
详解用 statsmodels 进行回归分析

很多人在做线性回归时都会使用scikit-learn中的linear_model这个模块,用linear_model的好处是速度快、结果简单易懂,但它的使用是有条件的,就是使用者在明确该模型是线性模型的情况下才能用,否则生成的结果很可能是错误的。如果不知道该模型是否是线性模型的情况下,我们该怎么办呢?今天笔者就介绍一下statsmodels,statsmodels是python中专门用于统计学分析的包,它能够帮我们在模型未知的情况下来检验模型的线性显著性,笔者就用一个简单的例子(一元回归模型)来详细介绍一下statsmodels在线性回归的应用。
首先还是来看一下数据集,本次使用的数据集是统计学中很常用的一个例子,就是火灾损失与住户到最近消防站距离之间的相关关系数据,代码如下。
distance = [0.7, 1.1, 1.8, 2.1, 2.3, 2.6, 3, 3.1, 3.4, 3.8, 4.3, 4.6, 4.8, 5.5, 6.1]
loss = [14.1, 17.3, 17.8, 24, 23.1, 19.6, 22.3, 27.5, 26.2, 26.1, 31.3, 31.3, 36.4, 36, 43.2]
这里有两个list,distance就是指住户到最近消防站的距离,其单位是千米,而loss是用户遭受的火灾损失,单位是千元。这两个list每个都包含15个数据,其数据是一一对应的。
接下来笔者就用代码来展示一下如何用statsmodels进行线性回归分析,对每一个步骤和每一个结果,笔者也都会详细解释,目的就是让大家了解statsmodels的用法。
在statsmodels中进行回归分析有两种方法,分别是statsmodels.api和statsmodels.formula.api,前者和我们平常用的各种函数没啥区别,输入参数即可,但后者却要求我们自己指定公式,其中formula的意思就是公式,两者的具体用法还是直接看代码吧。
首先还是导入各种库,并把数据做一个简单处理,这里我们把distance和loss放在一个dataframe中,这是为了方便后面使用。
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
distance = [0.7, 1.1, 1.8, 2.1, 2.3, 2.6, 3, 3.1, 3.4, 3.8, 4.3, 4.6, 4.8, 5.5, 6.1]
loss = [14.1, 17.3, 17.8, 24, 23.1, 19.6, 22.3, 27.5, 26.2, 26.1, 31.3, 31.3, 36.4, 36, 43.2]
data = pd.DataFrame({'distance':distance, 'loss':loss})
接下来我们先用statsmodels.api来进行分析,代码如下。
y1 = loss #更换变量名
X1 = distance #更换变量名
X1 = sm.add_constant(X1) #增加一个常数1,对应回归线在y轴上的截距
regression1 = sm.OLS(y1, X1) #用最小二乘法建模
model1 = regression1.fit() #数据拟合
仅仅5行代码我们就完成了这个回归分析,在这里我们对每一行代码都解释一下。前两行代码我们用y1和X1来代替loss和distance,这纯粹是为了符合日常使用习惯,因为(一元)线性回归模型的公式是y=β0+β1x+ε,所以这两行没有什么实质性影响,根据用户的个人习惯而定吧。第三行代码X1 = sm.add_constant(X1)是给X1加上一列常数项1,为什么要加1呢,这是因为该模型是一条直线,其在y轴上是有截距的,这个常数1最终会反映出这个截距。加上常数1后X1就变成了一个15行2列的矩阵,如图1所示。而regression1 = sm.OLS(y1, X1)就是用最小二乘法来进行建模,最小二乘法(ordinary least squares,即OLS)是回归分析中最常用的方法。model1 = regression1.fit()就是对数据进行拟合,生成结果。
