
TPAMI 2022|DeepMIH:基于可逆神经网络的多图像隐藏算法
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者 | 景俊鹏
编辑 | 极市平台
导读
本文介绍了北京航空航天大学徐迈教授MC2 Lab发表于IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2022)上的工作“DeepMIH: Deep Invertible Network for Multiple Image Hiding”。该工作对多图像隐藏任务(Multiple Image Hiding)进行了分析研究,首次提出了基于可逆神经网络的级联式模型架构,能够实现将多张秘密图像按次序隐藏到同一张载体图片中。该论文提出的方法在多个公开数据集上都实现了SOTA。
论文地址:https://ieeexplore.ieee.org/document/9676416
代码地址:https://github.com/TomTomTommi/DeepMIH
1 要点
本文创新点:
我们提出了一种基于可逆神经网络的新颖的多图像隐藏算法,用“级联”的方式将多张秘密图像隐藏到同一张载体图片中。
我们对多图像隐藏的任务进行了细致分析,并根据其特性设计了基于频域的损失函数,有效提高了性能。
我们应该是第一个利用前后级相关性辅助图像隐藏的工作。我们设计了一种预测重要性图的模块,用于提供多级隐藏之间的先验信息。
我们看图说话:
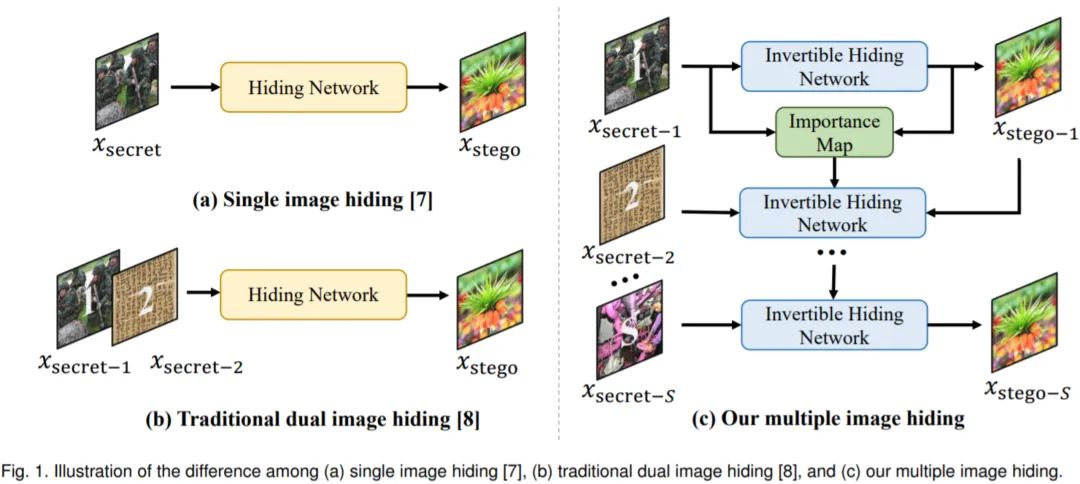
1) 如图 (a) 所示,现有的单图像隐藏算法将一张秘密图像(Secret image,图中的军人)通过一个隐藏网络嵌入到载体图像中,最终生成隐秘图像(Stego image,图中的花)。为了使不知情的人发现秘密图像的存在,图像隐藏任务要求隐秘图像和载体图像在视觉效果上是一致的(在训练时,我们通常使用L1/L2 Loss来实现)。除了图中画出的部分,在实际使用时,还需要一个恢复网络将隐秘图像中的秘密图像恢复出来,自然恢复图像的质量也不能太差,我们也需要一个损失函数项来约束。通过这两个损失函数,我们就能训练一个具有“隐藏过程”和“恢复过程”的图像隐藏算法了。
2) 基于单图像隐藏的思路,我们能够很自然地想到将其扩展为多图像隐藏。如图 (b) 所示,我们只需要将输入隐藏网络的通道数进行扩充(一张图是3通道,两张图是6通道,以此类推…),在输入时将多张秘密图像进行堆叠(Concatenation)操作,就实现了多图像隐藏的算法,这也是现有的多图像隐藏算法实现的基本思路。这种思路虽然简单,但仍存在着一些问题:所有秘密图像一股脑塞进网络,让网络“硬训”出一个结果,虽然网络也能收敛,但没有考虑秘密图像之间的关系,隐藏时容易产生“视觉伪影”和“颜色失真”(具体见第2节)。其次,实际应用场景可能有多个通信节点(A, B, C…),此时的多图像隐藏就变为了A—>B藏一张图像,B—>C藏一张图像的形式。图 (b) 中的方法没有解决多节点之间的隐秘通信。
