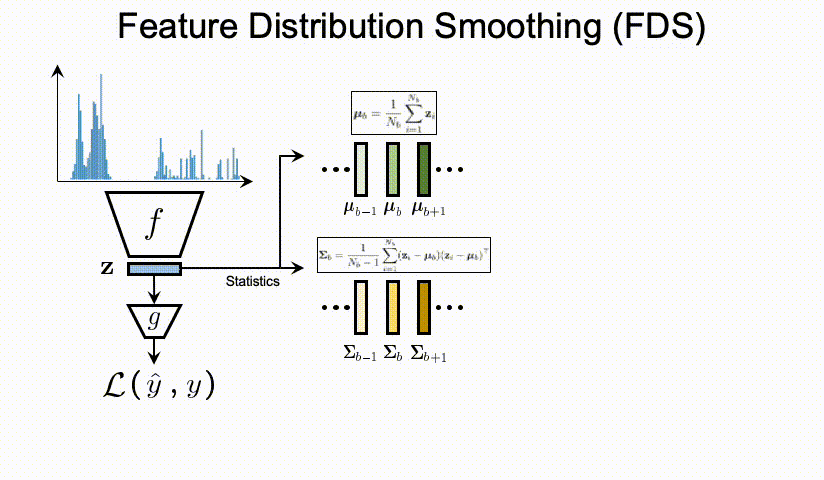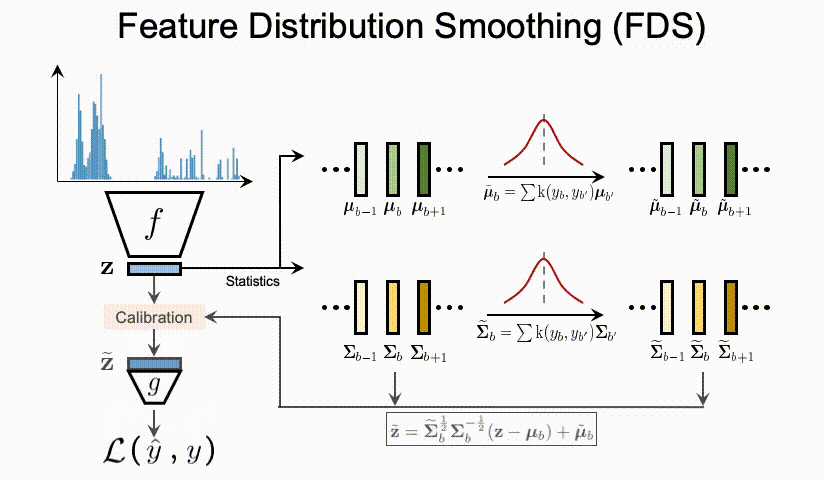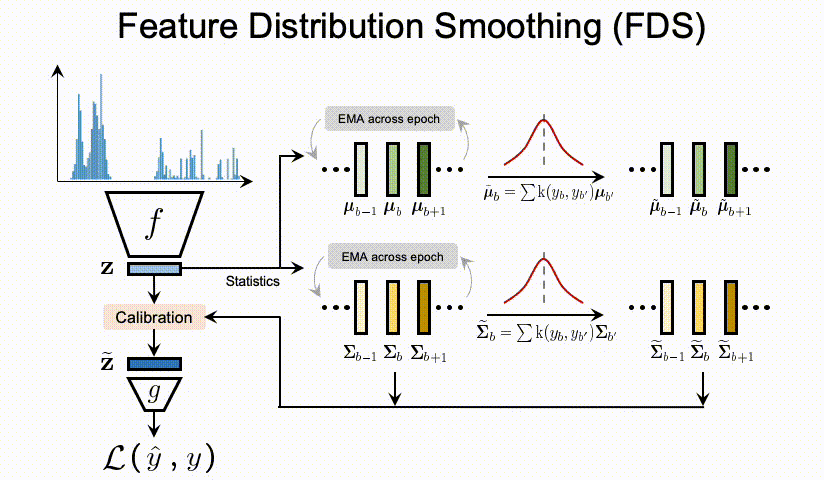
总结上述的问题,我们可以看到DIR相比与传统的不平衡分类具有全新的难点与挑战。那么,我们应该如何进行深度不平衡回归呢?在接下来的两节,我们分别提出了两个简单且有效的方法,标签分布平滑(label distribution smoothing,LDS)和特征分布平滑(feature distribution smoothing,FDS),分别通过利用在标签空间和特征空间中临近目标之间的相似性,来提升模型在DIR任务上的表现。
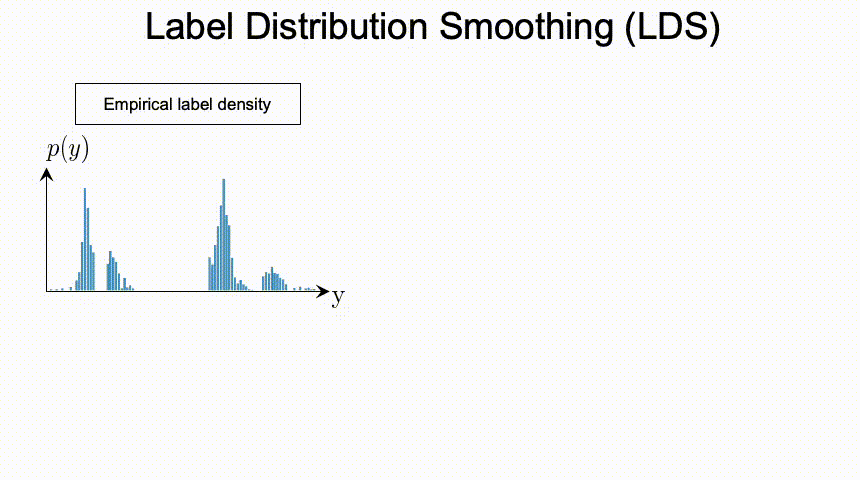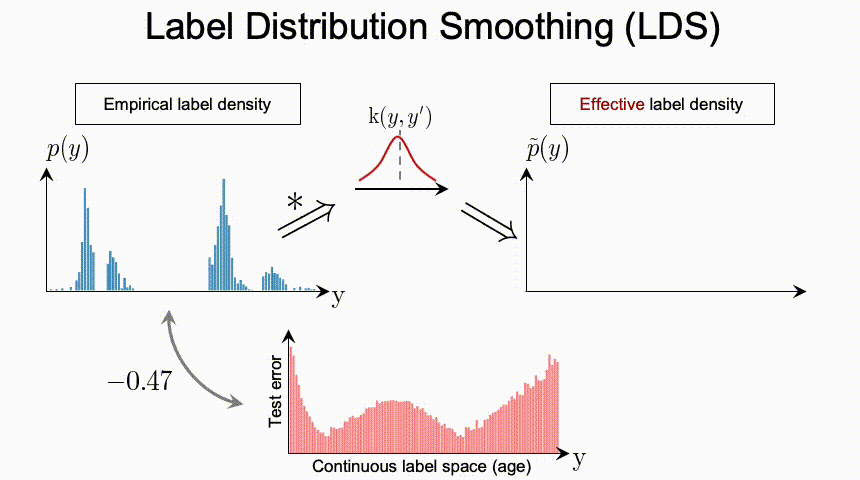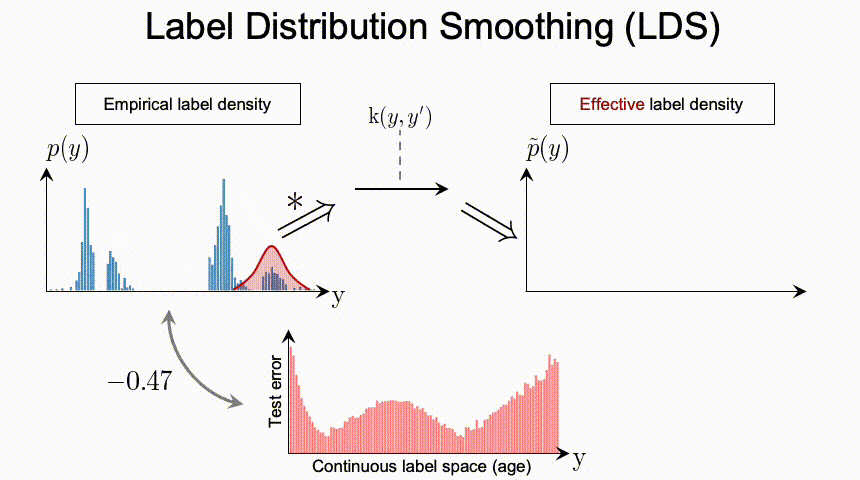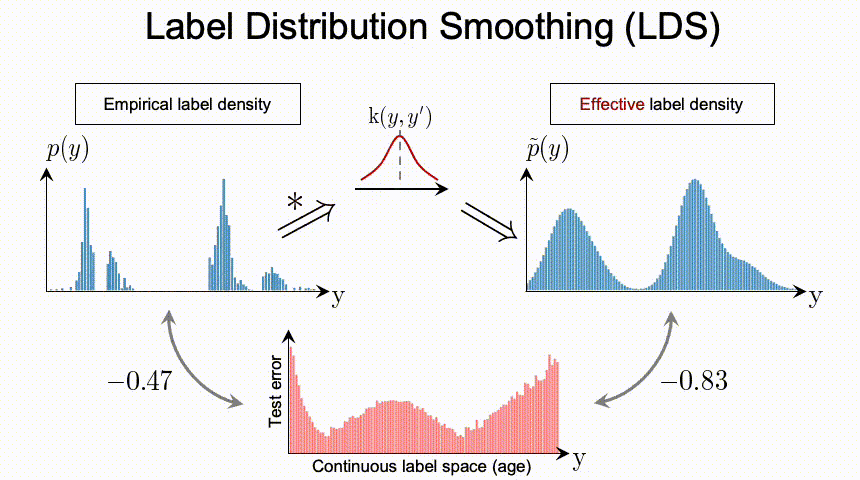
那么有了用LDS估计出的有效标签密度,之前用来解决类别不平衡问题的方法,便可以直接应用于DIR。比如说,一种直接的可以adapted 的方法是利用重加权方法,具体来说就是,我们通过将损失函数乘以每个目标值的LDS估计标签密度的倒数来对其进行加权。之后在实验部分我们也会展示,利用LDS可以一致提升很多方法。
