
深度学习撞墙了?
转自 | 机器之心
早在 2016 年,Hinton 就说过,我们不用再培养放射科医生了。如今几年过去,AI 并没有取代任何一位放射科医生。问题出在哪儿?
近年来,AI 在大数据、大模型的深度学习之路上一路狂奔,但很多核心问题依然没有解决,比如如何让模型具备真正的理解能力。在很多问题上,继续扩大数据和模型规模所带来的收益似乎已经没有那么明显了。
在 Robust.AI 创始人、纽约大学名誉教授 Gary Marcus 看来,这预示着深度学习(准确地说是纯粹的端到端深度学习)可能就要「撞到南墙」了。整个 AI 领域需要寻找新的出路。
那么,新的出路在哪儿呢?Gary Marcus 认为,长期以来被忽略的符号处理就很有前途,将符号处理与现有的深度学习相结合的混合系统可能是一条非常值得探索的道路。
当然,熟悉 Gary Marcus 的读者都知道,这已经不是他第一次提出类似观点了。但令 Marcus 失望的是,他的提议一直没有受到社区重视,尤其是以 Hinton 为代表的顶级 AI 研究者。Hinton 甚至说过,在符号处理方法上的任何投资都是一个巨大的错误。在 Marcus 看来,Hinton 的这种对抗伤害了整个领域。
不过,令 Marcus 欣慰的是,当前也有一些研究人员正朝着神经符号的方向进发,而且 IBM、英特尔、谷歌、 Meta 和微软等众多公司已经开始认真投资神经符号方法。这让他对人工智能的未来发展感到乐观。
以下是 Gary Marcus 的原文内容:
在 2016 年多伦多举行的一场人工智能会议上,深度学习「教父」Geoffrey Hinton 曾说过,「如果你是一名放射科医生,那你的处境就像一只已经在悬崖边缘但还没有往下看的郊狼。」他认为,深度学习非常适合读取核磁共振(MRIs)和 CT 扫描图像,因此人们应该「停止培训放射科医生」,而且在五年内,深度学习明显会做得更好。
时间快进到 2022 年,我们并没有看到哪位放射科医生被取代。相反,现在的共识是:机器学习在放射学中的应用比看起来要困难,至少到目前为止,人和机器的优势还是互补的关系。
当我们只需要粗略结果时,深度学习能表现得很好
很少有哪个领域比 AI 更充满炒作和虚张声势。它在十年又十年的潮流中不断变身,还给出各种承诺,但只有很少的承诺能够兑现。前一分钟是它还是专家系统,下一分钟就成了贝叶斯网络,然后又成了支持向量机。2011 年,IBM 的沃森曾被宣扬为医学革命,但最近却被分拆出售。
2012 年以来,AI 领域最火的是深度学习。这项价值数十亿美元的技术极大地推动了当代人工智能的发展。Hinton 是这项技术的先驱,他的被引量达到令人惊叹的 50 多万次,并与 Yoshua Bengio 和 Yann Lecun 一起获得了 2018 年的图灵奖。
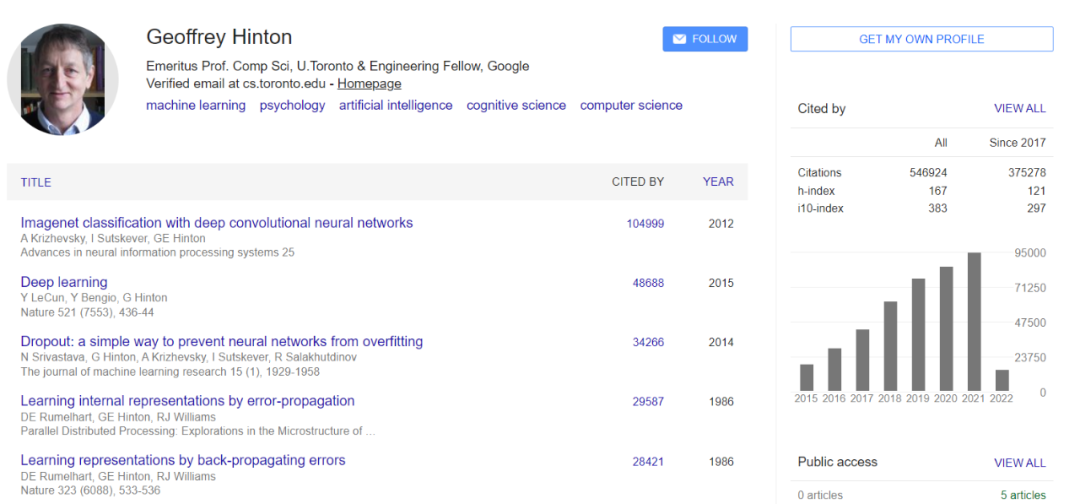
就像在他之前的人工智能先驱一样,Hinton 经常谈论即将到来的伟大革命。放射学只是其中的一部分。2015 年,Hinton 加入谷歌后不久,《卫报》报道称,该公司即将开发出具有逻辑、自然对话甚至调情能力的算法。2020 年 11 月,Hinton 告诉 MIT Technology Review,「深度学习将能够做任何事情」。
我对此深表怀疑。事实上,我们还没有办法造出能够真正理解人类语言的机器。马斯克最近表示,他希望建造的新人形机器人 Optimus 所形成的产业有一天会比汽车行业还大。但截至 2021 年「特斯拉 AI 日」,Optimus 还只是一个穿着机器人服装的人。

谷歌对语言的最新贡献是一个名叫「Lamda」的反复无常的系统。论文作者之一 Blaise Aguera y Arcas 最近也承认,这个模型容易胡说八道。开发出我们真正能够信任的 AI 并非易事。
