
基于深度学习的图像增强综述
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者丨木瓜子@知乎(已授权)
导读
本文介绍了近年来比较经典的图像增强模型,并分析其优缺点。
这篇博客主要介绍之前看过的一些图像增强的论文,针对普通的图像,比如手机拍摄的那种,比低光照图像增强任务更简单。
介绍
图像增强的定义非常广泛,一般来说,图像增强是有目的地强调图像的整体或局部特性,例如改善图像的颜色、亮度和对比度等,将原来不清晰的图像变得清晰或强调某些感兴趣的特征,扩大图像中不同物体特征之间的差别,抑制不感兴趣的特征,提高图像的视觉效果。传统的图像增强已经被研究了很长时间,现有的方法可大致分为三类,空域方法是直接对像素值进行处理,如直方图均衡,伽马变换;频域方法是在某种变换域内操作,如小波变换;混合域方法是结合空域和频域的一些方法。传统的方法一般比较简单且速度比较快,但是没有考虑到图像中的上下文信息等,所以取得效果不是很好。
近年来,卷积神经网络在很多低层次的计算机视觉任务中取得了巨大突破,包括图像超分辨、去模糊、去雾、去噪、图像增强等。对比于传统方法,基于CNN的一些方法极大地改善了图像增强的质量。现有的方法大多是有监督的学习,对于一张原始图像和一张目标图像,学习它们之间的映射关系,来得到增强后的图像。但是这样的数据集比较少,很多都是人为调整的,因此需要自监督或弱监督的方法来解决这一问题。本文介绍了近年来比较经典的图像增强模型,并分析其优缺点。
DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks
这是ICCV2017年的一篇文章,Ignatov等人自己构建了一个大的数据集(DPED),包含6K多张照片,使用三部手机和一部单反在多种户外条件下同时拍摄得到。然后作者针对这三个成对的数据集,提出了一种新的图像增强算法。通过学习手机拍摄的照片和单反照片之间的映射关系来将手机拍摄的照片提升到单反水平,这是一个端到端的训练,不需要额外的监督和人为添加特征。其网络结构采用的是GAN模型,如下:
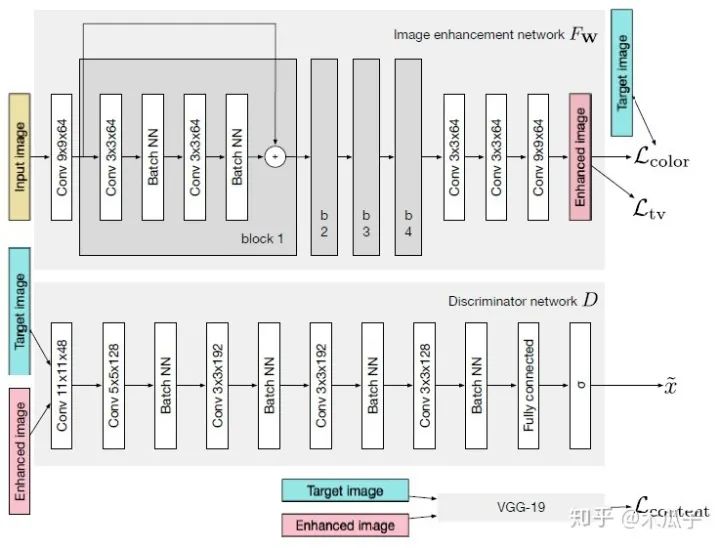
如图所示,GAN主要由两个网络组成,一个生成网络G和一个判别网络D,整个网络是一个对抗的过程,G不断生成能欺骗D的数据,D不断提高自己辨别真假的能力,直到达到一个均衡状态。这里的输入图像是手机拍摄的照片,目标图像是单反拍摄的照片,它们是一一对映的关系。生成器CNN结构,首先输入一张图像,经过一个卷积层预处理后,使用了4个残差块,再经过3个卷积层得到增强后的图像;判别器CNN用于判断增强后的图像和目标图像的真假,生成器生成的图像要尽可能地欺骗判别器,这样就表明生成的图像与目标图像越接近,也就是增强后的图像效果越好。
图像增强的主要难点之一是输入图像与输出图像不能密集匹配(pixel-to-pixel),因此标准的均方误差不太适用,本文的另一个贡献是提出了复合的损失函数,包含内容、纹理和色彩三部分。
色彩损失用于衡量增强后图像与目标图像的色彩差异,对图像先做高斯模糊再计算它们的欧式距离,这样的好处是可以消除纹理和内容的影响来评估两图像间的亮度、对比度和主要颜色差异,可以写成如下形式:
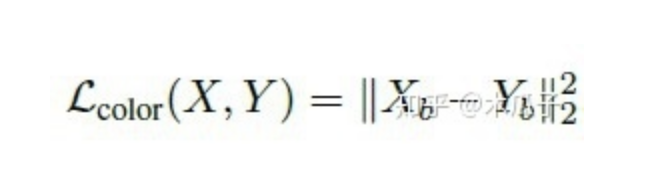
其中,Xb, Yb分别是为X,Y经过模糊的图像,如下:
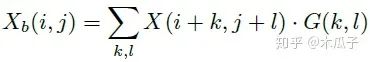
二维高斯模糊算子可以写成如下形式,其中A=0.053, μ=0, σ=3,
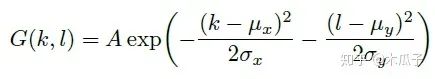
使用生成对抗网络(GANs)来衡量纹理质量,因此纹理损失定义为:
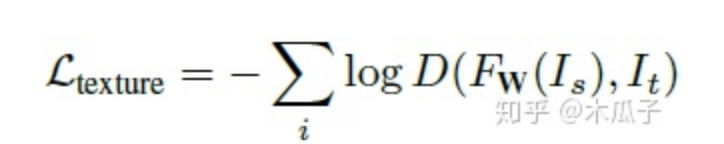
FW ,D分别表示生成和判别网络。
计算预训练好的VGG19网络ReLU层后激活的feature map的欧式距离作为内容损失,可以保留语义信息,定义为:
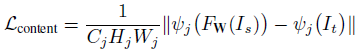
此外,还使用全变分(TV)来增强生成图像的空间平滑性,由于它占的权重比较小,不会影响图像的高频部分,且可以抑制一定程度的椒盐噪声,定义为:
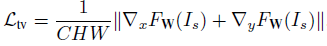
总的损失函数为:

最终要优化的目标函数如下,W为网络要学习的参数,L为总的损失函数,
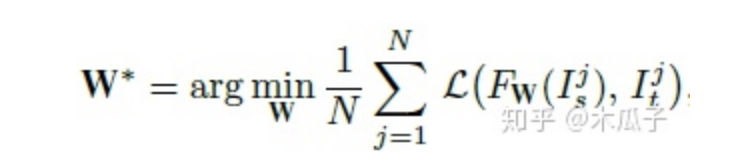
最后的结果如下:


这篇文章提出了一个照片增强的算法,将手机照片提升到单反水平,使用的数据集DPED均为自然图像,有实际的应用价值。但也存在一些问题,有一些复原后的图像存在色彩偏差或者对比度过高,显得不太自然。此外,文中使用GAN在复原高频信息时不可避免地会放大噪声。最大的缺点是它对每种不同手机的数据集都要重新训练,是一个强监督的过程,通用性不强,后续的工作也对这一算法进行了改进,提出了一种弱监督的方法。
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
这是CVPR Workshops2018上的一篇文章,是基于上一篇论文的改进,同一个作者写的。上一篇论文中最大的局限性是它对每一个数据集都要重新训练一个模型,不具有通用性,因此这篇文章中,作者提出一个新的弱监督的网络模型WESPE,输入数据和输出数据分别为低质量图像和高质量的图像,但它们在内容上不需要对应,使用一个传递性的CNN-GAN结构来学习它们之间的映射关系,其网络结构如下:
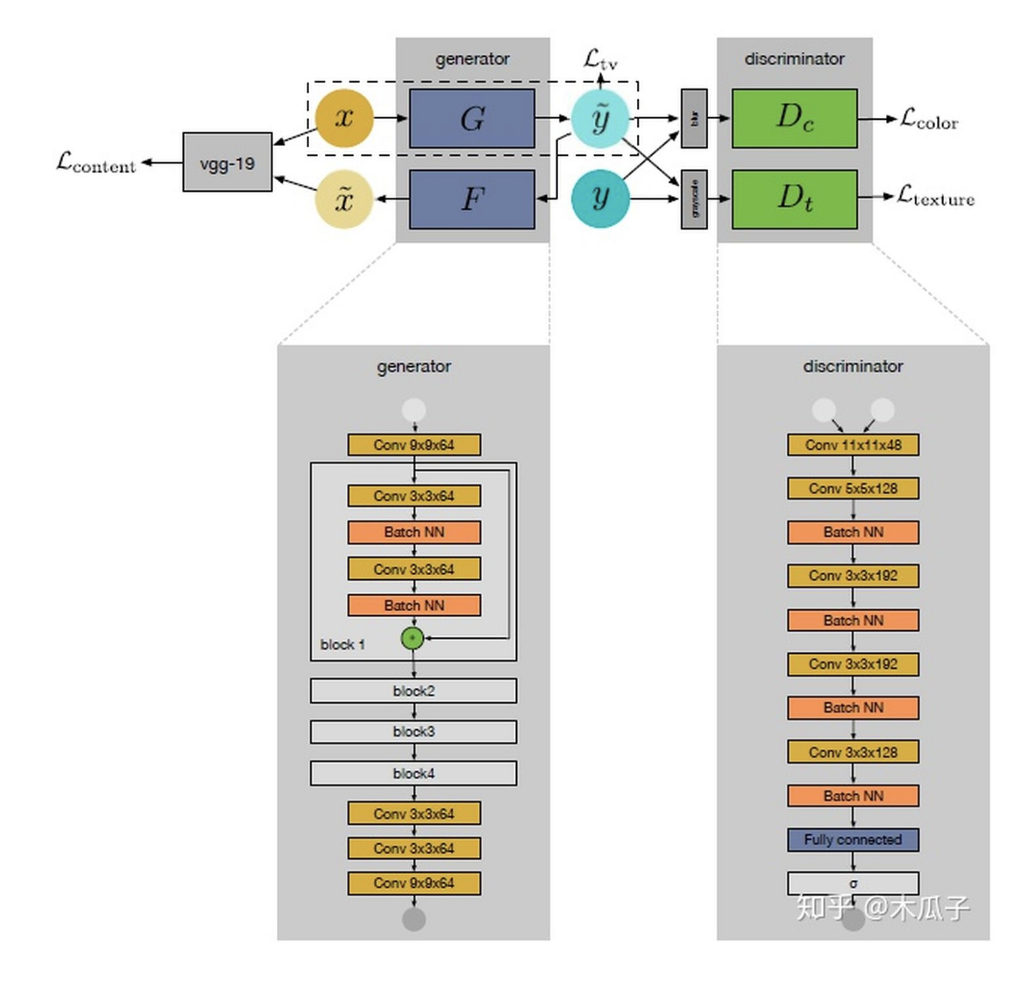
我们的目标是要学习源图像X到目标图像Y映射关系,如图所示,这个网络包含一个生成器映射 一个逆生成映射 , 这里的G可以看成图像增强器,可视为退化器,为了保证x与 widetildex 内容的一致性,使用VGG19计算内容损失,这样就可以避免成对的需要内容完全一致的数据集。右侧的两个判别器Dc, Dt分别用于判别增强后图像与目标图像在颜色和纹理上的差异,最后计算TV损失来得到较平滑的图像。
内容一致性损失,计算原图x与 idetildex 在VGG19上某一高
维feature map的L2范数,计算公式如下:

判别器颜色损失,计算增强后的图像与目标图像高斯模糊后的差异,如下:

判别器纹理损失,比较增强后图像与目标图像在灰度状态下的损失,定义为:
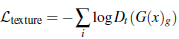
TV损失,为了使生成后的图像比较平滑,定义为:
总的损失为:
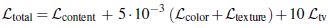
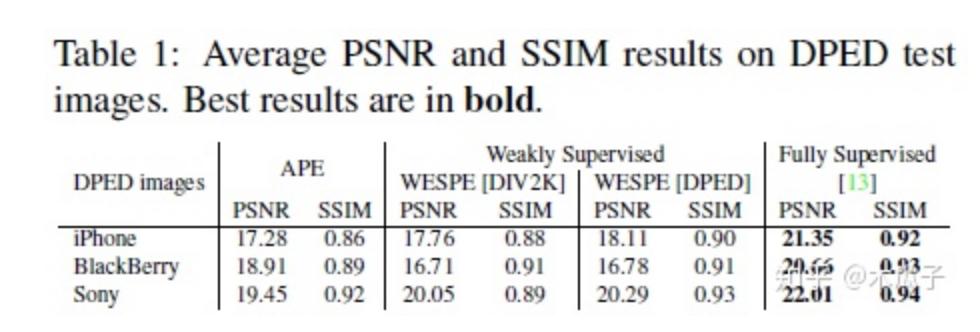
实验结果如下:

本文提出的算法WESPE是一种弱监督的方式,因此它可以适用于任何户外的数据集,不需要成对的增强图像来训练,还用到的数据集有以下几种:
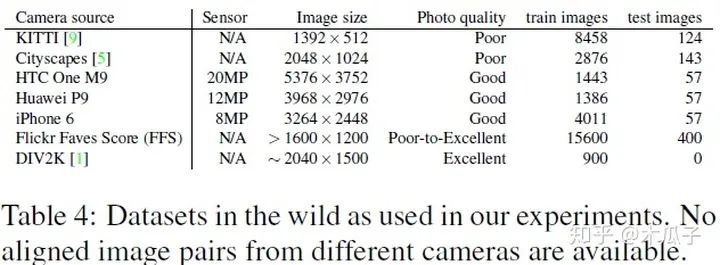
总的来说,这篇文章最大的贡献是提出了这种弱监督的方式来增强低质量的图像,虽然它的PSNR和SSIM结果跟强监督的相比还存在一定的差距,但它的创新点还是很有借鉴意义的。
Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs
这是CVPR2018的一篇文章,作者首次提出了用GANs实现无监督的照片增强,但这里的无监督并不是完全不需要数据对,同上一篇论文一样,是指用到的数据集并不是在内容上一致的。本文中使用的two-way GAN与CycleGAN的结构相似,在MIT-Adobe 5K数据集上取得了较好的结果,超过了第一篇论文的方法。首先看一下two-way GAN与1-way GAN结构的差别:
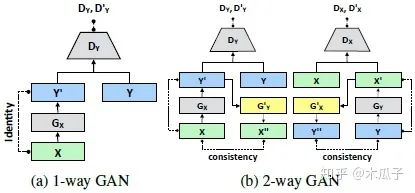
图中(a)为标准的GAN, X代表源域, Y表示目标域,给定输入x,经过生成器Gx得到增强后的图像y', 判别器Dy用于区分增强后的图像y'和目标图像y。为了得到更好的结果,加强循环一致性,就提出了这种two-way GAN, 通常包含一个前向映射 和一个后向映射 。前向映射中, 先经过生成器Gx得到增强后的图像y', 得到y'后再经过一个生成器G'y映射到源域x', , 检查x与x”的一致性; 判别器区分y与y'。在反向过程中, y先经过生 成器Gy得到退化的图像x', '再经过一个生成器G'x得到增强后的图y', 检查y与y'的一致性; 判别器区分x与x'。
GAN中的生成器Gx也就是最后的照片增强器,在U-Net的基础上加入全局特征,作者认为全局特征包含一些高维特征,如场景类别、目标类别、整体的光照条件等,有利于单个像素的局部调整。完整的网络结构如下:

文中作者对比了多种GAN方法,WGAN-GP效果最好,但它的表现依赖于梯度惩罚项的参数,因此作者提出了一种自适应的方法AWGAN(Adaptive WGAN),通过实验证明了将AWGAN扩展到2-way GAN中比1-way GAN效果更好。为了使生成器能适应不同的数据分布,使用独立的batch normalization层,也就是说除了批归一化层,其余所有的生成器共享相同的层和参数。
目标函数包含三部分损失,第一部分为恒等映射,保证输入图像x与增强后的图y内容相似,但因为是2-way GAN存在配对的映射y到x’,定义为I:
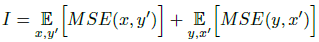
第二部分为循环一致性损失C,定义为:
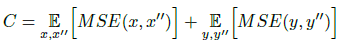
第三部分是生成对抗损失,判别器AD,生成器AG,定义为:

训练判别器时,加上梯度惩罚项P,
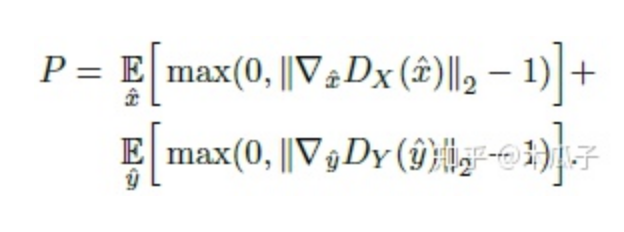
这一项满足了Wasserstein distance的1-Lipschitz约束。
最终要优化的为:
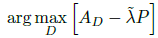
其中λ ̃为使用AWGAN得到的自适应权重参数。
生成器损失优化下式得到:
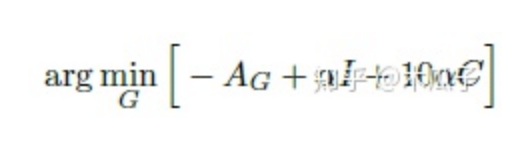
本文中采用的数据集为MIT Adobe 5K,作者将它划分为三部分,第一部分为2250张图像及其对应的修饰后图像用于有监督的训练;第二部分是第一部分中2250张图像及另外的修饰后的图像,这样就保证了输入图像与输出图像内容上是不同的,用于无监督训练;第三部分500张图像用来测试。
最后的实验结果如下:
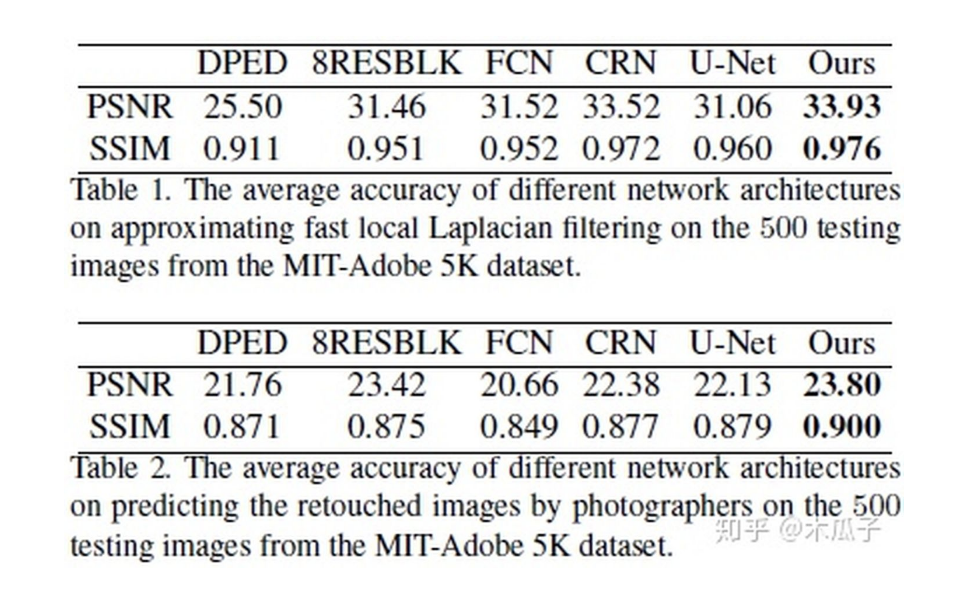