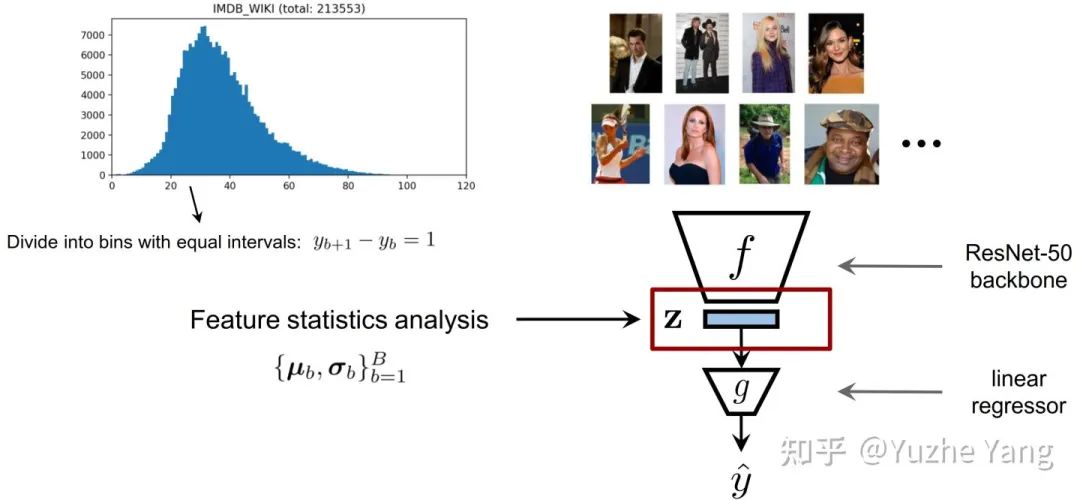
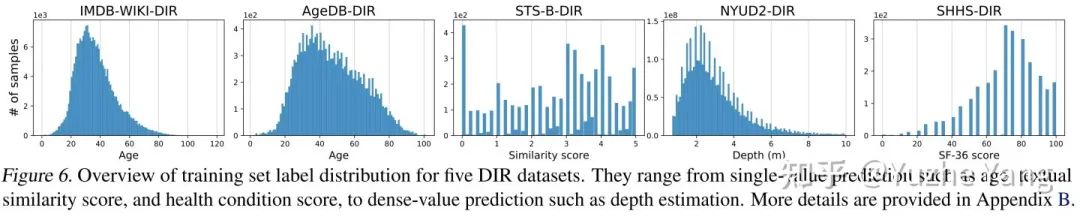
IMDB-WIKI-DIR(vision, age):从包含人面部的图像来推断估计相应的年龄。基于IMDB-WIKI[9]数据集,我们手动构建了验证集和测试集,使其保持了分布的平衡。 AgeDB-DIR(vision, age):同样是根据单个输入图像进行年龄估算,基于AgeDB[11]数据集。注意到与IMDB-WIKI-DIR相比,即使两个数据集是完全相同的task,他们的标签分布的不平衡也不相同。 NYUD2-DIR(vision, depth):除了single value的prediction, 我们还基于NYU2数据集[12]构建了进行depth estimation的DIR任务,是一个dense value prediction的任务。我们构建了NYUD2-DIR数据集来进行不平衡回归的评估。 STS-B-DIR(NLP, text similarity score):我们还在NLP领域中构建了一个叫STS-B-DIR的DIR benchmark,基于STS-B数据集[13]。他的任务是推断两个输入句子之间的语义文本的相似度得分。这个相似度分数是连续的,范围是0到5,并且分布不平衡。 