
理解Meta Learning 元学习,这篇文章就够了!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
AI编辑:我是小将
本文作者:谢杨易
https://zhuanlan.zhihu.com/p/261323968
本文已由原作者授权,不得擅自二次转载
1 什么是meta learning
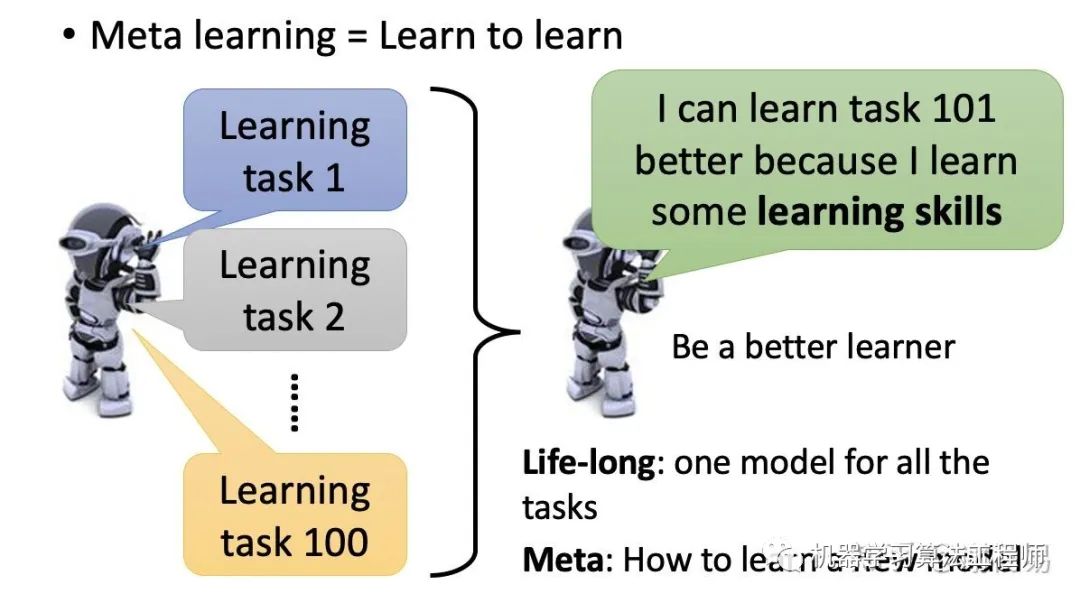
一般的机器学习任务是,通过训练数据得到一个模型,然后在测试数据上进行验证。一般来说我们仅关注模型在该任务上的表现。而meta learning则探讨解决另一个问题,就是我们能否通过学习不同的任务,从而让机器学会如何去学习呢?也就是learn to learn。我们关注的不再是模型在某个任务上的表现,而是模型在多个任务上学习的能力。
试想一下机器学习了100个任务,他在第101个任务上一般就可以学的更好。比如机器学习了图像分类、语音识别、推荐排序等任务后,在文本分类上,它就可以因为之前学到的东西,而学的更好。meta learning就是解决这个问题,如何让机器去学习。
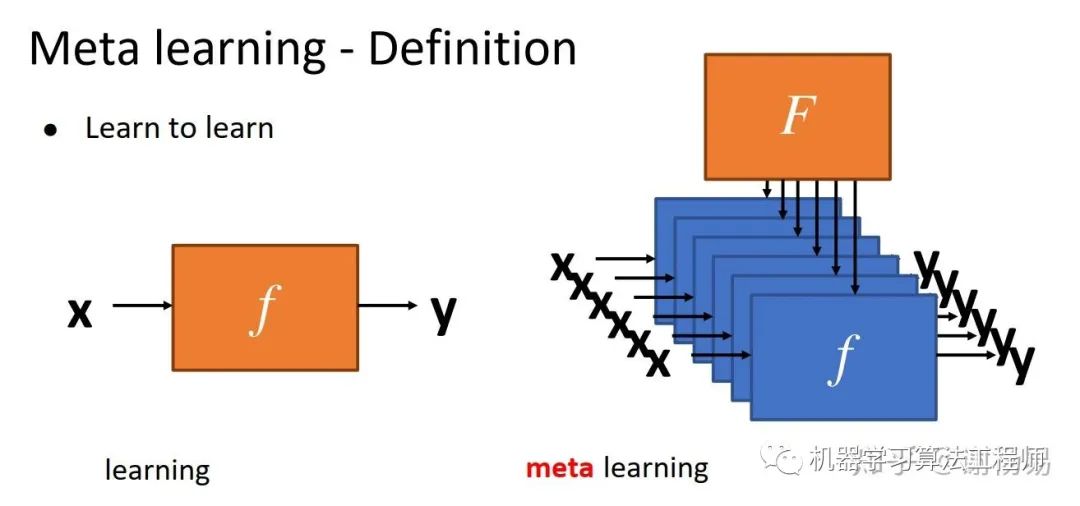
一般的机器学习任务,我们是需要学习一个模型f,由输入x得到输出y。而meta learning,则是要学习一个F,用它来学习各种任务的f。如下图
2 为什么需要meta learning
meta learning的优势主要有
让学习更加有效率。我们通过多个task的学习,使得模型学习其他task时更加容易。
样本数量比较少的任务上,更加需要有效率的学习,从而提升准确率和收敛速度。meta learning是few shot learning的一个比较好的解决方案
3 meta learning可以学到什么
通过meta learning,我们可以学到
模型参数 model parameters。包括模型的初始化参数,embedding,特征表达等
模型架构。可以通过network architecture search(NAS)得到模型的架构,比如几层网络,每层内部如何设计等
模型超参数。比如learning rate,drop out rate,optimizer等。这个是AutoML的范畴
算法本身,因为不一定是一个网络模型。
4 常用数据集
meta learning需要训练多个task,故一般每个task样本不会很多,其数据集本身也是few shot。常用的数据集datasets如下。
Omniglot
它由很多种不同语言构成,包括1623种字符,每个字符20个样本。所以也算是few shot learning了。

