
深度学习视觉研究综述
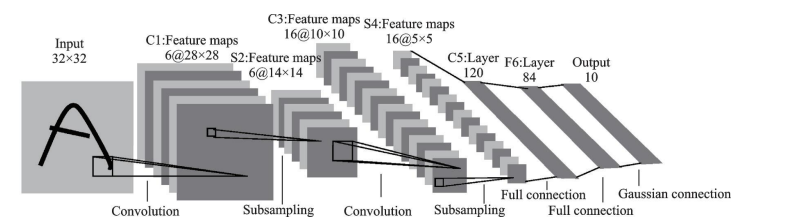
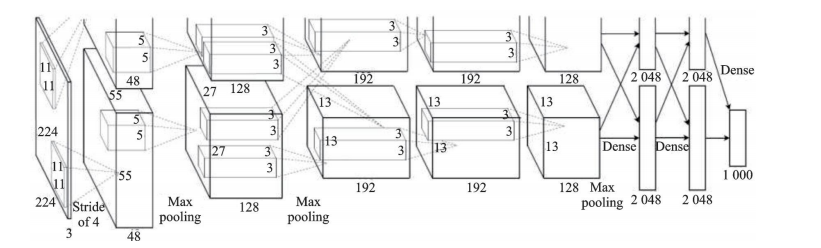
图2 AlexNet结构示意图
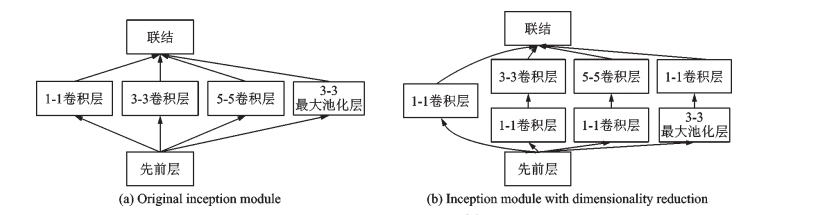
图3 Inception 模块示意图
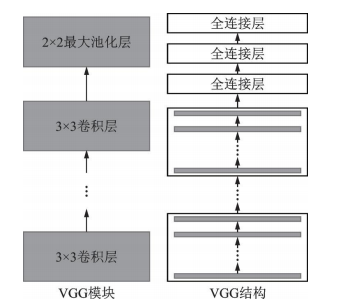
图 4 VGG 模块和VGG 结构示意图
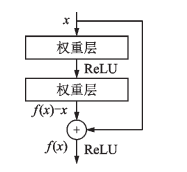
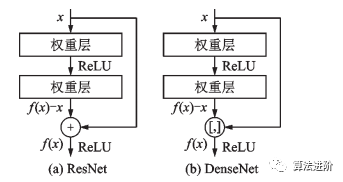
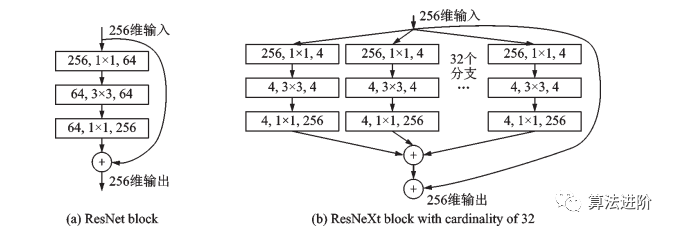
图7 ResNet残差模块和基数为 32 的 ResNeXt模块
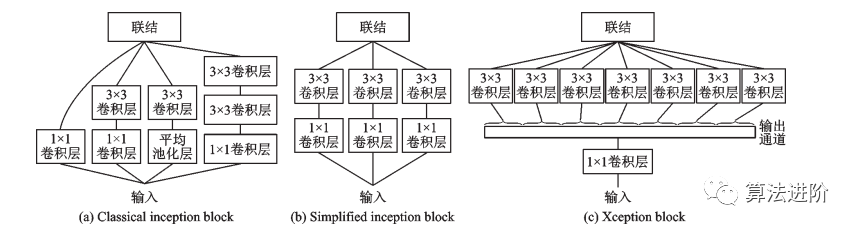
图8 经典及简化的 Inception 模块和 Xception 模块
生成模型能学习数据中隐含特征并对分布进行建模,应用于图像、文本、语音等,采样生成新数据。在深度学习前就有许多生成模型,因建模困难有挑战。
变分自编码器(Variationalautoencoder,VAE)是当前主流的基于深度学习技术的生成模型,是标准自编码器的一种变形,关注重构损失和隐向量的约束。通过强迫隐变量服从单位高斯分布,优化了以下损失函数:
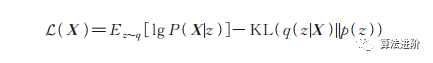
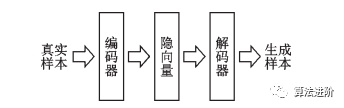
图9 自编码器示意图

图10 变分自编码器示意图
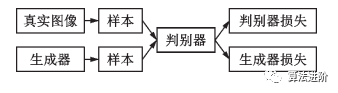
图11 生成对抗网络示意图
2 轻量化网络
轻量化网络是在保证模型精度前提下,降低计算和空间复杂度的深度神经网络,以便在计算和存储有限的嵌入式设备上部署,实现学术到工业的跃迁。目前,学术和工业界主要采用四种方法设计轻量化深度网络模型:人工设计的轻量化神经网络、基于神经网络架构搜索(Neural architecture search,NAS)的自动设计神经网络技术、卷积神经网络压缩和基于AutoML的自动模型压缩。这些方法旨在减少计算和存储需求,使深度学习模型能够在资源受限设备上运行。本节主要介绍人工设计的轻量化神经网络。
人工设计的轻量化神经网络是指通过手动设计网络结构和参数来减少模型的计算和存储需求的方法。这种方法通常需要深入理解深度神经网络的结构和参数,以及对不同任务的特征进行分析和提取。常见的人工设计的轻量化神经网络包括MobileNet、ShuffleNet、SqueezeNet等。
