
综述 | 基于深度学习的目标检测算法
点击左上方蓝字关注我们

转载自 | 计算机视觉life
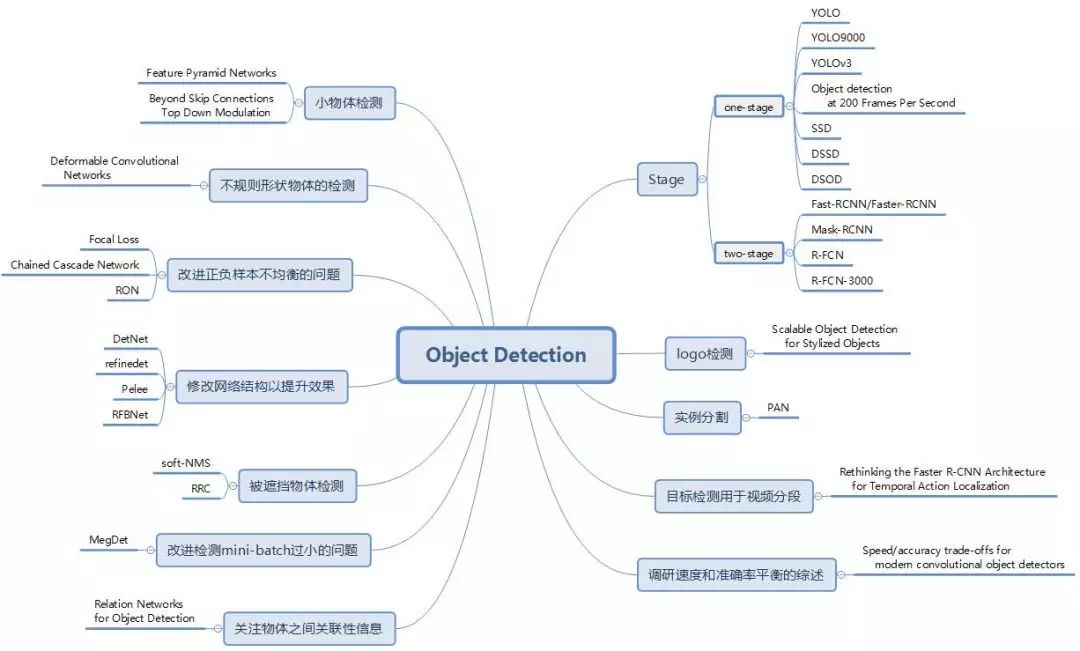
图1
下文中,我们针对每篇文章,从论文目标,即要解决的问题,算法核心思想以及算法效果三个层面进行概括。同时,我们也给出了每篇论文的出处,录用信息以及相关的开源代码链接,其中代码链接以作者实现和 mxnet 实现为主。
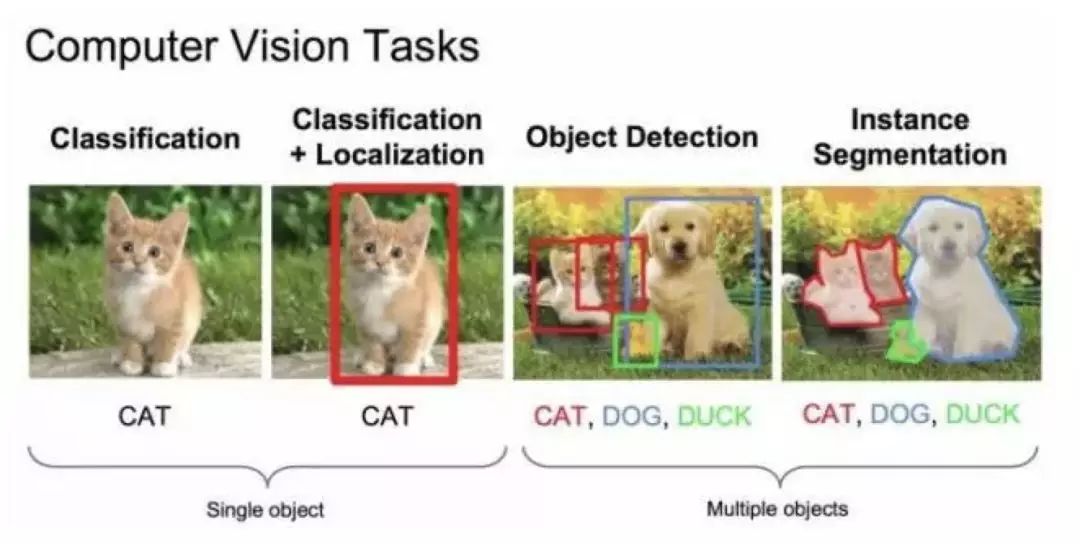
图2
物体检测的任务是找出图像或视频中的感兴趣物体,同时检测出它们的位置和大小,是机器视觉领域的核心问题之一。
物体检测过程中有很多不确定因素,如图像中物体数量不确定,物体有不同的外观、形状、姿态,加之物体成像时会有光照、遮挡等因素的干扰,导致检测算法有一定的难度。进入深度学习时代以来,物体检测发展主要集中在两个方向:two stage 算法如 R-CNN 系列和 one stage 算法如 YOLO、SSD 等。两者的主要区别在于 two stage 算法需要先生成 proposal(一个有可能包含待检物体的预选框),然后进行细粒度的物体检测。而 one stage 算法会直接在网络中提取特征来预测物体分类和位置。
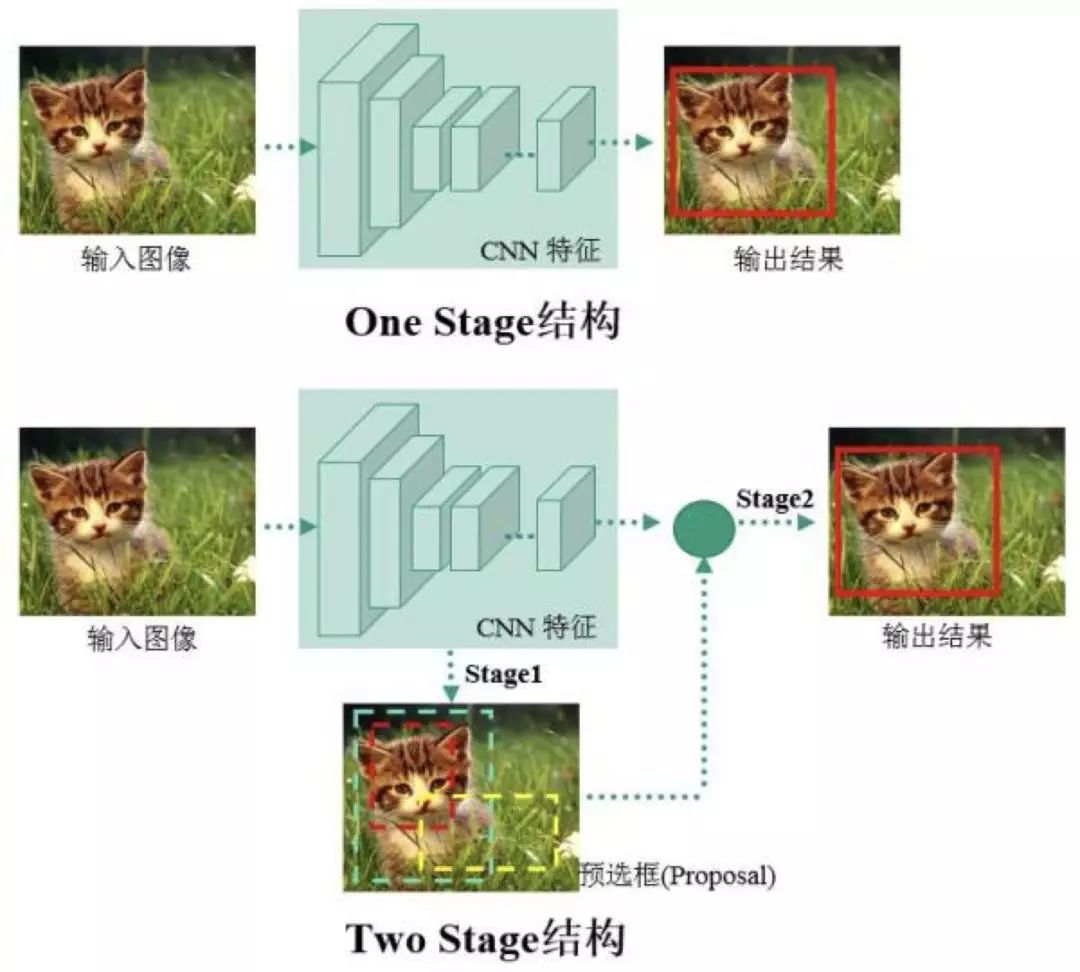
图3
基于深度学习的目标检测算法综述分为三部分:
Two/One stage 算法改进。 这部分将主要总结在 two/one stage 经典网络上改进的系列论文,包括 Faster R-CNN、YOLO、SSD 等经典论文的升级版本。
解决方案。 这部分我们归纳总结了目标检测的常见问题和近期论文提出的解决方案。
扩展应用、综述。 这部分我们会介绍检测算法的扩展和其他综述类论文。
本综述分三部分,本文介绍第一部分。
Faster R-CNN 网络包括两个步骤:1. 使用 RPN(region proposal network) 提取 proposal 信息;2. 使用 R-CNN 对候选框位置进行预测和物体类别识别。本文主要介绍在 Faster R-CNN 基础上改进的几篇论文:R-FCN、R-FCN3000 和 Mask R-CNN。R-FCN 系列提出了 Position Sensitive(ps) 的概念,提升了检测效果。另外需要注明的是,虽然 Mask R-CNN 主要应用在分割上,但该论文和 Faster R-CNN 一脉相承,而且论文提出了 RoI Align 的思想,对物体检测回归框的精度提升有一定效果,故本篇综述也介绍了这篇论文。
论文链接:arxiv.org/abs/1605.06409
开源代码:github.com/daijifeng001/R-FCN
录用信息:CVPR2017
Faster R-CNN 是首个利用 CNN 来完成 proposals 的预测的,之后的很多目标检测网络都是借助了 Faster R-CNN 的思想。而 Faster R-CNN 系列的网络都可以分成 2 个部分:
Fully Convolutional subnetwork before RoI Layer
RoI-wise subnetwork
第 1 部分就是直接用普通分类网络的卷积层来提取共享特征,后接一个 RoI Pooling Layer 在第 1 部分的最后一张特征图上进行提取针对各个 RoIs 的特征图,最后将所有 RoIs 的特征图都交由第 2 部分来处理(分类和回归)。第二部分通常由全连接层组层,最后接 2 个并行的 loss 函数:Softmax 和 smoothL1,分别用来对每一个 RoI 进行分类和回归。由此得到每个 RoI 的类别和归回结果。其中第 1 部分的基础分类网络计算是所有 RoIs 共享的,只需要进行一次前向计算即可得到所有 RoIs 所对应的特征图。
第 2 部分的 RoI-wise subnetwork 不是所有 RoIs 共享的,这一部分的作用就是给每个 RoI 进行分类和回归。在模型进行预测时基础网络不能有效感知位置信息,因为常见的 CNN 结构是根据分类任务进行设计的,并没有针对性的保留图片中物体的位置信息。而第 2 部分的全连阶层更是一种对于位置信息非常不友好的网络结构。由于检测任务中物体的位置信息是一个很重要的特征,R-FCN 通过提出的位置敏感分数图(position sensitive score maps)来增强网络对于位置信息的表达能力,提高检测效果。
position-sensitive score map