除了比较PSNR/SSIM,文中还采用了问卷调查的形式,其中HDR模型取得了最好的结果,从上面的图也可以看出它的效果比较好,色彩比较鲜艳,但该模型存在一定的局限性,一些用于训练的HDR图像是色调映射得到的,会产生光晕效应;若输入图像比较暗或包含噪声,本文的模型会放大噪声。此外,该模型还可以有一些其他应用,如图像分割、卧室图像合成等,取得了不错的效果。总的来说,这篇论文给我们提供了一种“无监督”做图像增强的方法,并且使用U-Net加入全局特征,自适应权重的WGAN和独立的BN层来学习具有用户期望特征的图像。
Classification-Driven Dynamic Image Enhancement
这是CVPR2018的一篇文章,基于分类的动态图像增强,这个论文首次将图像增强任务与分类结合起来,不同于现有的图像增强方法去评判增强后图像的感知质量,而是用分类结果的准确性来衡量图像增强的质量,在没有很好的评价指标的情况下,作者Vivek Sharma等人提出了这样的模型,让我们从high-level的角度来对图像进行增强,是一种创新和突破。
本文的主要贡献是联合优化一个CNN用于增强和分类,我们通过动态卷积自适应地增强图像中的特征来实现这一目标,使得CNN结构能够选择性地增强那些有助于提高图像分类的特征。网络的整体结构如下:
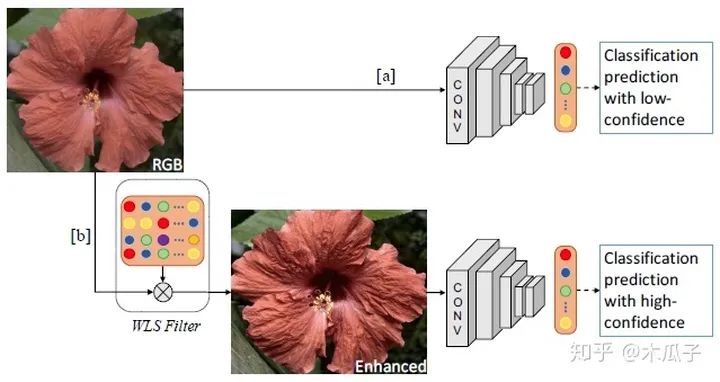
给定一张输入图像,不是直接用CNN进行分类,而是先用WLS滤波器对图像细节进行增强,再对其进行分类,这样可以提高分类的可信度。本文的目标是学习一种动态图像增强网络来提高分类准确度,但不是近似特定的增强方法。为此,文中给出了三种CNN结构。
动态增强滤波器:
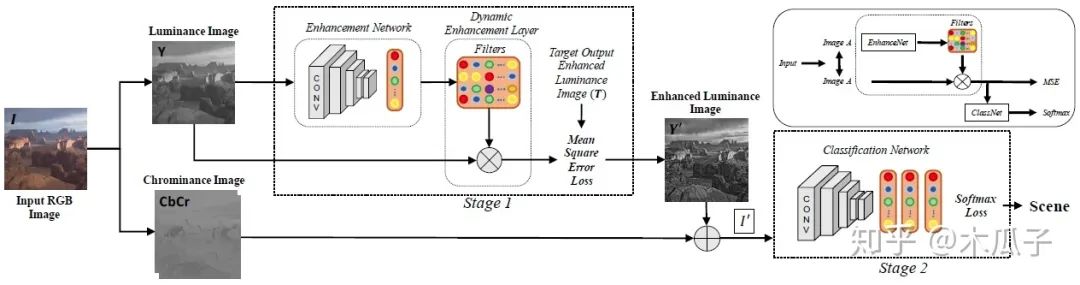
由图可知,对于一张输入的RGB图像I,先把它转化成亮度-色度(luminance-sschrominance)Y CbCr 彩色空间,增强算法用于RGB图像的亮度通道,可以使得过滤器修改整体色调属性和图像锐度,而不影响颜色。再加上色度通道的图像可以得到增强后的图像I’,之后增强后的图像输入分类网络中进行分类。其中的目标图像作者采用了5种经典的方法对其进行增强,分别为:(1) weighted least squares (WLS) filter, (2) bilateral filter (BF), (3) image sharpening filter (Imsharp), (4) guided filter (GF) ,(5)histogram equalization (HistEq),均使用其默认参数。但在该模型中,每个数据集一次只使用其中一种增强方法,且对每一张输入图像,都动态得产生特定的滤波器参数。这里的卷积网络用了AlexNet,GoogleNet, VGG-VD, VGG-16和BN-Inception这五个模型进行测试,其中BN-Inception在分类中表现最好,因此在后续实验中作为默认结构。分类网络中的全连接层和分类层的参数均使用预训练好的网络微调得到。
该网络的loss有两部分组成,用于增强的MSE loss和用于分类的softmax loss,用SGD优化器联合优化这两部分损失,总的损失函数如下:
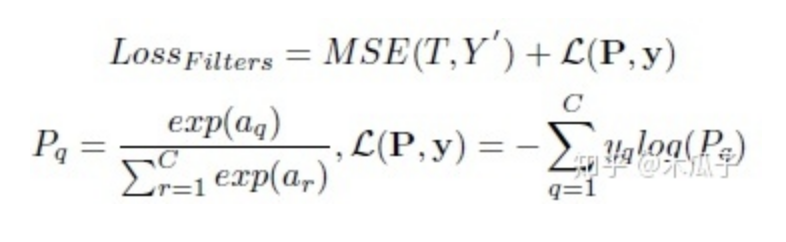
其中,MSE loss计算的是增强后的亮度图像与用传统方法增强后的目标图像的均方误差。a为分类网络中最后一个全连接层的输出,y为图像I的真实标签,C为分类数量。联合优化使得损失梯度可以从ClassNet中反向传播至EnhanceNet,来优化滤波器的参数。
静态滤波器:
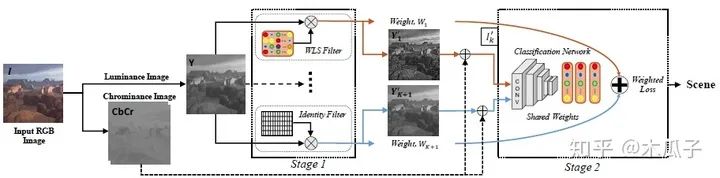
在该结构中,静态滤波器由第一种结构中所有的动态滤波器的平均得到,每个滤波器的权重相等,均为1/K=0.2(K=5);同时,由于增强后的图像可能比原始图像效果还差,因此这边使用一个恒等滤波器来产生一张原始图像,再将它们与色度图像相加得到增强后的RGB图像以及它们的权重,这个权重表明增强方法对输入图像的重要性。在分类网络中,输入为5种方法增强后的图像和原始图像及其对应权重和标签,输出为图像类别。和第一种方法一样,分类网络中的全连接层和分类层的参数均使用预训练好的网络微调得到。
这里的损失为权值与softmax损失的加权和,带权重的loss可写成如下形式:
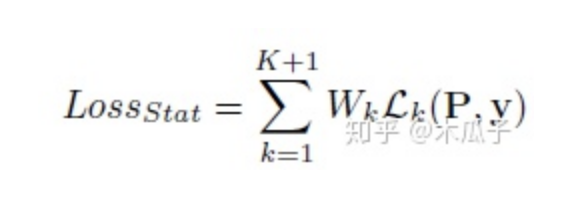
其中,K=5,前K个权重相等,均为0.2,第K+1个原始RGB图像的权重设为1.
多动态滤波器:
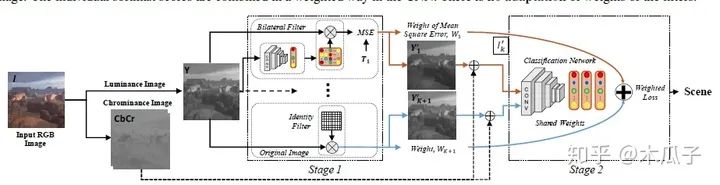
这个网络结构与第一种结构比较相似,针对每种增强方法使用K个增强网络动态地产生K个滤波器,不同于第二种方法中取相同的权重,这里的权值根据均方误差来决定,增强后的图像误差越小,则权重越大,其计算公式如下:

