
如何掌握好图像分类算法?
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
大家好,这是专栏《AI有识境》的第一篇文章,讲述如何掌握好图像分类算法。
进入到有识境界,可以大胆地说自己是一个非常合格的深度学习算法工程师了,能够敏锐地把握自己研究的领域,跟踪前沿和能落地的技术,对自己暂时不熟悉的领域也能快速地触类旁通。
作为第一篇文章,我们讲解图像分类需要掌握的重要知识点。本文将带你走进图像分类的大门,着重关注该领域的研究方向以及重点难点,讲述如何学好图像分类算法。
作者&编辑 | 郭冰洋&言有三
1 简介
图像分类,即给定计算机一张图像,旨在让其判断出该图像的所属类别。它是计算机视觉领域的基础,更是重中之重。
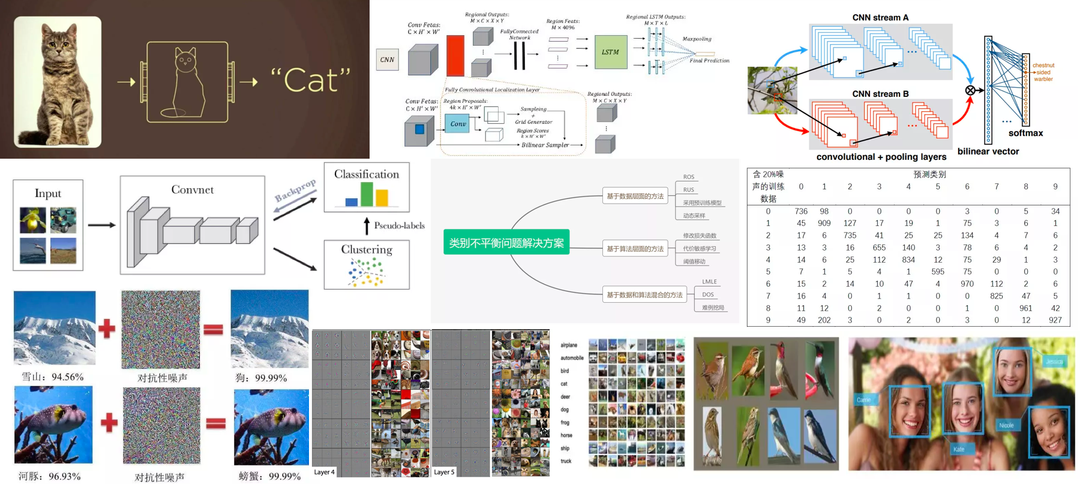
近年来,随着深度学习技术的兴起,图像分类领域得到了飞速的发展,并延申出一系列全新的研究方向,主要包括:
(1) 多类别图像分类;
(2) 细粒度图像分类;
(3) 多标签图像分类;
(4) 无/半监督图像分类;
(5) 零样本图像分类;
对人类而言,由于有大量的先验知识和相关的学习经验,可以迅速识别图像的相关内容。然而,对于计算机而言,提取并识别其中的特征是有挑战的。
目前存在的主要问题有:
(1) 遮挡:目标物体被遮挡某一部分
(2) 多视角:每个物体的呈现视角是多样的
(3) 光照条件:像素层级上而言,不同光照对识别的影响较大
(4) 样本量较少:某些图像的样本难以获取,导致样本过少
(5) 类内差异:某种类别下的物体差异性较大,比如桌椅等,呈现形式多样,不具备统一的特征
(6) 类别不平衡:数据集不同类别的样本数量差异较大
本文剩余部分将首先介绍分类任务的流程化处理,随后着重介绍每个研究方向的发展进程,并对其中难点问题的解决方法加以解读。
2 经典分类模型的发展简史
自深度学习发展以来,经过数十年的研究,衍生出了无数经典的分类模型。
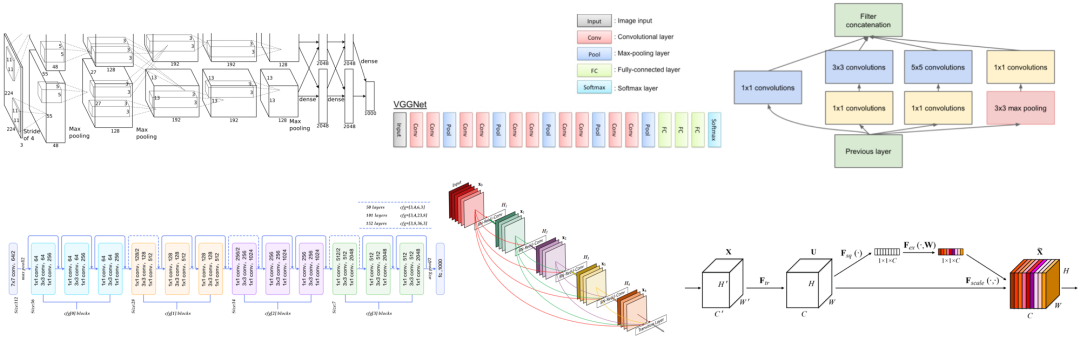
在上个世纪90年代末本世纪初,经典的手写字体识别MNIST数据集,被SVM和KNN为代表的传统算法统治,其错误率约为0.56%。彼时仍然超过以神经网络为代表的方法,即LeNet系列网络。LeNet[1]网络诞生于1994年,后经过多次的迭代才有了1998年的LeNet5,是为我们所广泛知晓的版本。
作为早期的分类网络,LeNet包含了现有CNN的核心模块。其中卷积层由卷积,池化,非线性激活函数构成。从1998年至今,经过20年的发展后,卷积神经网络依然遵循着这样的设计思想。其中,卷积发展出了很多的变种,池化则逐渐被带步长的卷积完全替代,非线性激活函数更是演变出了很多的变种。
