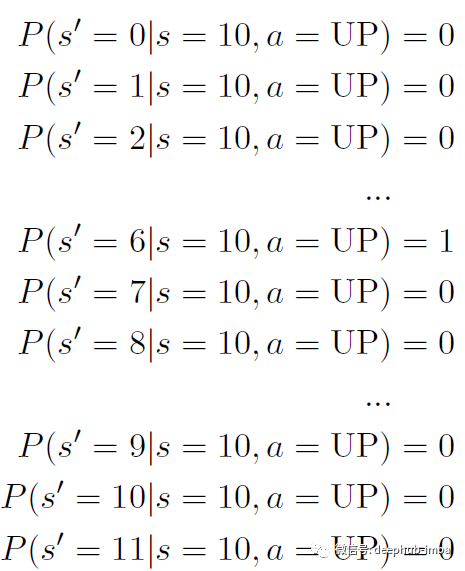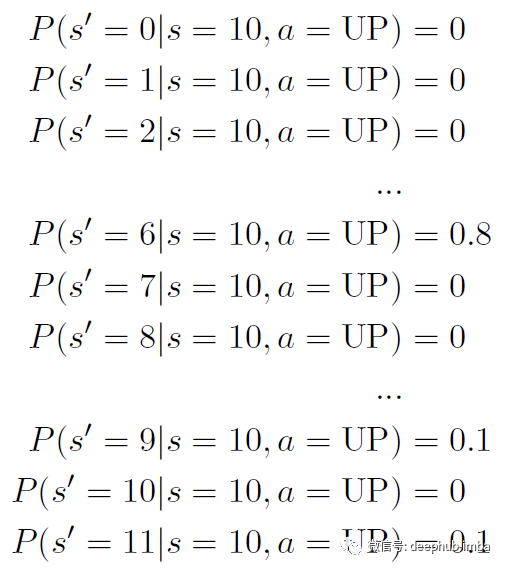马尔可夫决策过程(Markov decision process, MDP)是人工智能中的一个重要概念,也是强化学习的理论基础之一。在今天的文章中,我们使用来自Stuart Russell和Peter Norvig的《Artificial Intelligence: A Modern Approach》一书中的网格例子来介绍MDP的基本概念。
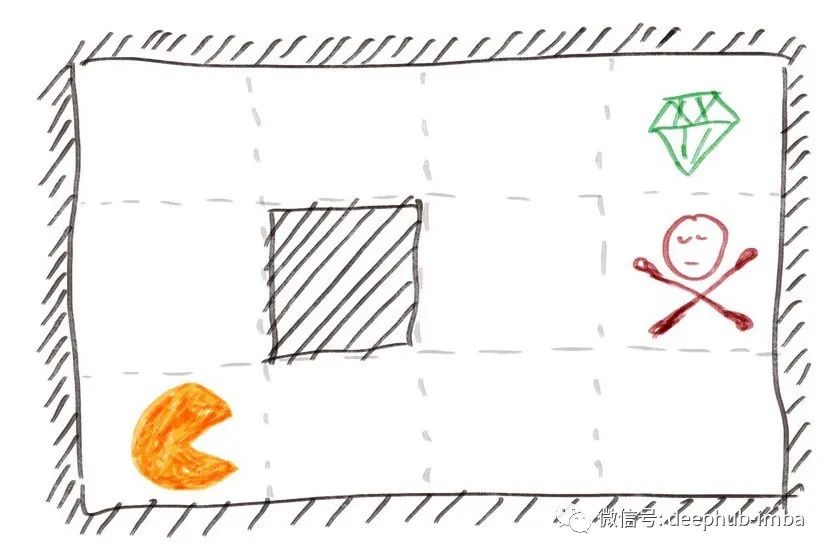
我们的吃豆人游戏
这里我们有一个 4×3 的网格世界,有一个机器人从左下角开始并在这个 2D 世界中移动来玩游戏。
世界示例
我们的机器人可以向四个方向移动:上、下、左、右,与吃豆人的相似之处是我们的世界被不可通行的墙包围。黑色方块代表的边界内也有不可通过的墙。右上角正方形中的绿色菱形代表终点线。如果我们到达这个方格,我们就会赢得这场比赛并获得很多积分(在本例中为 +1)。在吃豆人中,总有鬼魂试图伤害你。在我们的游戏中,我们有一个带有红色毒药的方块。如果我们进入这个方格,我们就会输掉比赛并受到很多惩罚(在这个例子中是 -1)。所有其他白色方块都是正常的方块。每次我们进入其中一个时,我们都会失去少量点数(在本例中为 -0.04)。如果我们随机移动,希望最终幸运地到达绿色菱形,那么我们每走一步就会损失 0.04 分,从而损失很多分。这就相当于机器人的电力系统,每走一步需要消耗一定的电量,所以机器人每走一步就要减去点积分,以保证最低的消耗。为简单起见,我们假设我们的机器人总是从左下角开始,如上图所示。综上所述,在玩这个游戏的时候,我们希望尽可能快地获得+1点,而一路上付出最少的-0.04,并且我们绝对要避免在红毒中以-1结束游戏。MDP的定义
在《Artificial Intelligence: A Modern Approach》中,MDP 被定义为具有马尔可夫转移模型和附加奖励的完全可观察的随机环境的顺序决策问题称为马尔可夫决策过程或 MDP,由一组状态(具有初始状态 s₀)组成;每个状态下的一组动作;一个转换模型 P(s'| s, a);和奖励函数 R(s)。