同样,这边也加入恒等滤波器得到原始图像,且权值为1。其损失函数在第二种结构的基础上加入MSE来联合优化这K个增强网络,公式如下:
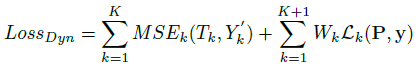
通过这种方式来训练网络可以使这些滤波器更好地增强图像的结构,以便于提高图像的准确率。
实验结果如下:

总的来说,本文提出了一种CNN结构能效仿一系列的增强滤波器,通过端到端的学习来提高图像分类,由于一般的图像增强方法没有评判标准,所以将图像增强与分类任务结合起来,以提高图像分类正确率作为图像增强的标准,更具有实际意义。但这种方法存在一些问题,文中使用五种传统的增强方法来得到目标图像,所以增强网络学习到的结果最好也是接近这几种方法的结果,且文中没有具体研究这些增强后的图像,所以不知道它的效果到底如何,只能说明有助于图像的分类。
Range Scaling Global U-Net for Perceptual Image Enhancement on Mobile Devices
这是ECCV-PIRM2018(Perceptual Image Enhancement on Smartphones Challenge)挑战赛中,图像增强任务第一名的论文,主要用于处理手机等小型移动设备上的图像增强。现有的图像增强方法在亮度、颜色、对比度、细节、噪声抑制等方面对低质量图像进行了改进,但由于移动设备处理速度慢、内存消耗大,很少能解决感知图像增强的问题,已有的一些方法也很难直接迁移到手机上使用。移动设备上的感知图像增强,尤其是智能手机,最近引起了越来越多的工业界和学术圈兴趣,因此本文提出了一个尺度缩放的全局U-Net网络(Range Scaling Global U-Net,RSGUNet)用于移动设备上的图像增强。
这篇文章的网络结构如下:
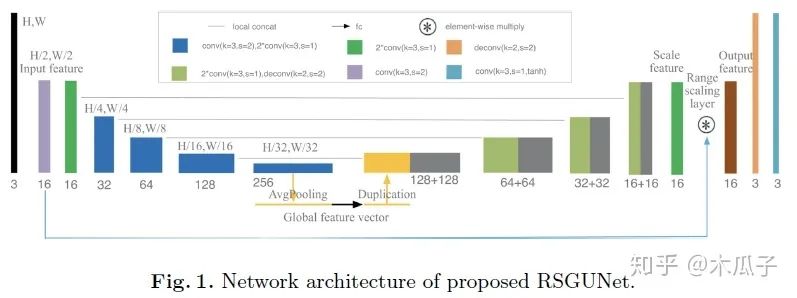
主体框架是U-Net,可以利用不同分辨率下图像的feature map。在此基础上本文做出了两点改进,一是引入全局特征来减少视觉伪影,二是使用range scaling layer代替residuals,也就是逐个元素相乘,而不是相加。作者通过实验发现这两点创新可以缓解增强后图像的视觉伪影。这里的全局特征向量可以看成是一个正则化器,用于惩罚会导致视觉伪影的低分辨率特征,且使用avgpooling来提取全局特征比使用全连接层所需要的参数量更少。Range scaling layer可以实现像素强度的逐像素缩放,相比于传统的residual-learning残差学习网络,本文提出的RSGUNet网络能力更强,它能学习到更精细、更复杂的低质量图像到高质量图像的映射关系。
Loss函数的设计包括L1 loss, MS-SSIM loss, VGG loss, GAN loss and total variation loss。
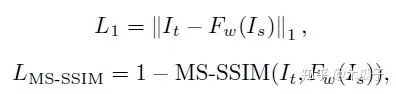
L1 loss可以获得色彩和亮度信息;MS-SSIM loss可以保留更多高频信息,有实验证明,这两个loss组合比L2 loss的效果要好。