3) 针对上述的问题,我们提出了一种“级联式”网络架构的解决思路。如图 (c) 所示,对于需要隐藏的多张秘密图像,我们每次只隐藏其中一张,将隐藏过程拆解为多个单图像的隐藏过程。这样做的好处是我们有空间能够专门处理秘密图像之间的关系。如图中绿色模块所示,我们提出了基于注意力机制的“重要性图”模块,它能够根据前级网络的隐藏结果给下级隐藏过程提供先验信息,在一定程度上避免将难以隐藏的像素区域隐藏到载体图像的同一个地方,提高隐藏性能。此外,和图 (b) 中的方法另一点不同的是,级联式隐藏在恢复时不但需要恢复出秘密图像,也要同时恢复出下一级的隐秘图像用于恢复下一级图像。这极大地增加了恢复网络的压力,我们使用自动编码器结构进行过尝试,效果很不理想。最终我们采用了可逆神经网络的架构,它的“双分支”结构能够天然地适应同时恢复秘密图像和隐秘图像的要求(具体见第3节)。
2 隐藏特性分析
2.1 频带特性分析
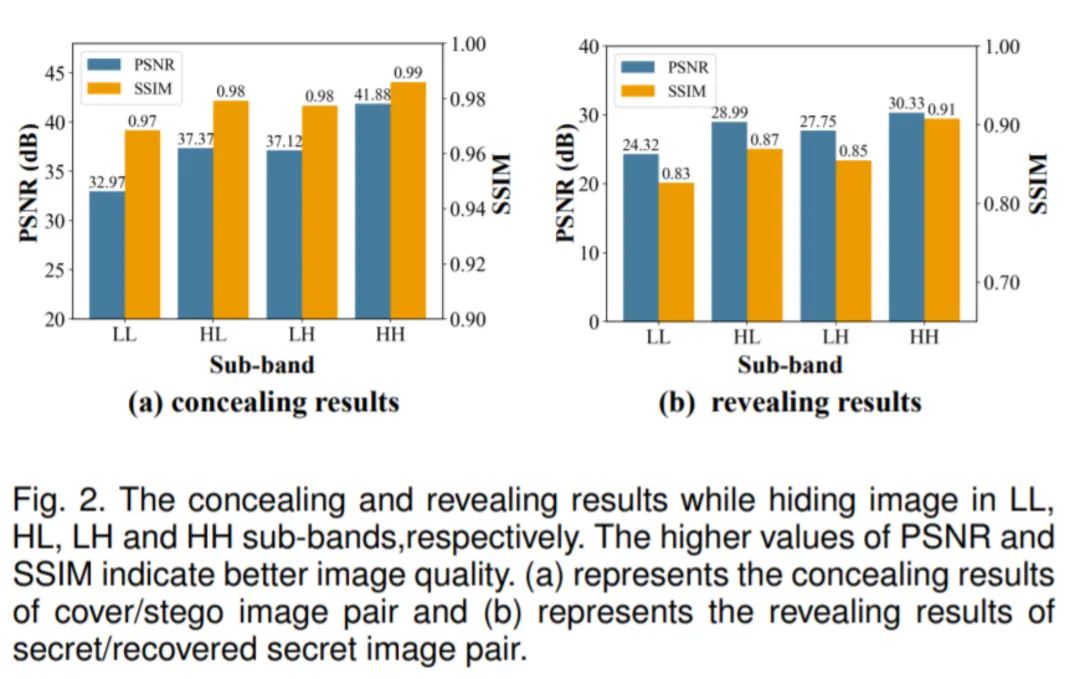
我们用现有算法做了一个简单的实验:将载体图片用小波变换分解为LL,LH,HL,HH四个频带,将四分之一原图大小的秘密图片分别藏进其中一个频带,然后再用小波逆变换得到“只有一个频带含有秘密信息”的隐秘图片。通过对PSNR和SSIM的测算,我们得到了如上的柱状图。分析可知,将信息藏在高频部分对隐秘图片的质量影响是最小的,PSNR和SSIM相对最高。这说明HH频带最适合进行图片隐藏,这个结论和我们在以往文章中得到的描述是一致的。针对这一点,我们设计了一个简单的频域Loss来辅助训练过程,提高了网络的性能。