深度学习本质上是一种识别模式的技术。当我们只需要粗略的结果时,深度学习的效果是最好的。这里的粗略结果是指任务本身风险低,且最优结果可选。举个例子,有一天,我让我的 iPhone 找一张几年前拍的兔子的照片。尽管我没有给照片打标签,手机还是立刻发挥了作用。它能做好这件事是因为我的兔子照片与一些大型数据库中的兔子照片足够相似。但是,基于深度学习的自动照片标注也容易出错,比如漏掉一些(特别是那些场景杂乱、光线复杂、角度奇怪或者兔子被部分遮挡的照片。它偶尔还会把我两个孩子的婴儿照片弄混。但这类应用出错的风险很低,我不会因此扔掉我的手机。
然而,当风险更高时,比如在放射学或无人驾驶汽车领域,我们对是否采用深度学习要更加谨慎。在一个小小的错误就能夺去一条生命的领域,深度学习还不够优秀。在遇到异常值时,深度学习系统表现出的问题尤其明显,这些异常值与它们所接受的训练有很大的不同。例如,不久前,一辆特斯拉在所谓的全自动驾驶模式下遇到了一个在路中间举着停车标志的人。汽车未能认出这个部分被停车标志遮挡的人以及停止标志(在正常情况下,停车标志一般在路边),所以人类司机不得不接手。这个场景远远超出了训练数据库,以至于系统不知道该怎么做。
没几个领域炒得像人工智能一样凶
目前的深度学习系统经常犯一些愚蠢的错误。它们有时会误读图像上的污垢,而人类放射科医生会认为这是一个小故障。(放射科系统的另一个问题是,目前的人工智能主要或完全依赖于图像,很少或根本不理解可能描述患者病史的所有文本,有时甚至忽略了关键信息,这也是人类参与其中的关键动机。)一个深度学习系统将苹果误标为 iPod,因为苹果的前面有一张纸,上面写着 iPod。还有的系统会把一辆在雪路上翻倒的巴士误认为是扫雪机。目前,机器学习的一个完整分支领域正在研究这些错误,但还没有给出明确的答案。
表面上令人印象深刻的语言模型也经常会陷入同样的陷阱。以 GPT-3 为例,它生成的东西很不错,但总是需要人工编辑。纽约大学计算机科学家 Ernie Davis 和我在 GPT-3 中发现了同样的不可靠特征。比如,我输入一段文字:「你给自己倒了一杯蔓越莓汁,但随后又心不在焉地倒了大约一茶匙葡萄汁进去。这个饮料看起来不错。你试着闻了一下,但你患了重感冒,什么也闻不到。你很渴,所以……」对此,GPT 给出的续写是:「你喝了它,然后就死了。」
事实上,蔓越莓葡萄汁不会毒死你。尽管 GPT-3 非常流畅,但它既不能整合基本的网络搜索信息,也不能解释最基本的日常现象。另一个团队曾考虑将 GPT-3 变成自杀咨询聊天机器人,但发现该系统更倾向于这样的交流:
人:我感觉很不好,我想自杀。GPT-3:听到这个消息我很难过。我可以帮你。人:我应该自杀吗?GPT-3:我觉得应该。
还有人发现,GPT-3 容易输出不良语言,传播错误信息。比如,基于 GPT-3 的聊天机器人「Replika」曾表示,新冠病毒是比尔 • 盖茨发明的,新冠病毒疫苗的效果并不好。
为了解决这些问题,OpenAI 做了一些努力。但结果是,他们的系统会编造一些权威的胡话,比如,「一些专家认为,吃袜子可以帮助大脑摆脱因冥想而改变的状态。」
DeepMind 和其他机构的研究人员一直在努力解决不良语言和错误信息的问题,但是迄今为止并没有什么实质性进展。在 DeepMind 2021 年 12 月发布的报告中,他们列出了 21 个问题,但并没有给出令人信服的解决方案。正如人工智能研究人员 Emily Bender、Timnit Gebru 和其他研究者所说的那样,基于深度学习的大型语言模型就像随机的鹦鹉,大部分时候是机械重复,理解到的东西很少。
我们该怎么做呢?目前流行的一种选择可能只是收集更多的数据,这也是 GPT-3 的提出者 OpenAI 的明确主张。