miniImageNet
ImageNet的few shot版本

CUB
Caltech-UCSD Birds。各种鸟类的图片,也是few shot。

5 优化目标和loss
如何评价meta learning的好坏呢,也就是我们的优化目标是什么呢。一般来说,meta learning需要多个机器学习task作为数据集,其中一部分task作为training task,另一部分作为testing task。training task和testing task中都包括训练数据和测试数据。
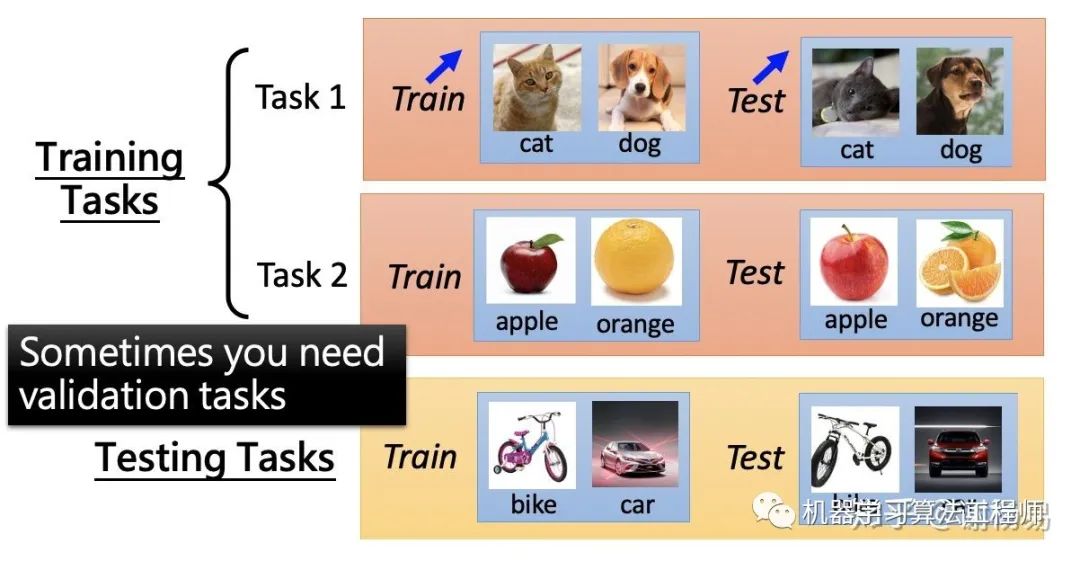
我们先通过task1学习到模型f1,并得到损失函数l1。然后再task2上学习模型f2,并得到l2。以此类推,得到所有task上的损失函数之和,即为meta learning的损失函数。如下
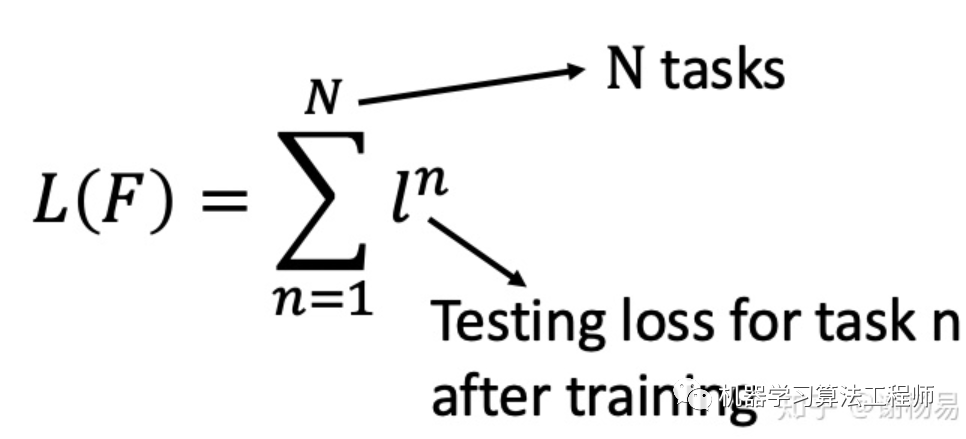
我们的目标就是降低这个损失函数 L(F)。
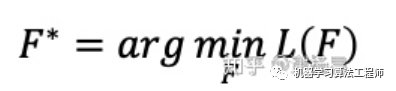
6 MAML

