
居然用 Numpy 实现了一个深度学习框架
今天跟大家分享一个牛逼的开源项目,该项目只用Numpy就实现了一个深度学习框架。
它不是一个demo, 而是一个实实在在能应用的深度学习框架,它的语法与PyTorch一致,用它可以实现CNN、RNN、DNN等经典的神经网络。
该框架对正在学习深度学习的朋友非常友好,因为它的代码量不到 2000 行,大家完全可以通过阅读源码来深入了解神经网络内部的细节。
如果大家读完源码自己也能做一个类似的深度学习框架,就更完美了。
1. 与 PyTorch 对比
接下来,我用该框架搭建一个简单的神经网络,并与PyTorch对比。
我们用这个神经网络来实现线性回归:
用下面的函数来生成训练样本
def synthetic_data(w, b, num_examples):
"""生成y=w1*x1+w2*x2+b训练样本"""
X = np.random.normal(0, 1, (num_examples, len(w)))
y = np.dot(X, w) + b
y += np.random.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
w = np.array([2, -3.4])
b = 4.2
features, labels = synthetic_data(w, b, 1000)
这里我们令w1=2、w2=-3.4、b=4.2,随机生成1000个训练样本,x1、x2存放在features变量中,y存放在labels变量中。
下面我们要做的是将这些样本输入神经网络中,训练出参数w1、w2和b,我们希望模型训练出来的参数跟实际的w1、w2和b越接近越好。
先用PyTorch来搭建神经网络,并训练模型。
from torch import nn, Tensor
import torch
# 只有一个神经元,并且是线性神经元
# 2代表有2个特征(x1、x2),1代表输出1个特征(y)
net = nn.Linear(2, 1)
print(f'初始w:{net.weight.data}')
print(f'初始b:{net.bias.data}')
# 用均方误差作为线性回归损失函数
loss = nn.MSELoss()
# 采用梯度下降算法优化参数,lr是学习速率
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
# 转 Tensor
X = Tensor(features)
y = Tensor(labels)
# 迭代次数
num_epochs = 300
for epoch in range(num_epochs):
l = loss(net(X), y) # 计算损失
trainer.zero_grad()
l.backward() # 反向传播,求导
trainer.step() # 更新参数
l = loss(net(X), y) # 参数更新后,再次计算损失
print(f'epoch {epoch + 1}, loss {round(float(l.data), 8)}')
print(f'模型训练后的w:{net.weight.data}')
print(f'模型训练后的b:{net.bias.data}')
这里我们用的是最简单的神经网络,只有一个神经元。
代码也比较简单,每行都做了注释。
输出的结果也是符合我们的预期,输出的损失如下:
epoch 1, loss 33.65092468
epoch 2, loss 29.78330231
epoch 3, loss 26.36030769
...
epoch 298, loss 0.0001022
epoch 299, loss 0.0001022
epoch 300, loss 0.0001022
前几轮损失比较大,等迭代300次后,损失已经非常小了。再看训练出来的参数:
初始w:tensor([[0.5753, 0.6624]])
初始b:tensor([-0.5713])
...
模型训练后的w:tensor([[ 1.9995, -3.4001]])
模型训练后的b:tensor([4.1998])
可以看到,经过训练后,模型的参数与设定的参数也是非常接近的。
下面,我们再用今天介绍的框架再来实现一遍。
from pydynet import nn, Tensor
from pydynet.optimizer import SGD
net = nn.Linear(2, 1)
print(f'初始w:{net.weight.data}')
print(f'初始b:{net.bias.data}')
loss = nn.MSELoss()
trainer = SGD(net.parameters(), lr=0.03)
X = Tensor(features)
y = Tensor(labels)
num_epochs = 300
for epoch in range(num_epochs):
l = loss(net(X), y) # 计算损失
trainer.zero_grad()
l.backward() # 反向传播,求导
trainer.step() # 更新参数
l = loss(net(X), y) # 参数更新后,再次计算损失
print(f'epoch {epoch + 1}, loss {round(float(l.data), 8)}')
print(f'模型训练后的w:{net.weight.data}')
print(f'模型训练后的b:{net.bias.data}')
代码从pydynet目录引入的,可以看到,用法跟PyTorch几乎是一模一样,输出参数如下:
初始w:[[-0.25983338]
[-0.29252936]]
初始b:[-0.65241649]
...