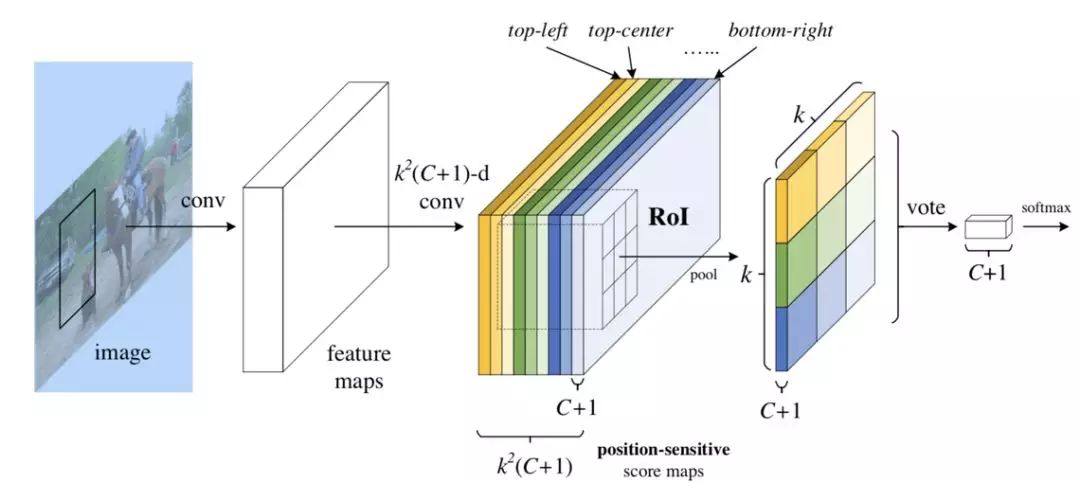
图4
图 4 展示的是 R-FCN 的网络结构图,展示了位置敏感得分图 (position-sensitive score map) 的主要设计思想。如果一个 RoI 含有一个类别 c 的物体,则将该 RoI 划分为 k x k 个区域,分别表示该物体的各个相应部位。其每个相应的部位都由特定的特征图对其进行特征提取。R-FCN 在 、共享卷积层的最后再接上一层卷积层,而该卷积层就是位置敏感得分图 position-sensitive score map。其通道数 channels=k x k x (C+1)。C 表示物体类别种数再加上 1 个背景类别,每个类别都有 k x k 个 score maps 分别对应每个类别的不同位置。每个通道分别负责某一类的特定位置的特征提取工作。
Position-sensitive RoI pooling
位置敏感 RoI 池化操作了(Position-sensitive RoI pooling)如下图所示:
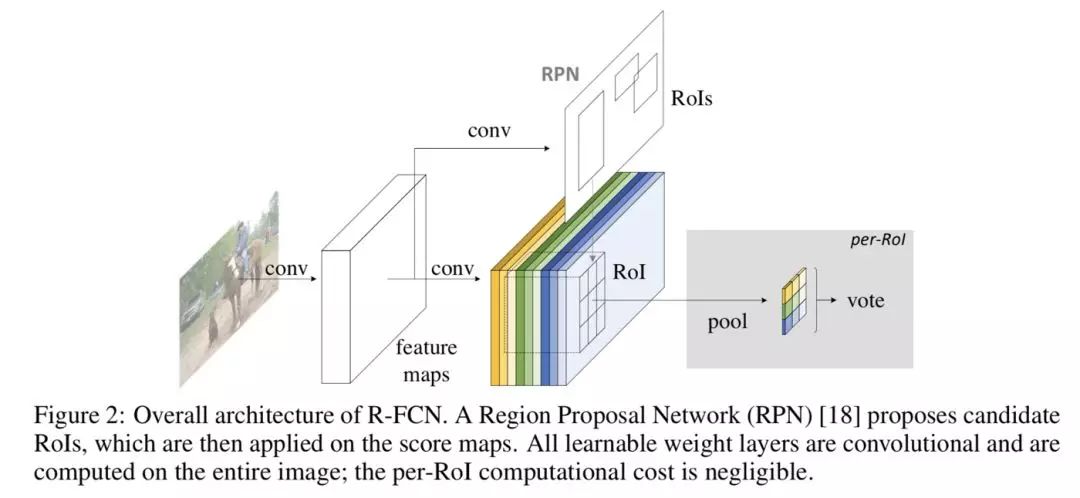
图5
该操作将每个 RoIs 分为 k x k 个小块。之后提取其不同位置的小块相应特征图上的特征执行池化操作,下图展示了池化操作的计算方式。
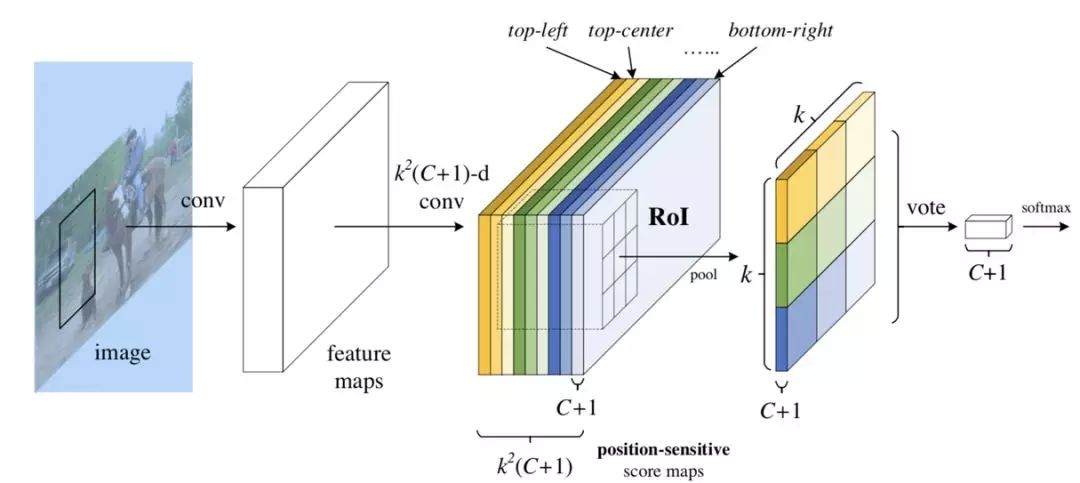
图6
得到池化后的特征后,每个 RoIs 的特征都包含每个类别各个位置上的特征信息。对于每个单独类别来讲,将不同位置的特征信息相加即可得到特征图对于该类别的响应,后面即可对该特征进行相应的分类。
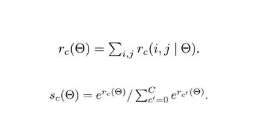
position-sensitive regression
在位置框回归阶段仿照分类的思路,将特征通道数组合为 4 x k x k 的形式,其中每个小块的位置都对应了相应的通道对其进行位置回归的特征提取。最后将不同小块位置的四个回归值融合之后即可得到位置回归的响应,进行后续的位置回归工作。
position-sensitive score map 高响应值区域
在训练的过程中,当 RoIs 包涵物体属于某类别时,损失函数即会使得该 RoIs 不同区域块所对应的响应通道相应位置的特征响应尽可能的大,下图展示了这一过程,可以明显的看出不同位置的特征图都只对目标相应位置的区域有明显的响应,其特征提取能力是对位置敏感的。

图 7
使用如上的损失函数,对于任意一个 RoI,计算它的 Softmax 损失,和当其不属于背景时的回归损失。因为每个 RoI 都被指定属于某一个 GT box 或者属于背景,即先让 GT box 选择与其 IoU 最大的那个 RoI,再对剩余 RoI 选择与 GT box 的 IoU>0.5 的进行匹配,而剩下的 RoI 全部为背景类别。当 RoI 有了 label 后 loss 就可以计算出来。这里唯一不同的就是为了减少计算量,作者将所有 RoIs 的 loss 值都计算出来后,对其进行排序,并只对最大的 128 个损失值对应的 RoIs 进行反向传播操作,其它的则忽略。并且训练策略也是采用的 Faster R-CNN 中的 4-step alternating training 进行训练。在测试的时候,为了减少 RoIs 的数量,作者在 RPN 提取阶段就将 RPN 提取的大约 2W 个 proposals 进行过滤:
去除超过图像边界的 proposals
使用基于类别概率且阈值 IoU=0.3 的 NMS 过滤
按照类别概率选择 top-N 个 proposals
在测试的时候,一般只剩下 300 个 RoIs。并且在 R-FCN 的输出 300 个预测框之后,仍然要对其使用 NMS 去除冗余的预测框。

图 8
图 8 比较了 Faster-R-CNN 和 R-FCN 的 mAP 值和监测速度,采用的基础网络为 ResNet-101,测评显卡为 Tesla K40。
论文链接:arxiv.org/abs/1712.01802
开源代码:/
录用信息:/
YOLO9000 将检测数据集和分类数据集合并训练检测模型,但 r-fcn-3000 仅采用具有辅助候选框信息的 ImageNet 数据集训练检测分类器。