图1. X1增加常数项后的结果
接下来我们再来看一下statsmodels.formula.api的用法,其代码如下。
regression2 = smf.ols(formula='loss ~ distance', data=data) #这里面要输入公式和数据
model2 = regression2.fit()
statsmodels.formula.api要求用户输入公式,公式的形式为“parameter1 ~ parameter2”,第一个参数parameter1是被解释变量,相对于前面例子中的y1,第二个参数parameter2则是解释变量,相对于前面的X1。而smf.ols还要我们输入数据data,这个数据必须是pandas.DataFrame格式的,这也是我们在最开始对数据进行处理的原因。
statsmodels.api和statsmodels.formula.api这两种用法的结果基本上是一样的,只是格式不太一样。如图2所示,model1的params是numpy.array格式的,而model2的params是pandas.Series格式的,虽然二者的格式不同,但包含的数值是一样的。其他的参数和用法二者也都类似。

图2. 两种建模方法结果对比
最后我们再对model1.summary()做一个详细解释,因为model1.summary()和model2.summary()内容一样,所以只介绍model1.summary()。model1的方法/属性那么多,为何只介绍summary?因为summary就像它的英文含义一样,是对整个模型结果的概括,把这个summary弄明白了,整个线性回归模型就很清楚了,这也是学习statsmodels的一个重点。首先来看一下model1.summary()的内容,如图3所示。
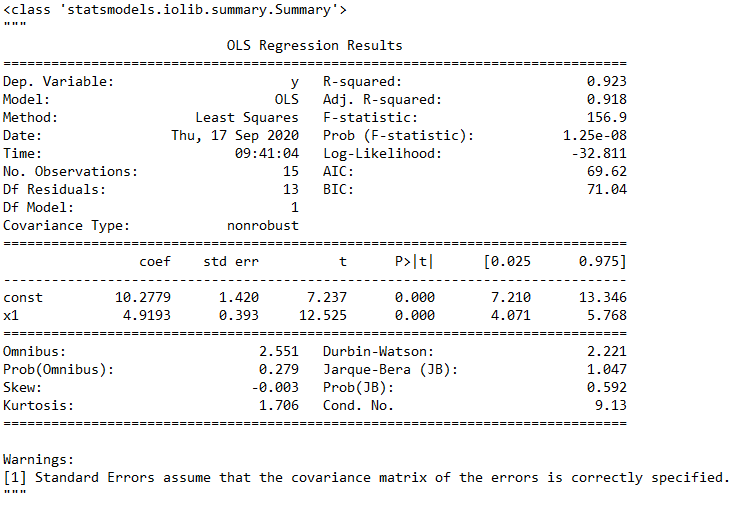
图3. summary的主要内容
当看到这个结果时,估计很多读者会一脸懵逼,这么多参数还都是英文的,到底该用哪些?确实这里面参数太多了,我们日常使用根本不需要这么多东西,我们只需要抓住几个关键的参数,能对我们的模型进行有效的解释,这就可以了。下面笔者就对这些参数进行一个详细的解释,并说一下那些是我们要重点关注的。
Dep.Variable: 就是因变量,dependent variable,也就是咱们输入的y1,不过这里statsmodels用y来表示模型的结果。
Model:就是最小二乘模型,这里就是OLS。
Method:系统给出的结果是Least Squares,和上面的Model差不多一个意思。
Date:模型生成的日期。
Time:模型生成的具体时间。
No. Observations:样本量,就是输入的数据量,本例中是15个数据,就是前面distance与loss中包含的数据个数。
Df Residuals:残差自由度,即degree of freedom of residuals,其值= No.Observations - Df Model - 1,本例中结果为15-1-1=13。
Df Model:模型自由度,degree of freedom of model,其值=X的维度,本例中X是一个一维数据,所以值为1。
Covariance Type:协方差阵的稳健性,在本例中是nonrobust,这个参数的原理过于复杂,想详细了解的朋友可以自行查询相关资料。不过在大多数回归模型中,我们完全可以不考虑这个参数。
