
用深度学习解决TSP旅行商问题,研究到哪一步了?
转自:机器之心
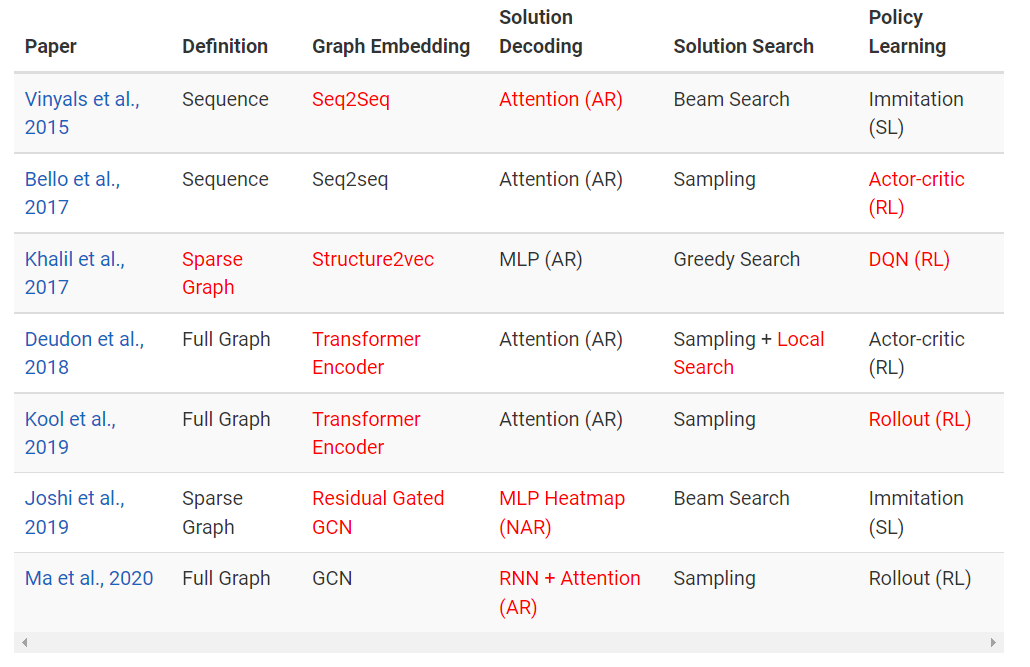
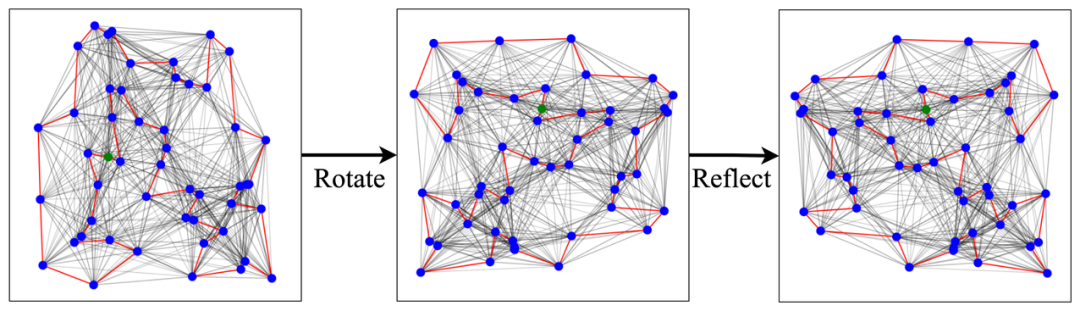
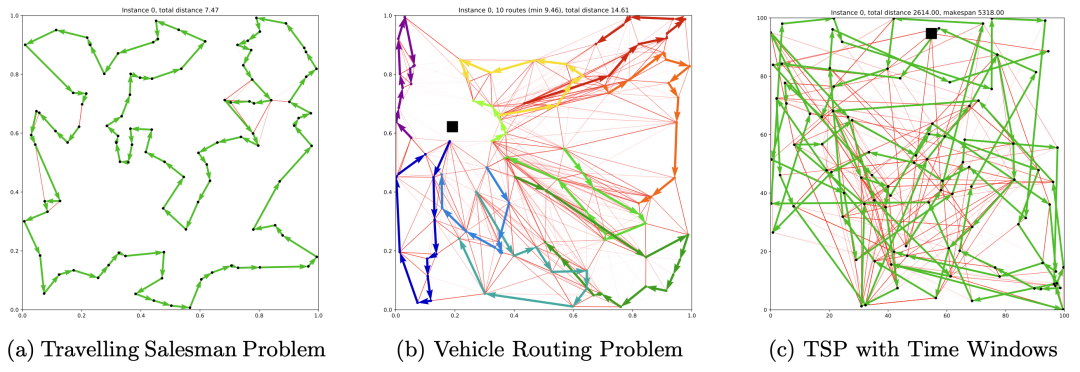
最近,针对旅行推销员等组合优化问题开发神经网络驱动的求解器引起了学术界的极大兴趣。这篇博文介绍了一个神经组合优化步骤,将几个最近提出的模型架构和学习范式统一到一个框架中。