SqueezeNet是2016年伯克利和斯坦福的研究者提出的深度模型轻量化工作之一,结构如图12,其结构借鉴了VGG堆叠的形式,使用了Fire模块(如图13)来减少参数量。
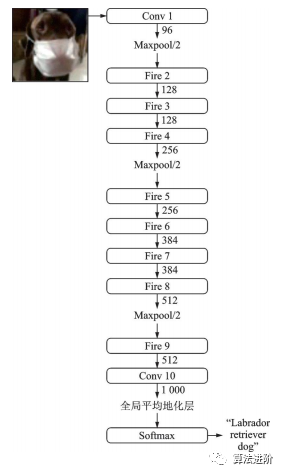
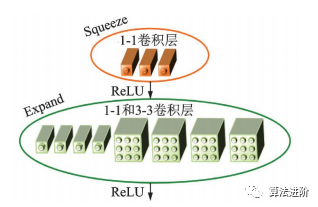
图13 SqueezeNet的 Fire 模块
MobileNet是谷歌于2017年提出的轻量化网络,核心是使用深度可分离卷积代替标准卷积,可以将计算量降低至原来的1/8~1/9。标准卷积和深度可分离卷积+BN+ReLU 结构如图 14 所示。
ShuffleNet晚于MobileNet两个月由Face++团队提出,ShuffleNet采用了ResNet的跳接结构,使用了Channel Shuffle(图15)和分组卷积的思想。ShuffleNet模块的设计借鉴了 ResNet bottleneck 的结构,如图 16 所示。
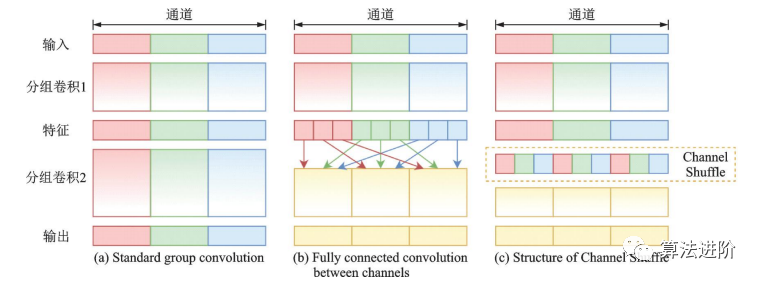
图15 Channel Shuffle 示意图
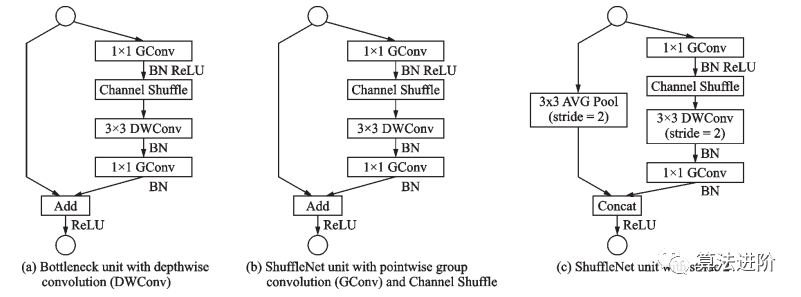
图16 ShuffleNet模块
2018年,MobileNet和ShuffleNet又相继提出了改进版本,MobileNetv2采用了效率更高的残差结构(图17),ShuffleNetv2采用了一种ChannelSplit操作。ShuffleNet v1 和 ShuffleNet v2 结构如图 18 所示。
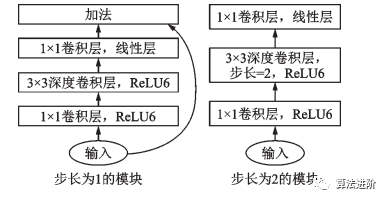
图17 MobileNet v2 模块
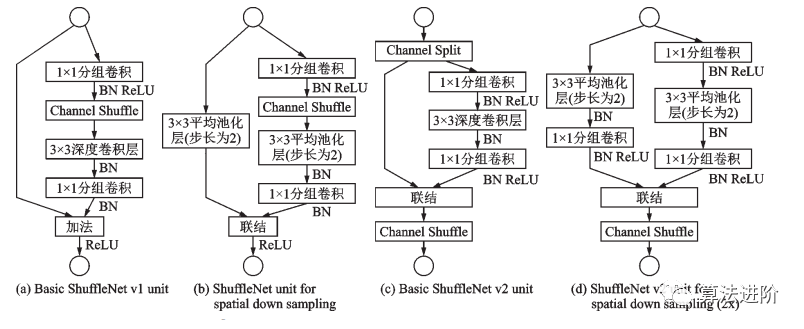
图18 ShuffleNet v1 和 ShuffleNet v2 结构
2020年,华为诺亚方舟实验室的团队提出了GhostNet,如图19所示。该网络用更少的参数量提取更多的特征图。Ghost模块通过一系列简单的线性操作生成特征图,模拟传统卷积层的效果,降低了参数量和计算量。
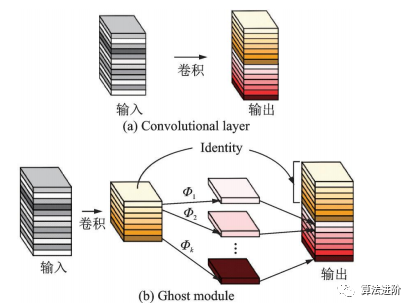
图19 卷积层和 Ghost模块
这些网络通过使用深度可分离卷积、通道重排、瓶颈结构等技术来减少模型的计算和存储需求,同时保持较高的精度。人工设计的轻量化神经网络通常具有较好的可解释性和可控性,但是需要大量的人力和经验来设计和优化网络结构和参数。
3 面向特定任务的深度网络模型
本节主要介绍特定计算机视觉任务的深度神经网络模型,包括目标检测、图像分割、图像超分辨率和神经架构搜索等。
3.1 目标检测