ICML 2017
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks。
6.1 用来解决什么问题
MAML focus在学习模型初始化参数上,这和pretrain models的目标是相同的。pretrain models通过有监督或自监督方式,先在数据集充足的任务A上训练模型,然后利用该模型的参数来初始化数据量比较少的任务B。通过迁移学习的方式,让数据量比较少的任务,也能够train起来。meta learning和pretrain models虽然都可以帮助模型参数初始化,但二者差别还是很大的
pretrain model的任务A,一般来说数据量比较充足,否则自己都没法train起来,也就无法得到一个不错的初始化参数
pretrain model的初始化参数,重在当前任务A上表现好,可能在任务B上不一定好。meta learning则利用初始化参数,在各任务上继续训练后,效果都不错。它重在模型的潜力

6.2 loss和优化目标
MAML loss function如下

所有task的testing set上的loss之和,即为MAML的Loss,我们需要最小化这个loss。通过gradient descent的方法就可以实现。
6.3 创新点
MAML的创新点在于,训练模型时,在单个任务task中,模型参数只更新一次。李宏毅老师认为主要原因是
MAML希望模型具有单个task上,参数只更新一次,就可以得到不错初始化参数的能力
meta learning的数据集一般都是few shot的,否则很多task,训练耗时会很高。而few shot场景下,一般模型参数也更新不了几次
虽然在训练模型时只更新一次初始化参数,但在task test时,是可以更新多次参数,让模型充分训练的
meta learning一般会包括很多个task,单个task上只更新一次,可以保证学习效率。
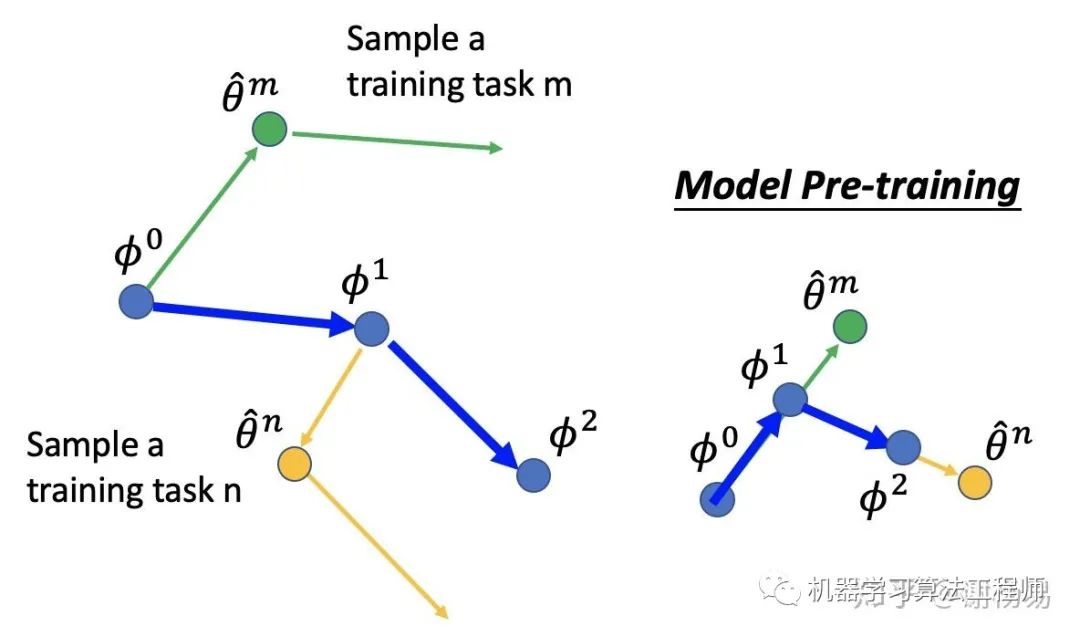
6.4 如何更新参数
MAML更新参数的过程如下所示
初始化meta learning参数φ0
由φ0梯度下降一次,更新得到θm
在task m上更新一次参数
通过第二次θ的方向,确定φ的更新方向,得到φ1。
而对于model pretrain,其φ和θ的更新始终保持一致。
7 Reptile