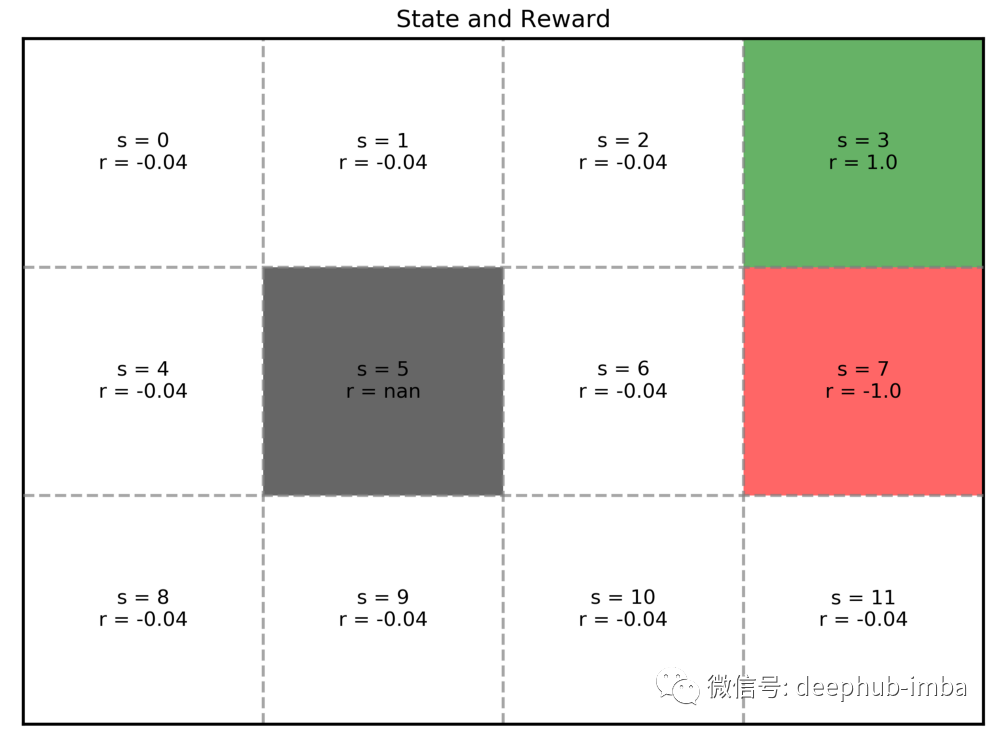
代理(又叫智能体)是指机器人或吃豆人或我们放置在这个世界中的任何东西,它会环顾四周寻找可能的移动,考虑可能移动的利弊,做出下一步移动的决定,并执行移动。环境是指世界的样子和世界的规则。在我们的例子中,环境包括我们的世界有多大,墙在哪里,如果我们撞到墙会发生什么,钻石在哪里,如果我们到达那里,我们得到多少分,毒药在哪里,如果我们到达还有我们输了多少分,等等。MDP 中的状态是指我们代理的状态,而不是我们环境的状态。在 MDP 中,环境是给定的并且不会改变。相比之下,我们的代理可以将状态从先前的移动更改为当前的移动。在这个示例中代理有 12 个状态,代表我们的代理可能处于的 12 个方格。从技术上讲,我们的代理不能处于黑色方格中,但为简单起见,我们仍将黑色方格视为一个状态。在 MDP 中,我们使用 s 来表示状态,在我们的示例中,我们称它们为 s = 0, 1, 2, ..., 11。
动作是指我们的代理在每个状态下可以采取的动作。每个状态的一组可能的操作不一定相同。在我们的示例中,对于每个状态 s,我们有四个可能的动作 A(s) = {up, down, left, and right}。我们使用 a 来表示动作。奖励是指我们进入一个状态时获得的积分。在我们的示例中,对于不同的状态,它是 +1、-1 或 -0.04。奖励仅依赖于状态,这个从状态到奖励的函数表示为 R(s)。无论我们之前的状态如何,我们在进入某个状态时都会获得相同的奖励。例如,当 s = 3 时,r = R(s) = R(3)= +1。无论我们从左边的方格向右移动到它,还是从它下面的方格向上移动到它,我们都会得到相同的 +1 奖励。
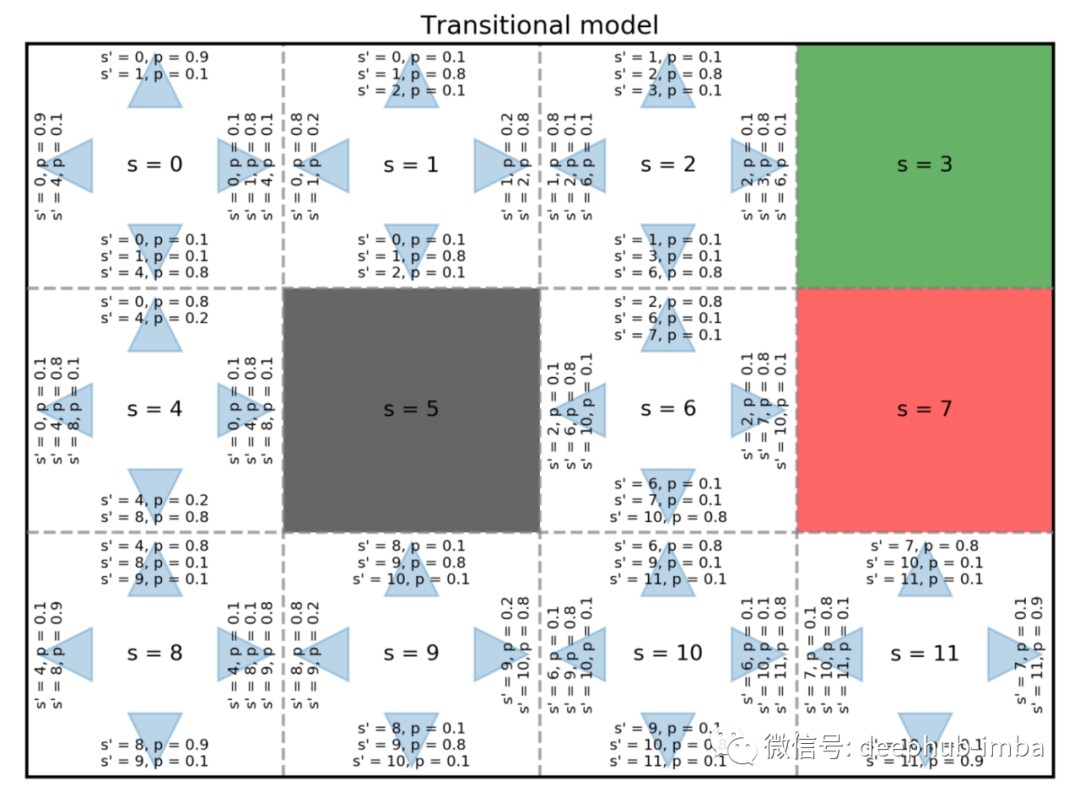
累加奖励意味着来自不同动作的奖励是累积的。在我们的示例中,我们的最终积分(总奖励)是从钻石或毒药获得的积分与沿途可通过的方块获得的积分相加。不仅是最后一格获得的奖励,一路上获得的所有小奖励也很重要。在 MDP 中,我们假设我们可以将这些奖励加在一起。转换模型告诉我们,如果我们在某个状态下选择某个动作,我们将进入下一个状态。这通常表示为表 P。如果我们处于状态 s 并且我们选择一个动作 a,那么 s' 成为下一个状态的概率是 P(s'| s, a)。如果我们假设我们的世界是确定性的,那么我们预期的移动方向总是会实现。例如,如果我们在 s = 10 并且我们选择 a = UP,我们肯定会进入一个新的状态 s' = 6。作为概率分布,所有 12 个 s' 的 P(s'| s = 10, a = UP) 之和总是等于 1。