在本世纪的早期,神经网络开始有复苏的迹象,但是受限于数据集的规模和硬件的发展,神经网络的训练和优化仍然是非常困难的。
后来在李飞飞等人数年时间的整理下,2009年,ImageNet数据集发布了,并且从2010年开始每年举办一次ImageNet大规模视觉识别挑战赛,即ILSVRC。竞赛初期,仍以SVM和Boost等传统算法为主,直到2012年AlexNet的横空出世。
AlexNet[2]是第一个真正意义上的深度网络,与LeNet5的5层相比,它的层数增加了3层,网络的参数量也大大增加,输入也从28变成了224,同时GPU的面世,也使得深度学习从此进行GPU为王的训练时代。
AlexNet在LeNet5的基础上进行改进,包括5个卷积层和3个全连接层。使用Relu激活函数,收敛很快,解决了Sigmoid在网络较深时出现的梯度弥散问题。同时加入了Dropout层,防止过拟合。此外,还使用了LRN归一化层,对局部神经元的活动创建竞争机制,抑制反馈较小的神经元放大反应大的神经元,增强了模型的泛化能力。由于算力限制,AlexNet创新性的采用两块GPU分块运算,并通过全连接的层将两个分支的结果进行融合。
2014年的冠亚军网络分别是GoogLeNet[3]和VGGNet[4]。
其中VGGNet包括16层和19层两个版本,共包含参数约为550M。全部使用3×3的卷积核和2×2的最大池化核,简化了卷积神经网络的结构。VGGNet很好的展示了如何在先前网络架构的基础上通过简单地增加网络层数和深度就可以提高网络的性能。虽然简单,但是却异常的有效,在今天,VGGNet仍然被很多的任务选为基准模型。
GoogLeNet是来自于Google的Christian Szegedy等人提出的22层的网络,其top-5分类错误率只有6.7%。
GoogleNet的核心是Inception Module,它采用并行的方式。一个经典的inception结构,包括有四个成分。1×1卷积,3×3卷积,5×5卷积,3×3最大池化,最后对四个成分运算结果进行通道上组合。这就是Inception Module的核心思想。通过多个卷积核提取图像不同尺度的信息然后进行融合,可以得到图像更好的表征。自此,深度学习模型的分类准确率已经达到了人类的水平(5%~10%)。与VGGNet相比,GoogleNet模型架构在精心设计的Inception结构下,模型更深又更小,计算效率更高。
2015年,ResNet[5]获得了分类任务冠军。它以3.57%的错误率表现超过了人类的识别水平,并以152层的网络架构创造了新的模型记录。由于ResNet采用了跨层连接的方式,它成功的缓解了深层神经网络中的梯度消散问题,为上千层的网络训练提供了可能。