R-squared:决定系数,其值=SSR/SST,SSR是Sum of Squares for Regression,SST是Sum of Squares for Total,这个值范围在[0, 1],其值越接近1,说明回归效果越好,本例中该值为0.923,说明回归效果非常好。
Adj. R-squared:利用奥卡姆剃刀原理,对R-squared进行修正,内容有些复杂,具体方法可自行查询。
F-statistic:这就是我们经常用到的F检验,这个值越大越能推翻原假设,本例中其值为156.9,这个值过大,说明我们的模型是线性模型,原假设是“我们的模型不是线性模型”(这部分不会的人要去复习一下数理统计了)。
Prob (F-statistic):这就是上面F-statistic的概率,这个值越小越能拒绝原假设,本例中为1.25e-08,该值非常小了,足以证明我们的模型是线性显著的。
Log likelihood:对数似然。对数函数和似然函数具有同一个最大值点。取对数是为了方便计算极大似然估计,通常先取对数再求导,找到极值点。这个参数很少使用,可以不考虑。
AIC:其用来衡量拟合的好坏程度,一般选择AIC较小的模型,其原理比较复杂,可以咨询查找资料。该参数一般不使用。
BIC:贝叶斯信息准则,其比AIC在大数据量时,对模型参数惩罚得更多,所以BIC更倾向于选择参数少的简单模型。该参数一般不使用。
coef:指自变量和常数项的系数,本例中自变量系数是4.9193,常数项是10.2779。
std err:系数估计的标准误差。
t:就是我们常用的t统计量,这个值越大越能拒绝原假设。
P>|t|:统计检验中的P值,这个值越小越能拒绝原假设。
[0.025, 0.975]:这个是置信度为95%的置信区间的下限和上限。
Omnibus:基于峰度和偏度进行数据正态性的检验,其常和Jarque-Bera检验一起使用,关于这两个检验,笔者之前给咱们公众号写过一篇名为《用Python讲解偏度和峰度》的文章,想要深入了解的读者可以去看一下。
Prob(Omnibus):上述检验的概率。
Durbin-Watson:检验残差中是否存在自相关,其主要通过确定两个相邻误差项的相关性是否为零来检验回归残差是否存在自相关。
Skewness:偏度,参考文章《用Python讲解偏度和峰度》。
Kurtosis:峰度,参考文章《用Python讲解偏度和峰度》。
Jarque-Bera(JB):同样是基于峰度和偏度进行数据正态性的检验,可参考文章《用Python讲解偏度和峰度》。
Prob(JB):JB检验的概率。
Cond. No.:多重共线性的检验,即检验变量之间是否存在精确相关关系或高度相关关系。
好了,这么多参数全部介绍完了,这里面内容过多,我们不需要全部掌握,在进行回归分析时,重点考虑的参数有R-squared、Prob(F-statistic)以及P>|t|的两个值,这4个参数是我们需要注意的,通过这4个参数我们就能判断我们的模型是否是线性显著的,同时知道显著的程度如何。
而在我们了解了summary之后,我们基本上就了解了线性回归的主要内容了。如果我们想要获取模型中的某些参数,其方法和在python中获取普通属性的方法一样,比如我们想要得到model1中的F检验数值和BIC数值,只需要输入model1.fvalue和model1.bic即可,结果如图4所示。
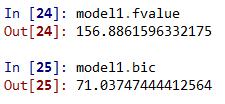
图4. 模型参数的获取
本文用一个简单的一元线性回归例子,比较详细地介绍了statsmodels的使用方法,其他更高级的回归方法也和这个例子类似。因为里面的内容较多,所以大家在学习时只要抓住重点即可。
作者简介:Mort,数据分析爱好者,擅长数据可视化,比较关注机器学习领域,希望能和业内朋友多学习交流。
赞赏作者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
长按扫码添加“Python小助手”后
回复“回归”获取本文全部代码
▼点击成为社区会员 喜欢就点个在看吧