随机意味着我们的世界不是我们上面假设的确定性的。从某个状态开始,如果我们选择相同的动作,我们不能保证进入相同的下一个状态。在我们的这个游戏中,可以将其视为我们的机器人以某种方式出现故障的可能性。例如,如果它决定向左走,那么实际上向左走的可能性很大。然而,它有一个很小的可能性,无论它有多小,它都会疯狂地向左以外的方向移动。按照书中的例子,实际朝预期方向移动的概率是 0.8。向预定方向左移 90 度的概率为 0.1,向预定方向向右移动 90 度的概率为 0.1。例如,如果我们在 s = 10 并且我们选择 a = UP,我们有 0.8 的概率进入预期的新状态 s' = 6。我们也有 0.1 的概率到达 s' = 9 并且到达 s' = 11 的概率为 0.1。这是当 s = 10 且 a = UP 时的转换模型。现在对于每对状态 s 和动作 a,我们可以像这样写出到达每个新状态的概率。将所有这些组合在一起,我们得到了转换模型 P。我们有 12 种可能的状态和 4 种可能的动作。因此,我们的过渡模型 P 的维度为 12×4×12,共有 576 个概率值。
完全可观察意味着我们的代理是知道世界的全部样子以及它自己目前在那个世界中的位置。从某种意义上说,我们可以说我们的代理有上帝视角。它可以访问在每次移动中找到最佳决策所需的所有知识。这里的知识指的是我们的奖励函数 R(s) 和过渡模型 P(s'| s, a)。顺序意味着我们当前的情况受先前决定的影响。出于同样的原因,所有未来的情况都会受到我们当前决定的影响。例如,如果我们从 s = 8 开始并决定向上移动作为我们的第一步,那么我们到达 s = 4。我们无法在下一步移动中到达 s = 10。如果我们选择向右移动作为我们从 s = 8 开始的第一步,那么我们到达 s = 9。现在我们可以通过向右移动到达 s = 10。换句话说,我们能否在第二步中达到 s = 10 取决于我们在第一步中的选择。马尔可夫意味着我们的世界是没有记忆的。