在ResNet基础上,密集连接的DenseNet[6]在前馈过程中将每一层与其他的层都连接起来。对于每一层网络来说,前面所有网络的特征图都被作为输入,同时其特征图也都被后面的网络层作为输入所利用。
DenseNet中的密集连接还可以缓解梯度消失的问题,同时相比ResNet,可以更强化特征传播和特征的复用,并减少了参数的数目。DenseNet相较于ResNet所需的内存和计算资源更少,并达到更好的性能。
2017年,也是ILSVRC图像分类比赛的最后一年,SeNet[7]获得了冠军。这个结构,仅仅使用了注意力机制对特征进行处理,通过学习获取每个特征通道的重要程度,根据重要性去降低或者提升相应的特征通道的权重。
至此,图像分类的比赛基本落幕,也接近算法的极限。但是,在实际的应用中,却面临着比比赛中更加复杂和现实的问题,需要大家不断积累经验。
3 如何完成一个图像分类任务
3.1 构建流程化处理模式
初学者在入门阶段,需要构建流程化处理的思维模式,将一个完整的任务进行拆解,并对其中的各个流程加以掌握。一个完整的图像分类任务,包括以下几个流程:
(1) 选择开源学习框架
本流程需要掌握主流的深度学习框架,常见的包括Tensorflow、Pytorch、Mxnet等。此外,还需要掌握Linux开发指令以及相应的编程技巧。
(2) 构建数据集并读取数据
图像分类作为数据驱动的任务,高质量的数据集是准确率的保证。因此,在明确任务需求的初期,就需要着手构建内容清晰、符合实际的数据集,并将其划分为训练集、验证集和测试集。此外,还要根据数据集的格式,结合不同的学习框架,完成对数据集的读取,保证每张图片以张量的形式,送入训练网络。
(3) 网络模型选择
在选择训练网络时,需要根据现有的研究内容和成果进行筛选。在选定的基础网络结构上进行实验和改进,进一步提升网络的性能。
(4) 训练及参数调试
选择合适的学习率、优化方式、损失函数进行训练,并可以借助不同的数据增强方式,进一步提升模型对数据的敏感力。参数的选择是否合适,可以通过训练集和验证集的结果对比进行调试。
(5) 测试
在测试集上达到精度要求后,对模型完成进一步的部署。
3.2 进一步提高分类任务的质量
分类精度的提高主要可以从数据集、网络结构和调参三个方面入手。
(1) 数据集:质量高、目标清晰
(2) 网络结构:根据不同任务进行针对性的选择,务必根据现有的研究选取合适的结构,不可以盲目猜想
(3) 调参:针对任务需求选择合适的损失函数,并选择合适的学习率和优化方式
4 分类损失函数
作为网络模型的优化目标,合理的损失函数可以提高最终的准确率。常见的分类损失函数主要包括0-1损失函数、交叉熵损失函数等等。
0-1损失函数:计算n个样本上的0-1分类损失的和或者平均值。
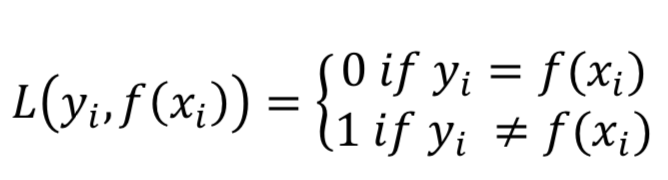