如果使用包含标注辅助信息(候选框)的大规模分类数据集,如 ImageNet 数据集,进行物体检测模型训练,然后将其应用于实际场景时,检测效果会是怎样呢?how would an object detector perform on "detection"datasets if it were trained on classification datasets with bounding-box supervision?
r-fcn-3000 是对 r-fcn 的改进。上文提到,r-fcn 的 ps 卷积核是 per class 的,假设有 C 个物体类别,有 K*K 个 ps 核,那么 ps 卷积层输出 K*K*C 个通道,导致检测的运算复杂度很高,尤其当要检测的目标物体类别数较大时,检测速度会很慢,难以满足实际应用需求。
为解决以上速度问题,r-fcn-3000 提出,将 ps 卷积核作用在超类上,每个超类包含多个物体类别,假设超类个数为 SC,那么 ps 卷积层输出K*KSC 个通道。由于 SC 远远小于 C,因此可大大降低运算复杂度。特别地,论文提出,当只使用一个超类时,检测效果依然不错。算法网络结构如下:
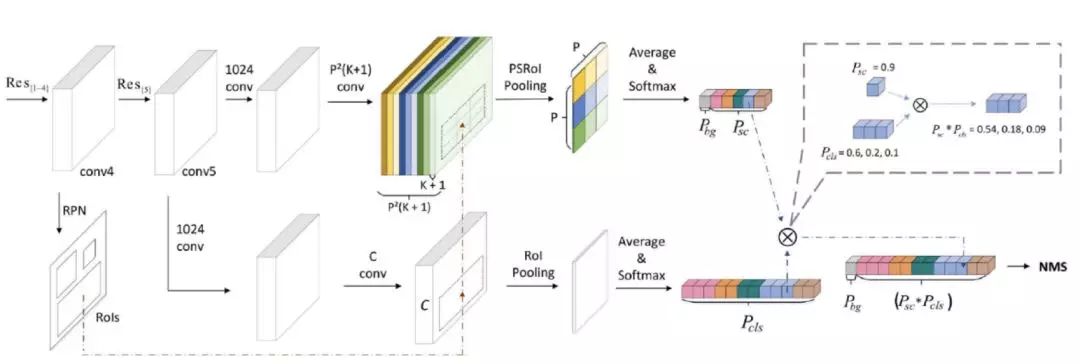
图 9
上图可以看出,与 r-fcn 类似,r-fcn-3000 也使用 RPN 网络生成候选框(上图中虚线回路);相比 r-fcn,r-fcn-3000 的网络结构做了如下改进:
r-fcn-3000 包含超类(上图中上半部分)和具体类(上图中下半部分)两个卷积分支。
超类卷积分支用于检测超类物体,包含分类(超类检测)和回归(候选框位置改进)两个子分支;注意上图中没有画出用于候选框位置改进的 bounding-box 回归子分支;回归分支是类别无关的,即只确定是否是物体。
具体类卷积分支用于分类物体的具体类别概率,包含两个普通 CNN 卷积层。
最终的物体检测输出概率由超类卷积分支得到的超类类概率分别乘以具体类卷积分支输出的具体类别概率得到。引入超类和具体类两个卷积分支实现了“物体检测”和“物体分类”的解耦合。超类卷积分支使得网络可以检测出物体是否存在,由于使用了超类,而不是真实物体类别,大大降低了运算操作数。保证了检测速度;具体类分支不检测物体位置,只分类具体物体类别。
超类生成方式:对某个类别 j 的所有样本图像,提取 ResNet-101 最后一层 2018 维特征向量,对所有特征项向量求均值,作为该类别的特征表示。得到所有类别的特征表示进行 K-means 聚类,确定超类。
在 imagenet 数据集上,检测 mAP 值达到了 34.9%。使用 nvidia p6000 GPU,对于 375x500 图像,检测速度可以达到每秒 30 张。在这种速度下,r-fcn-3000 号称它的检测准确率高于 YOLO 18%。
此外,论文实验表明,r-fcn-3000 进行物体检测时具有较强的通用性,当使用足够多的类别进行训练时,对未知类别的物体检测时,仍能检测出该物体位置。如下图:

图 10
在训练类别将近 3000 时,不使用目标物体进行训练达到的通用预测 mAP 为 30.7%,只比使用目标物体进行训练达到的 mAP 值低 0.3%。
论文链接:
arxiv.org/abs/1703.06870
开源代码:
github.com/TuSimple/mx-maskrcnn
录用信息:CVPR2017
解决 RoIPooling 在 Pooling 过程中对 RoI 区域产生形变,且位置信息提取不精确的问题。
通过改进 Faster R-CNN 结构完成分割任务。
LaneNet模型 使用 RoIAlign 代替 RoIPooling,得到更好的定位效果。
在 Faster R-CNN 基础上加上 mask 分支,增加相应 loss,完成像素级分割任务。
Mask R-CNN 是基于 Faster R-CNN 的基础上演进改良而来,不同于 Faster R-CNN,Mask R-CNN 可以精确到像素级输出,完成分割任务。此外他们的输出也有所不同。Faster R-CNN 输出为种类标签和 box 坐标,而 Mask R-CNN 则会增加一个输出,即物体掩膜 (object mask)。
Mask R-CNN 结构如下图:
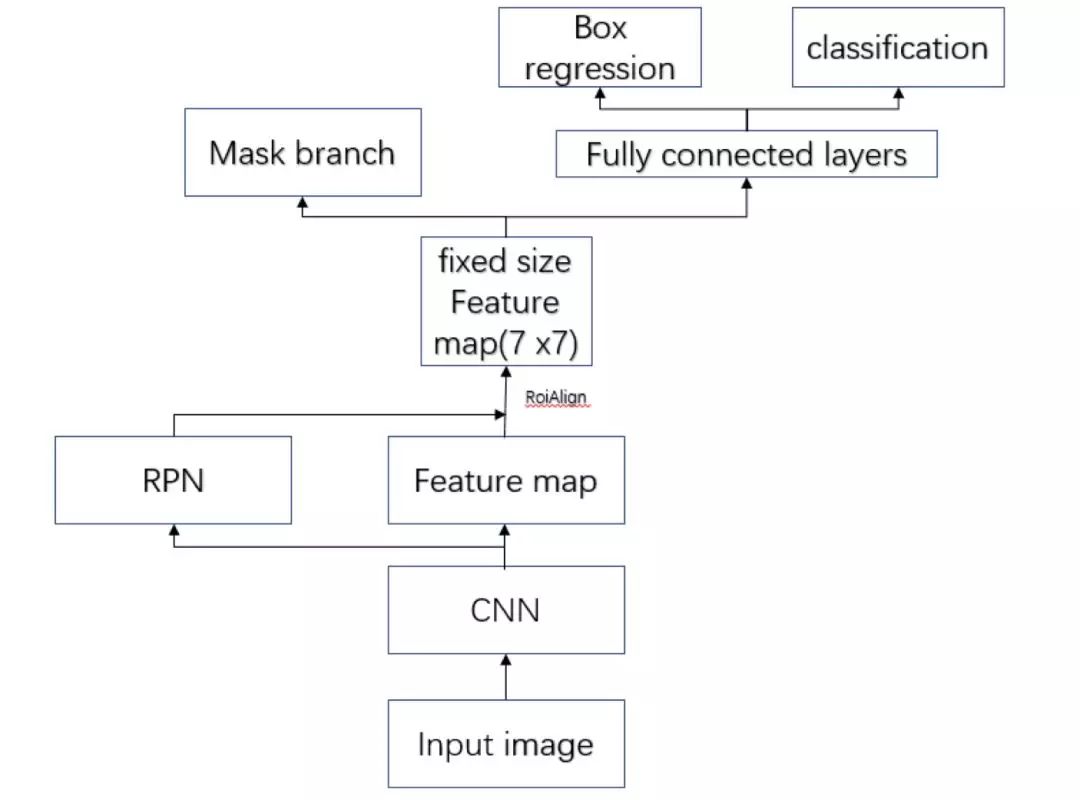
图 11
Mask R-CNN 采用和 Faster R-CNN 相同的两个阶段,具有相同的第一层 (即 RPN),第二阶段,除了预测种类和 bbox 回归,并且并行的对每个 RoI 预测了对应的二值掩膜 (binary mask)。
RoIAlign
Faster R-CNN 采用的 RoIPooling,这样的操作可能导致 feature map 在原图的对应位置与真实位置有所偏差。如下图:

图 12
而通过引入 RoIAlign 很大程度上解决了仅通过 Pooling 直接采样带来的 Misalignment 对齐问题。
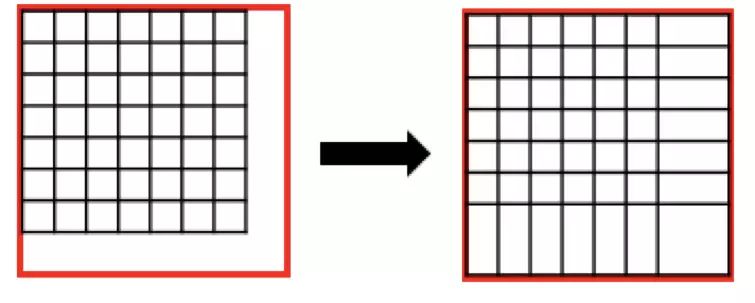
图 13:RoIPooling
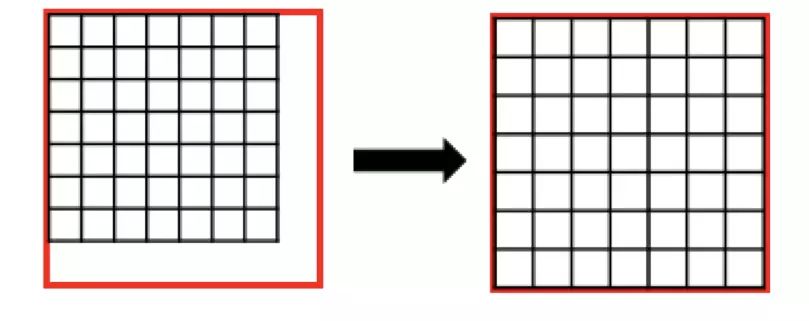
图 14:RoIAlign
RoIPooling 会对区域进行拉伸, 导致区域形变。RoIAlign 可以避免形变问题。具体方式是先通过双线性插值到 14 x 14,其次进行双线性插值得到蓝点的值,最后再通过 max Pooling 或 average pool 到 7 x 7。
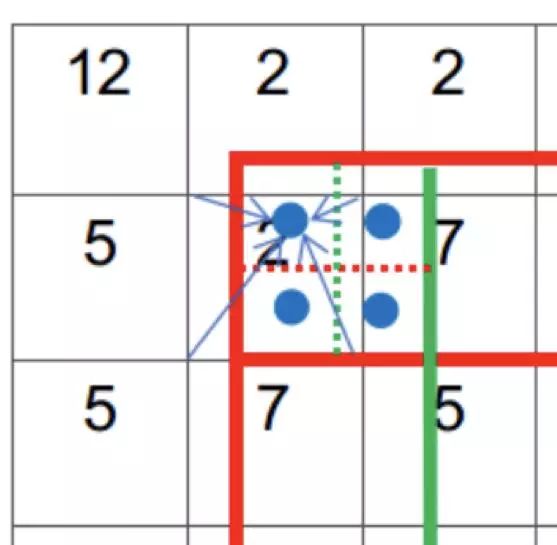
图 15
多任务损失函数
Mask R-CNN 的损失函数可表示为:


掩膜分支针对每个 RoI 产生一个 K x M xM 的输出, 即 K 个 M x M 的二值的掩膜输出。其中 K 为分类物体的类别数目。依据预测类别输出,只输出该类对应的二值掩膜,掩膜分支的损失计算如下示意图:

图 16
mask branch 预测 K 个种类的 M x M 二值掩膜输出。
依据种类预测分支 (Faster R-CNN 部分) 预测结果:当前 RoI 的物体种类为 i。
RoI 的平均二值交叉损失熵(对每个像素点应用 Sigmoid 函数)即为损失 。
此外作者发现使用 Sigmoid 优于 Softmax ,Sigmoid 可以避免类间竞争。
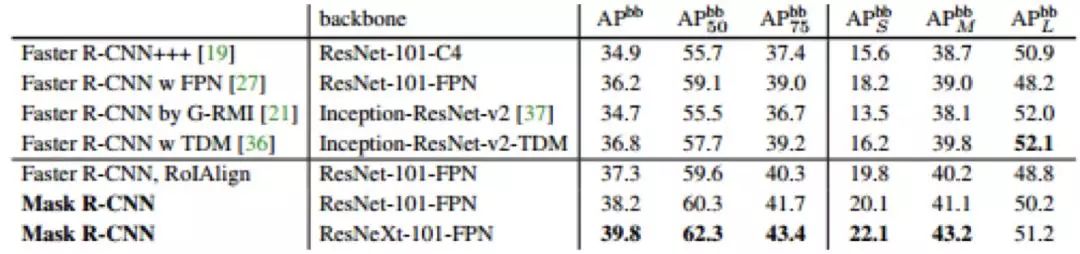
图 17
体现了在 COCO 数据集上的表现效果。
One stage
提到 one stage 算法就必须提到 OverFeat,OverFeat 网络将分类、定位、检测功能融合在一个网络之中。随后的 YOLO 和 SSD 网络,都是很经典的 one stage 检测算法。
YOLO 论文作者对原始 YOLO 网络进行了改进,提出了 YOLO9000 和 YOLOv3。YOLO9000 号称可以做到更好,更快,更强。其创新点还包括用小规模(指类别)检测标注数据集 + 大规模分类标注数据集训练通用物体检测模型。YOLOv3 是作者的一个 technical report,主要的工作展示作者在 YOLO9000 上的改进。另外本综述还将介绍新论文 Object detection at 200 Frames Per Second,这篇论文在 YOLO 的基础上进行创新,能在不牺牲太多准确率的情况下达到 200FPS(使用 GTX1080)。
SSD 算法是一种直接预测 bounding box 的坐标和类别的 object detection 算法,利用不同分辨率卷积层的 feature map,可以针对不同 scale 的物体进行检测。本篇综述中主要介绍 DSSD(原始作者的改进版本)和 DSOD 这两篇论文。
论文链接:
arxiv.org/abs/1612.0824
开源代码:github.com/pjreddie/darknet
github.com/zhreshold/mxnet-yolo(MXNet 实现)
录用信息:CVPR2017
论文目标是要解决包含大规模物体类别的实际应用场景中的实时目标检测。实际应用场景中,目标检测应满足两个条件:1. 检测速度满足实际场景需求;2. 覆盖物体类别满足实际场景需求。实际场景包含很多类别的物体,而这些类别物体的标注数据很难拿到,本论文提出使用小规模(指类别)检测标注数据集 + 大规模分类标注数据集训练通用物体检测模型。
YOLO9000 是在 YOLO 基础上的改进,相比 YOLO,YOLO9000 号称可以做到更好,更快,更强。下面从这三个方面介绍 YOLO9000 如何做到这三点。YOLO 相关的论文解读可以参考:https://zhuanlan.zhihu.com/p/25236464
准确率提升。相比 R-CNN 系列,YOLOv1 的召回率和物体位置检测率较低,YOLO9000 做了如下七点改进对其进行提升。
加入 BN 层。在所有的卷积层后加入 BN 操作,去掉所有 dropout 层。
使用高分辨率训练得到的分类模型 pretrain 检测网络。YOLOv1 使用 224x224 训练得到的分类模型 pretrain,而 YOLO9000 直接使用 448x448 训练得到的分类模型 pretrain 检测网络。