目标检测任务包括物体的分类、定位和检测。自2014年R-CNN模型提出后,目标检测成为计算机视觉热点。Girshick团队随后推出Fast R-CNN、Faster R-CNN等两阶段模型,将问题分为提出可能包含目标的候选区域和对这些区域分类。
R-CNN系列模型由共享特征提取子网和RoI预测回归子网组成。全卷积网络结构在性能更强的分类网络出现后应用于目标检测任务,但检测精度低于分类精度。R-FCN提出位置敏感分数图,增强网络对位置信息的表达能力,提高检测精度,结构如图20所示。
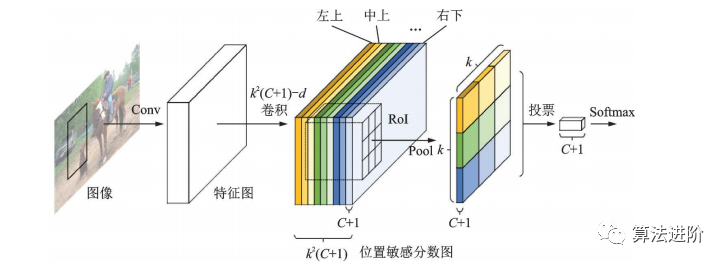
图20 R-FCN 结构示意图
如何准确识别不同尺寸的物体是目标检测任务的难点之一。不同方法包括提取不同尺度特征(图21(a))、单一特征图(图21(b))和多尺度融合(图21(c))。

图21 多尺度检测的常见结构
特征金字塔网络(FeaturePyramidnetwork,FPN)借鉴ResNet跳接思想,结合了层间特征融合与多分辨率预测,结构如图22。用于Faster R-CNN的RPN,实现多尺度特征提取,提高检测性能。实验证明FPN特征提取效果优于单尺度特征提取。
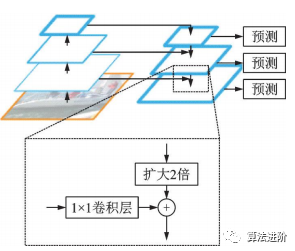
图22 FPN 结构示意图
YOLO是单阶段模型的代表,它将候选区域和分类统一为边界框回归问题,实现了端到端的学习,示意图如图23。它采用等分网格对图片进行划分,并运行单独的卷积网络进行预测,最后使用非极大值抑制得到最终的预测框。其损失函数包括坐标误差、物体误差和类别误差,并添加权重平衡类别不均衡和大小物体影响。YOLO网络结构图如图24。
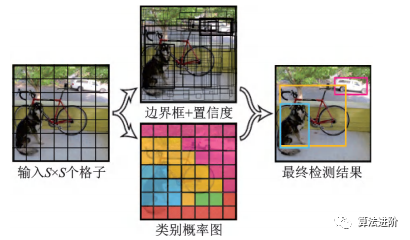
图23 YOLO 示意图
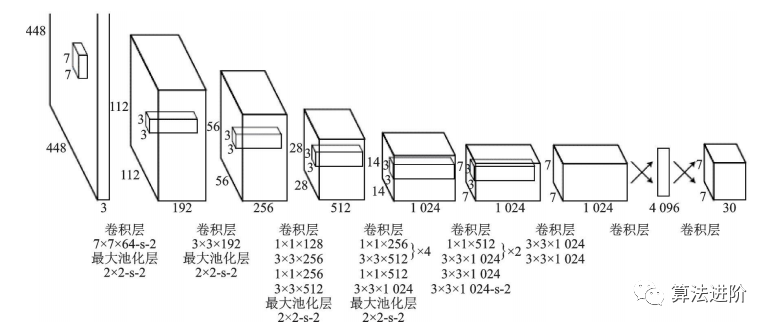
图24 YOLO网络结构图
YOLOv1的训练流程简单,背景误检率低,但由于每个格子只能预测出一个物体,限制了其检测能力。YOLOv2在YOLOv1的基础上采用了以VGG16为基础的Darknet19,借鉴了FasterR-CNN锚框的设计,并采用多尺度训练,提高了模型的健壮性。YOLOv3则采用了Darknet53作为骨干网络,引入了FPN结构,解决了小目标检测精度较差的问题,使得YOLO系列模型在单阶段检测方面更加强大和健壮。
SSD是最早达到两阶段模型精度的单阶段模型之一,结构如图25所示。为提高小目标检测精度,SSD采用多尺度特征图和更多预测框。

单阶段模型相比两阶段模型拥有更快的速度和更小的内存占用,最新的单阶段模型如FCOS、VFNet等工作已接近两阶段模型精度,更适合在移动端部署。目标检测技术从传统的手工特征算法发展到深度学习算法,精度和速度不断提升。工业界已经实现了多种基于目标检测技术的应用,如人脸检测识别、行人检测、交通信号检测、文本检测和遥感目标检测等。小目标检测和视频目标检测是未来的研究热点问题,目标检测的轻量化和多模态信息融合也是未来的研究方向。