交叉熵损失函数:图像分类任务中最常用的损失函数,定义在概率分布基础上的,通常用来度量分类器的预测输出的概率分布与真实分布的差异,令n对应于样本数量,m是类别数量,yij 表示第i个样本属于分类j的标签,它是0或者1,f(xij)是预测第i个样本属于分类j的概率。
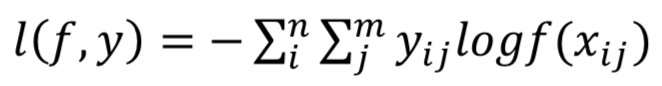
Hinge损失函数:计算模型与数据之间的平均距离,是一个仅仅考虑了预测误差的单边度量。通常被用于最大间隔分类器。
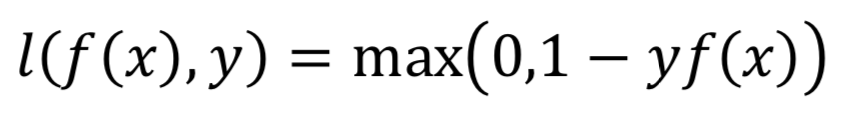
多标签分类任务函数:多标签分类任务与单分类任务不同,每一张图像可能属于多个类别,因此需要预测样本属于每一类的概率值,sigmoid cross_entropy_loss通常被用于多标签分类任务,单个样本的损失定义如下:
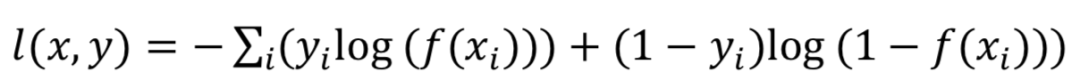
汉明距离损失函数:将预测的标签集合与实际的标签集合进行对比,按照汉明距离的相似度来衡量。汉明距离的相似度越高,即汉明损失函数越小,则模型的准确率越高,也常用于多标签分类任务,∆Y表示距离。
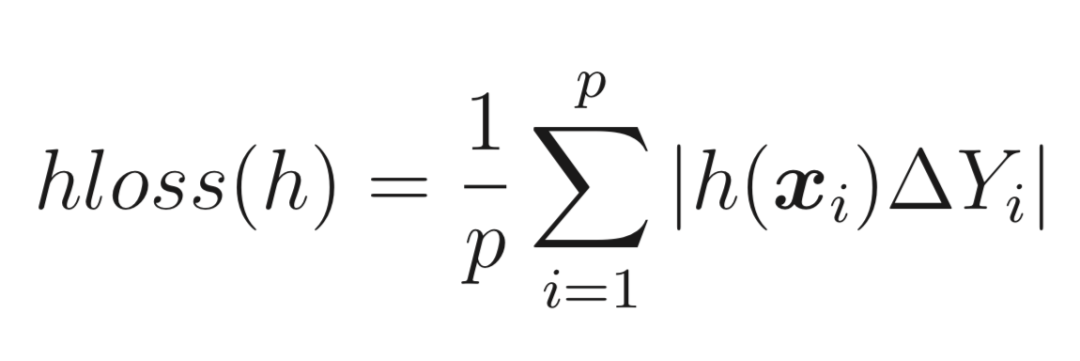
5 图像分类的不同研究方向
5.1 多类别图像分类

多类别图像分类作为图像分类的最基础研究,其目的是将若干不相关类别的图像进行分类。随着深度学习的发展,已经由原有的特征提取方式,转化为数据驱动的深度学习方式,并得到了极大的发展。现有的经典网络,如VGG、ResNet、SENet等均是在此基础上研究而来。对于该方向的研究,笔者建议对经典文章进行精读,并掌握其中经典结构的设计思想。
5.2 细粒度图像分类

细粒度分类即在区分出基本类别的基础上,进行更精细的子类划分,如猫的品种、车的品牌等等。相较于多类别图像分类,细粒度图像具有更加相似的外观和特征,导致数据间的类内差异较大,分类难度也更高。
现有的解决方案主要包括线性网络结构、额外标注信息和注意力机制。
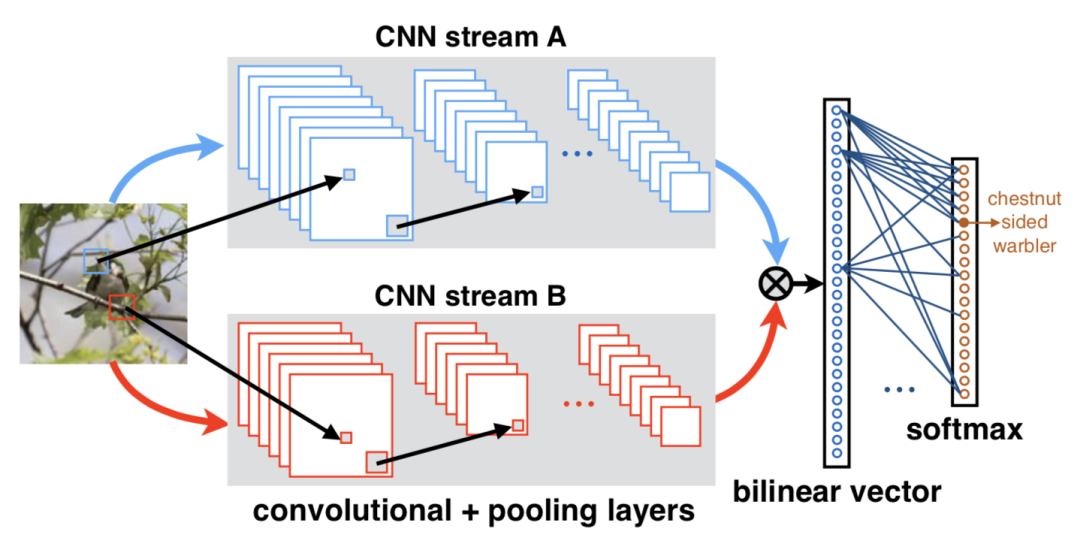
Lin等[8]提出了双线性卷积神经网络结构(Bilinear CNN),通过不同的分支提取到两个特征向量,如KxN和KxM,通过池化函数将两个特征汇聚成MxN的特征向量,即包含了图像的特征信息和位置信息,达到互补的目的。
还有的方法通过引入bounding box和key point等额外的人工标注信息,通过R-CNN提取相关的区域信息,对其进行特征修正,送入相应的分类器进行训练。
还有的方法通过引入视觉注意力机制(Vision Attention Mechanism),在CNN内部嵌入注意力模块,定位图像中有区分性的区域,无需引入额外的标注信息。