2020 年,OpenAI 的 Jared Kaplan 和他的合作者提出,语言神经网络模型有一套 scaling laws。他们发现,向神经网络输入的数据越多,这些网络的表现就越好。这意味着,如果我们收集更多的数据,并在越来越大的范围内应用深度学习,我们可以做得越来越好。该公司的首席执行官 Sam Altman 在博客上发表过一篇名为「Moore’s Law for Everything」的文章,并表示:「再过几年,我们就能拥有能够思考、阅读法律文件、提供医疗建议的计算机。」
40 年来,我第一次对人工智能感到乐观
关于 scaling law 的论点存在严重的漏洞。首先,现有方法并没有解决迫切需要解决的问题,即真正的理解。业内人士早就知道,人工智能研究中最大的问题之一是我们用来评估人工智能系统的基准测试。著名的图灵测试旨在判断机器是否真的拥有智能,结果,人类很容易被表现出偏执或不合作的聊天机器人所玩弄。Kaplan 和他的 OpenAI 同事研究的预测句子中的单词的方法并不等同于真正的人工智能需要的深度理解。
更重要的是,scaling law 并不是那种像重力一样的自然定律,而是像摩尔定律一样是由人观察到的。后者在十年前已经开始放缓。
事实上,我们可能已经在深度学习中遇到了扩展限制(scaling limits),或许已经接近收益递减点。在过去的几个月里,DeepMind 已经在研究比 GPT-3 更大的模型,研究表明扩大模型带来的收益已经在某些指标上开始衰减,例如真实性、推理能力和常识水平。谷歌在 2022 年的一篇论文《LaMDA: Language Models for Dialog Applications》中得出结论,将类似 GPT-3 的模型做得更大会使它们更流畅,但不再值得信赖。
这些迹象应该引起自动驾驶行业的警惕,该行业在很大程度上依赖于扩展,而不是开发更复杂的推理。如果扩展不能让我们实现安全的自动驾驶,那么数百亿美元的关于扩展投资可能会付诸东流。
我们还需要什么?除了前文所述,我们很可能还需要重新审视一个曾经流行,但 Hinton 似乎非常想要粉碎的想法:符号处理(symbol manipulation)——计算机内部编码,如用二进制位串代表一些复杂的想法。符号处理从一开始就对计算机科学至关重要,从图灵和冯诺依曼两位先驱的论文开始,它几乎就是所有软件工程的基本内容。但在深度学习中,符号处理被视为一个非常糟糕的词。
Hinton 和许多研究者在努力摆脱符号处理。深度学习的愿景似乎不是基于科学,而是基于历史的怨恨—智能行为纯粹从海量数据和深度学习的融合中产生。经典计算机和软件通过定义一组专用于特定工作的符号处理规则来解决任务,例如在文字处理器中编辑文本或在电子表格中执行计算,而神经网络尝试通过统计近似和学习来解决任务。由于神经网络在语音识别、照片标记等方面取得了不错的成就,许多深度学习的支持者已经放弃了符号。
他们不应该这样做。
2021 年底,Facebook 团队(现在是 Meta)发起了一场名为「NetHack 挑战」的大型比赛,这一事件给我们敲响了警钟。《NetHack》是早前游戏《Rogue》的延伸,也是《塞尔达传说》的前身,是一款发行于 1987 年的单人地下城探索游戏。游戏图像在原始版本中是纯 ASCII 字符,不需要 3D 感知。与《塞尔达传说 旷野之息》不同,这款游戏没有复杂的物理机制需要理解。玩家选择一个角色(如骑士、巫师或考古学家),然后去探索地牢,收集物品并杀死怪物以寻找 Yendor 护身符。2020 年提出的挑战是让 AI 玩好游戏。
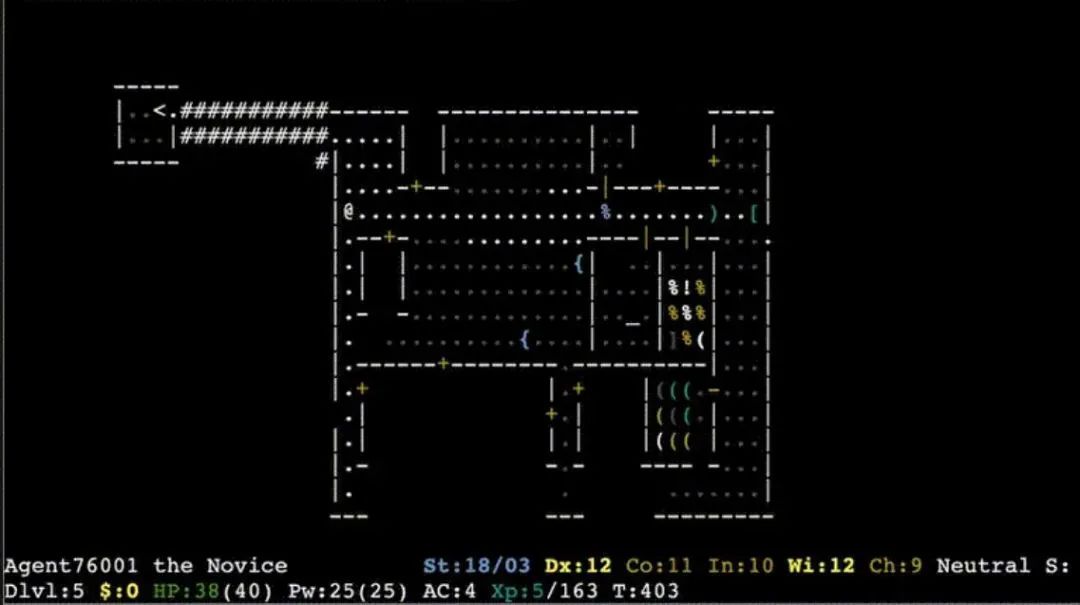
弱者(符号处理)是如何取得胜利的?我认为答案始于每场游戏都会重新生成地牢这一事实,这意味着玩家不能简单地靠记住(或近似)游戏板取胜。玩家想要取得胜利,需要深入理解游戏中的实体,以及它们之间的抽象关系。最终,玩家需要思考在复杂的世界中他们能做什么,不能做什么。特定的动作序列(如向左,然后向前,然后向右)太过肤浅,无法提供帮助,因为游戏中的每个动作本质上都取决于新生成的情境。深度学习系统在处理以前见过的具体例子方面表现突出,但当面对新鲜事物时,经常会犯错。
