
用隐马尔科夫模型来预测股价走势

一、初识HMM
隐马尔科夫模型(Hidden Markov Model,简称HMM)是用来描述隐含未知参数的统计模型,HMM已经被成功于语音识别、文本分类、生物信息科学、故障诊断和寿命预测等领域。
HMM可以由三个要素组成: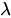 =(A,B,II),其中A为状态转移概率矩阵,B为观测状态概率矩阵,II为隐藏状态初始概率分布。
=(A,B,II),其中A为状态转移概率矩阵,B为观测状态概率矩阵,II为隐藏状态初始概率分布。
HMM有两个基本假设,一是齐次马尔可夫性假设,隐马尔可夫链t的状态只和t-1状态有关;二是观测独立性假设,观测只和当前时刻状态有关。
HMM解决的三个问题:
一是概率计算问题,已知模型和观测序列,计算观测序列出现的概率,该问题求解的方法为向前向后法;
二是学习问题,已知观测序列,估计模型的参数,该问题求解的方法为鲍姆-韦尔奇算法
三是预测问题(解码问题),已知模型和观测序列,求解状态序列,该问题求解的方法为动态规划的维特比算法。
HMM的实现:python的hmmlearn类,按照观测状态是连续状态还是离散状态,可以分为两类。GaussianHMM和GMMHMM是连续观测状态的HMM模型;MultinomialHMM是离散观测状态的模型。
二、实例分析
(1)问题描述:股票预测问题,观测值为股票的涨幅值(当天收盘价-前一天收盘价)和成交量2种,隐藏状态假定为平、跌和涨3种,根据股票的历史数据构建HMM,并进一步预测股票的收盘价。
(2)数据预处理:从原始数据中提取有用的列,并做异常值处理操作,得到模型的数据数据,原始数据为某支股票2013-2019的记录数据,如下图所示。

import datetime
import numpy as np
import pandas as pd
from matplotlib import cm, pyplot as plt
from hmmlearn.hmm import GaussianHMM
#数据处理
df = pd.read_excel("601668.SH.xlsx", header=0)
print("原始数据的大小:", df.shape)
print("原始数据的列名", df.columns)
df['日期'] = pd.to_datetime(df['日期'])
df.reset_index(inplace=True, drop=False)
df.drop(['index','交易日期','开盘价','最高价','最低价' ,'市值', '换手率', 'pe', 'pb'], axis=1, inplace=True)
df['日期'] = df['日期'].apply(datetime.datetime.toordinal)
print(df.head())
dates = df['日期'][1:]
close_v = df['收盘价']
volume = df['成交量'][1:]
diff = np.diff(close_v)
#获得输入数据
X = np.column_stack([diff, volume])
print("输入数据的大小:", X.shape) #(1504, 2)
(3)异常值的处理:
min = X.mean(axis=0)[0] - 8*X.std(axis=0)[0] #最小值
max = X.mean(axis=0)[0] + 8*X.std(axis=0)[0] #最大值
X = pd.DataFrame(X)
#异常值设为均值
for i in range(len(X)): #dataframe的遍历
if (X.loc[i, 0]< min) | (X.loc[i, 0] > max):
X.loc[i, 0] = X.mean(axis=0)[0]
(4)模型的构建:
#数据集的划分
X_Test = X.iloc[:-30]
X_Pre = X.iloc[-30:]
print("训练集的大小:", X_Test.shape) #(1474, 2)
print("测试集的大小:", X_Pre.shape) #(30, 2)
#模型的搭建
model = GaussianHMM(n_components=3, covariance_type='diag', n_iter=1000)
model.fit(X_Test)
print("隐藏状态的个数", model.n_components) #
print("均值矩阵")
print(model.means_)
print("协方差矩阵")
print(model.covars_)
print("状态转移矩阵--A")
print(model.transmat_)
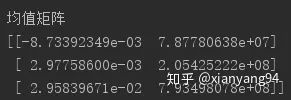
均值矩阵:共三行,每一行代表一种隐藏层状态(状态0、1、2),每一行的两个元素分别代表涨幅值的均值和成交量的均值。由于该股票的变化不是特别大,因此结果不是特别明显,但可以观察到状态0均值为负值,可以解释为“跌”;状态1均值最小,接近0,可以解释为“平”,状态2均值为正,可以解释为“涨”。