这似乎与我们对顺序的定义相反,但实际上它们具有完全不同的含义。顺序意味着我们能否在第二步中达到 s = 10 取决于我们在第一步中所做的选择。这意味着无论我们如何到达状态 s = 10,无论我们是从 s = 9 或 s = 11 或 s = 6 到达它,一旦我们处于该状态,我们总是面临相同的情况,具有相同可能的行动的集合 。如果我们做出决定,将会发生什么并不取决于过去发生了什么。换句话说,这只是意味着无论你在游戏中做了什么,P(s'| s, a) 在整个游戏过程中都不会改变。当我们第 100 次达到 s = 10 时,我们将面临与第一次达到相同的动作选择。如果我们在这个状态下选择某个动作,结果总是遵循相同的概率分布。如果某个动作是我们第一次到达该状态时状态 s = 10 的最优动作,那么该动作始终是该状态的最优动作。网格世界的代码实现
我们使用 csv 文件来表示我们的世界地图,其中 0 为可通过的白色方块,1 为绿色方块,2 为红色方块,3 为黑色方块。对于我们的示例,csv 文件如下所示:我们使用以下代码来实现网格世界示例。每种类型方块的奖励由字典奖励表示。import numpy as npimport matplotlib.pyplot as pltimport matplotlib.patches as patches
class GridWorld: def __init__(self, filename, reward=None): if reward is None: reward = {0: -0.04, 1: 1.0, 2: -1.0, 3: np.NaN} file = open(filename) self.map = np.array( [list(map(float, s.strip().split(","))) for s in file.readlines()] ) self.num_rows = self.map.shape[0] self.num_cols = self.map.shape[1] self.num_states = self.num_rows * self.num_cols self.num_actions = 4 self.reward = reward self.reward_function = self.get_reward_table() self.transition_model = self.get_transition_model()