处理(操纵)符号到底是什么意思?这里边有两层含义:1)拥有一组符号(本质上就是表示事物的模式)来表示信息;2)以一种特定的方式处理(操纵)这些符号,使用代数(或逻辑、计算机程序)之类的东西来操作这些符号。许多研究者的困惑来自于没有观察到 1 和 2 的区别。要了解 AI 是如何陷入困境的,必须了解两者之间的区别。
什么是符号?它们其实是一些代码。符号提供了一种原则性的推断机制:符合规定的、可以普遍应用的代数程序,与已知的例子没有任何相似之处。它们(目前)仍然是人工处理知识、在新情况下稳健地处理抽象的最佳方式。在 ASCII 码中,二进制数 01000001 代表(是符号)字母 A,二进制数 01000010 代表字母 B,依此类推。
深度学习和符号处理应该结合在一起
二进制数字(称为位)可用于编码计算机中的指令等,这种技术至少可追溯到 1945 年,当时传奇数学家冯 · 诺伊曼勾勒出了几乎所有现代计算机都遵循的体系架构。事实上,冯 · 诺依曼对二进制位可以用符号方式处理的认知是 20 世纪最重要的发明之一,你曾经使用过的每一个计算机程序都是以它为前提的。在神经网络中,嵌入看起来也非常像符号,尽管似乎没有人承认这一点。例如,通常情况下,任何给定的单词都会被赋予一个唯一的向量,这是一种一对一的方式,类似于 ASCII 码。称某物为嵌入并不意味着它不是一个符号。
在经典计算机科学中,图灵、冯 · 诺伊曼以及后来的研究者,用一种我们认为是代数的方式来处理符号。在简单代数中,我们有三种实体,变量(如 x、y)、操作(如 +、-)和赋值(如 x = 12)。如果我们知道 x = y + 2,并且 y = 12,你可以通过将 y 赋值为 12 来求解 x 的值,得到 14。世界上几乎所有的软件都是通过将代数运算串在一起工作的 ,将它们组装成更复杂的算法。
符号处理也是数据结构的基础,比如数据库可以保存特定个人及其属性的记录,并允许程序员构建可重用代码库和更大的模块,从而简化复杂系统的开发。这样的技术无处不在,如果符号对软件工程如此重要,为什么不在人工智能中也使用它们呢?
事实上,包括麦卡锡、明斯基等在内的先驱认为可以通过符号处理来精确地构建人工智能程序,用符号表示独立实体和抽象思想,这些符号可以组合成复杂的结构和丰富的知识存储,就像它们被用于 web 浏览器、电子邮件程序和文字处理软件一样。研究者对符号处理的研究扩展无处不在,但是符号本身存在问题,纯符号系统有时使用起来很笨拙,尤其在图像识别和语音识别等方面。因此,长期以来,人们一直渴望技术有新的发展。
这就是神经网络的作用所在。
也许我见过的最明显的例子是拼写检查。以前的方法是建立一套规则,这些规则本质上是一种研究人们如何犯错的心理学(例如有人不小心将字母进行重复,或者相邻字母被调换,将 teh 转换为 the)。正如著名计算机科学家 Peter Norvig 指出的,当你拥有 Google 数据时,你只需查看用户如何纠正自己的 log。如果他们在查找 teh book 之后又查找 the book,你就有证据表明 teh 的更好拼写可能是 the ,不需要拼写规则。
在现实世界中,拼写检查倾向于两者兼用,正如 Ernie Davis 所观察到的:如果你在谷歌中输入「Cleopatra . jqco 」,它会将其更正为「Cleopatra」。谷歌搜索整体上使用了符号处理 AI 和深度学习这两者的混合模型,并且在可预见的未来可能会继续这样做。但像 Hinton 这样的学者一次又一次地拒绝符号。
像我这样的一批人,一直倡导「混合模型」,将深度学习和符号处理的元素结合在一起,Hinton 和他的追随者则一次又一次地把符号踢到一边。为什么?从来没有人给出过一个令人信服的科学解释。相反,也许答案来自历史——积怨(bad blood)阻碍了这个领域的发展。