openAI,2018,On First-Order Meta-Learning Algorithms
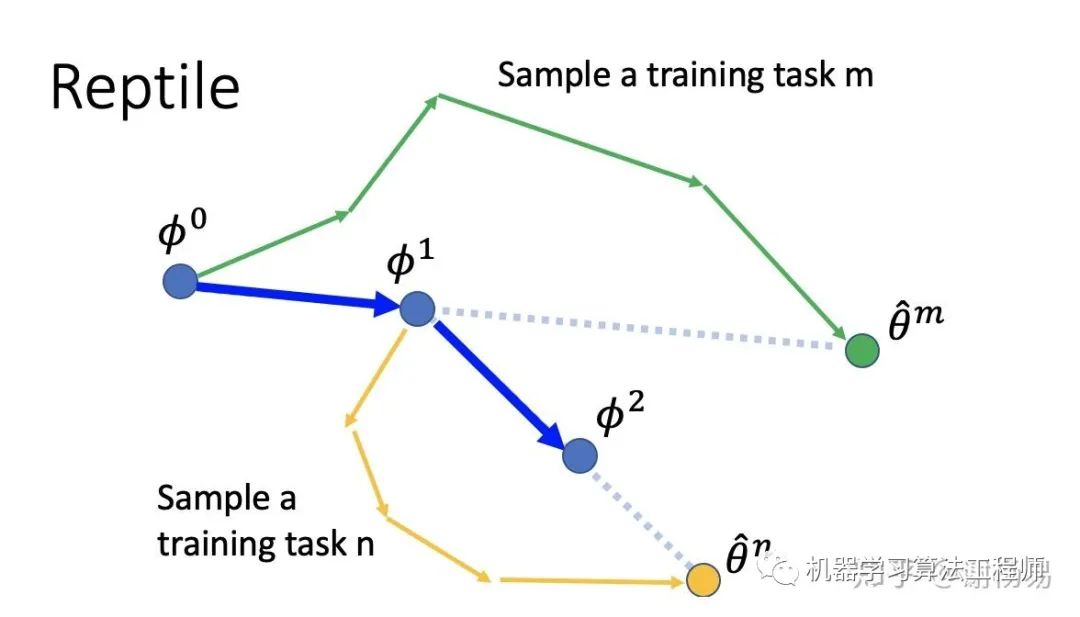
7.1 模型特点
Reptile和MAML一样,也是focus在模型参数初始化上。故loss function也基本相同。不同之处是,它结合了pretrain model和MAML的特点,在模型参数更新上有所不同。Reptile也是先初始化参数φ0,然后采样出任务m,更新多次(而不是MAML的单次),得到一个不错的参数θm。利用θm的方向来更新φ0到φ1。同样的方法更新到φ2
推荐阅读
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
