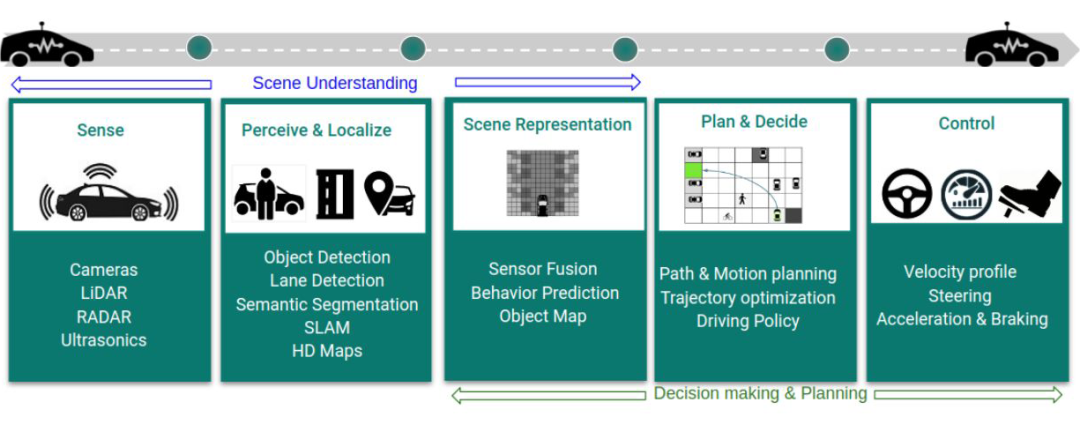
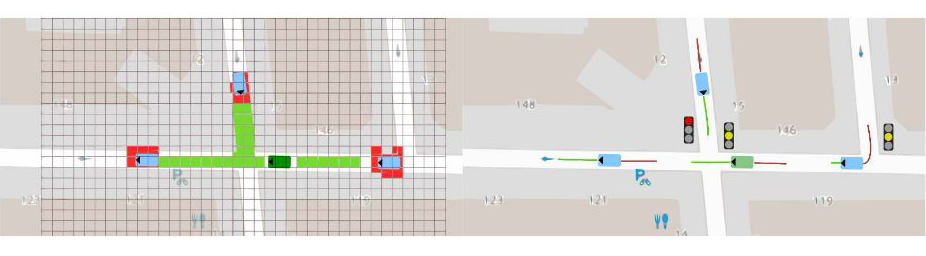
该模块的作用是将感知模块获得的信息映射到高级动作或决策层。该模块旨在提供对场景的更高层次的理解,通过融合异构传感器源(如激光雷达、相机、雷达、超声波),抽象和概括场景信息,为决策制定提供简化的信息。2.3 定位和建图(Localization and Mapping)定位和建图技术,又称 SLAM 是自动驾驶的关键技术之一。由于问题的规模,传统的 SLAM 技术通过语义对象检测得到增强,以实现可靠的消歧。此外,局部高清地图(HD maps)可以用作物体检测的先验。
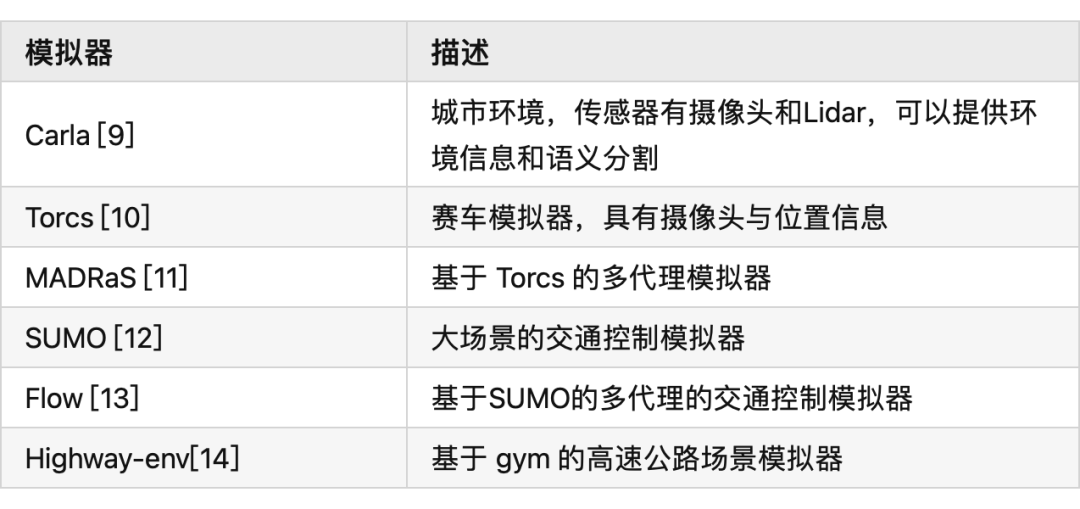
[1] A Survey of Deep Learning Applications to Autonomous Vehicle Control: https://ieeexplore.ieee.org/abstract/document/8951131?casa_token=fwUZxwU0Eo8AAAAA:B[2] End-to-End Deep Reinforcement Learning for Lane Keeping Assist:https://arxiv.org/abs/1612.04340[3] Deep Reinforcement Learning framework for Autonomous Driving:https://www.ingentaconnect.com/content/ist/ei/2017/00002017/00000019/art00012[4] A Reinforcement Learning Based Approach for Automated Lane Change Maneuvers:https://ieeexplore.ieee.org/abstract/document/8500556?casa_token=OcyB7gHOxcAAAAAA:JrwO6[5] Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge:https://ieeexplore.ieee.org/abstract/document/8317735?casa_token=HaEyBLwaSU0AAAAA:5[6] A Multiple-Goal Reinforcement Learning Method for Complex Vehicle Overtaking Maneuvers:https://ieeexplore.ieee.org/abstract/document/5710424?casa_token=Y-bJbe3K9r0AAAAA:ZNo[7] Navigating Occluded Intersections with Autonomous Vehicles Using Deep Reinforcement Learning:https://ieeexplore.ieee.org/abstract/document/8461233?casa_token=uuC5uVdLp60AAAAA:6fr7[8] Reinforcement Learning with A* and a Deep Heuristic:https://arxiv.org/abs/1811.07745[9] CARLA: An Open Urban Driving Simulator:https://proceedings.mlr.press/v78/dosovitskiy17a.html[10] TORCS - The Open Racing Car Simulator:https://sourceforge.net/projects/torcs/[11] MADRaS Multi-Agent DRiving Simulato:https://www.opensourceagenda.com/projects/madras[12] Microscopic Traffic Simulation using SUMO:https://ieeexplore.ieee.org/abstract/document/8569938?casa_token=1z4z-bT6kTsAAAAA:BdTO6tJB4xEgr_EO0CPveWlForEQHJWyprok3uyy3DssqzT-7Eh-pr7H__3DOJPDdpuIVUr7Lw[13] Flow: Architecture and Benchmarking for Reinforcement Learning in Traffic Control:https://www.researchgate.net/profile/Abdul-Rahman-Kreidieh/publication/320441979_Flow_Archite[14] A Collection of Environments for Autonomous Driving and Tactical Decision-Making Tasks:https://github.com/eleurent/highway-env