VGG loss保证了增强后图像和目标图像特征表现的相似性,它是在预训练好的VGG计算多个层之间feature map欧式距离的均值得到的。
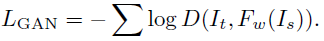
GAN loss可以近似两幅图像之间的感知距离,因此最小化GAN loss可以使得生成的图像更加真实。

TV loss可以有效抑制高频噪声。
总的loss为这些loss的加权和:

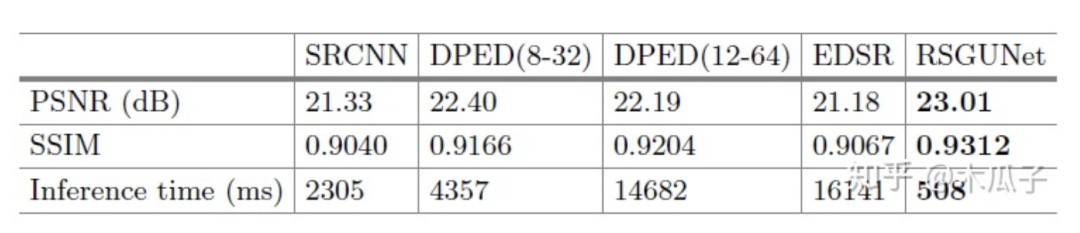
实验中用到的数据集是DPED中iPhone和Canon这个数据对,训练集为160000个100*100的patch,验证集为43000个patch,测试的时候用的是400张原图,作者对比了一些方法,结果如下:
可视化结果如下:

PRIM2018图像增强挑战赛的结果如下:

这篇论文也存在一些问题,它在大多数图像上表现较好,但少数增强后的图像比较黑或者模糊,原因可能是U-Net的下采样操作,但实验结果中没有发现伪影。总的来说,本文提出的结构在主观上和客观上都取得了较好的效果,且计算复杂度大大降低,适用于移动设备上的图像增强。这篇文章也给我们提供了一个新的研究方向,探索新的、轻量级的网络结构来实现实时的图像增强任务。
Fast Perceptual Image Enhancement
这篇文章跟上一篇一样,也是ECCV-PRIM2018年挑战赛的,在图像增强任务上获得第二名,它是在这边介绍的第一篇论文的模型作为baseline,在它的基础上改进了生成器模型,判别器模型和loss函数的设计都跟baseline一样,但其速度大大提升,因此可以适用于移动设备上。
来看一下baseline和这篇论文的生成器模型:
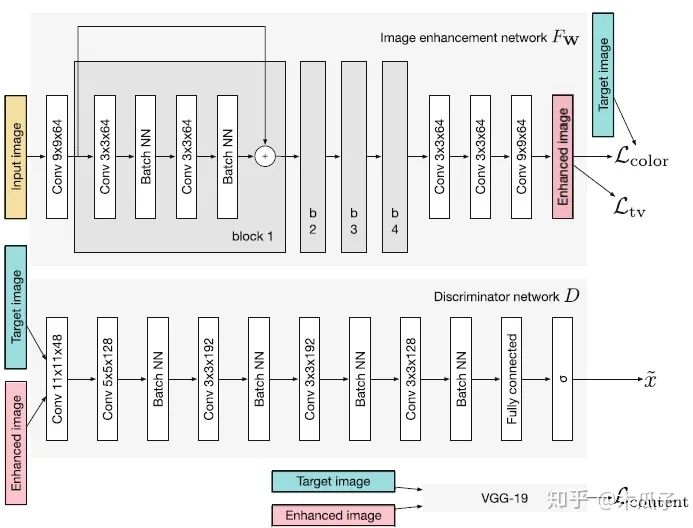

通过对比可以发现,block的数量从4变成了2,第一层和最后几层的通道数都大大减少,降低模型的复杂度。此外,为了进一步减少计算时间,还做了一个改进就是空间分辨率的减少,多出来的4*4*32和4*4*64其实是一个下采样(strided convolutional layers),每次卷积后feature map的大小就减半,在两个residual block后的两个卷积层相当于是两个上采样层(transposed convolution layers),将特征恢复到原始分辨率。在每个分辨率下,通过skip connection将相同分辨率的feature map学习一个残差,便于网络学习。作者对比了不同的卷积核大小、通道数及block数对模型性能与速度的影响,结果如下:
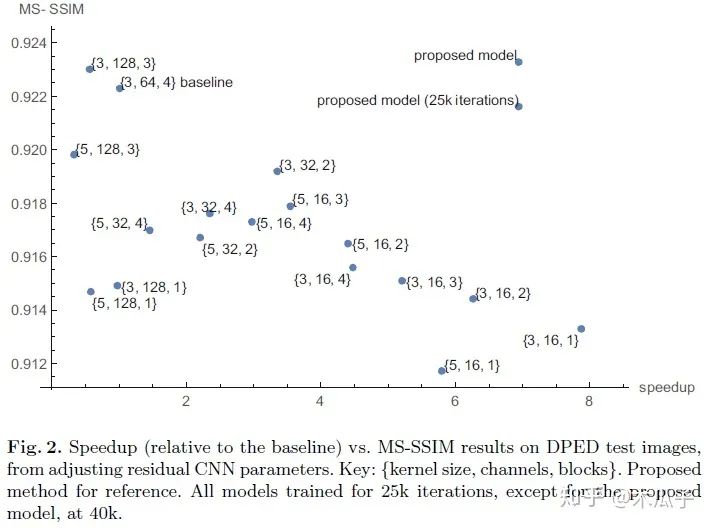
可以看到,本文提出的模型在不影响性能的情况下,实现了baseline近6.3倍的加速。虽然该模型由于上采样过程会引入轻微的棋盘伪影,但它是一个不损失图像质量的更快的模型,本文采用的数据集也是DPED,测试结果如下:
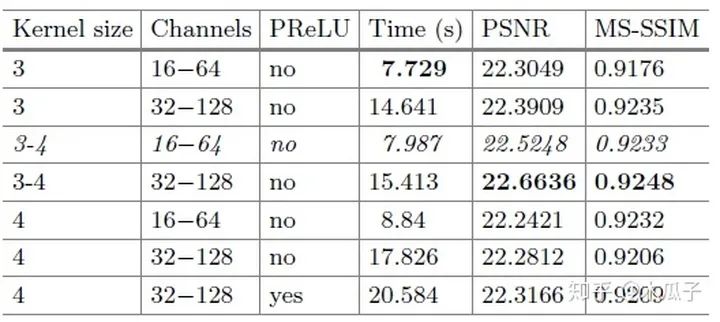
作者对不通道卷积核大小、通道数以及激活函数进行了实验,最终权衡了效果和速度,选择了第三行的参数作为网络结构。
可视化结果如下:

与baseline相比,本文的方法生成的图像在某些方面更加精细,在边缘处没有色彩伪影,且减少噪声,纹理更清晰。从整体上来说,这篇文章的创新的不是很大,在baseline基础上网络结构的没有特别大的改动,但它的计算速度明显提升,这就表明了基于卷积神经网络的图像增强已经可以产生适用于移动设备的高质量的结果。
Deep Networks for Image-to-Image Translation with Mux and Demux Layers
这篇论文是ECCV-PRIM2018年挑战赛图像增强任务的第三名,虽然结果没有之前两篇的好,但创新点比较大。第一,这篇论文提出了一种shuffle pixel的上采样和下采样层,分别称为Mux and Demux layers,可以直接在CNN中使用,和标准的池化操作相比,这种方式可以保持输入信息不丢失;第二,提出了一种的CNN结构,将Mux,Demux,DenseNet结合起来,在低分辨率下处理feature map,效率比较高;第三,本文在DPED方法基础上引入了一个加权的L1 loss和上下文损失,(contextual loss),为了验证,使用NIQE index来提高图像的感知质量。
先来看一下Demux和Mux layer,结构如下:
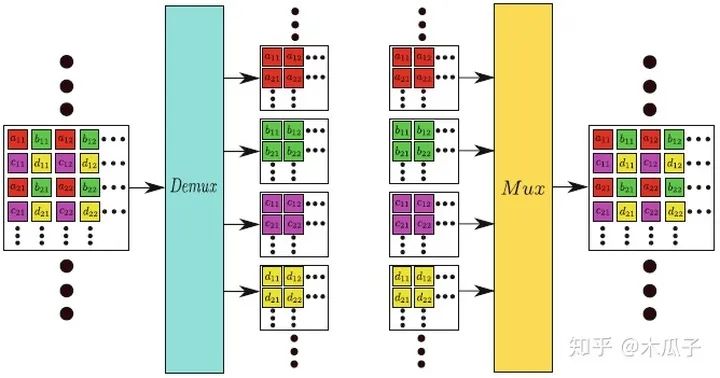
Mux layer类似于pixel shuffling layer,能直接处理feature map产生一个新的feature map,可以直接在卷积神经网络中当成一个上采样层。Mux先把输入分为几个小组,每组四个feature map,按上述规则重新排列,输出的feature map长宽分别为输入的两倍,数量为输入的1/4。Demux可以看成网络中的下采样操作,是Mux的逆过程,其feature map数量是输入的4倍,长宽分别为输入的1/2。标准的下采样操作如max pooling, average pooling, strided convolutional 是不可逆的,但本文中提出的这种方式没有改变任何像素值,即没有丢失输入信息,这是提高深度学习模型性能的关键之一。
本文的网络结构包含一个生成器和一个判别器,判别器和DPED中的结构一样,生成器有两种不同的结构,如下:
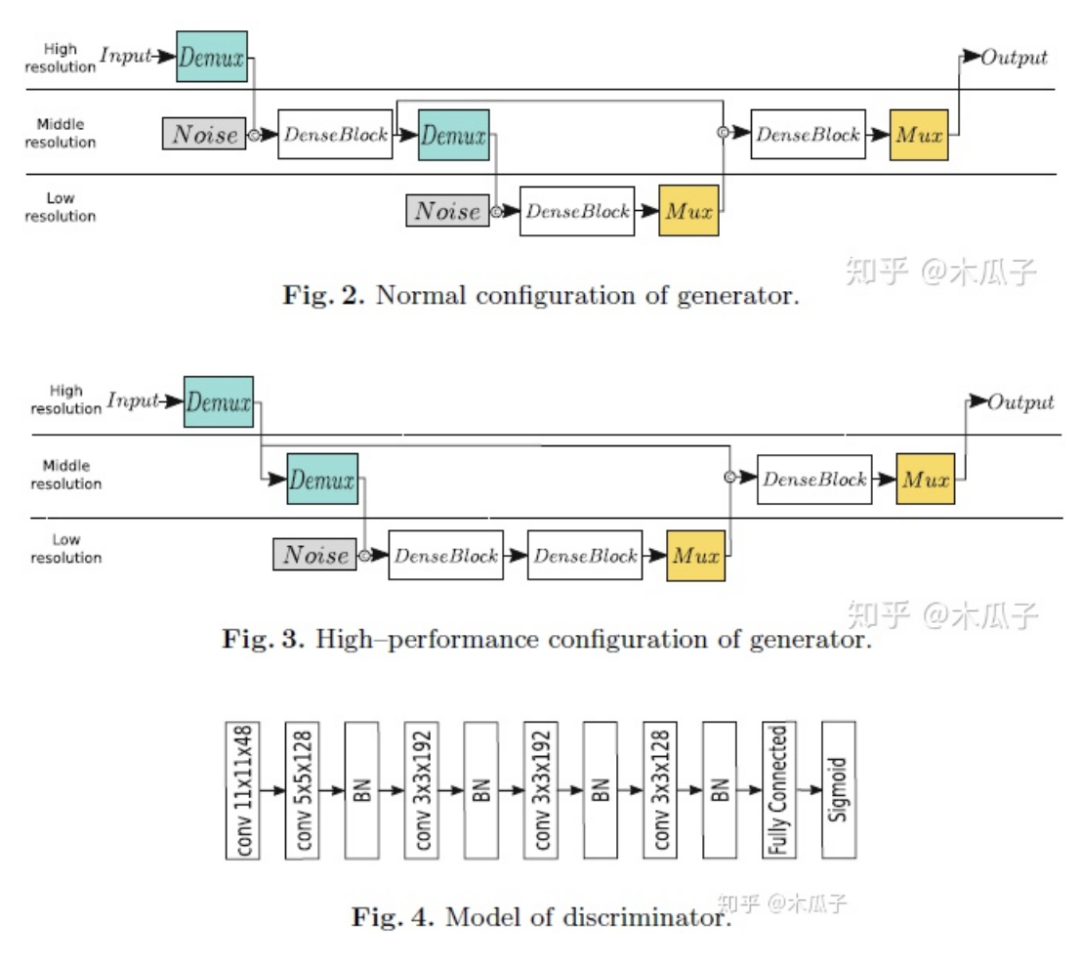
从图2中可以看出,生成器处理三种分辨率,输入一张RGB图像先经过下采样,为了生成高频细节和高感知质量的图像,每次下采样后引入噪声通道,然后输入到DenseBlock进行处理,再经过一次相同的操作,之后两次上采样得到输出的RGB图像,在每个卷积层后使用instance normalization来调整feature map的全局参数。图3中,直接对输入图像做两次下采样操作,得到的feature map比较小,可以减少计算复杂性且提高模型性能。图4判别器网络包含五个卷积层,每个接着一个LeakyReLU和BN,第1,2,5个卷积层的步长分别为4,2,2。
Loss函数在DPED的基础上引入了一个加权的L1 loss,如下:
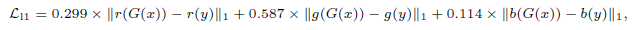
分别计算R,G,B三个通道的L1损失,参数使用的是YUV色彩空间转换的系数。
还有和一个上下文损失(Contextual Loss),如下:
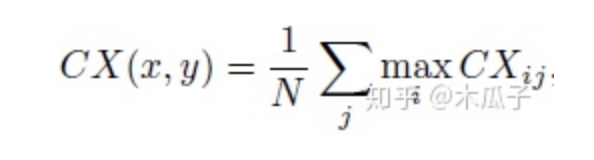
其中CXij表示两个特征之间的相似性,定义为:
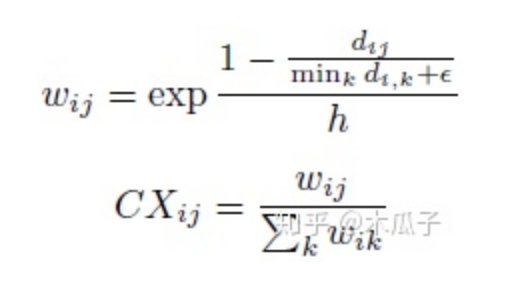
Dij表示xi, yi之间的余弦距离,eps=0.00001, h>0为带宽系数,最终的上下文损失为:

DPED中的4个损失函数分别如下:
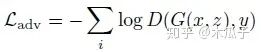
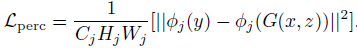

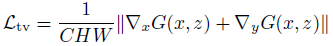
总的损失为:

系数分别为:5000,10,10,0.5,2000。
在DPED上的实验结果如下:
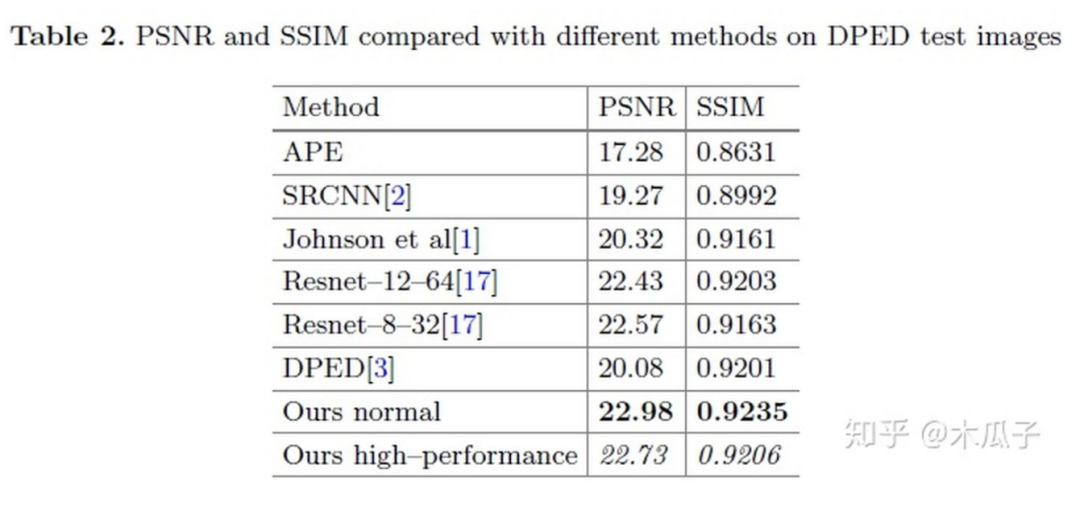
在衡量图像的PSNR和SSIM之外,本文还引入了一种新的评价机制NIQE。Natural Image Quality Evaluator(NIQE)是一种盲图像质量指数,它基于一组已知的统计特征,这些特征对自然图像遵循多元高斯分布。它可以在没有任何参考图像的情况下量化自然或真实图像的外观,提供类似于人类评估的感知质量指数。其值越小,则表示图像感知质量越好,可以看到本文的结果所得的NIQE最低。

可视化结果如下:

从图中可以看出,DPED的结果局部过亮,本文中的方法比其他方法更能平衡对比度和细节,得到高质量的感知图像。但也存在局限性,当输入图像过亮或者曝光过度的时候就很难成功转化为高质量图像,这可能是数据集的影响,DPED中只包含低亮度的图像,因此可以在训练中加入一些自适应和扩展的数据集。
总的来说,本文提出了新的上采样和下采样操作,引入了两个新的损失函数和NIQE这个评价机制,并在实验中加入噪声通道,可以有效提高图像感知质量,在低分辨率下处理图像,也使得模型复杂度大大降低,适用于手机等移动设备。
本文亮点总结
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!