
ICML 2021 (Long Oral) | 深入研究不平衡回归问题
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文介绍了一篇被ICML2021接收的工作:Long oral presentation:Delving into Deep Imbalanced Regression。该工作推广了传统不平衡分类问题的范式,将数据不平衡问题从离散值域推广到连续域。

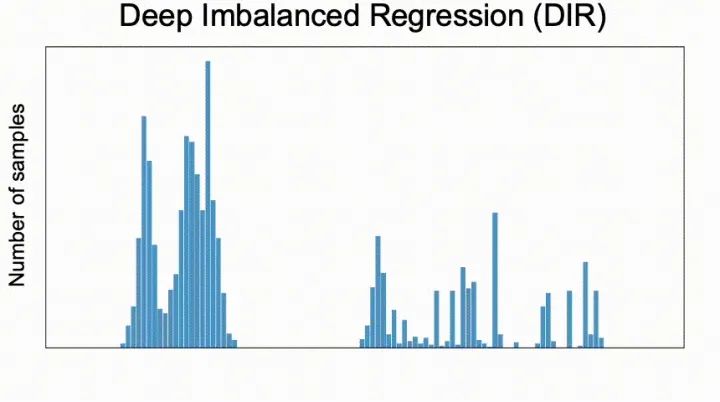
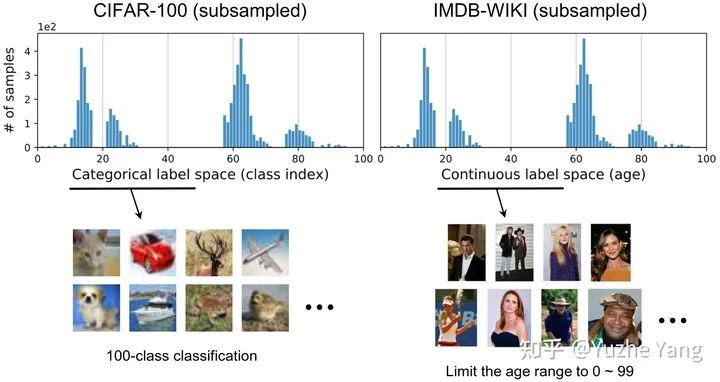
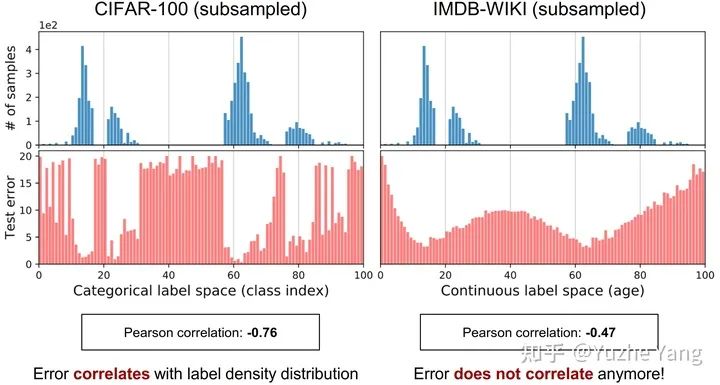
我们提出了一个新的任务,称为深度不平衡回归(Deep Imbalanced Regression,简写为DIR)。DIR任务定义为从具有连续目标的不平衡数据中学习,并能泛化到整个目标范围; 我们同时提出了针对不平衡回归的新的方法,标签分布平滑(label distribution smoothing, LDS)和特征分布平滑(feature