def get_state_from_pos(self, pos): return pos[0] * self.num_cols + pos[1]
def get_pos_from_state(self, state): return state // self.num_cols, state % self.num_cols
奖励函数
正如我们上面解释的,奖励函数R(s) 仅依赖于状态 s。我们使用以下代码为每个 s 生成奖励函数 R(s) 的结果。class GridWorld: def get_reward_function(self): reward_table = np.zeros(self.num_states) for r in range(self.num_rows): for c in range(self.num_cols): s = self.get_state_from_pos((r, c)) reward_table[s] = self.reward[self.map[r, c]] return reward_table
转换模型
让我们回顾一下我们的游戏规则。如果我们撞到一堵墙,我们会被弹回并留在原处。如果我们想向上或向下移动,实际上向上或向下移动的概率为 0.8,向左移动的概率为 0.1,向右移动的概率为 0.1。同样,如果我们想向左或向右移动,实际上向左或向右移动的概率为 0.8,向上的概率为 0.1,向下的概率为 0.1。class GridWorld: def get_transition_model(self, random_rate=0.2): transition_model = np.zeros((self.num_states, self.num_actions, self.num_states)) for r in range(self.num_rows): for c in range(self.num_cols): s = self.get_state_from_pos((r, c)) neighbor_s = np.zeros(self.num_actions) for a