SHHS-DIR(Healthcare, health condition score):最后,我们在healthcare领域也构建了一个DIR的benchmark,叫做 SHHS-DIR,基于SHHS数据集[14]。这项任务是推断一个人的总体健康评分,该评分在0到100之间连续分布,评分越高则健康状况越好。网络的输入是每个患者在一整晚睡眠过程中的高维PSG信号,包括ECG心电信号,EEG脑电信号,以及他的呼吸信号。很明显可以看到,总体健康分数的分布也是极度不平衡的,并存在一定的target value是没有数据的。
在评估过程中,我们在平衡的测试集上评估每种方法的性能。我们进一步将目标空间划分为几个不相交的子集:称为many-shot,medium-shot,few-shot,还有zero-shot region,来反映训练数据中样本数量的不同。比如,many-shot代表对于这个固定的区间,有超过100个training data sample。对于baseline方法,由于文献中只有很少的不平衡回归的方法,除了之前的使用合成样本进行不平衡回归的工作[15][16]外,我们也提出了一系列不平衡回归的baseline,包含了不同种类的学习方法(例如Focal loss[17]的regression版本Focal-R),具体详见我们的文章。
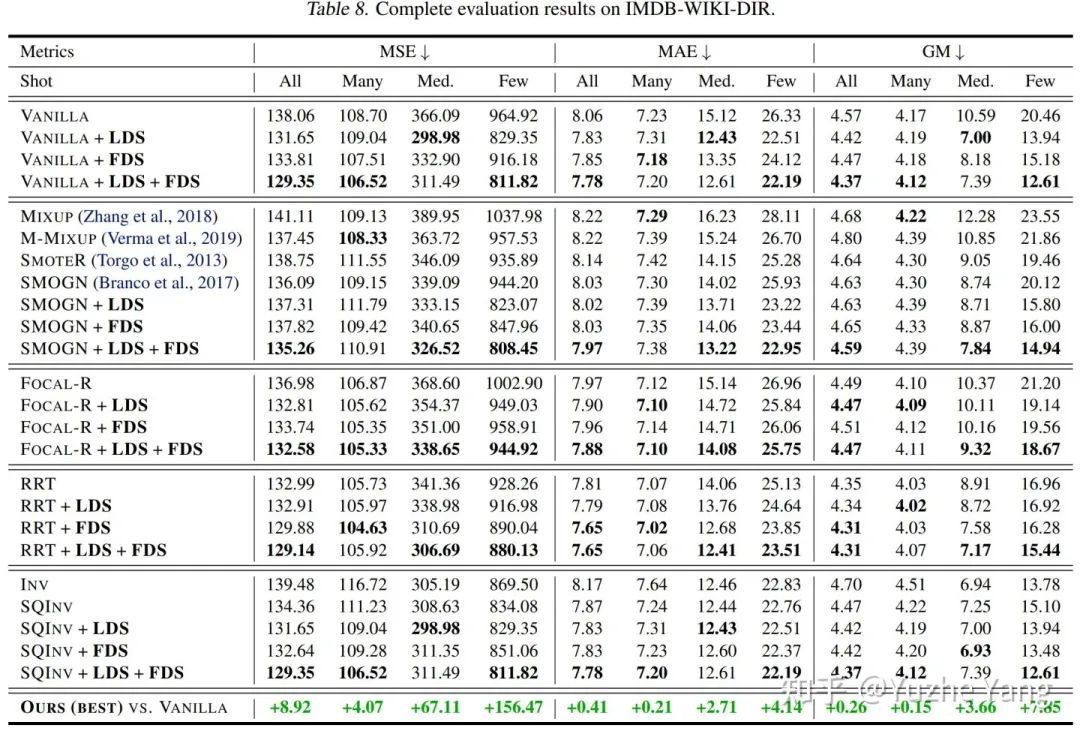