协方差矩阵:共三个协方差矩阵,分别对应三种隐藏层状态。对角线的值为该状态下的方差,方差越大,代表该状态的预测不可信。状态0的方差约为0.00255,方差最小,预测非常可信;状态1的方差约为0.0157,可信度居中;状态2的方差为0.1232,方差最大,最不可信。
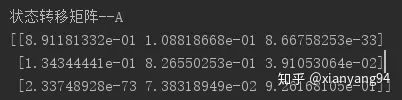
状态转移矩阵:代表三个隐藏层状态的转移概率。可以看出对角线的数值较大,即状态0、1、2都倾向保持当前的状态,意味该股票较稳。
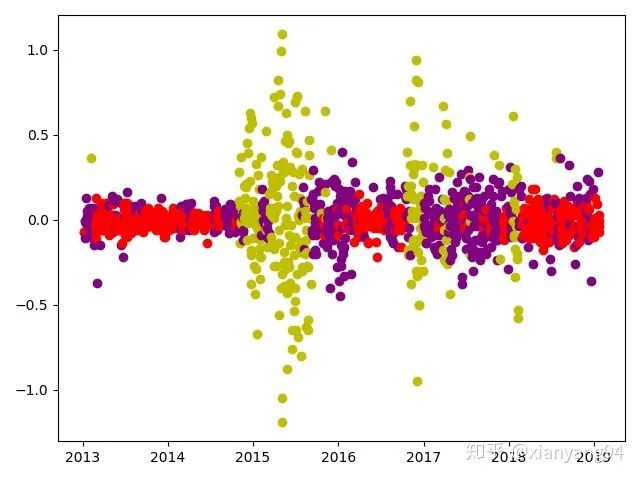
(5)隐藏状态划分结果:
#训练数据的隐藏状态划分
X_pic = np.column_stack([dates[:-30], hidden_states, X_Test])
for i in range(len(X_pic)):
if X_pic[i, 1] == 0:
plt.plot_date(x=X_pic[i, 0],y=X_pic[i,2],color='r')
elif X_pic[i, 1] == 1:
plt.plot_date(x=X_pic[i, 0],y=X_pic[i,2],color='purple')
else:plt.plot_date(x=X_pic[i, 0],y=X_pic[i,2],color ='y')
plt.show()
(6)预测值计算:
将预测数据的第一组作为初始数据,预测下一时段的股票涨幅值,以此类推预测该股票后三十组的价格。
expected_returns_volumes = np.dot(model.transmat_, model.means_)
expected_returns = expected_returns_volumes[:,0]
predicted_price = [] #预测值
current_price = close_v.iloc[-30]
for i in range(len(X_Pre)):
hidden_states = model.predict(X_Pre.iloc[i].values.reshape(1,2)) #将预测的第一组作为初始值
predicted_price.append(current_price+expected_returns[hidden_states])
current_price = predicted_price[i]
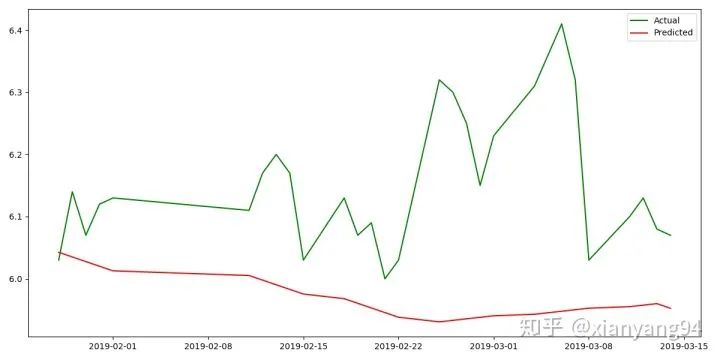
(7)预测结果展示:
x = dates[-29: ]
y_act = close_v[-29:]
y_pre = pd.Series(predicted_price[:-1])
plt.figure(figsize=(8,6))
plt.plot_date(x, y_act,linestyle="-",marker="None",color='g')
plt.plot_date(x, y_pre,linestyle="-",marker="None",color='r')
plt.legend(['Actual', 'Predicted'])
plt.show()
三、小结
可以看出,该预测结果的趋势与真实值一致,但预测结果不佳。可以通过增加训练的数据量,并进行模型参数调优来提高预测的精度。HMM应用场景:研究问题是基于序列的,比如时间序列或状态序列;存在两种状态的意义,一种是观测序列,一种是隐藏状态序列。相比于RNN、LSTM等神经网络序列模型,HMM进行预测的效果可能较劣,总之股市有风险,投资需谨慎。
参考资料:hmmlearn官方文档
https://hmmlearn.readthedocs.io/en/latest/
本文由作者:xianyang94,zhihu.com/p/166552799 投稿
长按扫码添加Python小助手进入
Python 中 文 社 区 俱 乐 部 微 信 群
▼点击成为社区会员 喜欢就点个在看吧