使用卷积层预测 anchor box 位置。YOLOv1 基于输入图像的物理空间划分成 7x7 的网格空间,每个网格最多对应两个候选预测框,因此每张图像最多有 98 个 bounding box,最后接入全连接层预测物体框位置。而 YOLO9000 移除全连接层,使用 anchor box 预测候选框位置,大大增加了每张图片的候选框个数。这个改进将召回率由 81% 提高到 88%,mAP 由 69.5% 稍微降低到 69.2%。同时,由于去掉了全连接层,YOLO9000 可以支持检测时不同分辨率的图像输入。
kmeans 聚类确定候选框形状。使用 k-means 对训练数据集中的物体框的分辨率和比例进行聚类,确定 anchor box 的形状。为避免物体大小引起的统计误差,YOLO9000 使用 IoU 而不是欧氏距离来作为距离度量方式。
预测“候选框相对于图像的内部偏移”。以往 RPN 网络,通过回归候选框相对于当前 anchor box 的偏移来定位候选框的位置,由于偏移相对于 anchor box 外部,所以取值范围是不受限的,导致训练的时候难以收敛。因此 YOLO9000 采用与 YOLO 类似的方式,预测候选框相对于图像左上角的位置偏移,并将偏移量归一化到 0-1 区间,解决了训练难收敛问题。
使用更精细的特征。YOLOv1 提取 13x13 的特征层进行后续物体检测,对于小物体的检测效果并不友好。为解决这个问题,YOLO9000 将前一层 26x26 的特征与 13x13 层的特征进行通道 concatenation。如 26x26x512 的 feature map 被拆分成 13x13x2048,然后同后面的 13x13 特征层进行 concatenation。mAP 提升 1%。
多尺度图像训练。YOLO9000 采用不同分辨率的图像进行模型迭代训练,增强模型对多尺度图像的预测鲁棒性。
YOLOv1 的 basenet 基于 GoogleNet 改进得到,计算复杂度大概是 VGG16 的 1/4,但在 imagenet 上 224x224 图像的 top-5 分类准确率比 vgg16 低 2%。YOLO9000 提出一个全新的 basenet,号称 darknet-19,包含 19 个卷积层和 5 个 max pooling 层,详细网络结构见论文,计算复杂度比 YOLOv1 进一步减少了 34%,imagenet 上 top-5 准确率提升了 3.2%。
更强是指在满足实时性需求的前提下,能检测出的物体类别数更多,范围更大。YOLO9000 提出使用词树“wordtree”,将分类数据集和检测数据集合并,进行模型训练。反向传播时,检测样本的训练 loss 用于计算和更新整个网络的模型参数;而分类样本的训练 loss 仅用于更新与分类相关的网络层模型参数。这样以来,检测数据集训练网络学到如何检测出物体(是否是物体,位置),而分类数据集使得网络识别出物体类别。
下图给出了 YOLOv2 和对比算法的准确率和运行时间的综合性能结果。可以看出 YOLOv2 在保证准确率的同时,可以达到超过 30fps 的图像检测速度。相比 SSD512 和 Faster R-CNN(使用 ResNet),YOLOv2 在准确率和运行性能上都更胜一筹(图中左边第一个蓝圈)。

图 18
论文链接:arxiv.org/abs/1804.02767
开源代码:github.com/pjreddie/darknet
录用信息:/
原文是 4 页 technical report,2018 年 4 月在 arxiv 放出
保证准确率同时,更快。
YOLOv3 对 YOLO9000 进行了改进,v3 采用的模型比 YOLO9000 更大,进一步提高检测准确率,但速度比 YOLO9000 稍慢。相比其他检测算法,RetinaNet、SSD、DSSD 等算法,YOLOv3 的综合性能(准确率 & 速度)仍然很是最好的。但总的来说,文章的改进主要还是修修补补,换换网络,没有特别的突出创新点。具体改进如下:
候选框预测时增加“物体性”的预测,即增加对候选框「是否包含物体」的判断。这条改进借鉴 Faster R-CNN 的做法。区别在于,Faster R-CNN 一个 ground truth 框可能对应多个检测候选框,而 YOLO9000 每个 ground truth object 最多对应到一个检测候选框。那么这会使得很多候选框对应不到 ground truth box,这种候选框在训练时不会计算坐标或分类误差,而只会加入对“物体性”的检测误差。