in range(self.num_actions): new_r, new_c = r, c if a == 0: new_r = max(r - 1, 0) elif a == 1: new_c = min(c + 1, self.num_cols - 1) elif a == 2: new_r = min(r + 1, self.num_rows - 1) elif a == 3: new_c = max(c - 1, 0) if self.map[new_r, new_c] == 3: new_r, new_c = r, c s_prime = self.get_state_from_pos((new_r, new_c)) neighbor_s[a] = s_prime for a in range(self.num_actions): transition_model[s, a, int(neighbor_s[a])] += 1 - random_rate transition_model[s, a, int(neighbor_s[(a + 1) % self.num_actions])] += random_rate / 2.0 transition_model[s, a, int(neighbor_s[(a - 1) % self.num_actions])] += random_rate / 2.0 return transition_model
让我们检查一下我们的模型是否有意义。例如,如果我们看 s = 8,当动作向下时,我们有 0.8 的概率向下然后撞墙并弹回 s' = 8,0.1 的概率向左走然后撞墙并返回 s' = 8,向右走并到达 s' = 9 的概率为 0.1。因此,s' = 8 对应于 p = 0.8 + 0.1 = 0.9,而 s' = 9 对应于 p = 0.1。
策略
策略是指在每个状态下要采取什么行动的指令。它通常表示为 π,它是 s 的函数。例如,如果 s = 2 且 π(s) = π(2) = RIGHT,那么每当代理处于状态 s = 2 时都会执行 RIGHT 的动作。它是否真的可以走到右边的方块是另一个故事,这取决于转换模型中的概率。关键是,不管结果如何,只要策略返回应该走到哪里,代理总是认为策略是正确的并且执行。我们查看策略的出发点是简单地生成一个随机策略并将其可视化。class GridWorld:def generate_random_policy(self): return np.random.randint(self.num_actions, size=self.num_states)