模型训练后的w:[[ 2.00030734]
[-3.39951581]]
模型训练后的b:[4.20060585]
训练出来的结果也是符合预期的。
2. 项目结构
pydynet项目架构如下:
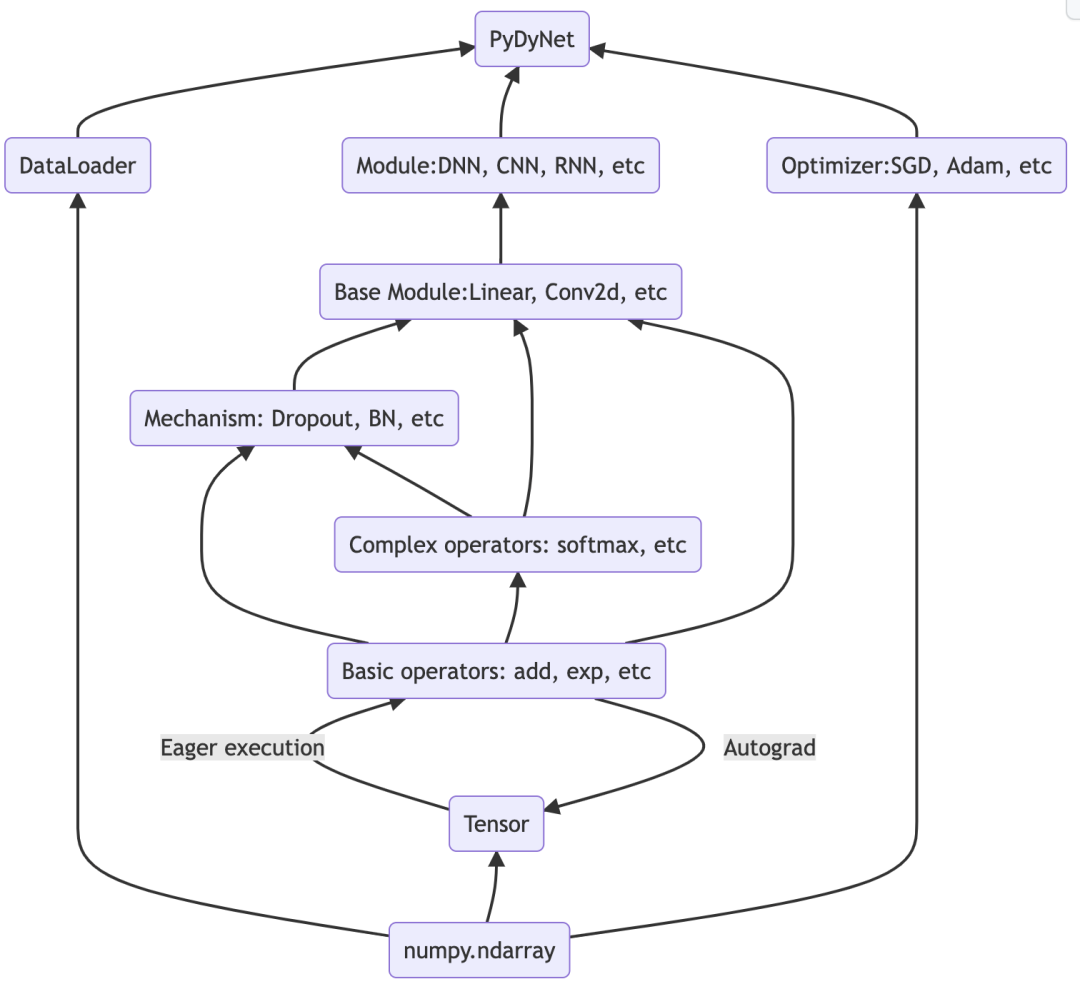
目前只有 5 个 Python源文件,不到 2000 行代码。
第一小节我们只实现最简单的神经网络,其他经典的神经网络,也有源码,大家可以自行查阅
项目地址:https://github.com/Kaslanarian/PyDyNet
我非常喜欢这个项目,佩服这个项目的作者。如果你也正好在学习人工智能,强烈建议学习学习这个项目。
希望今天的内容对你有用,感谢你的关注,我将持续分享优秀的 AI 项目。
--end-- 扫码即可加我微信
学习交流
老表朋友圈经常有赠书/红包福利活动