distribution smoothing, FDS),以解决具有连续目标的不平衡数据的学习问题; 最后我们建立了五个新的DIR数据集,涵盖了computer vision,NLP,和healthcare上的不平衡回归任务,来方便未来在不平衡数据上的研究。
1. 研究背景与动机
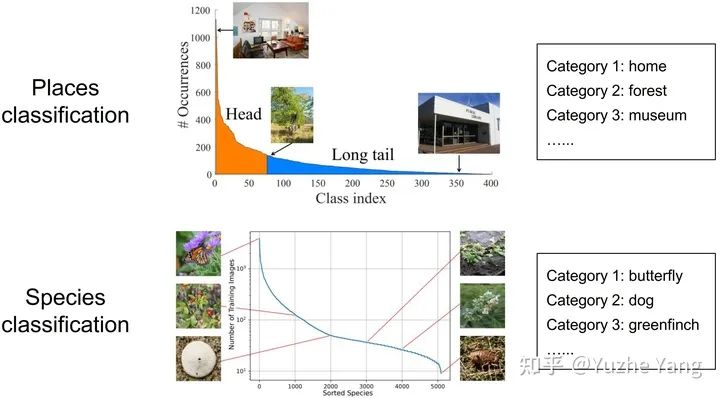

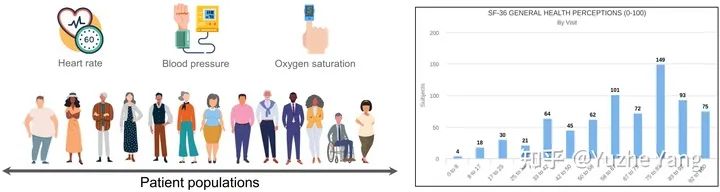
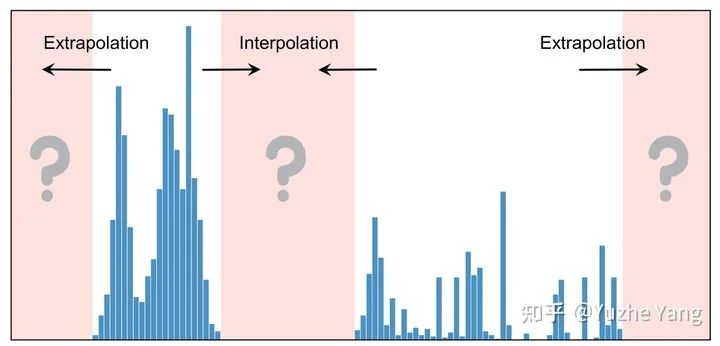
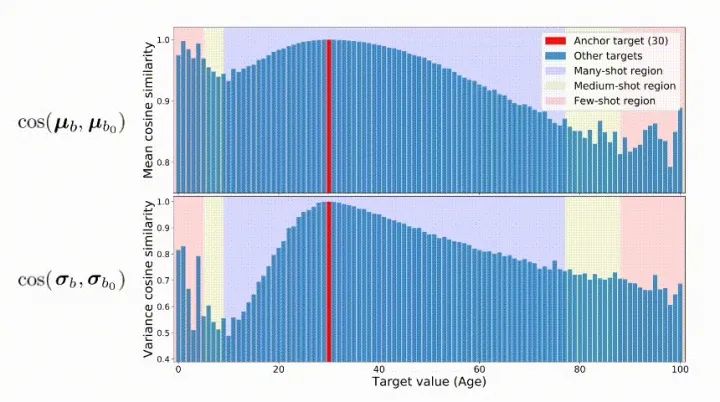
2. 不平衡回归的难点与挑战
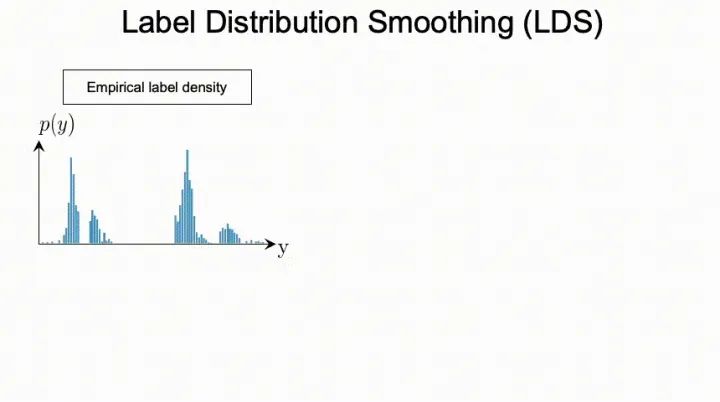
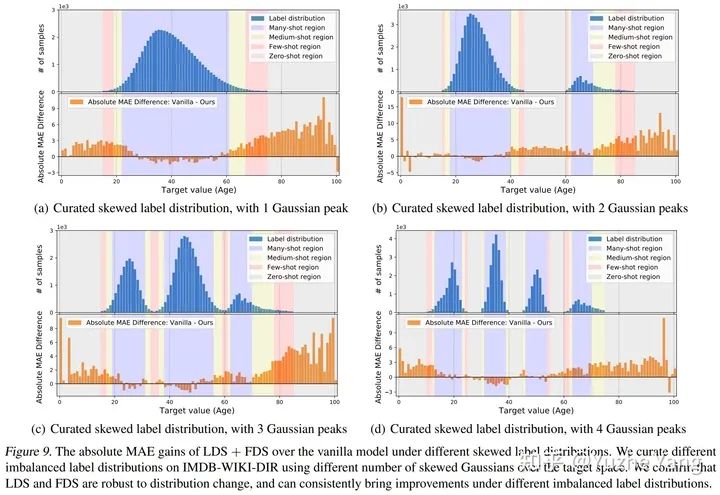
3. 标签分布平滑(LDS)
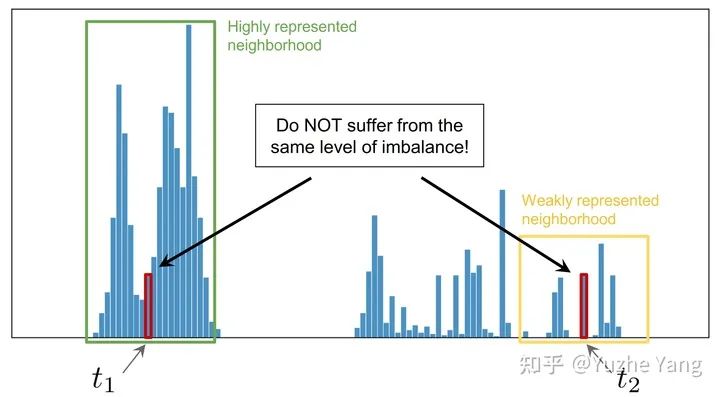
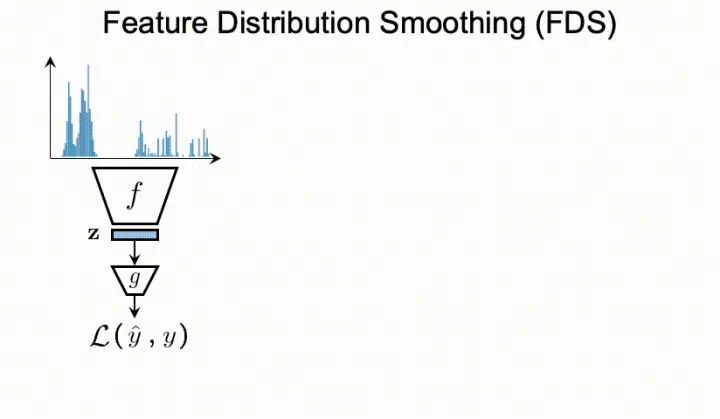