图像语义分割任务,要求将图像像素分类为多个预定义类别。由于是像素级稠密分类,比图像分类和目标检测更困难。深度学习在计算机视觉领域取得成功,因此大量研究基于深度学习的图像分割方法。
2015年提出的U-Net和全卷积网络(Fully convolutional network,FCN)启发了图像分割和目标检测工作。U-Net是医学图像分割的卷积神经网络,赢得两项挑战赛冠军。U-Net为编码器-解码器结构,通过最大池化和上采样调整分辨率,结构如图26。卷积采用Valid模式,输出分辨率低于输入。U-Net采用跳接结构,连接上采样结果和编码器输出,作为解码器输入,融合高低分辨率信息,适用于医学图像分割。
图26 U-Net结构示意图
MaskR-CNN在FasterR-CNN基础上改进,实现像素级分类,拓展至图像分割。通过RoIAlign提高定位精度,添加二进制Mask表征目标范围。网络结构图和分支结构图如图27、28所示。
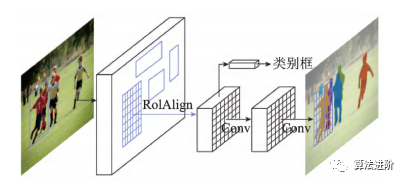
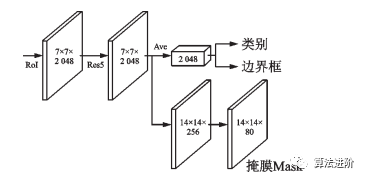
图28 Mask R-CNN 分支示意图
深度卷积神经网络中池化层和上采样层设计存在缺陷,导致图像分割精度受限。2016年DeepLab提出空洞卷积,避免信息损失,并使用全连接的条件随机场(Condi-tionalrandomfield,CRF)优化分割精度,结构如图29。空洞卷积增大感受野,不增加参数。DeepLabv1作为后处理,用条件随机场描述像素点关系,在分割边界取得良好效果。DeepLabv1速度快,平均交并比达71.6%,对后续工作产生深远影响。

2017年剑桥大学提出的SegNet,针对道路和室内场景理解,设计像素级图像分割网络,高效且内存、计算时间要求低。采用全卷积“编码器-解码器”结构,复用池化索引减少参数量,改善边界划分。在CamVid11RoadClassSegmentation和SUNRGB-DIndoorScenes数据集上表现优异。结构如图30所示。
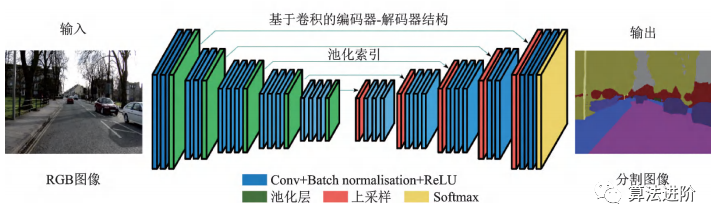
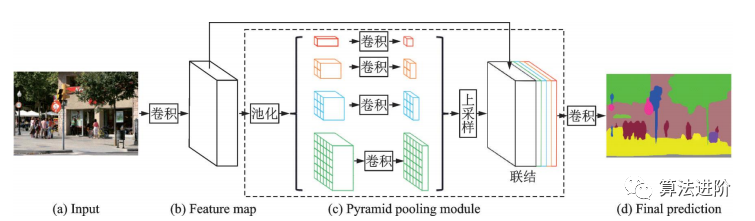
2017年香港中文大学提出PSPNet,采用金字塔池化模块,用不同尺度的金字塔提取信息,通过双线性插值恢复长宽,融合多尺度信息。PSPNet在PASCALVOC2012和MSCOCO数据集上分别达到82.6%和85.4%的mIoU。结构如图31。