2.2 隐藏容量分析

在对现有单图像算法进行分析的过程中我们发现,当把已经藏有一张秘密图片的隐秘图片当作载体图片再进行隐藏时,会出现很明显的“视觉伪影”和“颜色失真”。从图中可以看出,当隐藏第一张秘密图像时,秘密图像的香蕉区域相对于载体图像的天空区域有很明亮的颜色和复杂的轮廓,将这个图案隐藏进去已经很困难了。在接下来隐藏第二张秘密图像时,如果还出现复杂的纹理区域,网络就难以再实现较好的隐藏了。从第二行结果中也能看到,有的隐秘图片中出现了骷髅头的轮廓,有的产生了颜色失真的问题。这个现象说明了如果忽略掉秘密图像之间的关联性,随着隐藏容量的增加(隐藏图片数量增加),网络的隐藏效果将受到限制,甚至会产生明显的失真。这也说明现有的解决思路不能简单拓展到多图像隐藏领域,我们需要新的解决思路。
3 方法
3.1 总体框架
我们在文章中进行详细叙述时,都以两张图片的隐藏作为例子进行了阐述。多图像隐藏的整体机制也是一样的,在文章最后,我们将模型进行了扩展,讨论了多张图像隐藏的性能效果。
我们的DeepMIH方法由一个框图说明:
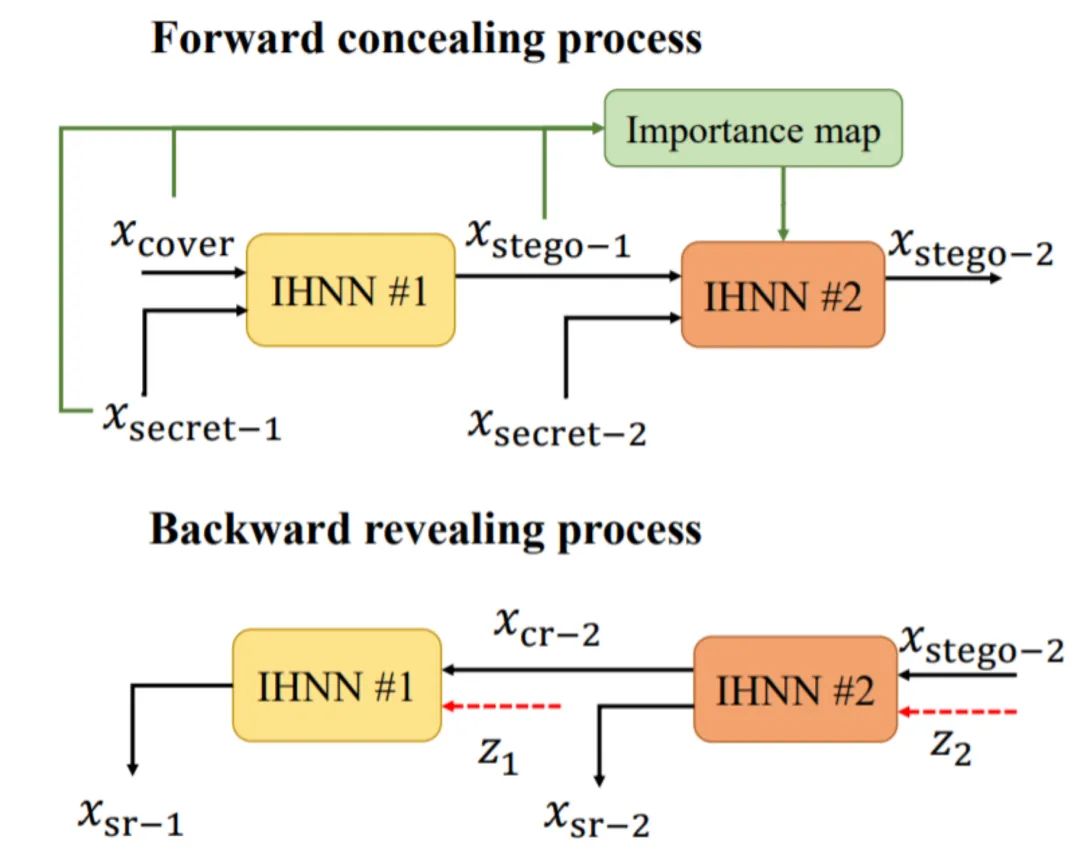
DeepMIH 由两个子结构组成,分别是基于可逆网络、用于隐藏和恢复的网络结构 IHNN 和基于注意力机制、获取前级先验信息用于指导下级隐藏的重要性图模块 IM。
