
一听就明白的零样本学习 Zero-Shot Learning

而实际情况并不是所有的类别都有大量标注好的实例数据可供使用,因此,这些模型并不一定实用。另外,实际上并不能在所有类别的图像上进行训练,因此我们希望模型能够识别出在训练阶段未曾见过的类别的实例图像,这就是本文主角 - 零样本学习大显伸手的地方。
1零样本学习的提出
零样本学习 Zero-Shot Learning,简称 ZSL,是由 Lampert 等人在 2009 年提出的。他们提供了一个 Animals with Attributes 数据集以及经典的基于属性的学习算法,开启了这一机器学习新方法。从原理上来说,ZSL 就是让计算机模拟人类的推理方式,来识别从未见过的新事物。之所以独立出来,是因为它解决问题的思路不同于传统的机器学习方法。
2ZSL 的通俗理解
首先,我们举个栗子来看看零样本学习到底是处理什么问题的。
我们用小明找斑马的经典例子。某个周末,爸爸带小明到动物园玩,看到了马,爸爸告诉他,这是马。之后,又看到了老虎,告诉他: 看,这种身上有条纹的家伙就是老虎。最后,又带他去看了熊猫,对他说: 你看这熊猫是黑白色的。然后,爸爸给小明安排了一个任务,让他在动物园里找一种叫斑马的动物。由于小明没有见过斑马,于是爸爸给他讲了一下斑马的大概情况: 斑马形状像马,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。结果,根据爸爸的描述,小明在动物园里轻松地找到了斑马。

这个例子说明,虽然你没见过斑马,但如果你清楚关于它的描述,那么很可能在你第一次看到斑马的照片时就能认出它。
以上是白话,下面我们改用行话来讲一下这个例子。
首先,我们可以将其视为一个类似于自然语言处理的任务,它使用词嵌入(将词汇表中的词或短语映射到实数向量,要求具有相似含义的词将具有相似的词嵌入)。那么对于上面的例子,零样本学习是下面这样来处理的,
训练数据中并没有斑马的图像,但是有带条纹的动物(如老虎),有跟马长得相似的一类动物(如马、驴、小马等),还有黑白色的动物(如熊猫、企鹅等)的各种图像。可以提取这些图像的特征(条纹、形状似马、黑/白色)并生成词嵌入,组成字典。
然后,我们描述斑马的外观,并使用前面训练集里提出的特征来将斑马的外观转化成相应的词嵌入。
最后,当你给模型输入一张斑马的图像,它会先提取图像的特征,转化成词嵌入,然后与字典中最接近的词嵌入进行比较,得出那图像可能是只斑马。

这个例子体现了人类的推理过程,即利用已有知识(马、老虎、熊猫和斑马的描述),在脑海中推理出新对象的具体形态,从而能对新对象进行识别。ZSL 就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。
概括一下,就是利用类别的高维语义特征代替样本的低维特征,使得训练出来的模型具有迁移性。这里斑马的高维语义就是马的外形、老虎的斑纹、熊猫的颜色,尽管缺乏更多细节,但这些高维语义已经足够刻画斑马,从而让计算机成功识别出来未见过的斑马实例。
◇ 与传统机器学习方法的区别
在传统的图像识别算法中,要想让计算机认出斑马,往往需要给计算机投喂足够量的斑马图像才有做到。而且,训练出来的分类器,往往无法识别它没有见过的其他类别的图像。
但是 ZSL 却可以在没有提供新事物数据的情况下,只凭特征描述就能识别出新事物。是不是觉得 ZSL 比以往的机器学习方法更加智慧呢?
3ZSL 的问题设置
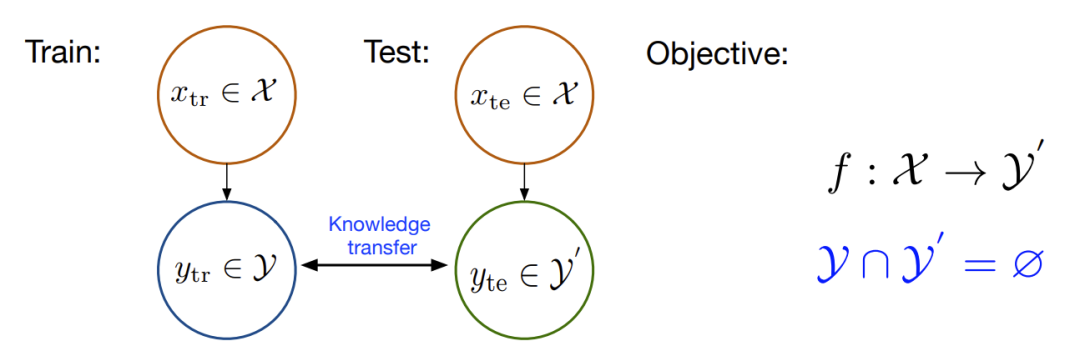
下面我们用机器学习的语言来组织一下 ZSL 的问题设置。针对一般的图片分类问题,零样本学习涉及的数据主要包括,
训练集数据
及其标签 ,包含了模型需要学习的类别(马、老虎和熊猫等),这里和传统的监督学习中的定义一致; 测试集数据
及其标签 ,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中的定义也一致; 训练集类别的描述
,以及测试集类别的描述 ;我们将每一个类别 ,都表示成一个语义向量 的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如 黑白色、有尾巴、有羽毛等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。
在 ZSL 中,我们希望利用
为了更加直观一点,对数据集配上一个图,右图中的 See Gull 这一类的数据不在训练集里。