多标签分类。每个候选框可以预测多个分类,使用逻辑归二分类器进行分类。
多尺度预测。借鉴 FPN 思想,在 3 个尺度上进行预测,每个尺度对应 3 个候选框,每个候选框输出“位置偏移”,是否包含物体以及分类结果。YOLOv3 对小物体的检测效果比 YOLO9000 有提升,但是对中大物体的检测准确率却有降低。文章没给出具体原因。
提出新的 basenet。YOLOv3 采用一个 53 层卷积的网络结构,号称 darknet-53,网络设计只采用 3x3,1x1 的卷积层,借鉴了 ResNet 的残差网络思想。该 basenet 在 ImageNet 上对 256x256 的 Top-5 分类准确率为 93.5,与 ResNet-152 相同,Top-1 准确率为 77.2%,只比 ResNet-152 低 0.4%。与此同时,darknet-53 的计算复杂度仅为 ResNet-152 的 75%, 实际检测速度(FPS)是 ResNet-152 的 2 倍。
除以上改进外,YOLOv3 还做了一些其他尝试,但效果都不理想。具体见论文,此处不列出。
对 320x320 的输入图像,YOLOv3 在保证检测准确率与 SSD 一致(mAP=28.2)的前提下,处理每张图像的时间为 22ms,比 SSD 快 3 倍。
值得注意的是,论文提出的 darknet-53,是一个比 ResNet152 综合性能更好的分类网络。
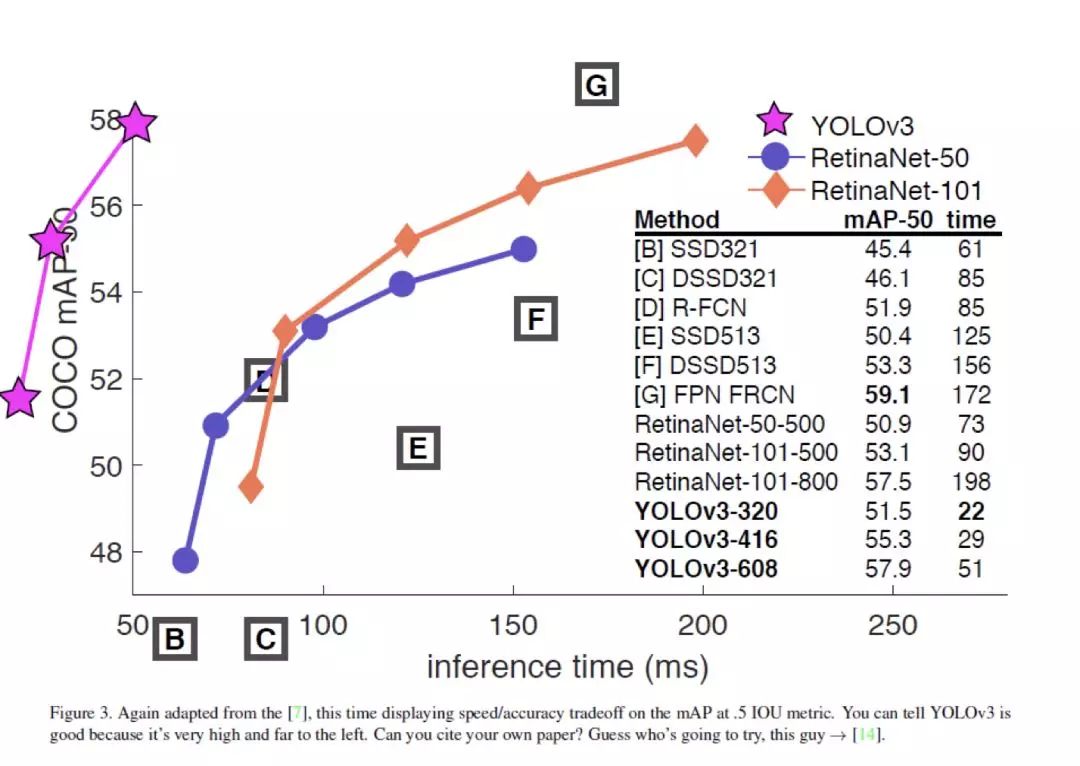
图 19
论文链接:arxiv.org/abs/1805.06361
开源代码:/
录用信息:/
为了解决检测算法计算复杂度过高、内存占用过大的问题,本文提出了一种快而有效的方法,能够在保持高检测率的同时,达到每秒 200 帧的检测速度。
为了实现又快又强的检测目标,本文从三个方面提出了创新:网络结构、损失函数以及训练数据。在网络结构中,作者选择了一种深而窄的网络结构,并探讨了不同特征融合方式带来的影响。在损失函数设计中,作者提出了蒸馏损失函数以及 FM-NMS 方法以适应 one-stage 算法的改进。最后,作者在训练时同时使用了已标注数据和未标注数据。下面具体介绍下本文在这三方面的创新工作。
一般来说,网络越深越宽,效果也会越好,但同时计算量和参数量也会随之增加。为了平衡算法的效果与速度,作者采用了一个深而窄的网络结构。示意图如下:
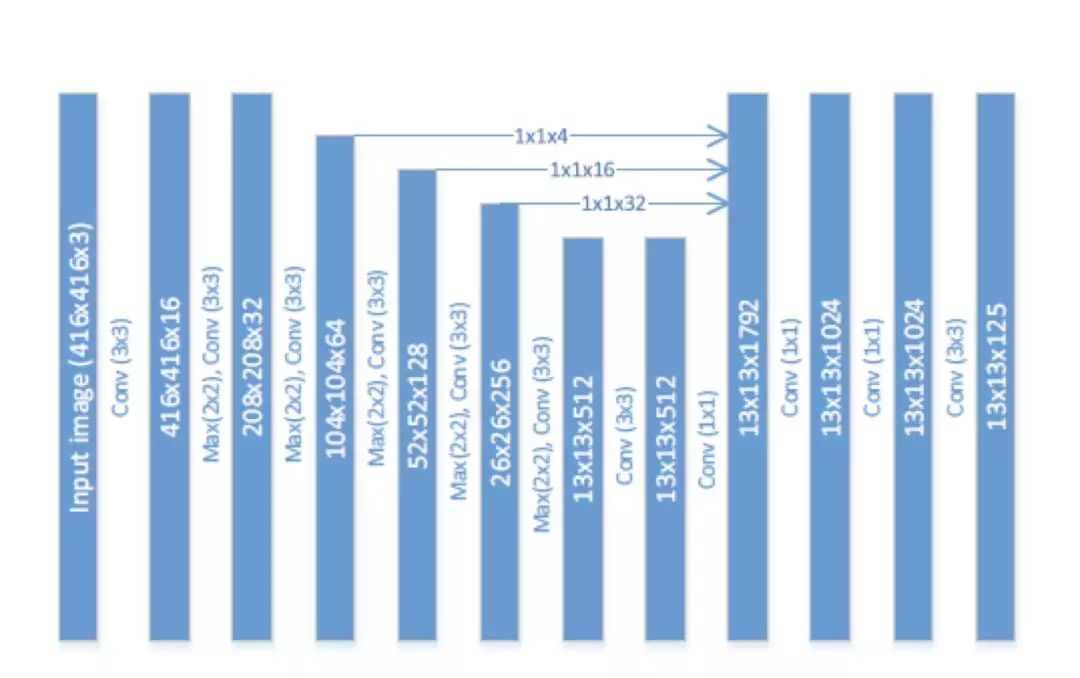
图 20
说明一下,本文的 baseline 算法是 Tiny-Yolo(Yolo 9000 的加速版)。
为了实现更窄,作者将卷积的通道数做了缩减,从 Yolo 算法的 1024 缩减为了 512;为了实现更宽,作者在最后添加了 3 个 1*1 的卷积层。为了加深理解,建议读者结合 Yolo 的网络结构图,对比查看。
从上图中,我们还可以看出,作者采用了特征融合的方式,将前几层提取的特征融合到了后面层的特征图中。在融合的过程中,作者并没有采取对大尺寸特征图做 max pooling 然后与小尺寸特征图做融合的方式,而是采用了 stacking 方法,即先将大尺寸特征图进行 resize 然后再和小尺寸特征图做融合。具体到上图中,对 104*104*64 的特征图用卷积核数量为 4,大小为 1*1 的卷积层进行压缩,得到 104*104*4 的特征图,然后做 resize 得到 13
13*256 的输出。
蒸馏算法是模型压缩领域的一个分支。简单来说,蒸馏算法是用一个复杂网络(teacher network)学到的东西去辅助训练一个简单网络(student network)。但直接将蒸馏算法应用于 one stage 的 Yolo 算法还存在着一些困难。
困难 1 是对于 two stage 算法,在第一阶段就会去除很多背景 RoI,送入检测网络的 RoI 相对较少,并且大部分包含 object;而 one stage 算法,输出中包含大量背景 RoI。如果直接对输出进行学习,会导致网络过于关注背景,而忽视了前景。
鉴于此,本文作者提出 objectness scaled distillation,主要考虑了 teacher network 中输出的 objectness 对损失函数的影响。作者认为只有 objectness 比较大的才应该对损失函数有贡献。
为了更好地理解作者的思路,我们先回顾一下 Yolo 算法的损失函数,如下所示:


困难 2 是对于检测算法来说,如果不做 NMS,直接将 teacher network 的预测 RoI 输出给 student network,会因为某些 box 有很多的相关预测 RoI 而导致这些 box 容易过拟合。
鉴于此,本文作者提出 FM-NMS。取 3*3 区域内的相邻 grid cell,对这 9 个 grid cell 中预测相同类别的 bbox 按照 objectness 进行排序,只选择得分最高的那个 bbox 传给 student network。2 个 grid cell 做 FM-NMS 的示意图如下:
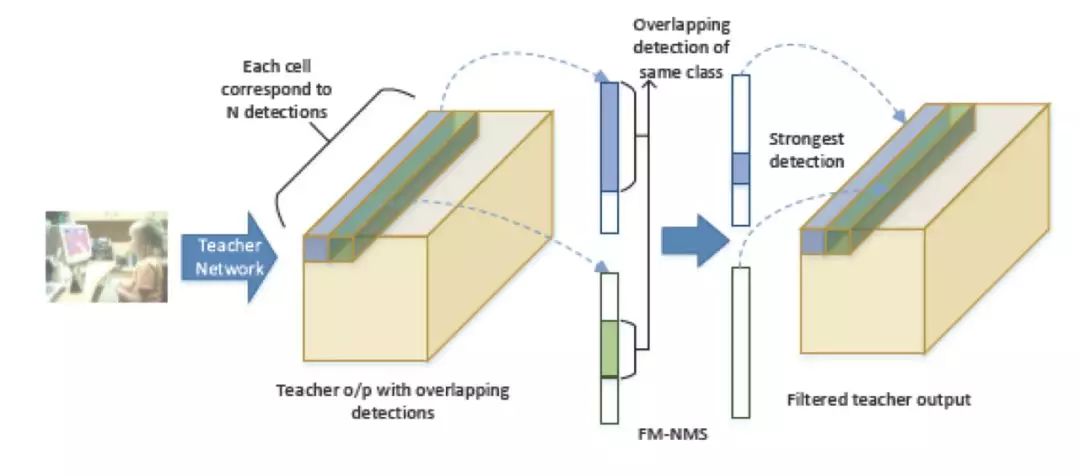
图 21
鉴于作者使用了蒸馏算法,在训练时,可以非常方便地使用已标注数据和未标注数据。如果有标注数据,就使用完整的蒸馏损失函数。如果没有标注数据,就只使用蒸馏损失函数的 distillation loss 部分。
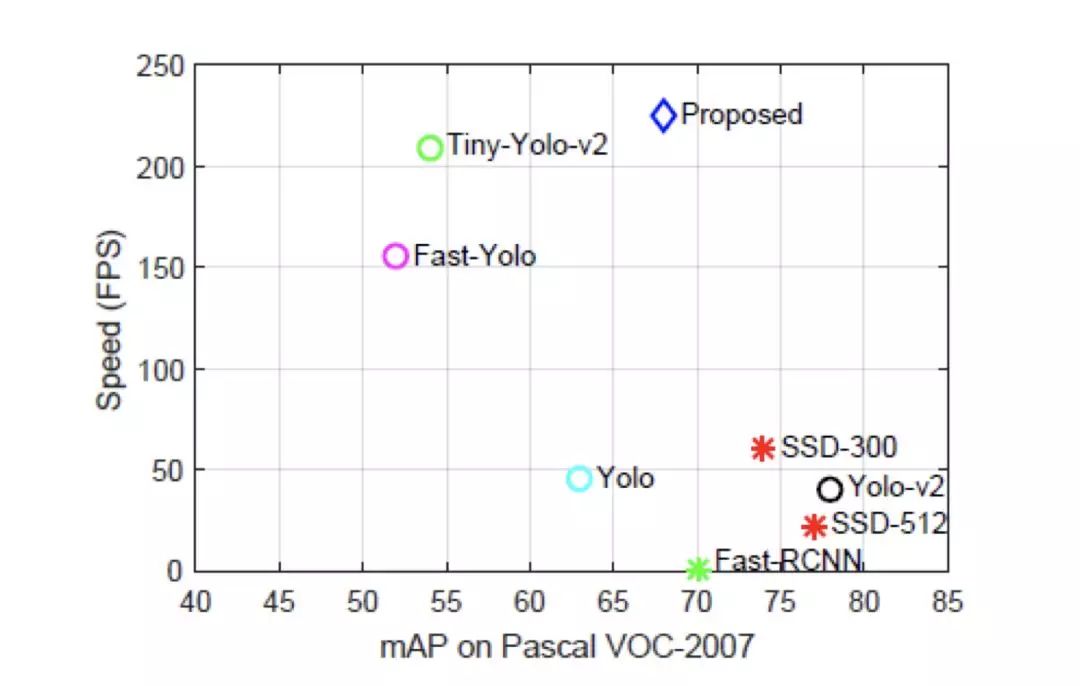
图 22
论文链接:arxiv.org/abs/1701.06659
开源代码:github.com/MTCloudVision/mxnet-dssd(综述笔者实现版本)
录用信息:/
大小物体通吃。使用 Top-Down 网络结构,解决小物体检测的问题。DSSD 论文的详细解读可以参见:https://zhuanlan.zhihu.com/p/33036037
DSSD 与 FPN 类似,都是基于 Top-Down 结构解决小物体检测,不同的是,如 FPN 的网络结构只是针对 ResNet 做了优化,文章中也没有提及过更换其他的基础网络的实验结果,普适度不够。DSSD 作者提出一种通用的 Top-Down 的融合方法,使用 vgg 和 ResNet 网络将高层的语义信息融入到低层网络的特征信息中,丰富预测回归位置框和分类任务输入的多尺度特征图,以此来提高检测精度。
笔者认为,虽然 Top-Down 结构也许有效,但毕竟 DSSD 比 FPN 放出时间更晚一些,且在网络结构上这并没有太大创新,也许这就是本文未被会议收录的原因之一。
DSSD 是基于 SSD 的改进,引入了 Top-Down 结构。下文分别从这两方面出发,介绍 DSSD 思想。
DSSD 相对于 SSD 算法的改进点,总结如下:
提出基于 Top-Down 的网络结构,用反卷积代替传统的双线性插值上采样。
在预测阶段引入残差单元,优化候选框回归和分类任务输入的特征图。
采用两阶段训练方法。
DSSD 的网络结构与 SSD 对比如下图所示,以输入图像尺寸为为例,图中的上半部分为 SSD-ResNet101 的网络结构,conv3_x 层和 conv5_x 层为原来的 ResNet101 中的卷积层,后面的五层是 SSD 扩展卷积层,原来的 SSD 算法是将这七层的特征图直接输入到预测阶段做框的回归任务和分类任务。DSSD 是将这七层特征图拿出六层(去掉尺寸为的特征图)输入到反卷积模型里,输出修正的特征图金字塔,形成一个由特征图组成的沙漏结构。最后经预测模块输入给框回归任务和分类任务做预测。
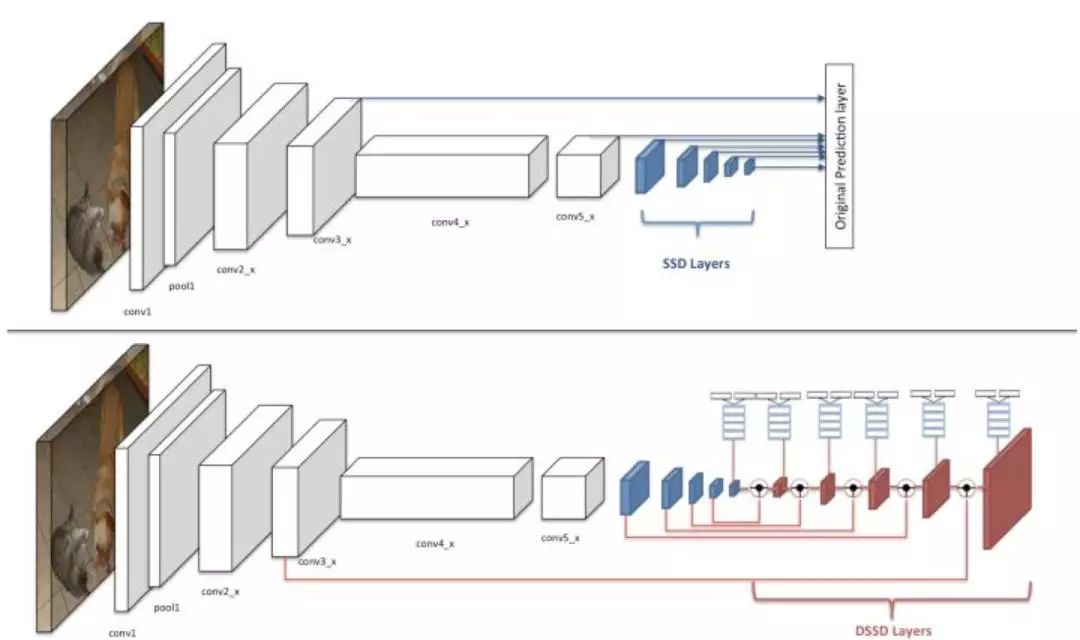
图 23
DSSD 中的 D,即反卷积模型,指的是 DSSD 中高层特征和低层特征的融合模块,其基本结构如下图所示:
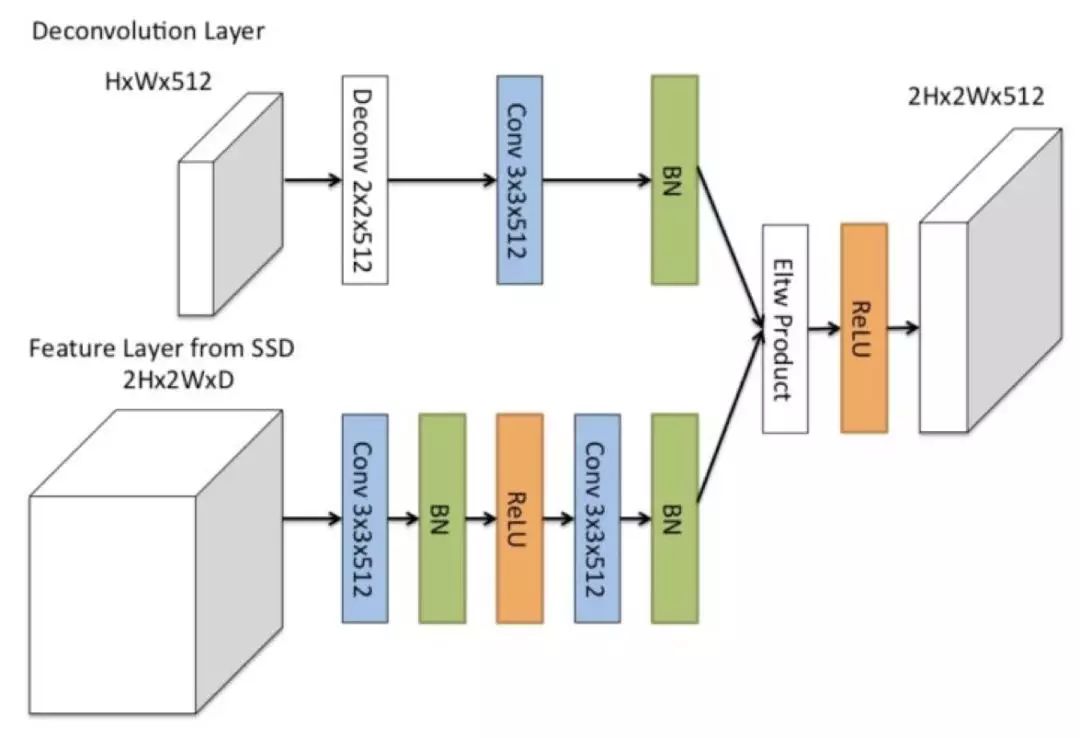
图 24
同样是采用 Top-Down 方式,DSSD 与 FPN 和 TDM(这两篇论文将在本论述后文中详细介绍)的网络结构区别如下图。可以看出,TDM 使用的是 concat 操作,让浅层和深层的特征图叠在一起。DSSD 使用的是 Eltw Product(也叫 broadcast mul)操作,将浅层和深层的特征图在对应的信道上做乘法运算。FPN 使用的是 Eltw Sum(也叫 broadcast add)操作,将浅层和深层的特征图在对应的信道上做加法运算。

图 25
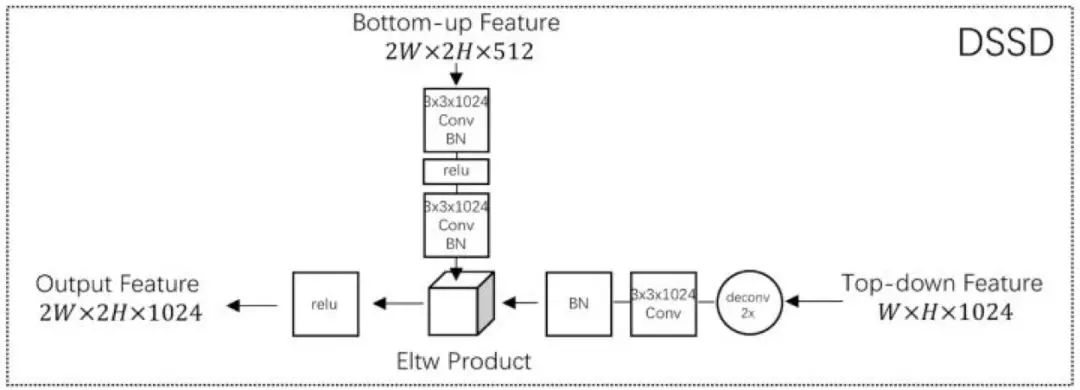
图 26

图 27
DSSD 当输入为 513x513 的时候在 VOC2007 数据集赏达到了 80.0%mAP。更详细的实验复现和结果对比见:https://zhuanlan.zhihu.com/p/33036037
论文链接:arxiv.org/abs/1708.0124
开源代码:github.com/szq0214/DSOD
录用信息:ICCV2017
从零开始训练检测网络。DSOD 旨在解决以下两个问题:
是否可以从零开始训练检测模型?