透过这一系列步骤,作者分析了深度学习在路由问题方面的最新进展,并提供了新的方向来启发今后的研究,以创造实际的价值。


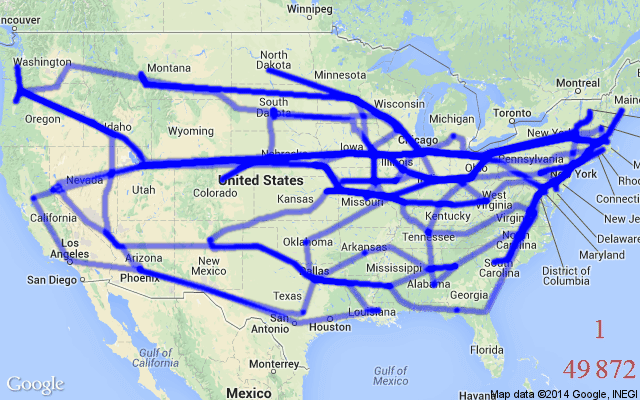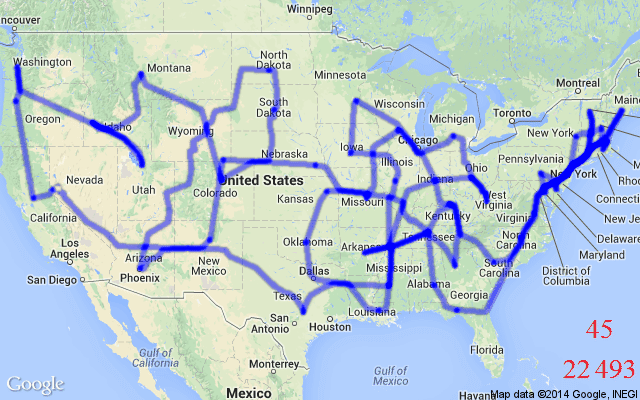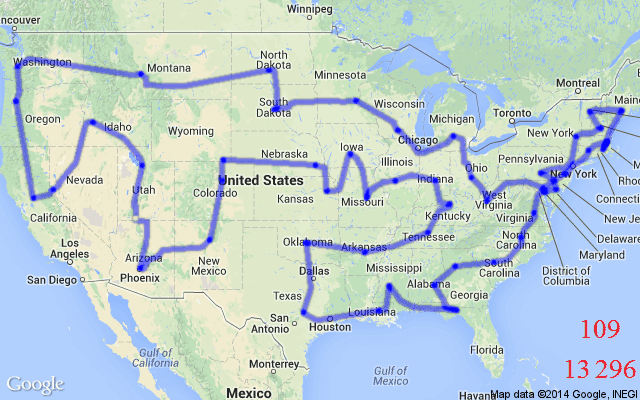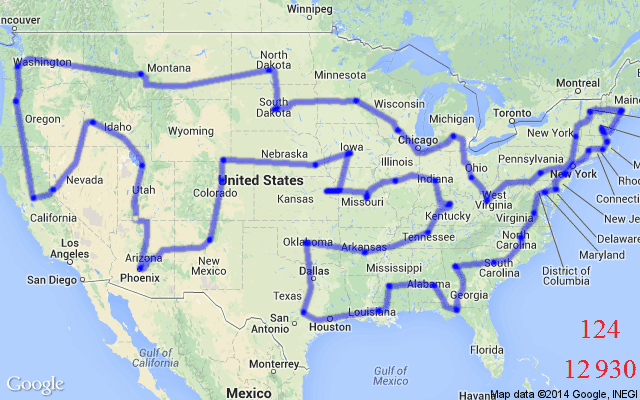