对于对象分类问题,我们可以这样理解,需要建立图像特征空间和语义空间两者之间的联系。特征空间与语义空间之间的联系怎么建立有不同的方法,请参见下图大致了解一下。

4基础算法介绍
对问题已经有概念了,那怎么解决呢?我们来看一个最简单的解决方案。
首先,这里要处理的是一个图像分类问题,即对测试集的样本
对于分类,我们能想到的最简单的形式就是岭回归(Ridge Regression),具体形式为,
其中,
这样一个岭回归之所以有效,是因为训练集类别语义
5ZSL 方法分类
一、根据模型训练时对数据的可用性,零样本学习可以分为两类。
Inductive Zero-Shot
在该设置中,我们可以访问已知类别中的标注图像数据。除此之外,还可以访问已知类和未知类的语义描述,即训练过程中的集合
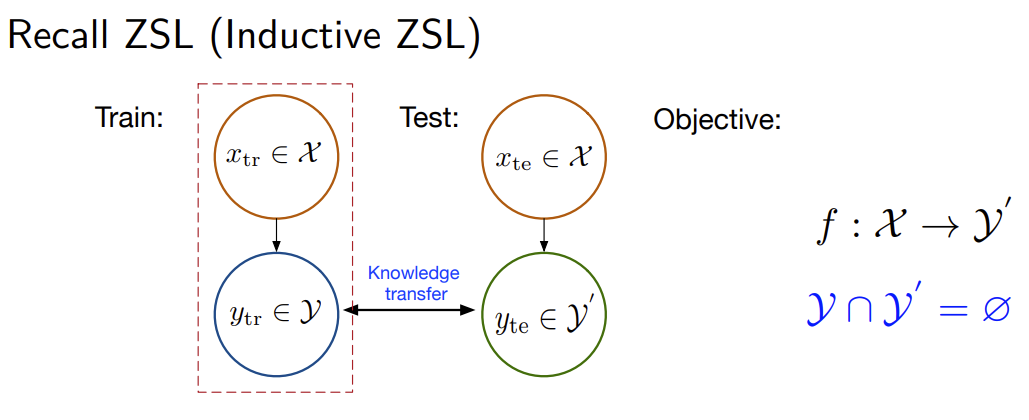
Transductive Zero-Shot
直推式学习其实是指在训练模型的时候,除了所有类别的语义描述

二、根据测试或推论时数据的可用性,零样本学习也可以分为两类。
常规零样本学习
在常规的零样本学习中,在测试时要识别的图像仅限于未知类别,即测试类别。但这类方法并不实用,因为实际中很难保证测试时数据仅仅来自未知的类别。
广义零样本学习
在广义零样本学习中,测试时的图像可以属于已知或未知类别。与常规设置相比,该设置实际上更加实用,但却更具挑战性。原因就是该模型仅在已知类图像上训练,因此可想而知其预测会偏向于已知类。这会导致许多未知类的图像在测试时被错误地分类为已知类,从而大大降低了模型的性能。
本文主要介绍零样本学习要处理的问题以及大概的解决思路,让大家对它有个初步的概念,至于零样本学习的应用以及问题与挑战等将在后期再展开。
⟳参考资料⟲
Zero-Shot Learning: https://en.wikipedia.org/wiki/Zero-shot_learning
[2]Zero-Shot Learning via CCDGM: http://people.duke.edu/~ww107/material/ZSL.pdf
[3]零次学习 Zero-Shot Learning 入门: https://zhuanlan.zhihu.com/p/34656727?utm_source=wechat_session&utm_medium=social&utm_oi=695187683760148480&from=singlemessage&s_r=0
[4]Zero-Shot Learning 如何打破零起点的封印: https://www.tmtpost.com/3665596.html
[5]Zero-shot Learning : An Introduction: https://www.learnopencv.com/zero-shot-learning-an-introduction/