在进行正向隐藏过程时,首先给 IHNN#1 喂入载体图像 和第一张秘密图像 进行第一级隐藏,得到第一张隐秘图像 然后,将得到的隐秘图像当作载体图像和第二张秘密图像 一起喂给 IHNN#2,进行第二级的隐藏。与上一级不同的是,此时 IM 模块接收载体图像、秘密图像和隐秘图像,并生成一张重要性图,同时喂给 IHNN#2,然后得到最终藏有两张图像的隐秘图像
在进行反向恢复时,整体的信号流程与正向过程完全相反。隐秘图像 首先经过 IHNN#2 的反向过程进行恢复,得到恢复出的前级隐秘图像 和秘密图像 , 将 喂给 IHNN#1 的反向过程,恢复出 。接着我们来分别看看组成 DeepMIH 的两个子结构。
3.2 IHNN结构
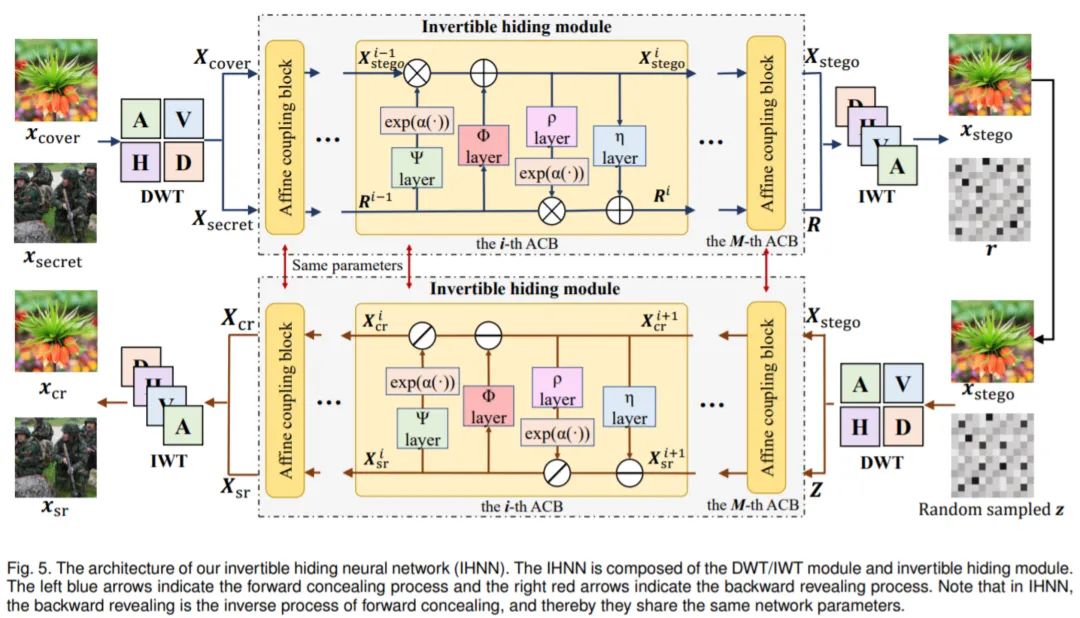
如上图所示,IHNN的结构可以分为最前端和最后端的DWT/IWT部分和中间的可逆隐藏模块。经过对频域隐藏特性的分析我们知道,将秘密信息隐藏在载体图像的高频部分能够实现更好的效果。这也是我们使用小波变换模块的动机,通过设计损失函数能够让秘密信息更趋向于隐藏在高频部分。此外,我们在溶解实验中也发现在频域上进行图像隐藏能减少参数量,提高整体性能(具体可见原文)。这也说明经过小波变换后的两个输入能够更加有效地进行秘密信息的融合。可逆隐藏模块采用了INN的仿射变换结构(具体公式可见原文),用一套参数对正向和反向过程进行了建模,实现了更好的效果。
3.3 IM结构