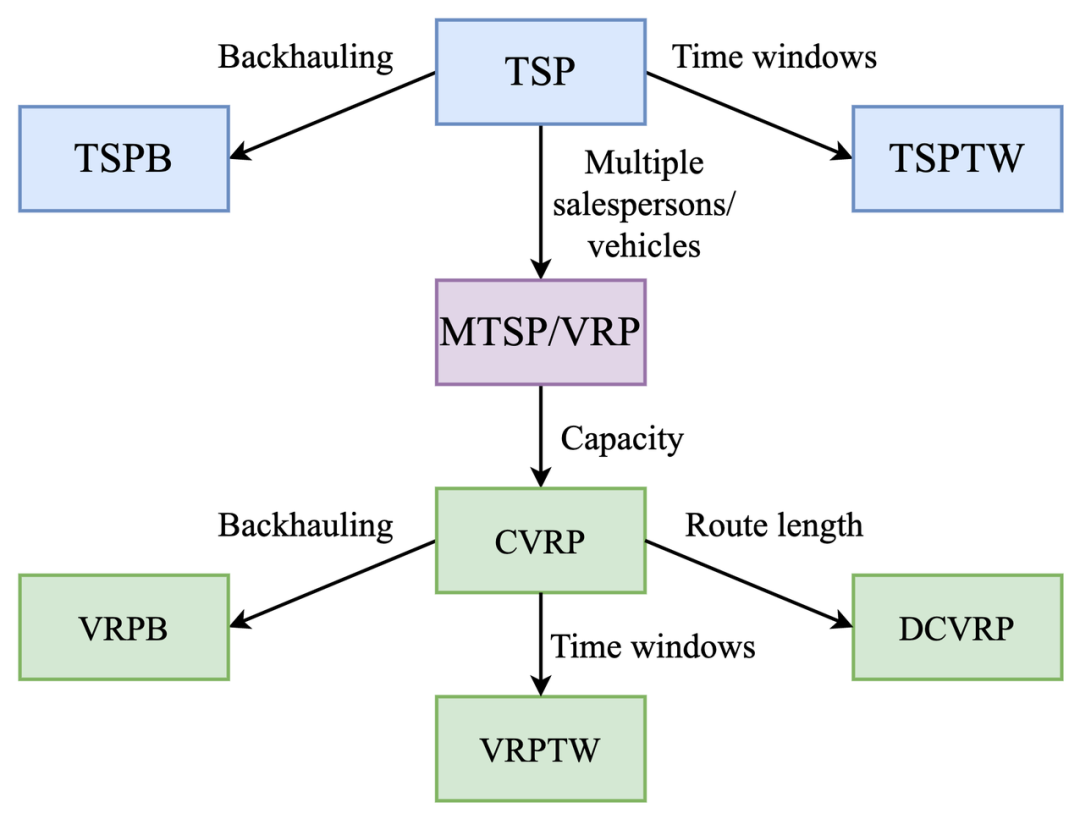
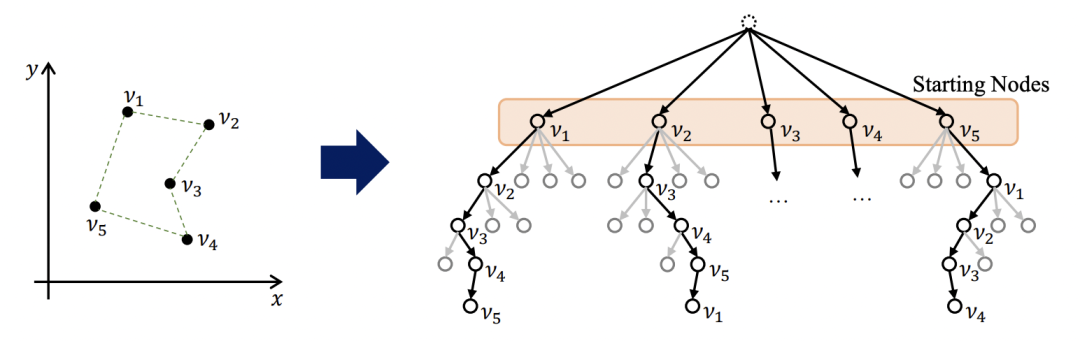
非手工的启发式方法。神经网络不需要应用专家手动设计启发式和规则,而是通过模仿最佳求解器或通过强化学习来学习这些启发式和规则(下一节中展示了一个示例)。
GPU 快速推理。对于问题规模较大的情况,传统求解器的执行时间通常很长,例如 Concorde 用了 7.5 个月的时间解决了拥有 109,399 个节点的最大 TSP。