实验:由于实验较多,这里仅展示在IMDB-WIKI-DIR上的部分结果,所有的结果请详见论文。如下图所示,我们首先根据使用的基本策略的不同,将不同的方法分为4个部分,在每个部分里,我们进一步将LDS,FDS以及LDS和FDS的组合应用于基线方法。最后,我们报告了LDS + FDS相对于Vanilla模型的performance提升。如表所示,无论使用哪一类训练方法,LDS和FDS均具有非常出色的表现,特别是在few-shot region上能达到相对误差近40%的提升。
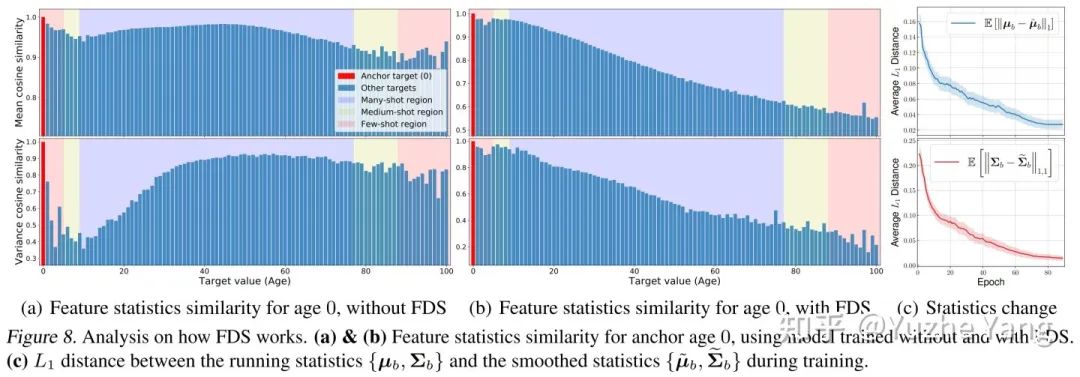
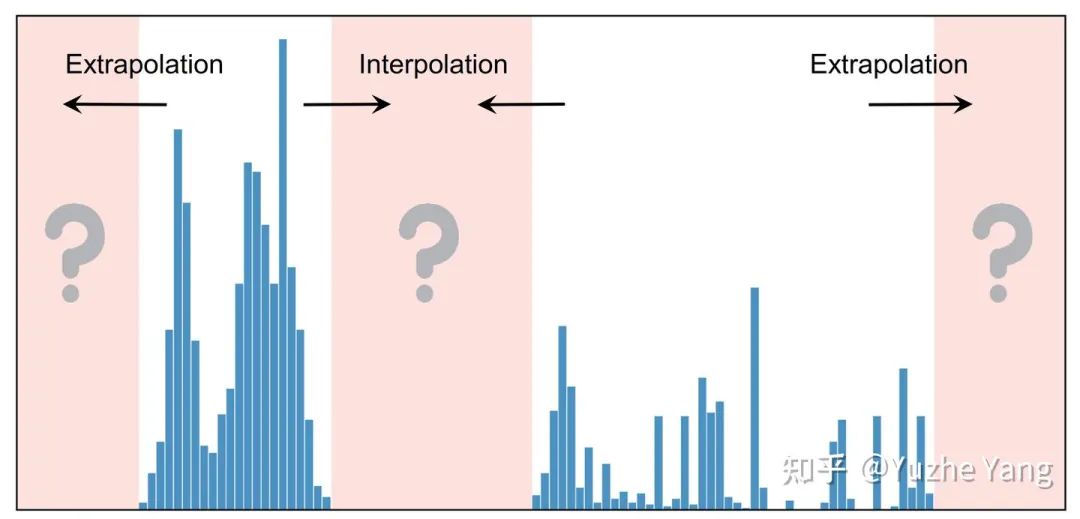
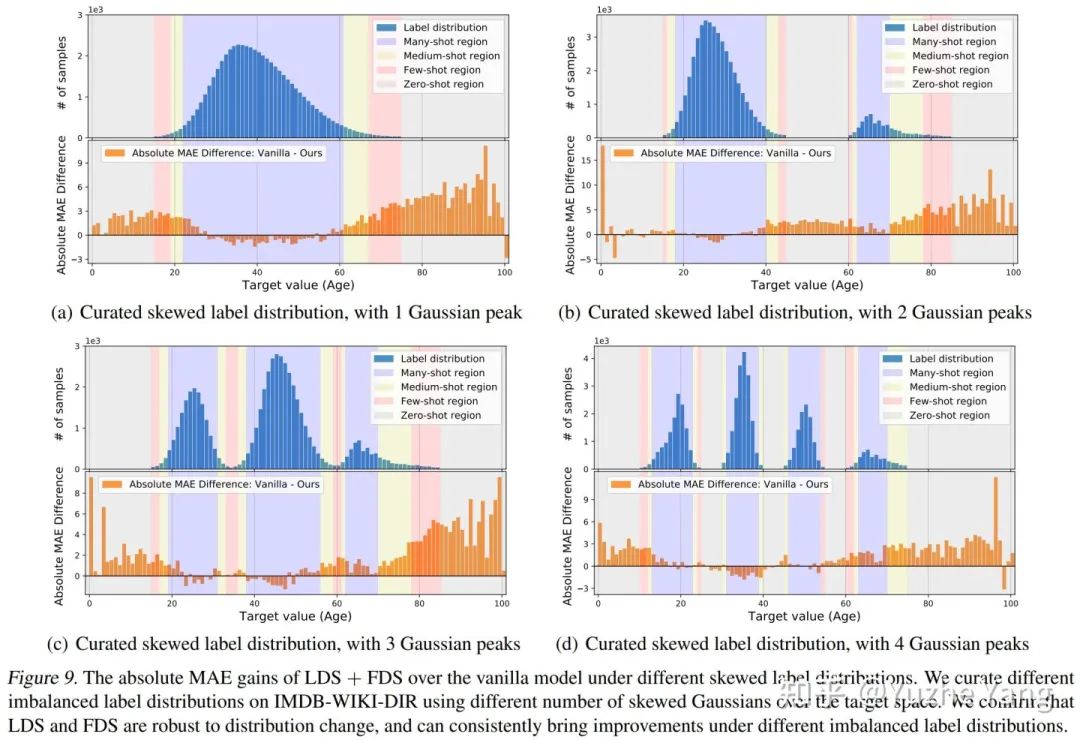
实验分析之 Extrapolation & Interpolation:最后,在实际的DIR任务中,某些目标值可能根本没有数据(例如之前看到的SHHS-DIR和STS-B-DIR上的标签分布)。这激发了对 target extrapolation 和 interpolation 的需求。如下图所示,我们从IMDB-WIKI-DIR的训练集中建立了不同的子集,涵盖了不同peak的标签分布,并且这些训练子集在某些区域中是没有训练数据的,但是我们对训练的模型会在原始的测试集进行评估,来分析zero-shot的generalization。