详细了解细粒度分类,请阅读:【图像分类】细粒度图像分类是什么,有什么方法,发展的怎么样
5.3 无监督/半监督图像分类
顾名思义,不借助类别标签或只借助部分类别标签对图像完成分类,属于图像分类中较难的任务类型,现阶段的解决方案大都是传统聚类算法与深度学习的融合。
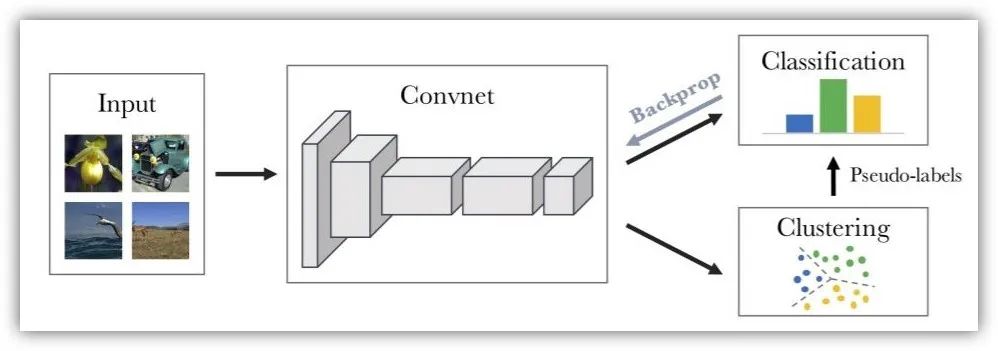
Deep Clustering[9]通过CNN提取图像的特征信息,然后通过K-means算法对特征进行聚类,并赋予相应的伪标签,再用伪标签进行相应的分类训练。

牛津大学构建了信息不变性聚类网络(Invariant Information Clustering CNN)[10],将原有的图像进行平移、旋转得到新的图像,原有图像和新图像输入同一CNN,获得的特征信息相匹配的,则聚合为一类。
详细了解无监督分类,请阅读:【图像分类】简述无监督图像分类发展现状
5.4 多标签图像分类
现实生活中的图像往往包含多个目标,并非只包含单一种类的物体。针对此问题,多标签分类应运而生。其需要对含有多个目标的图像进行分类,准确识别出多个类别。常见的解决方案主要包括以下几点:
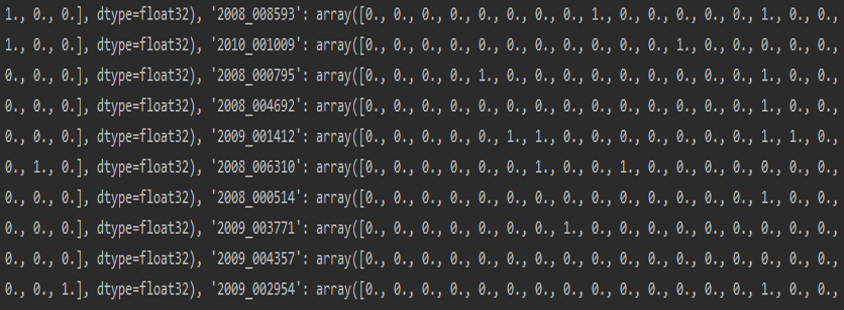
标签转化:假定多标签分类任务中共有N个标签,则针对每张图片,将其标签转化为Nx1的向量,如[1,1,0,…,1,0],同时使用汉明距离作为损失函数,这一方法简单便捷,只需要在标签格式上进行处理。
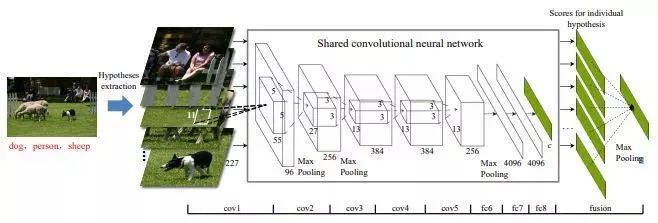
原图拆分:根据BING理论将图像生成若干含有标签的区域图像,将区域图像送入单标签分类网络得到分类结果,随后将每个区域图像的结果进行融合得到最终结果。
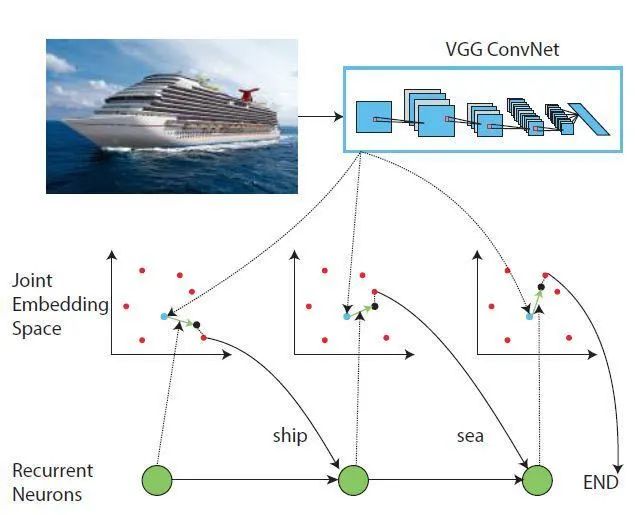
添加词向量:通过添加一定的词向量对不同的类别进行描述,首先利用CNN对图像进行特征提取,随后利用RNN构建图像特征与词向量之间的关系,可以充分考虑类别之间的相关性。
详细了解多标签分类,请阅读:【技术综述】多标签图像分类综述
5.5 零样本图像分类

在传统的分类模型中,为了解决多分类问题(例如三个类别:猫、狗和猪),就需要提供大量的猫、狗和猪的图片用以模型训练,然后给定一张新的图片,就能判定属于猫、狗或猪的其中哪一类。但是对于之前训练图片未出现的类别(例如牛),这个模型便无法将牛识别出来,而零样本分类就是为了解决这种问题。在零样本分类中,某一类别在训练样本中未出现,但是我们知道这个类别的特征,然后通过语料知识库,便可以将这个类别识别出来。
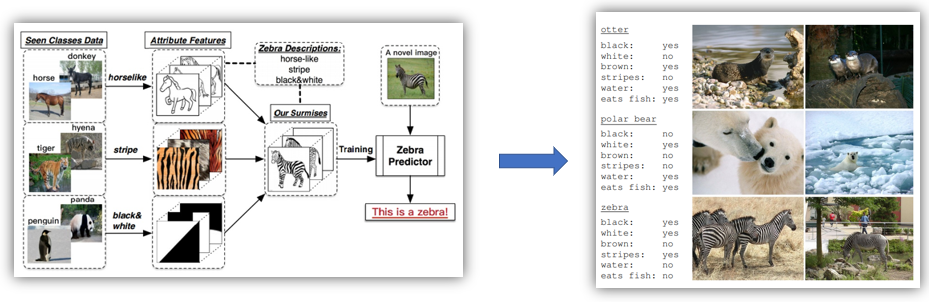