DeepLabv2在DeepLabv1和PSPNet的基础上,使用ResNet101和ASPP模块提取特征图信息,增加了感受野,其结构如图32所示,mIoU达79.7%。DeepLabv3重新审视了空洞卷积的作用,将其应用在ResNet最后一个模块之后,并改进了ASPP模块(图33),去掉了后处理的DenseCRF模块,mIoU达86.9%。图34展示了不使用空洞卷积和使用空洞卷积的级联模块示意图。DeepLabv3+,结构如图35,相对于DeepLabv3采用了“编码器-解码器”的结构(图36),并将骨干网络替换为Xception,结合空洞深度可分离卷积,mIoU达89.0%。深度卷积、逐点卷积和空洞深度可分离卷积示意图如图 37所示。
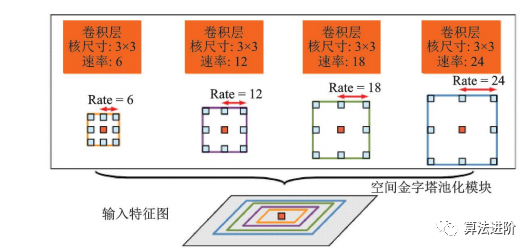
图32 空洞空间金字塔池化示意图
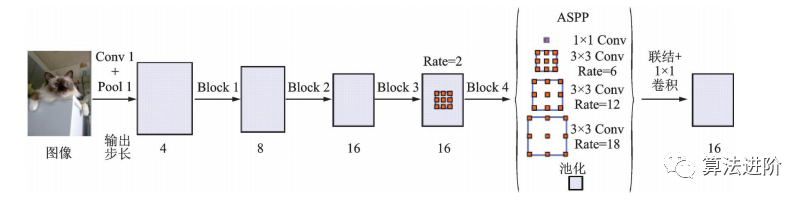
图33 改进的 ASPP 模块示意图
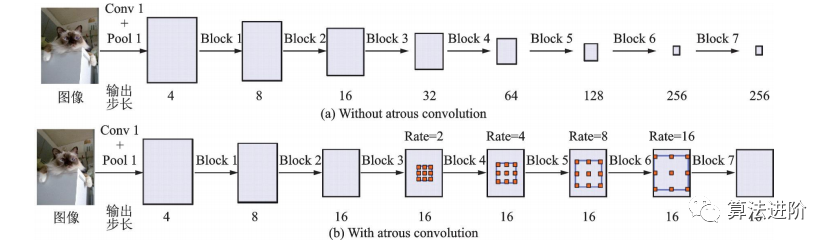
图34 不使用和使用空洞卷积的级联模块示意图
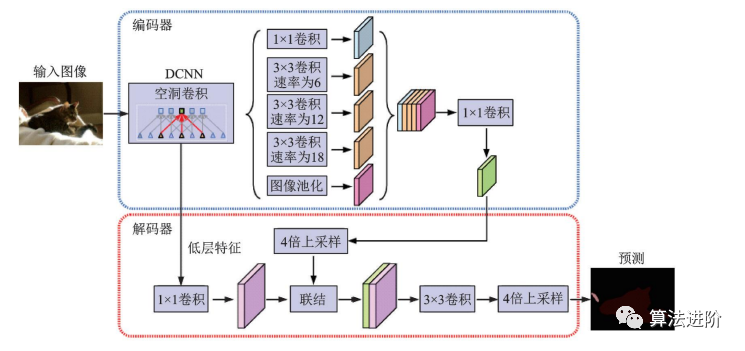
图35 DeepLabv3+示意图
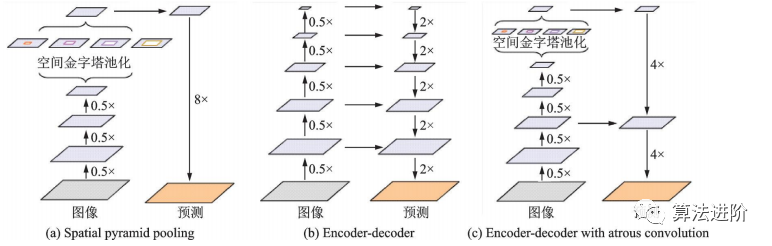
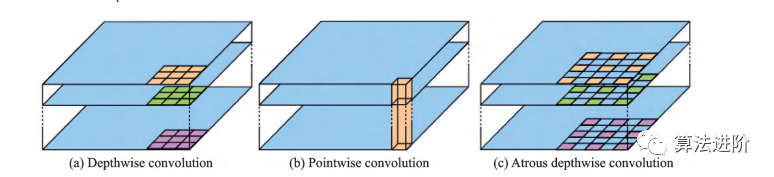
图37 空洞深度可分离卷积示意图
2019年,旷视科技提出DFANet高效CNN架构,通过子网和子级联聚合多尺度特征,减少参数量,结构如图38所示。采用“编码器-解码器”结构,解码器为3个改良轻量级Xception融合结构,编码器为高效上采样模块。
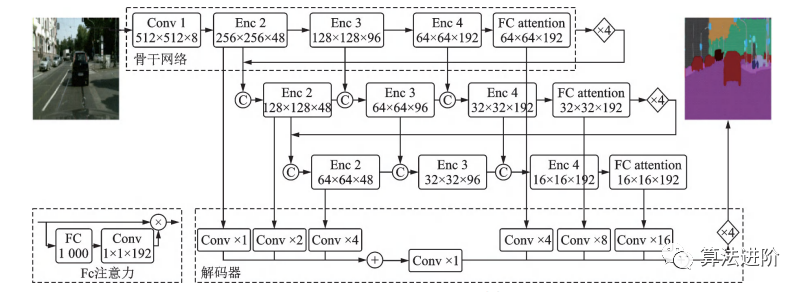
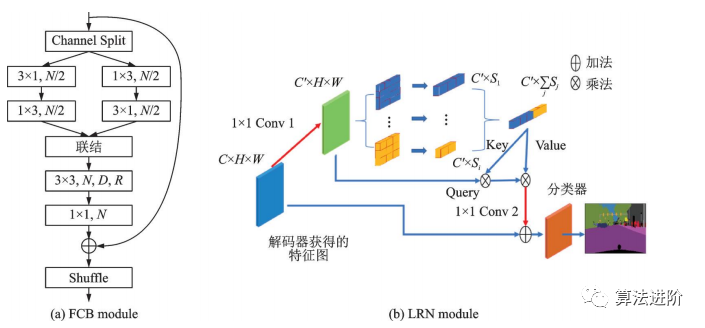
图39 LRNNet中的 FCB 和 LRN 模块
图像分割需要像素级稠密分类,真值标注耗时且昂贵。研究人员采用弱监督和半监督学习方法,使用图像类别标签、边界框、显著图和类激活图等弱标注训练网络。
2015年谷歌和UCLA团队最早研究基于弱监督学习技术的图像分割算法,基于DeepLab模型,研究了弱标注与少量强标注和大量弱标注混合对DCNN图像分割模型的影响,提出了一种期望最大化方法,证实了仅使用图像级标签的弱标注存在性能差距,在半监督设定下使用少量强标注和大量弱标注混合可以获得优越的性能。另一篇文献提出一个仅使用类别标签和显著图信息的图像分割模型,结构如图40所示。通过种子信息确定目标的类别和位置,测试精度mIoU达到56.7%。AffinityNet结合类别标签和CAM信息,通过构建图像的语义相似度矩阵,结合随机游走进行扩散,最终恢复出目标的形状。AffinityNet流程如图 41 所示。