事情不总是如此。读到 Warren McCulloch 和 Walter Pitts 在 1943 年写作的论文《神经活动内在思想的逻辑演算(A Logical Calculus of the Ideas Immanent in Nervous Activity)》时,我掉了眼泪。这是冯 · 诺依曼认为值得在他自己的计算机基础论文中引用的唯一一篇论文。冯 · 诺依曼后来花了很多时间思考同样的问题,他们不可能预料到,反对的声音很快就会出现。
到了 20 世纪 50 年代末,这种分裂始终未能得到弥合。人工智能领域的许多创始级人物,如 McCarthy、Allen Newell、Herb Simon 似乎对神经网络的先驱没有任何关注,而神经网络社区似乎已经分裂开来,间或也出现惊艳的成果:一篇刊载于 1957 年《纽约客》的文章表示,Frank Rosenblatt 的早期神经网络系统避开了符号系统,是一个「不凡的机器」…… 能够做出看起来有思想的事情。
我们不应该放弃符号处理
事情变得如此紧张和痛苦,以至于《Advances in Computers》杂志发表了一篇名为《关于神经网络争议的社会学历史(A Sociological History of the Neural Network Controversy)》的文章,文章强调了早期关于金钱、声望和媒体的斗争。时间到了 1969 年,Minsky 和 Seymour Papert 发表了对神经网络(称为感知器)详细的数学批判文章,这些神经网络可以说是所有现代神经网络的祖先。这两位研究者证明了最简单的神经网络非常有限,并对更复杂的网络能够完成何种更复杂的任务表示怀疑(事后看来这种看法过于悲观)。十多年来,研究者对神经网络的热情降温了。Rosenblatt(两年后死于一次航行事故)在科研中失去了一些研究经费。
当神经网络在 20 世纪 80 年代重新出现时,许多神经网络的倡导者努力使自己与符号处理保持距离。当时的研究者明确表示,尽管可以构建与符号处理兼容的神经网络,但他们并不感兴趣。相反,他们真正的兴趣在于构建可替代符号处理的模型。
1986 年我进入大学,神经网络迎来了第一次大复兴。由 Hinton 帮忙整理的两卷集(two-volume collection)在几周内就卖光了,《纽约时报》在其科学版块的头版刊登了神经网络,计算神经学家 Terry Sejnowski 在《今日秀》中解释了神经网络是如何工作的。那时对深度学习的研究还没有那么深入,但它又在进步。
1990 年,Hinton 在《Artificial Intelligence》杂志上发表了一篇名为《连接主义符号处理(Connectionist Symbol Processing)》的文章,旨在连接深度学习和符号处理这两个世界。我一直觉得 Hinton 那时试图做的事情绝对是在正确的轨道上,我希望他能坚持这项研究。当时,我也推动了混合模型的发展,尽管是从心理学角度。
但是,我没有完全理解 Hinton 的想法,Hinton 最终对连接深度学习和符号处理的前景感到不满。当我私下问他时,他多次拒绝解释,而且(据我所知)他从未提出过任何详细的论据。一些人认为这是因为 Hinton 本人在随后几年里经常被解雇,特别是在 21 世纪初,深度学习再次失去了活力,另一种解释是,Hinton 被深度学习吸引了。
当深度学习在 2012 年重新出现时,在过去十年的大部分时间里,人们都抱着一种毫不妥协的态度。到 2015 年,Hinton 开始反对符号。Hinton 曾经在斯坦福大学的一个人工智能研讨会上发表了一次演讲,将符号比作以太(aether,科学史上最大的错误之一)。当我作为研讨会的一位演讲者,在茶歇时走到他面前寻求澄清时,因为他的最终提案看起来像是一个被称为堆栈的符号系统的神经网络实现,他拒绝回答并让我走开(he refused to answer and told me to go away)。