利用若干学习器去学习斑马的相关特征,随后输入斑马的图片。如果此时我有一张表,这张表里记录着每一种动物这三种属性的取值,我们就可以通过查表的方式,将这张图片对应到斑马这一类别这里的属性表。相关属性表是事先总结好的,因为收集大量的未知类别的图片是困难的,但是仅仅总结每一类别相应的属性却是可行的。
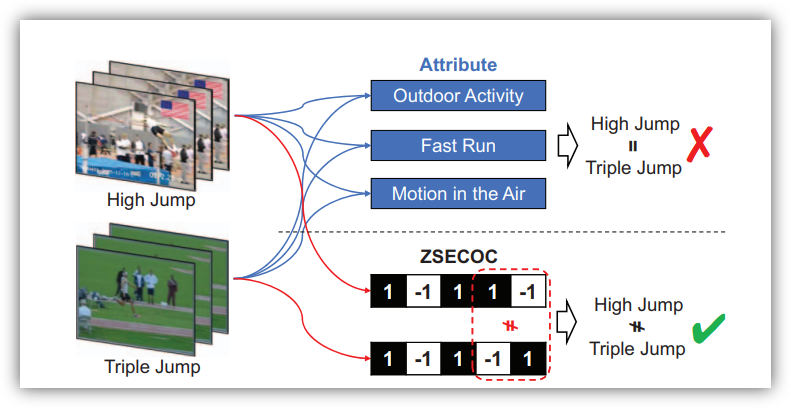
通过构建词向量(word2vec)的方式,将自然语言中的字词转化为计算机可以理解的数字向量,结合图像和相应的词向量训练学习器。在测试阶段,输入测试的图像,输入预测的词向量,从而得到预测结果与相应类别的距离,距离最近的则为所属类别。
6 如何解决类别不平衡
构建数据集时,不同类别下的样本数目相差过大,从而导致分类模型的性能变差。现有的解决方案包括以下几类:
优化目标设计法:优化目标设计主要是通过修改损失和函数对不同类别进行不同的加权或者归一化处理,比如在交叉熵中添加类别权重。
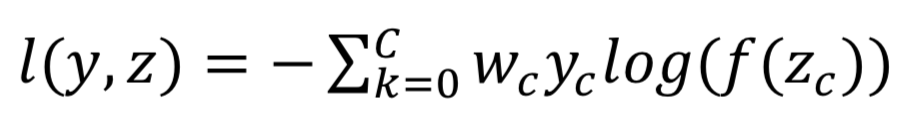
提升样本(over sampling)法:即对于类别数目较少的类别,从中随机选择一些图片进行复制并添加至该类别包含的图像内,直到这个类别的图片数目和最大数目类的个数相等为止。通过实验发现,这一方法对最终的分类结果有了非常大的提升。
在这个基础上进行改进的方法是动态采样(dynamic sampling)法:该方法根据训练结果对数据集进行动态调整,对结果较好的类别进行随机删除样本操作,对结果较差的类别进行随机复制操作,以保证分类模型每次学习都能学到相关的信息。
两阶段(two-phase)训练法:首先根据数据集分布情况设置一个阈值N,通常为最少类别所包含样例个数。随后对样例个数大于阈值的类别进行随机抽取,直到达到阈值。此时根据阈值抽取的数据集作为第一阶段的训练样本进行训练,并保存模型参数。最后采用第一阶段的模型作为预训练数据,再在整个数据集上进行训练,对最终的分类结果有了一定的提升。
详细了解类别不平衡问题,请阅读:【图像分类】 关于图像分类中类别不平衡那些事
7 如何解决样本量过少的问题
在构建数据集时,由于某些图片的采集难度交大或存在状况较少,往往会导致样本量过少,这一现象同样会导致分类模型的性能降低。现有的解决方案主要包括以下几类:
采用预训练模型:使用在大量样本下足够训练的模型,如果模型的训练数据足够大,且跟你所需求的任务相匹配,那么可以理解为该预训练模型所学到的特征具备一定的通用性。
降低模型复杂度:在样本量过少的情况下,现有的数据无法满足网络模型的庞大参数,因此可以对所用模型进行简化。
数据增强:包括平移、翻转、亮度、对比度、裁剪、缩放等。
详细了解数据增强技术,请阅读:【技术综述】深度学习中的数据增强方法都有哪些?