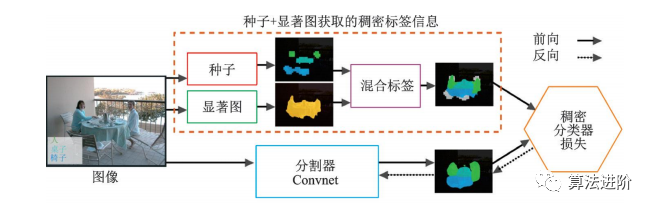
图40 高层信息指导的图像分割网络结构图
图41 AffinityNet流程示意图
超分辨率技术是计算机视觉领域提高图像和视频分辨率的关键处理技术,广泛应用于高清电视、监控视频、医学成像等领域。本文从图像分类、目标检测、图像分割到超分辨率,输出逐级复杂,最后生成比输入图像大的高分辨率图像,需要生成输入中不存在的信息。
超分辨率概念始于光学领域,1952年Francia提出,1964年Harris和Goodman提出Harris‑Goodman频谱外推方法,但实际效果不佳。1984年Tsai首次利用单幅低分辨率图像的频域信息重建高分辨率图像,超分辨率重建技术得到广泛认可和应用,成为图像增强和计算机视觉领域的重要研究方向。
传统的超分辨率方法包括基于预测、基于边缘、基于统计、基于块和基于稀疏表示等方法。根据输入输出的不同,超分辨率问题可以分为基于重建的超分辨率问题、视频超分辨率问题和单幅图像超分辨率问题。根据是否依赖训练样本,超分辨率问题则又可以分为增强边缘的超分辨率问题(无训练样本)和基于学习的超分辨率问题(有训练样本)。
插值法是最简单的单幅图像超分辨率方法,包括Lanczos、Bicubic、Bilinear和Nearest等,操作简单、实施性好,但难以恢复清晰边缘和细节。因此,许多传统算法被提出,以增强细节。其中,基于块的方法,利用局部线性嵌入重构高分辨率图像。基于稀疏表示的方法,将图像表示为字典D与原子α,用低分辨率图像得到α,重构高清图像。基于学习的超分辨率技术如图42所示,上、下采样方法示意图如图43所示。

图42 基于学习的超分辨率技术
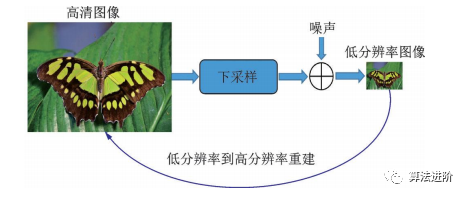
深度学习技术在超分辨率领域的应用研究。
香港中文大学Dong等于 2015年首次将卷积神经网络用于单幅图像超分辨率重建,提出了SRCNN。SRCNN激活函数采用 ReLU,损失函数采用均方误差,流程图如图44所示。
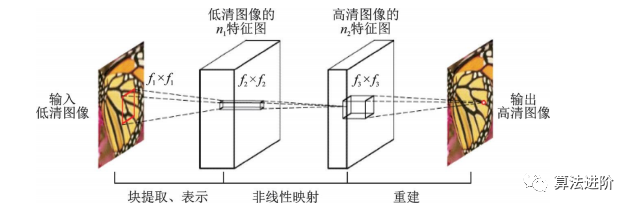
图44 SRCNN 流程图
2016年Dong团队提出了FSRCNN,这是一种更快、更实时的超分辨率卷积神经网络。FSRCNN在原始SRCNN的基础上,加入反卷积层放大尺寸,摒弃 Bicubic插值法,使用更多映射层和更小卷积核,改变特征维度并共享映射层,FSRCNN改进示意图如图45所示。
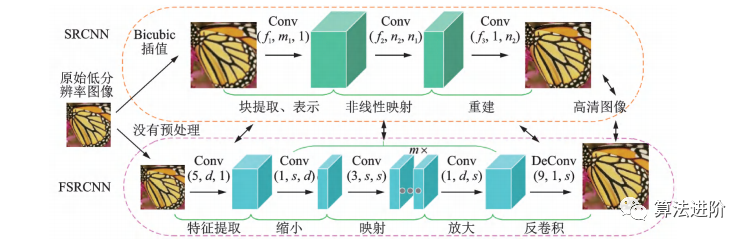
图45 FSRCNN 对 SRCNN 的改进
同年提出的ESPCN是一种基于SRCNN的超分辨率网络,结构如图46所示。主要特点是提高了速度,其引入了一种亚像素卷积层,直接在低分辨率图像上提取特征,降低计算复杂度。