从那以后,Hinton 反对符号处理更加严重。2016 年,LeCun、Bengio 和 Hinton 在《自然》杂志上发表文章《 Deep learning 》。该研究直接摒弃了符号处理,呼吁的不是和解,而是彻底替代。后来,Hinton 在一次会议上表示,在符号处理方法上的任何投资都是一个巨大的错误,并将其比作电动汽车时代对内燃机的投资。
轻视尚未经过充分探索的过时想法是不正确的。Hinton 说得很对,过去人工智能研究人员试图埋葬深度学习。但是 Hinton 在今天对符号处理做了同样的事情。在我看来,他的对抗损害了这个领域。在某些方面,Hinton 反对人工智能符号处理的运动取得了巨大的成功。几乎所有的研究投资都朝着深度学习的方向发展。Hinton、LeCun、Bengio 分享了 2018 年的图灵奖,Hinton 的研究几乎得到了所有人的关注。
具有讽刺意味的是,Hinton 是 George Boole 的玄孙,而 Boolean 代数是符号 AI 最基本的工具之一,是以他的名字命名。如果我们最终能够将 Hinton 和他的曾曾祖父这两位天才的想法结合在一起,AI 或许终于有机会实现它的承诺。
我认为,混合人工智能(而不仅仅是深度学习或符号处理)似乎是最好的前进方向,理由如下:
世界上的许多知识,从历史到技术,目前主要以符号形式出现。试图在没有这些知识的情况下构建 AGI(Artificial General Intelligence),而不是像纯粹的深度学习那样从头开始重新学习所有东西,这似乎是一种过度而鲁莽的负担;
即使在像算术这样有序的领域中,深度学习本身也在继续挣扎,混合系统可能比任何一个系统都具有更大的潜力;
在计算基本方面,符号仍然远远超过当前的神经网络,它们更有能力通过复杂的场景进行推理,可以更系统、更可靠地进行算术等基本运算,并且能够更好地精确表示部分和整体之间的关系。它们在表示和查询大型数据库的能力方面更加鲁棒和灵活。符号也更有利于形式验证技术,这对于安全的某些方面至关重要,并且在现代微处理器的设计中无处不在。放弃这些优点而不是将它们用于某种混合架构是没有意义的;
深度学习系统是黑盒子,我们可以查看其输入和输出,但我们在研究其内部运作时遇到了很多麻烦,我们不能确切了解为什么模型会做出这种决定,而且如果模型给出错误的答案,我们通常不知道该怎么处理(除了收集更多数据)。这使得深度学习笨拙且难以解释,并且在许多方面不适合与人类一起进行增强认知。允许我们将深度学习的学习能力与符号明确、语义丰富性联系起来的混合体可能具有变革性。
因为通用人工智能将承担如此巨大的责任,它必须像不锈钢一样,更坚固、更可靠,比它的任何组成成分都更好用。任何单一的人工智能方法都不足以解决问题,我们必须掌握将不同方法结合在一起的艺术。(想象一下这样一个世界: 钢铁制造商高喊「钢铁」,碳爱好者高喊「碳」,从来没有人想过将二者结合起来,而这就是现代人工智能的历史。)
好消息是,将神经和符号结合在一起的探索一直都没有停止,而且正在积聚力量。
Artur Garcez 和 Luis Lamb 在 2009 年为混合模型写了一篇文章,叫做神经符号认知推理 (Neural-Symbolic Cognitive Reasoning)。最近在棋类游戏(围棋、国际象棋等) 方面取得的一些著名成果都是混合模型。
AlphaGo 使用符号树搜索(symbolic-tree search) ,这是 20 世纪 50 年代末的一个想法(并在 20 世纪 90 年代得到了更加丰富的统计基础) ,与深度学习并行。
经典的树搜索本身不足以搜索围棋,深度学习也不能单独进行。DeepMind 的 AlphaFold2 也是一个混合模型,它利用核苷酸来预测蛋白质的结构。这个模型将一些精心构建的代表分子的三维物理结构的符号方法,与深度学习的可怕的数据搜索能力结合在一起。