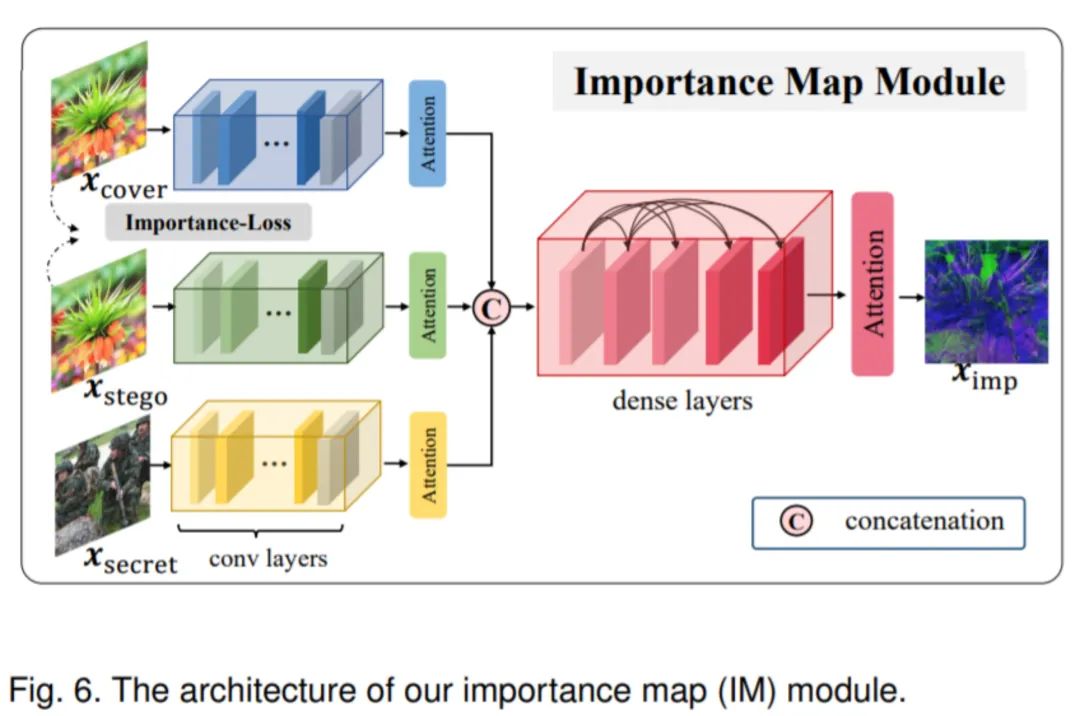
为了能够在网络多级之间引入先验信息,我们设计了一个简单的IM网络。输入载体图像、秘密图像和隐秘图像后,这三个图像先经过不进行共享参数的相同模块网络后再堆叠经过一个稠密网络。每一级输出后都接入注意力机制模块。
3.4 多图像隐藏
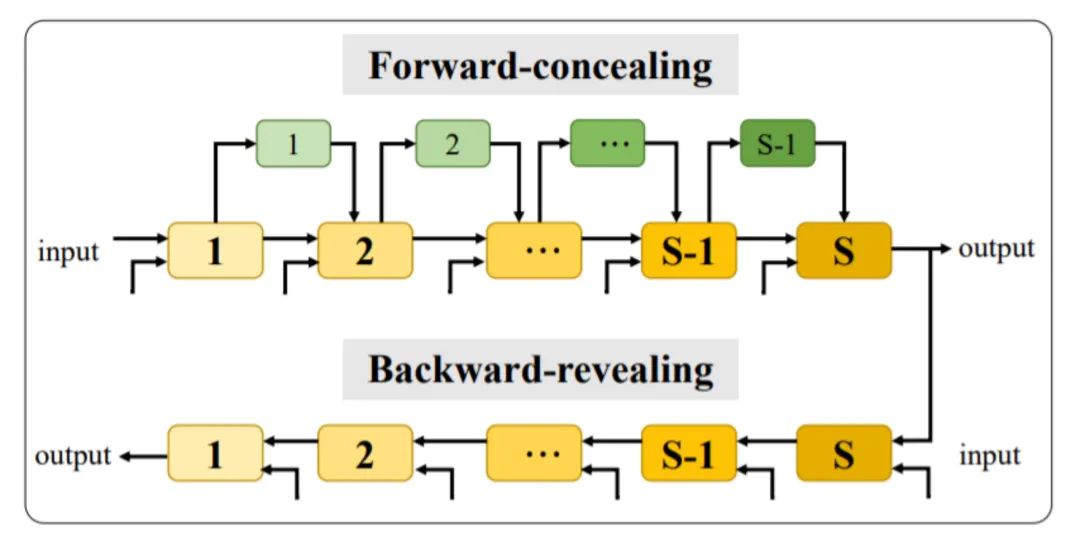
阐述完两张图像隐藏的模型后,我们能够很容易将其扩展到多图像隐藏。这里我们给出了统一的范式流程,见上图。对于S张图片,我们使用S个IHNN模块和S-1个IM模块实现总体的网络搭建。
4 实验
4.1 客观效果
我们选用了Y-PSNR,SSIM,MAE,RMSE作为评价指标,结果如表格所示:
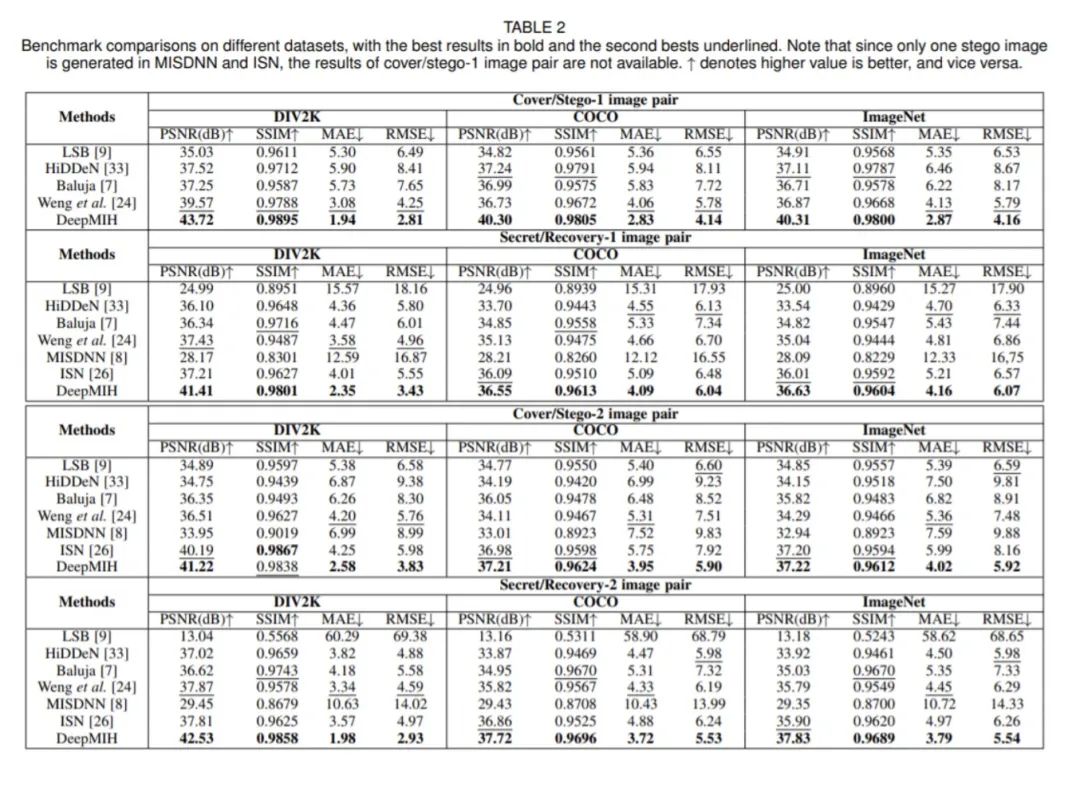
在通用数据集DIV2K,COCO和ImageNet上,DeepMIH全面胜出,展现出较好的泛化能力。
我们还拓展实现了三张图像和四张图像的隐藏模型。我们看看结果:

从平均值可以看出,随着隐藏图像数量的增加,总体的隐藏效率是下降的,这是符合我们认知的。
4.2 主观效果
除了客观的指标外,审稿人建议我们增加user study实验,我们在Response的时候进行了相应的补充。在我们的实验中,受试的志愿者能够发现隐秘图像的异样情况被标记为0,不能则标记为1。我们最后统计了MOS分的情况。
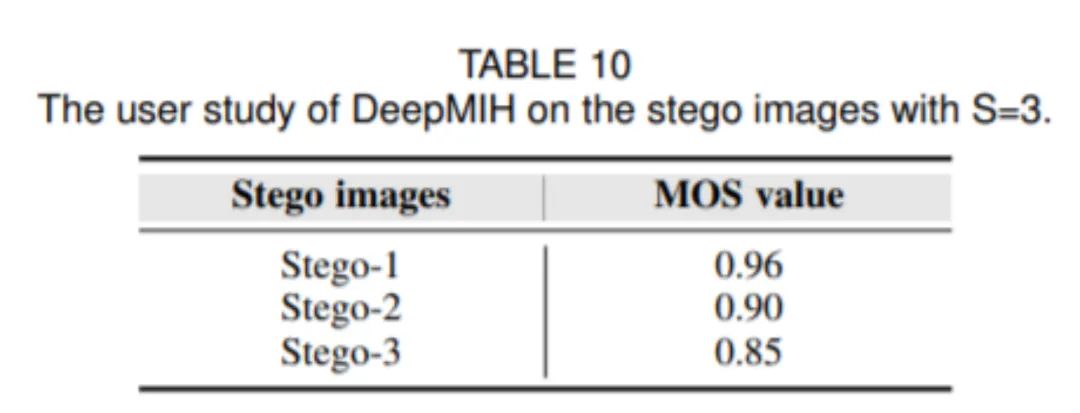