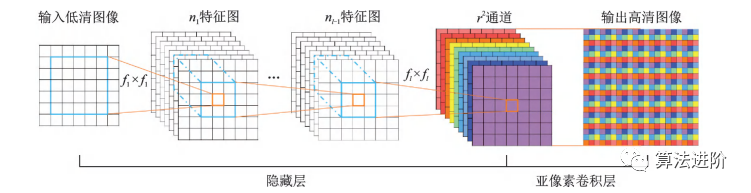
图46 ESPCN示意图
由于 SRCNN的计算复杂度高,FSRCNN和 ESPCN选择在网络末端上采样以降低复杂度。但上采样后没有足够深的网络提取特征,图像信息就会损失。为了解决这个问题,很多工作引入了残差网络。Kim等人在 2016年提出的 VDSR是第一个引入全局残差的模型,结构如图47。高低分辨率图像携带的低频信息很相近,因此网络只需要学习高频信息之间的残差即可。
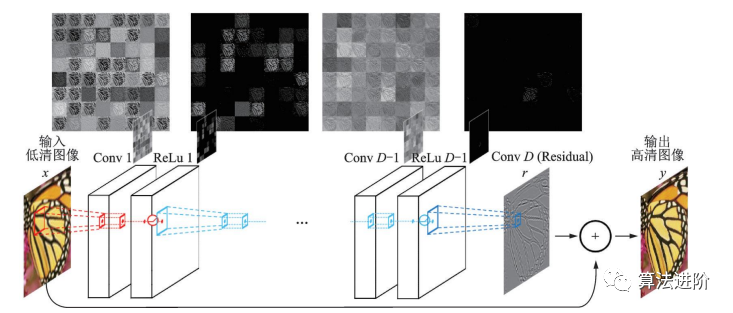
图47 VSDR 网络结构图
CARN是NTIRE2018超分辨率挑战赛冠军方案,采用全局和局部级联,用级联模块和1×1卷积模块替换ResNet残差块,并提出残差‑E模块提升效率。如图48和图49所示。
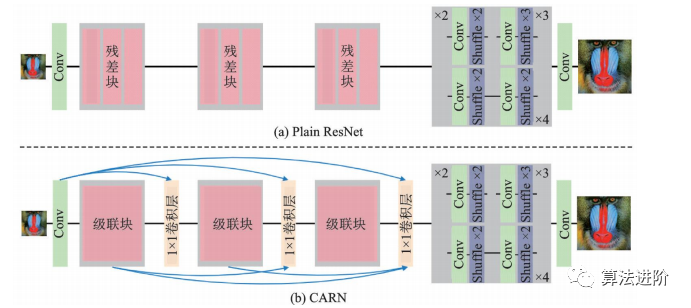
图48 CARN 对于 ResNet的改进
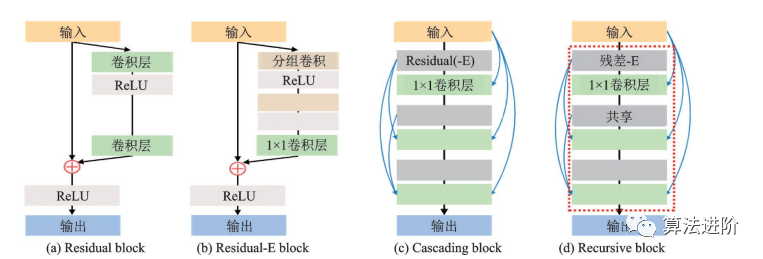
图49 残差-E 模块与其他常见模块的对比
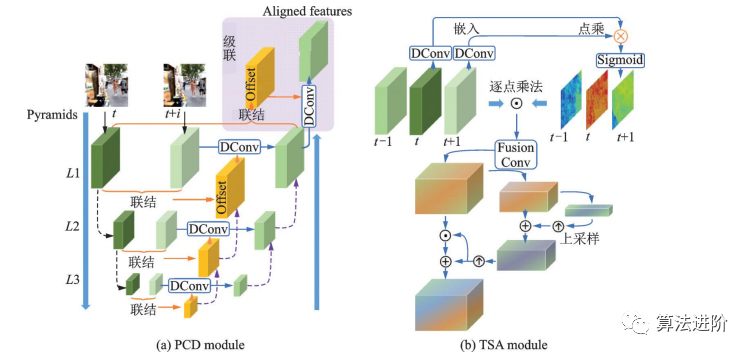
EDVR是商汤科技2019年提出的一种视频修复通用框架,在NITRE2019的4个赛道中均获得冠军。它通过增强的可变形卷积网络实现视频修复和增强,适用于各种视频修复任务。EDVR框架示意图如图50所示。EDVR提出了PCD对齐模块和TSA两个模块,结构如图51所示。PCD模块用可变形卷积将每个相邻帧与参考帧对齐,TSA模块用于在多个对齐的特征层之间融合信息。
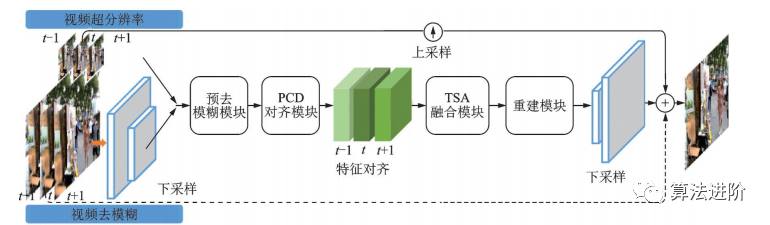
图50 EVDR 框架示意图
FSTRN(2019)将三维卷积用于视频超分辨率,通过分解三维滤波器降低复杂度,实现更深网络和更好性能。此外,提出跨空间残差学习方法,连接低分辨率空间和高分辨率空间,减轻计算负担。FSTRN结构如图52所示。

图52 FSTRN 结构示意图
深度学习技术的发展推动了超分辨率领域的快速进步,出现了许多性能优异的模型,但距离实际应用仍有差距。图像配准技术对多帧图像超分辨率重建效果至关重要,但目前还没有成熟的解决方案。另一难点是密集计算限制了视频超分辨率重建的计算效率,难以达到实时性要求。鲁棒性和可迁移性是未来的研究热点,现有的评价标准还不够客观,有时与人眼视觉相违背。
4 神经架构搜索
深度学习在图像分类、语音识别等领域取得显著成功。神经架构搜索技术(Neuralarchitecturesearch,NAS)可自动设计网络结构,如图像分割的Auto-DeepLab和目标检测的NAS-FPN。NAS是机器学习自动化的子领域,代表未来发展方向。流程包括搜索空间、搜索策略和性能评估,如图53所示。搜索空间包括网络架构参数和超参数,如卷积层、池化层等,典型的网络架构如图54所示。搜索策略有随机搜索、贝叶斯优化、遗传算法、强化学习等。性能评估需降低成本,可能导致偏差。更高级策略包括权重共享、通过迭代表现推断最终性能等。