下图我们可视化了我们的方法相对于原始模型,在所有target value上的绝对的MAE的提升(子图上半部分蓝色是训练的标签分布,下半部分橙色是相对误差的增益)。如前所述,我们的方法可以对所有区间得到显着的性能提升,特别是对于zero-shot范围,能够更好的进行Extrapolation & Interpolation。
项目主页
http://dir.csail.mit.edu/
论文
https://arxiv.org/abs/2102.09554
代码
https://github.com/YyzHarry/imbalanced-regression
参考
1. Chawla, N. V., et al. SMOTE: Synthetic minority over-sampling technique. JAIR, 2002.
2. Deep Imbalanced Learning for Face Recognition and Attribute Prediction. TPAMI, 2019.
3. Learning imbalanced datasets with label-distribution-aware margin loss. NeurIPS, 2019.
4. Liu, Z., et al. Large-scale long-tailed recognition in an open world. CVPR 2019.
5. Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting. NeurIPS, 2019.
6. Decoupling representation and classifier for long-tailed recognition. ICLR, 2020.
7. Learning from imbalanced data: open challenges and future directions. 2016.
8. Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009.
9. abRothe, R., et al. Deep expectation of real and apparent age from a single image without facial landmarks. IJCV, 2018.
10. Sun, B., Feng, J., and Saenko, K. Return of frustratingly easy domain adaptation. AAAI, 2016.
11. Agedb: The first manually collected, in-the-wild age database. CVPR Workshop, 2017.
12. Indoor segmentation and support inference from rgbd images. ECCV, 2012.
13. Semeval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. International Workshop on Semantic Evaluation, 2017.
14. The sleep heart health study: design, rationale, and methods. Sleep, 20(12):1077–1085, 1997.
15. Branco, P., Torgo, L., and Ribeiro, R. P. Smogn: a preprocessing approach for imbalanced regression. 2017.
16. Torgo, L., Ribeiro, R. P., Pfahringer, B., and Branco, P. Smote for regression. In Portuguese conference on artificial intelligence, 2013.
17. Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. ICCV, 2017.
编辑:王菁
校对:龚力