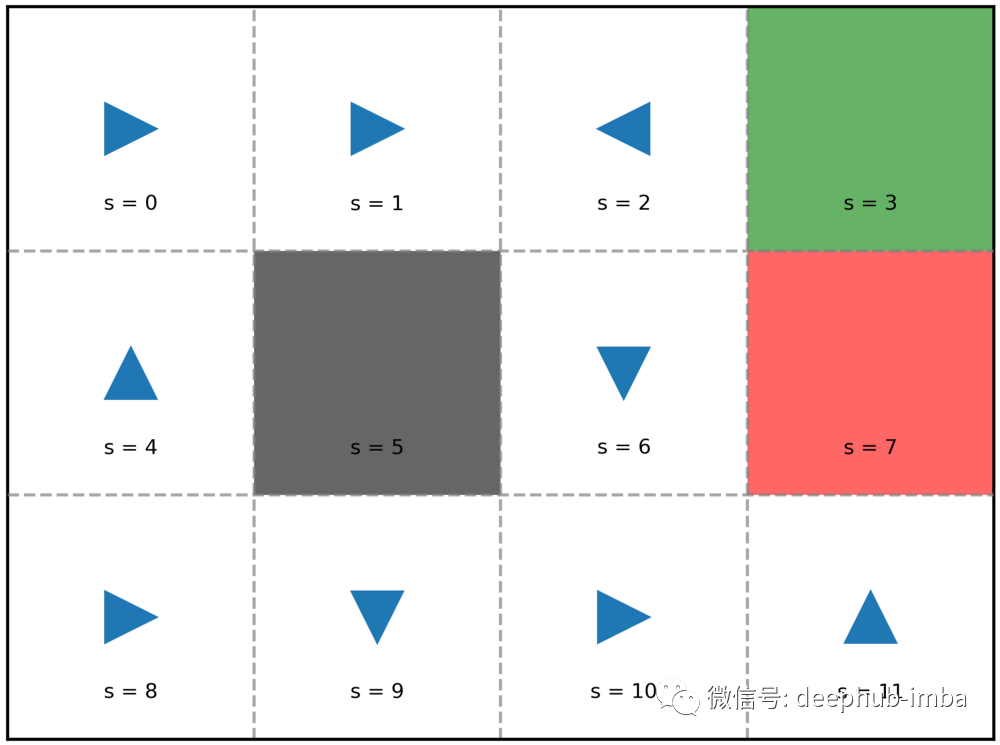
我们可以明确地写出这个策略:π(0) = RIGHT, π(1) = RIGHT, π(2) = LEFT, … π(11) = UP。
乍一看,这种随机生成的策略似乎不起作用。例如,我们从s = 8开始,政策要求向右进入了s = 9,然后政策说向下。然而,s = 9的底部是一堵墙。我们只是撞到那堵墙,然后反弹回s = 9。似乎我们在s = 9处卡住了。我们不会永远被困在 s = 9 的原因是我们处于一个随机的世界。即使策略告诉我们向下并且我们遵循该策略,我们最终在 s = 8 中的概率仍然为 0.1,而在 s = 10 中的概率为 0.1。策略的执行
现在我们至少有一个策略,尽管它可能看起来不是很好。让我们看看如果我们执行它会发生什么。class GridWorld:def execute_policy(self, policy, start_pos=(2, 0)): s = self.get_state_from_pos(start_pos) total_reward = 0 state_history = [s] while True: temp = self.transition_model[s, policy[s]] s_prime = np.random.choice(self.num_states, p=temp) state_history.append(s_prime) r = self.reward_function[s_prime] total_reward += r s = s_prime if r == 1 or r == -1: break return total_reward