DARTS是第一个基于连续松弛的搜索空间的神经网络架构技术,通过梯度下降优化网络在验证集上的性能,实现了端到端的网络搜索,大大减少了迭代次数,降低了搜索时间。DARTS流程包括:初始未知操作、候选操作的组合、双层规划问题联合优化混合概率与网络权重、用学到的混合概率求得最终的网络架构,如图55。DARTS适用于CNN和RNN,在CIFAR-10和PTB数据集上取得了优异性能,优于很多手工设计的轻量化模型。
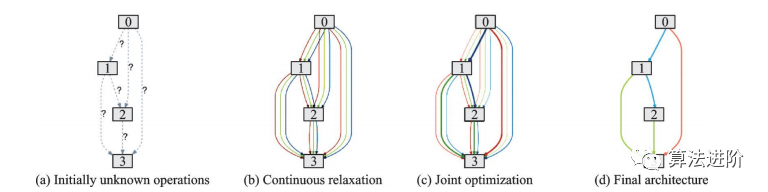
图55 DARTS流程示意图
基于DARTS,一系列改进算法相继提出,包括P-DARTS、ProxylessNAS、DARTS+和SNAS。P-DARTS采用渐进式搜索,逐步增加网络深度和减少候选操作数量,如图56所示。ProxylessNAS提出无代理神经架构搜索技术,降低显存需求,并首次提出针对特定时延的神经网络架构方法,如图57所示。DARTS+通过引入早停机制,缩短搜索时间并提高性能,如图58所示。SNAS将NAS重新表述为联合分布参数优化问题,直接优化损失函数,偏差更小。PC-DARTS在P-DARTS基础上设计了部分通道连接机制,节省训练资源,降低不确定性,取得更快更好的搜索效果,如图59所示。
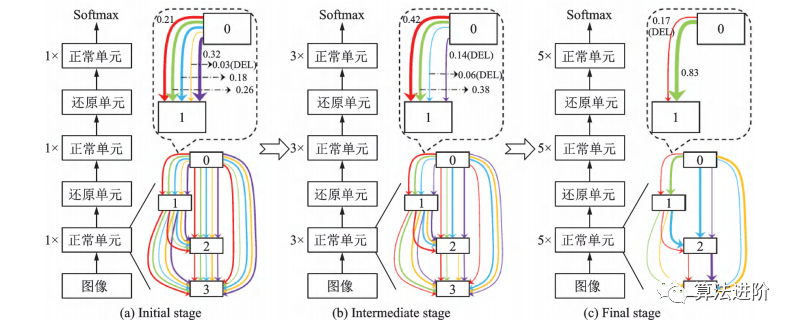
图56 P-DARTS 流程示意图

图57 ProxylessNAS 示意图
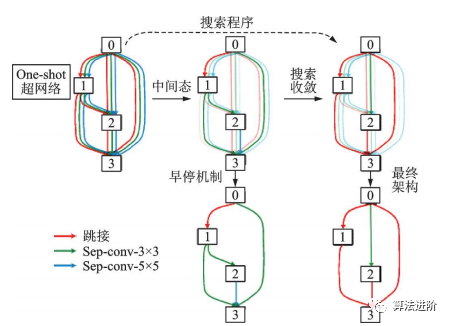
图58 DARTS+中的早停机制示意图
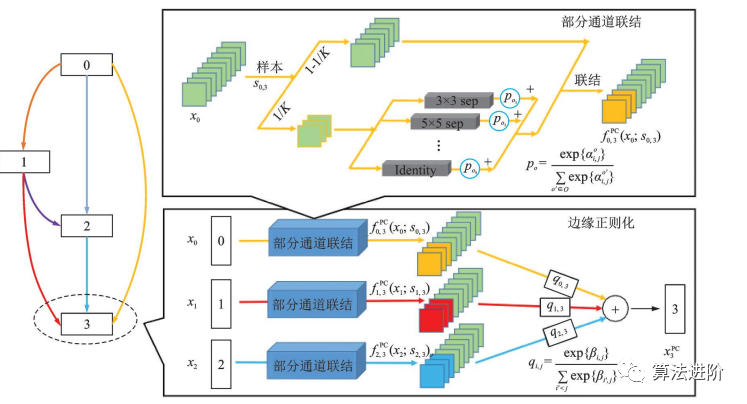
图59 PC -DARTS 结构示意图
神经架构搜索技术主要应用于图像分类任务,但搜索空间的定义限制了其设计出与人工网络有本质区别的网络。此外,NAS技术设计的网络可解释性差,不同研究者的方法不同,使得NAS设计出的架构难以复现和比较性能。因此,神经架构搜索领域仍面临挑战,如何解决这些问题将是未来的研究方向之一。
5 总结
深度学习在计算机视觉中的目标检测、图像分割、超分辨率和模型压缩等任务上取得卓越成绩,但仍存在难题,如对数据依赖强、模型迁移困难、可解释性不强。科技巨头投入巨型模型建设,如GPT的训练需要大量时间和计算资源。且深度学习依赖大规模带标签数据集,无监督学习和自监督技术是重要研究方向。同时,深度学习技术带来的安全隐患也引起重视,优化分布式训练是具有潜力的研究方向。