8 图像分类的相关竞赛与数据集
自图像分类兴起以来,各行各业均提出了自身的需求,并举办很多图像分类的竞赛,提出了各种数据集。
8.1 竞赛
其中,最著名的即ImageNet分类竞赛,自2009年李飞飞团队发布了ImageNet数据集以来,从2010年开始每年举办一次ImageNet大规模视觉识别挑战赛,即ILSVRC。该竞赛于2017年正式结束。八年间,该竞赛大大促进了图像分类领域的发展,并有无数经典的网络得以提出。
2011 年,谷歌开始赞助举办第一届FGVC Workshop,之后每两年举办一次,到 2017 年已经举办了四届。由于近年来计算机视觉的快速发展,FGVC 活动影响力也越来越大,自2018年开始由两年一次改为了一年一次。FGVC竞赛侧重于子类别的详细划分,每届赛事都包含了多个主题,涵盖了动物种类、零售产品、艺术品属性、木薯叶病、腊叶标本的野牡丹科物种、来自生命科学图片的动物物种、蝴蝶和蛾物种、菜肴烹饪以及博物馆艺术品等多个事物的细粒度属性。
除此了上述两个大型竞赛以外,Kaggle和阿里天池也同样举办了若干图像分类竞赛,不仅解决了实际的应用问题,也进一步促进了分类模型的研究发展。
8.2 数据集
俗话说:巧妇难为无米之炊。数据作为驱动深度学习的源动力之一,更是图像分类任务的根基,直白来说,任何领域的分类研究都离不开数据。
不论学界还是工业界,确定特定的研究方向后,必须搭建相关的高质量数据集才可以进行进一步的研究,同时也能以更统一的标准对模型性能进行评判。
下面根据应用场景的不同,汇总了9个相关领域的数据集,并根据数据集自身特点,注明其容量、类别和适用的分类任务,以供大家参考使用。
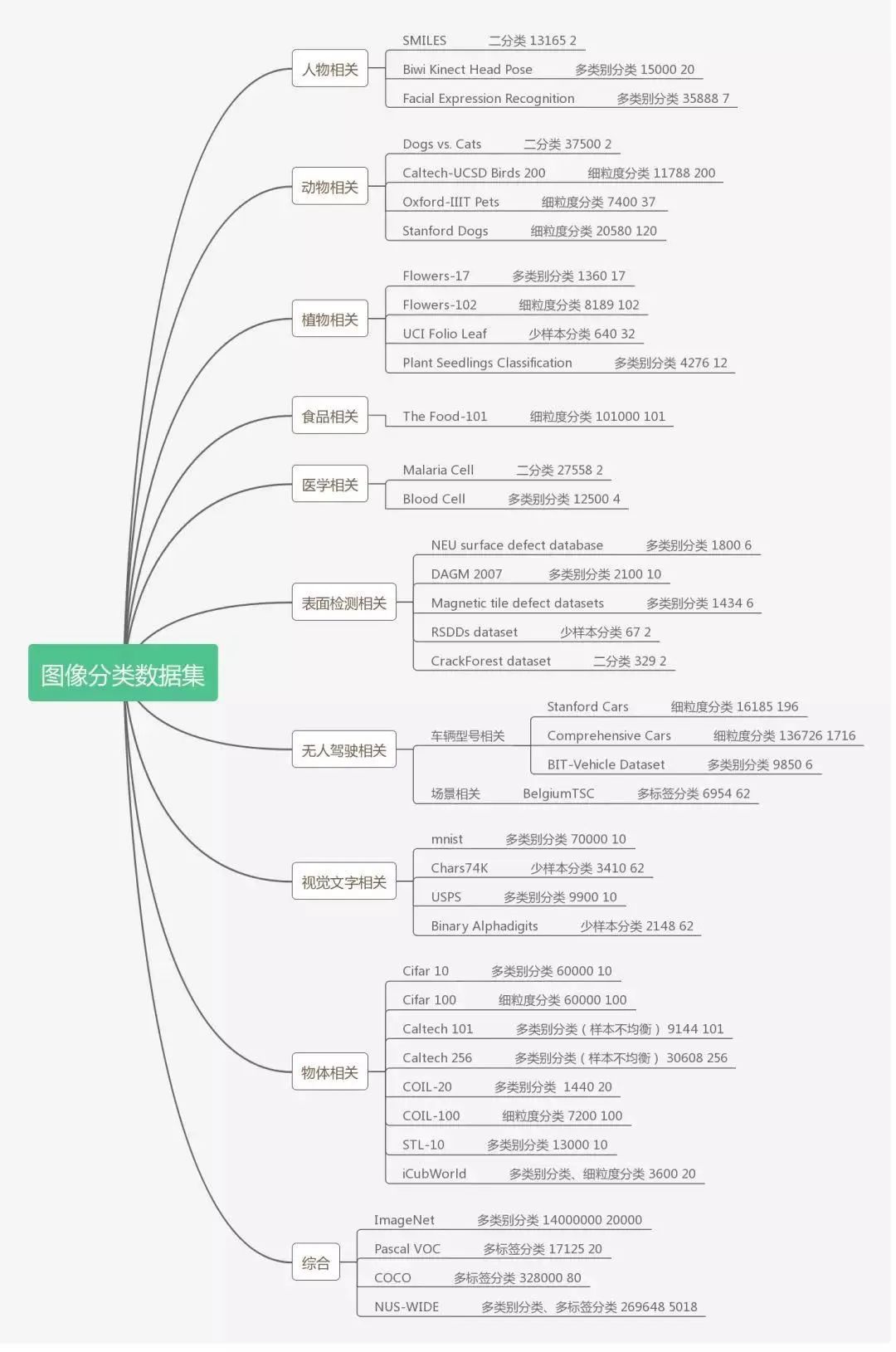
初入图像处理领域的同学,主要以MNIST、CIFAR 10数据集进行练手,可以帮助新手迅速了解神经网络的构成,同时掌握深度学习和图像处理的相关基础知识。
对于已经有一定基础的同学,需要通过更多的实操来强化对不同结构和知识的理解以及应用,并实现调参、数据处理、网络结构替换等更高一层的任务,CIFAR 100、表情分类相关的数据集则是其中代表。
对于经过多个任务历练,需要根据实际需求和科研方向来选择数据集的同学,这就涉及到多标签分类、细粒度分类和少样本分类等更复杂的任务,也就需要选择Pascal VOC、ImageNet等更高层级的数据集,同时还有可能同时利用这些数据集,从中选取合适的图像以搭建满足自己需求的数据。
9 参考资料
最后,我们来汇总一下有三AI生态中掌握好图像分类任务可以使用的相关资源。
(1) 图像分类专栏,本专栏详解了图像分类的各领域关键技术。

(2) 书籍《深度学习之图像识别:核心技术和与案例实战》和《深度学习之模型设计:核心算法与案例实践》,前者详解了图像分类中的核心算法,后者详解了各种各样的模型设计思想。

[1] Lecun Y , Bottou L . Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