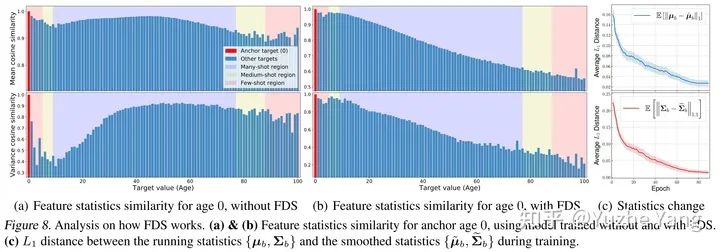
4. 特征分布平滑(FDS)
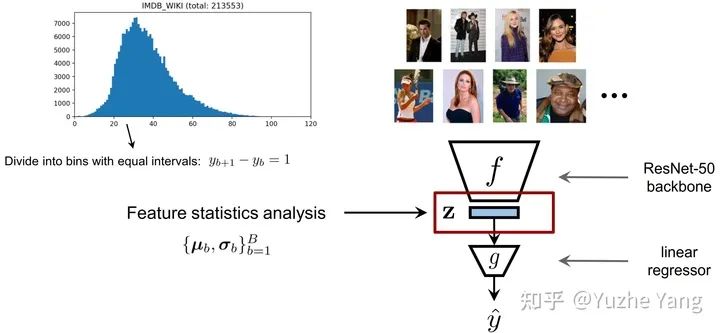
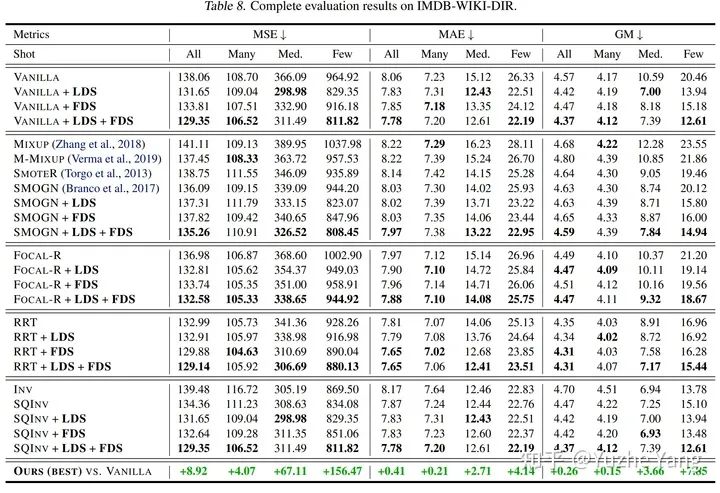
5. 基准DIR数据集及实验分析
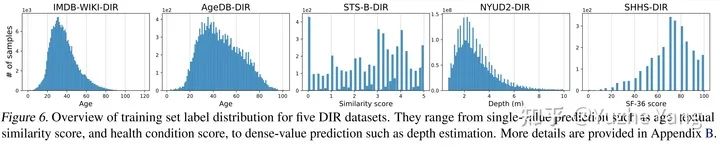
IMDB-WIKI-DIR(vision, age): 从包含人面部的图像来推断估计相应的年龄。基于IMDB-WIKI[9]数据集,我们手动构建了验证集和测试集,使其保持了分布的平衡。 AgeDB-DIR(vision, age): 同样是根据单个输入图像进行年龄估算,基于AgeDB[11]数据集。注意到与IMDB-WIKI-DIR相比,即使两个数据集是完全相同的task,他们的标签分布的不平衡也不相同。 NYUD2-DIR(vision, depth): 除了single value的prediction, 我们还基于NYU2数据集[12]构建了进行depth estimation的DIR任务,是一个dense value prediction的任务。我们构建了NYUD2-DIR数据集来进行不平衡回归的评估。 STS-B-DIR(NLP, text similarity score): 我们还在NLP领域中构建了一个叫STS-B-DIR的DIR benchmark,基于STS-B数据集[13]。他的任务是推断两个输入句子之间的语义文本的相似度得分。这个相似度分数是连续的,范围是0到5,并且分布不平衡。 SHHS-DIR(Healthcare, health condition score): 最后,我们在healthcare领域也构建了一个DIR的benchmark,叫做 SHHS-DIR,基于SHHS数据集[14]。这项任务是推断一个人的总体健康评分,该评分在0到100之间连续分布,评分越高则健康状况越好。网络的输入是每个患者在一整晚睡眠过程中的高维PSG信号,包括ECG心电信号,EEG脑电信号,以及他的呼吸信号。很明显可以看到,总体健康分数的分布也是极度不平衡的,并存在一定的target value是没有数据的。
6. 结语
参考
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!

点个在看 paper不断!
评论