如果可以从零训练,什么样的设计会让网络结果更好?
DSOD 是第一个不使用图像分类预训练模型进行物体检测训练初始化的检测算法。此外,DSOD 网络参数只有 SSD 的 1/2,Faster R-CNN 的 1/10。
现有的物体检测算法如 Faster R-CNN、YOLO、SSD 需要使用在大规模分类数据集上训练得到的分类模型进行 backbone 网络初始化。比如使用 ImageNet 分类模型。这样做的优势在于:1. 可以使用现有的模型,训练较快;2. 由于分类任务已经在百万级的图像上进行过训练,所以再用做检测需要的图片数量会相对较少。
但其缺点也很明显:1. 很多检测网络都是分类网络改的。图像分类网络一般都较大,检测任务可能不需要这样的网络。2. 分类和检测的策略不同,可能其最佳收敛区域也不一样。3. 分类任务一般都是 RGB 图像训练的,但检测有可能会使用深度图像、医疗图像等其他类型的图像。导致图像空间不匹配。
为解决以上问题,DSOD 提出从零开始训练检测模型。
DSOD 网络由 backbone sub-network 和 front-end sub-network 构成,Backbone 的作用在于提取特征信息,Front-end 网络是检测模块,通过对多层信息的融合用于物体检测。
基础网络 Backbone sub-network 部分,是一个 DenseNets 的变种, 由一个 stem block, 四个 dense blocks, 两个 transition layers , 两个 transition w/o pooling layers 构成, 用来提取特征。如下图所示:

图 28
Stem block 中作者没有使用 DenseNet 的 7*7 卷积,而是使用了两个 3*3 的卷积(这点和 Inception-V3 的改进很像)。作者指出这种设计可以减少从原始图像的信息损失,对检测任务更有利。其他的模块和 Densenet 很类似。作者使用了详细的实验证明了基础网络的设计部分的规则,如 Densenet 的过渡层 transition layer 通道数不减少、Bottleneck 结构的通道更多、使用 stem block 而非 7*7 卷积对最终的识别率都是有提升的。
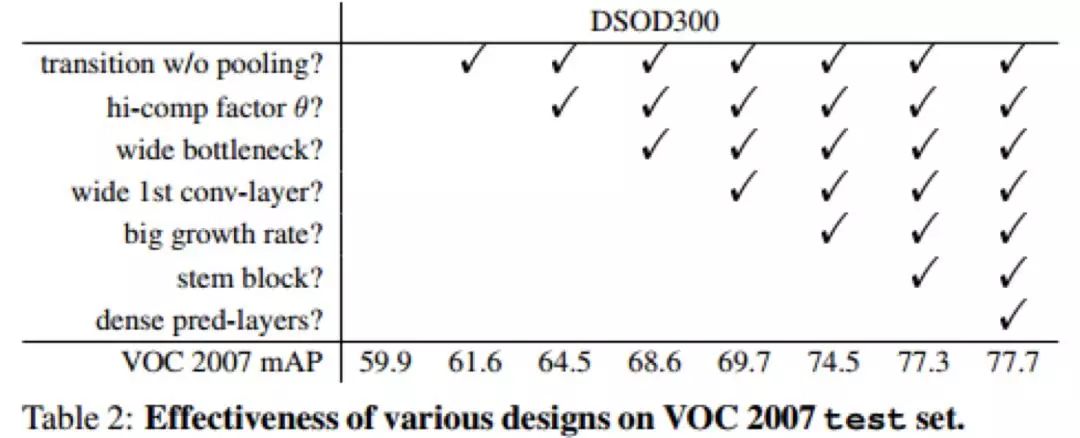
图 29
经过基础特征提取后,检测的网络 Front-end sub-network 有两种实现方式:Plain Connection 和 Dense Connection。其中 Plain Connection 就是 SSD 的特征融合方法。注意虚框中的是 Bottlenet 结构,即使用 1*1 的卷积先降维然后再接 3*3 的卷积。
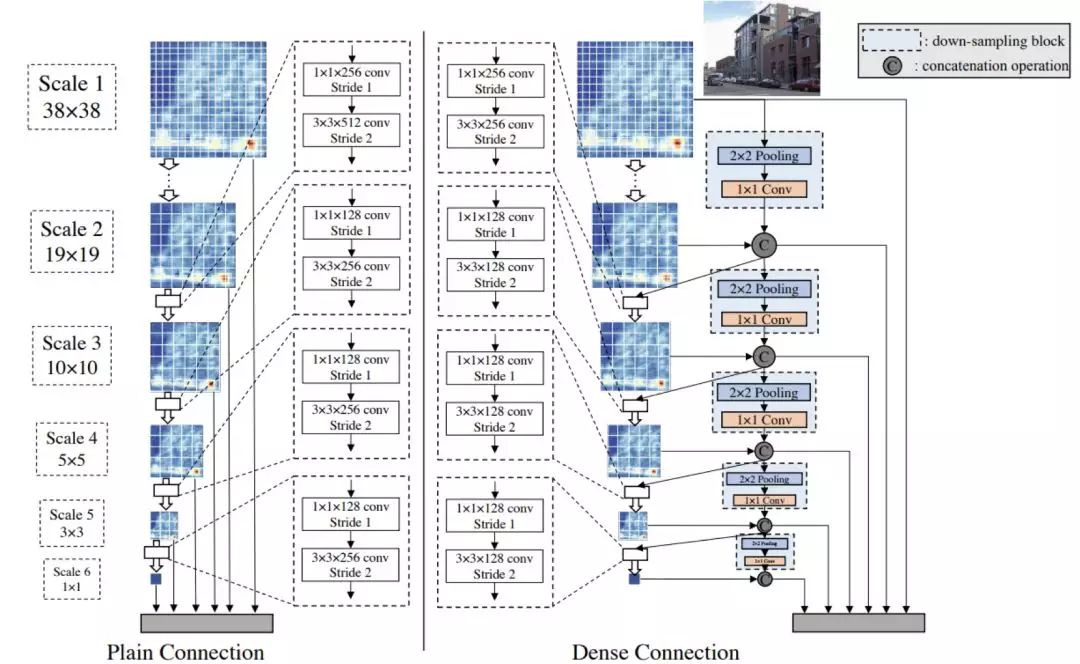
图 30
笔者认为 Dense Connection 结构就是 DSOD 的主要创新点,这部分也很巧妙的采用了 densenet 的思想,一半的 Feature map 由前一个 scale 学到,剩下的一半是直接 down-sampling 的高层特征。

图 31
以第一个链接结构为例,该结构的输入一半为上一层的降采样的 Feature Map,其中通道的改变由 1*1 的卷积完成。另一半为这个尺度学习到的 feature。经过 Concat 后的输出是三个部分:1. 经过 1*1 卷积和 3*3 卷积作为下一层的输入;2. 直接降采样并修改通道作为下一层的输入;3. 输入这一层的 feature 到最后的检测任务。
DSOD 的检测速度 (17.4fps) 比 SSD、YOLO2 略差,但在模型准确率和模型大小方面却更胜一筹,最小的网络只有 5.9M,同时 mAP 也能达 73.6%。作者在实验部分还使用了 pre-trained model 初始化 DSOD,结果反而没有从零开始训练效果好, 未来可能去探究一下。
END
整理不易,点赞三连↓