如上表所示,最末级的隐秘图像的MOS分是最低的,最容易被看出异样,表明它的质量最差,这与上述客观质量的规律是一致的。
除了上述的实验外,我们还进行了大量的溶解实验、主观效果和频域可视化等。在此不过多赘述,更多细节请感兴趣的读者阅读原文。
5 不足和展望
DeepMIH构建的多图像隐藏范式有待提升。随着隐藏图像数量的增加,模型的参数量也随之线性增加,尽管在两张、三张、四张隐藏时模型参数量是可以接受的,但当隐藏数量过大时,网络参数仍面临压力。
隐藏范式不够优美也会导致训练困难。网络在训练时要考虑到多个子模块的参数更新,每个模块都需要进行预训练和fine-tune,不能实现从0开始的end-to-end。DeepMIH的训练部分依赖于经验和手动控制,尽管我们总结了优化的算法步骤,但具体的训练节点和细节仍需根据实际情况而定。
尽管DeepMIH考虑了多级之间的相关性,但这种方法过于简单,仅通过较为粗糙地引入基于注意力的模块未能从根本上解决问题。而且随着IM模块的引入,网络的整体可逆性受到了破坏,也会造成性能下降。如何将多级相关性巧妙融入隐藏和恢复模型中是未来的研究方向。
DeepMIH只考虑了基于图片的任务,拓展成视频是一个待实现的任务领域。视频相比于多张图片关联性更大,如何有效利用帧内和帧间的信息相关性,以此来优化隐藏和恢复的过程是尚未解决的问题。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!