[2] Krizhevsky A , Sutskever I , Hinton G . ImageNet Classification with Deep Convolutional Neural Networks[C]// NIPS. Curran Associates Inc. 2012.
[3] Szegedy C , Liu W , Jia Y , et al. Going Deeper with Convolutions[J]. 2014.
[4] Krizhevsky A , Sutskever I , Hinton G . ImageNet Classification with Deep Convolutional Neural Networks[C]// NIPS. Curran Associates Inc. 2012.
[5] He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. 2015.
[6] Huang G , Liu Z , Laurens V D M , et al. Densely Connected Convolutional Networks[J]. 2016.
[7] Hu J , Shen L , Albanie S , et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
[8] Lin T Y , Roychowdhury A , Maji S . Bilinear CNN Models for Fine-grained Visual Recognition[J]. 2015.
[9] Bhatnagar B L , Singh S , Arora C , et al. Unsupervised Learning of Deep Feature Representation for Clustering Egocentric Actions[C]// IJCAI. 2017.
[10] Ji X , Vedaldi A , Henriques J . Invariant Information Clustering for Unsupervised Image Classification and Segmentation[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019.
[11]言有三.深度学习之图像识别:核心技术和与案例实战[M].机械工业出版社:北京,2019:5.
[12] 言有三.深度学习之模型设计:核心算法与案例实践[M].电子工业出版社:北京,2020:6.
图像分类作为计算机视觉领域的基础任务之一,是其他计算机视觉任务的研究基础,更是进入该领域的敲门砖。因此,掌握图像分类的基础知识,会帮助你更快地开展学习任务。本文所涵盖的内容并非全面,但仍希望能在你初学的道路上给予一定的帮助!