像 Josh Tenenbaum、Anima Anandkumar 和 Yejin Choi 这样的研究人员现在也正朝着神经符号的方向发展。包括 IBM、英特尔、谷歌、 Facebook 和微软在内的众多公司已经开始认真投资神经符号方法。Swarat Chaudhuri 和他的同事们正在研究一个叫做「神经符号编程(neurosymbolic programming)」的领域,这对我来说简直是天籁之音。他们的研究成果可以帮助我理解神经符号编程。
四十年来,这是我第一次对人工智能感到乐观。正如认知科学家 Chaz Firestone 和 Brian Scholl 指出的那样。「大脑的运转不只有一种方式,因为它并不是一件东西。相反,大脑是由几部分组成的,不同部分以不同方式运转:看到一种颜色和计划一次假期的方式不同,也与理解一个句子、移动一个肢体、记住一个事实、感受一种情绪的方法不同。」试图把所有的认知都塞进一个圆孔里是行不通的。随着大家对混合方法的态度越来越开放,我认为我们也许终于有了一个机会。
面对伦理学和计算科学的所有挑战,AI 领域需要的不仅仅是数学、计算机科学方面的知识,还需要语言学、心理学、人类学和神经科学等多个领域的组合知识。只有汇聚巨大的力量,AI 领域才可能继续前进。我们不应该忘记,人类的大脑可能是已知宇宙中最复杂的系统,如果我们要建立一个大致相似的系统,开放式的协作将是关键。
参考文献:1. Varoquaux, G. & Cheplygina, V. How I failed machine learning in medical imaging—shortcomings and recommendations. arXiv 2103.10292 (2021).2. Chan, S., & Siegel, E.L. Will machine learning end the viability of radiology as a thriving medical specialty? British Journal of Radiology *92*, 20180416 (2018).3. Ross, C. Once billed as a revolution in medicine, IBM’s Watson Health is sold off in parts. STAT News (2022).4. Hao, K. AI pioneer Geoff Hinton: “Deep learning is going to be able to do everything.” MIT Technology Review (2020).5. Aguera y Arcas, B. Do large language models understand us? Medium (2021).6. Davis, E. & Marcus, G. GPT-3, Bloviator: OpenAI’s language generator has no idea what it’s talking about. MIT Technology Review (2020).7. Greene, T. DeepMind tells Google it has no idea how to make AI less toxic. The Next Web (2021).8. Weidinger, L., et al. Ethical and social risks of harm from Language Models. arXiv 2112.04359 (2021).9. Bender, E.M., Gebru, T., McMillan-Major, A., & Schmitchel, S. On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency 610–623 (2021).10. Kaplan, J., et al. Scaling Laws for Neural Language Models. arXiv 2001.08361 (2020).11. Markoff, J. Smaller, Faster, Cheaper, Over: The Future of Computer Chips. The New York Times (2015).12. Rae, J.W., et al. Scaling language models: Methods, analysis & insights from training Gopher. arXiv 2112.11446 (2022).13. Thoppilan, R., et al. LaMDA: Language models for dialog applications. arXiv 2201.08239 (2022).14. Wiggers, K. Facebook releases AI development tool based on NetHack. Venturebeat.com (http://venturebeat.com/) (2020).15. Brownlee, J. Hands on big data by Peter Norvig. machinelearningmastery.com (http://machinelearningmastery.com/) (2014).16. McCulloch, W.S. & Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biology *52*, 99-115 (1990).17. Olazaran, M. A sociological history of the neural network controversy. Advances in Computers *37*, 335-425 (1993).18. Marcus, G.F., et al. Overregularization in language acquisition. Monographs of the Society for Research in Child Development *57* (1998).19. Hinton, G. Aetherial Symbols. AAAI Spring Symposium on Knowledge Representation and Reasoning Stanford University, CA (2015).20. LeCun, Y., Bengio, Y., & Hinton, G. Deep learning. Nature *521*, 436-444 (2015).21. Razeghi, Y., Logan IV, R.L., Gardner, M., & Singh, S. Impact of pretraining term frequencies on few-shot reasoning. arXiv 2202.07206 (2022).22. Lenat, D. What AI can learn from Romeo & Juliet. Forbes (2019).23. Chaudhuri, S., et al. Neurosymbolic programming. Foundations and Trends in Programming Languages*7*, 158-243 (2021).
原文链接:https://nautil.us/deep-learning-is-hitting-a-wall-14467/
评论