另一方面,一旦用来近似求解 COP 的神经网络训练完成,那么使用的时候就具有显着有利的时间复杂度,并且可以通过 GPU 进行并行化。这使得它们非常适合解决实时决策问题,尤其是路由问题。
应对新颖且研究不足的 COP。神经组合优化可以显着加快针对具有深奥约束的新问题或未研究问题的特定 COP 求解器的开发进度。此类问题经常出现在科学级的发现或计算机体系结构中,一个令人兴奋的成功例子是谷歌的芯片设计系统,它将为下一代 TPU 提供动力。你没看错——下一个运行神经网络的 TPU 芯片是由神经网络设计的!

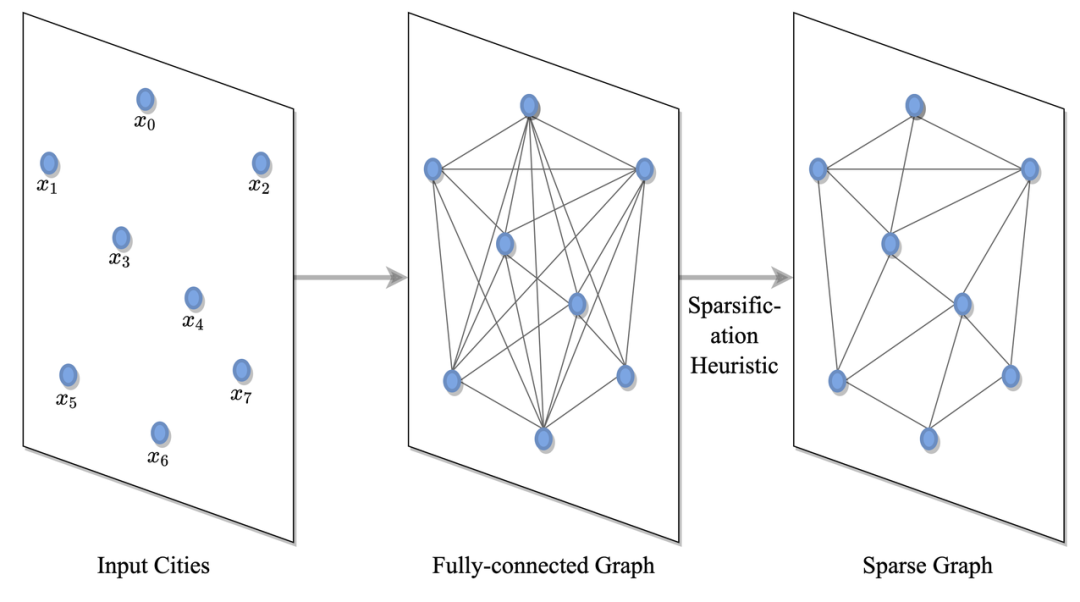
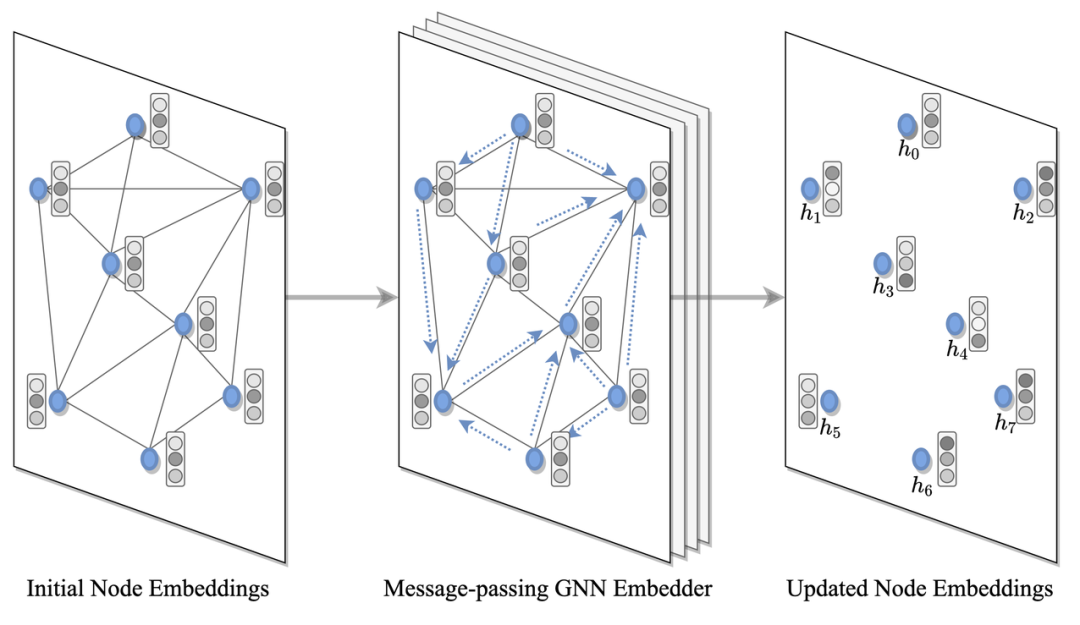
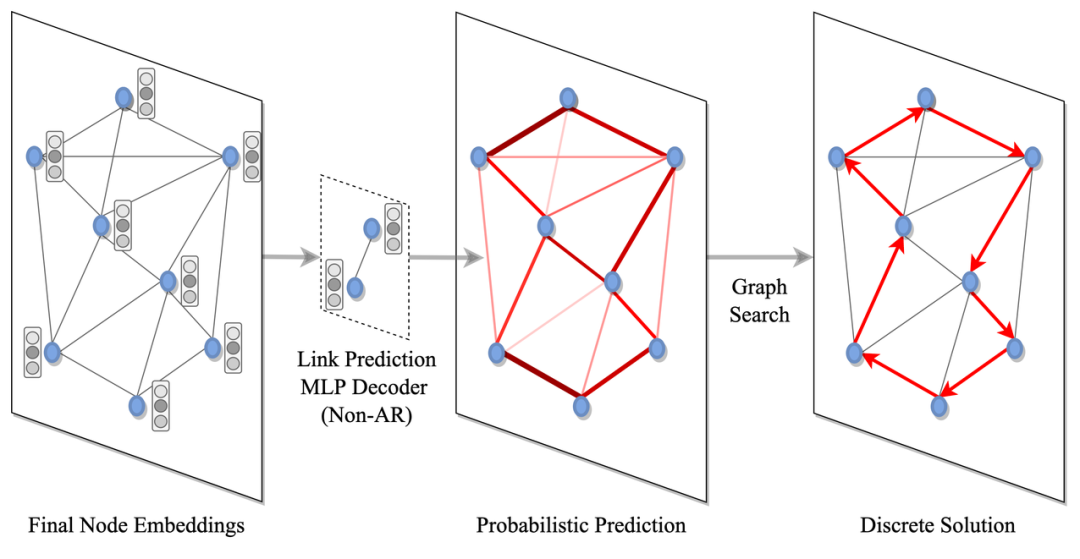
往期精彩:
时隔一年!深度学习语义分割理论与代码实践指南.pdf第二版来了!
评论