
独家 | 基于新闻标题的股价走势分析(附链接)

作者: Ronil Patil
翻译:王闯 (Chuck)
校对:詹好
标签:自然语言处理、情感分析、股价预测
“不要在草堆里找一根藏针,而是要买下整个草堆!”
数据集介绍
标签为1–股价上涨。
标签为0–股价持平或下跌。
开始
首先引入相关库
import pandas as pdfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import classification_report,confusion_matrix,accuracy_score
读取数据集
df = pd.read_csv('F:Stock-Sentiment-Analysis-master/Stock News Dataset.csv', encoding = "ISO-8859-1")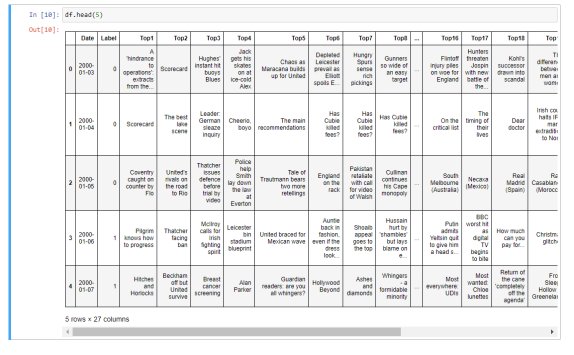
将数据集划分为训练集和测试集
train = df[df['Date'] < '20150101']test = df[df['Date'] > '20141231']
特征工程
# Removing special charactersdata=train.iloc[:,2:27]data.replace("[^a-zA-Z]"," ",regex=True, inplace=True)# Renaming column names for better understanding and ease of accesslist1= [i for i in range(25)]new_Index=[str(i) for i in list1]data.columns= new_Indexdata.head(5)
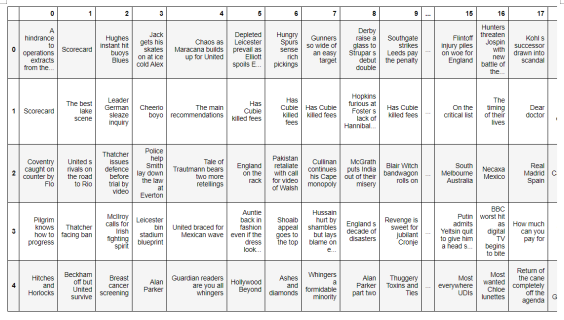
# Convertng headlines to lower casefor index in new_Index:data[index] = data[index].str.lower()data.head(1)
根据索引来合并所有新闻标题:
headlines = []for row in range(0,len(data.index)):headlines.append(' '.join(str(x) for x in data.iloc[row,0:25]))

应用CountVectorizer和RandomForestClassifier方法
## implement BAG OF WORDScountvector=CountVectorizer(ngram_range=(2,2))traindataset=countvector.fit_transform(headlines)## implement RandomForest Classifier
randomclassifier=RandomForestClassifier(n_estimators=200,criterion='entropy')randomclassifier.fit(traindataset,train['Label'])
在测试集上进行预测
## Predict for the Test Datasettest_transform= []for row in range(0,len(test.index)):test_transform.append(' '.join(str(x) for x in test.iloc[row,2:27]))test_dataset = countvector.transform(test_transform)predictions = randomclassifier.predict(test_dataset)
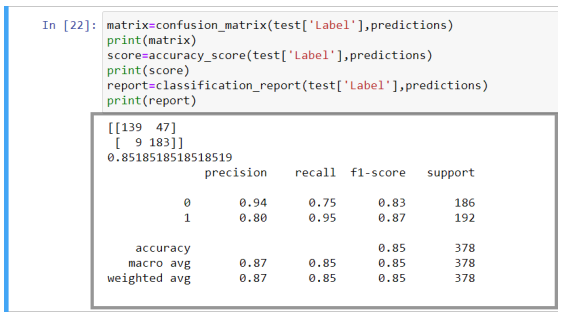
最后,检查准确性
matrix = confusion_matrix(test['Label'],predictions)print(matrix)score = accuracy_score(test['Label'],predictions)print(score)report = classification_report(test['Label'],predictions)print(report)
关于作者
Ronil Patil
https://www.linkedin.com/in/ronil08/
原文标题:
Stock Price Movement Based On News Headline
原文链接:
https://www.analyticsvidhya.com/blog/2021/05/stock-price-movement-based-on-news-headline
编辑:王菁
校对:林亦霖
译者简介

王闯(Chuck),台湾清华大学资讯工程硕士。曾任奥浦诺管理咨询公司数据分析主管,现任尼尔森市场研究公司数据科学经理。很荣幸有机会通过数据派THU微信公众平台和各位老师、同学以及同行前辈们交流学习。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织