如果我们当前处于状态 s,则我们的策略 a = π(s)。由于我们的世界是随机的,我们使用 numpy.random.choice 根据 P(s'| s, π(s)) 给出的概率分布来选择 s'。因为这个过程是随机的,不同的运行可能会有不同的结果。让我们尝试一下。这个特定运行的状态历史是 [8, 9, 9, 9, 9, 10, 10, 6, 10, 11, 7]。我们从 8 开始,以 0.8 的概率进入 9;然后我们尝试下降 3 次,然后弹回 9;然后以 0.1 的概率,我们移动到 10,然后是 11,最后不幸的是 7。沿着这条路径我们使用 10 移动。我们收到的总奖励是 -0.04 *10 加 -1 等于 -1.4 。
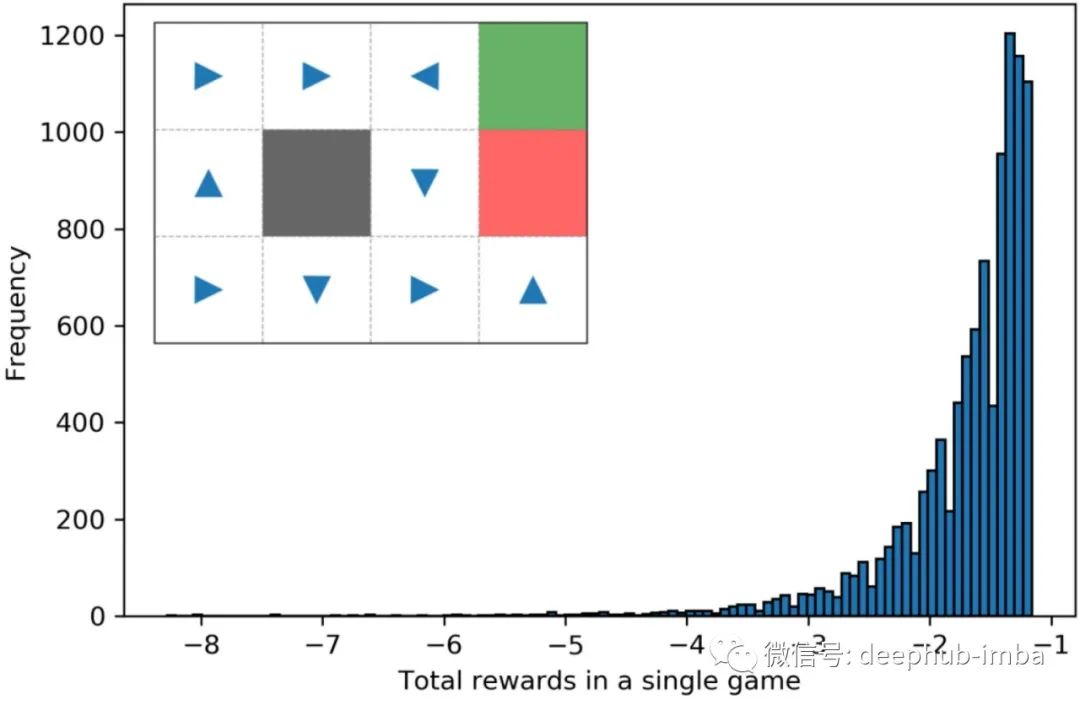
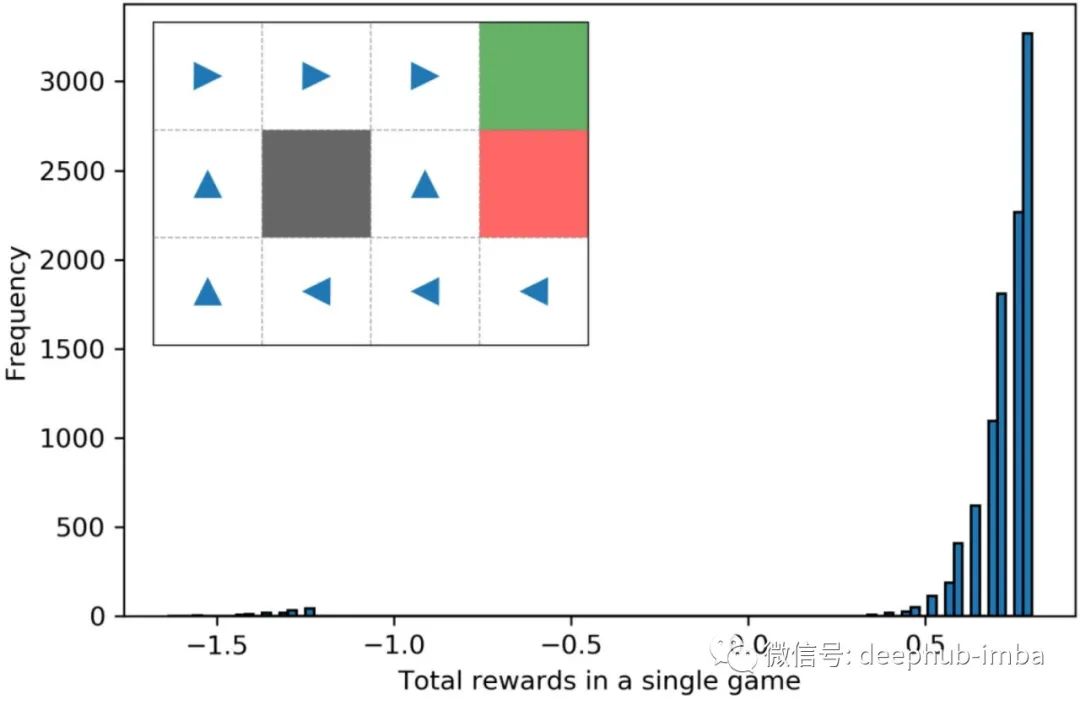
这只是一次运行,我们可能在这一次运行中不走运。让我们使用蒙特卡罗方法来评估该策略的好坏。对于这个例子,让我们重复执行 10,000 次并记录我们在每次运行中获得的总奖励。在这 10,000 次重复运行中,我们得到的最高总奖励为 -1.16,最低为 -8.5 左右。平均 -1.7。显然这不是很好。让我们看看一些其他策略。
更多策略
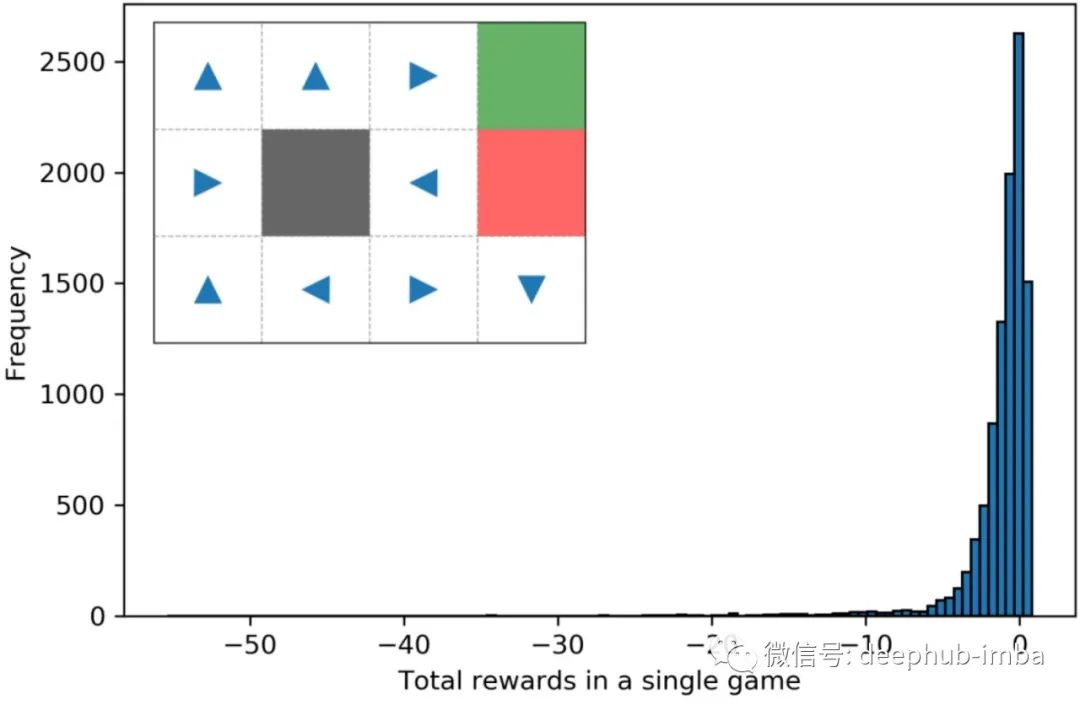
最高的是 0.8,这实际上是我们所能得到的。平均值为 -1.2,优于之前的随机策略 #1。但是最低的是 -55,这比随机策略 #1 的 -8.5 差得多。
这个好像还不错。最高为0.8,最低为-1.64,平均为0.7。总的来说,似乎比前两个好很多。
如何找到最优策略?
回顾我们的三个随机策略,我们可以说#3 似乎是最好的一个。还有另一个更好的吗?如果是这样,我们如何找到它?显然,我们有有限数量的可能策略。在我们的示例中,有 9 个状态需要指定的操作并且每个状态有 4 个可能的操作。,总共有 4⁹ 项政策。如果我们重复执行多次,这些策略中的每一个都有一定的预期总回报。因此,其中一个(或多个,如果有联系)将比其他人具有更高的预期总回报。因此,这种策略是最佳策略 π*。要找到最佳策略,一种天真的方法是尝试所有 4⁹ 策略并找到最佳策略。显然,这根本不实用。在实践中,我们有两种方法:策略迭代和值迭代。我们将在以后的文张中讨论这两种方法。敬请关注!https://github.com/clumsyhandyman/mad-from-scratch
编辑:于腾凯
校对:林亦霖