Soft-Masked BERT 一种新的中文纠错模型

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
今年,字节AI-Lab与复旦大学合作提出了一种中文文本纠错模型:Soft-Masked BERT[1].这项工作发表在了ACL 2020上,由于论文并没有开源代码,所以我将对这篇论文进行解读与复现。
问题提出:
中文文本纠错是一项挑战性的任务,因为模型要想获得令人满意的解决方案,就必须具备人类水平的语言理解能力。比如:
eg1 Wrong:埃及有金子塔。Correct: 埃及有金字塔。
eg2 Wrong: 他的求胜欲很强,为了越狱在挖洞。Correct: 他的求生欲很强,为了越狱在挖洞。
eg3 Wrong: 他主动拉了姑娘的手, 心里很高心。Correct: 他主动拉了姑娘的手, 心里很高兴。
在Soft-Masked BERT被提出之前,最好的方法是先通过在句子的每个位置建立基于BERT的语言表示模型,再从候选字符列表中选择一个字符进行修正。然而,BERT使用了mask的方式进行预训练,没有足够的能力来检测每个位置是否存在误差(只有15%的错误被找出),所以这种方法的精度不够好。
Soft-Masked BERT解决方案:
使用两个网络模型,一个用于错误检测;另一个基于BERT进行纠错。
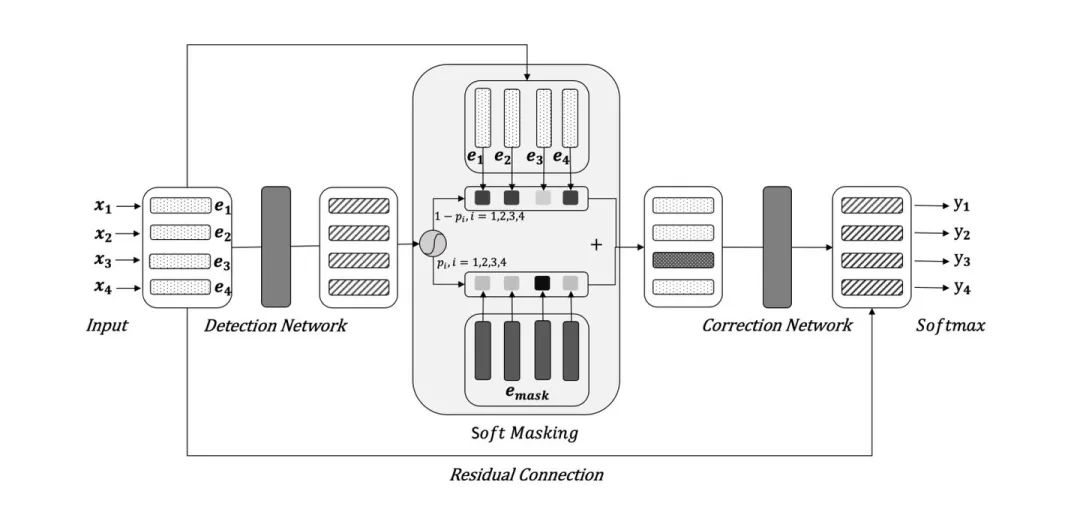
Detection Network
Detection Network通过双向的GRU来实现:

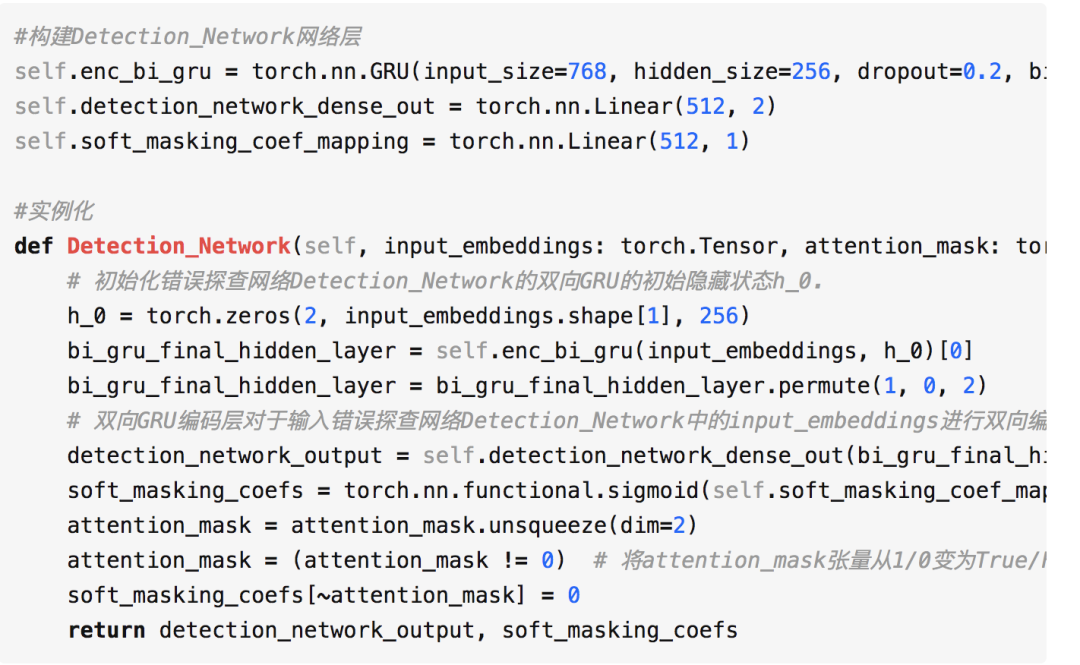
构建Detection_Network中的网络层与实例化代码:
Soft Masking Connection
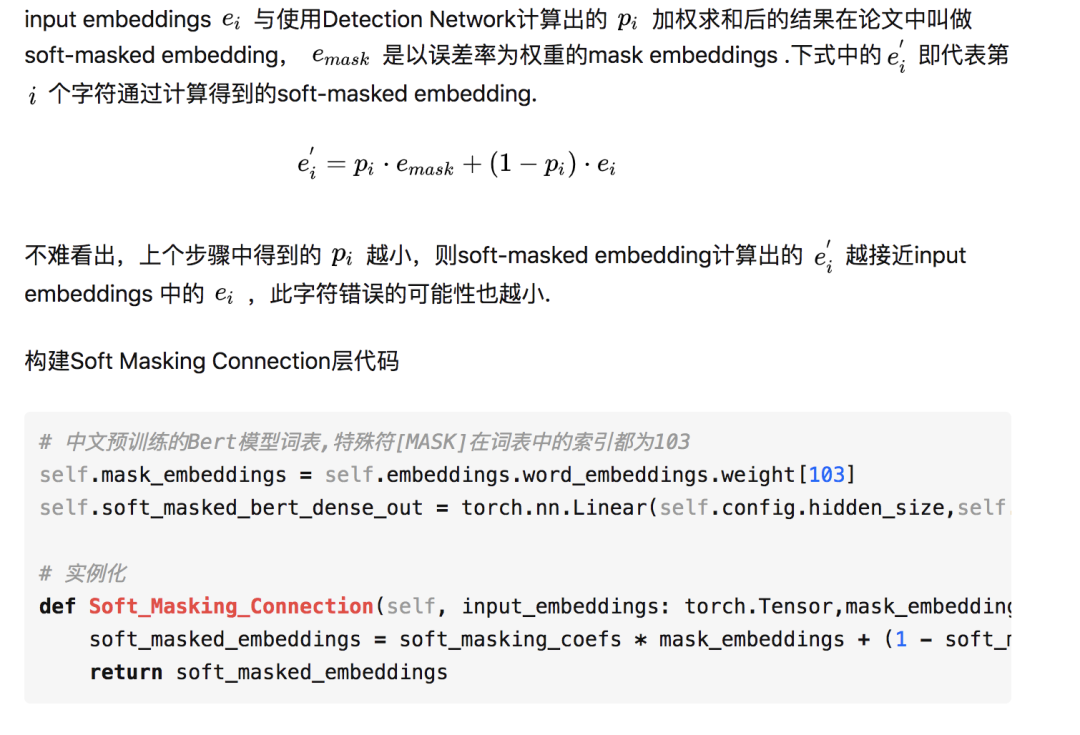
Correction Network
该层主要的结构就是Bert模型,其中有12个Encoder层,以整个序列作为输入。每个block包含一个多头部的self-attention操作,然后接一个前馈网络:



实验结果
论文中使用的数据集有3个:
Chinese Spelling Check Task(CSC)数据集:选择了其中《对外汉语测试》的作文部分(SIGHAN);
News Title数据集:来自于今日头条app中的文章的标题部分;
5 million news titles数据集:从一些中文新闻app中爬取,该数据集只用来fine-tuning
其中公开数据集为Chinese Spelling Check Task数据集[2],包含1100个文本和461种错误(字符级别).
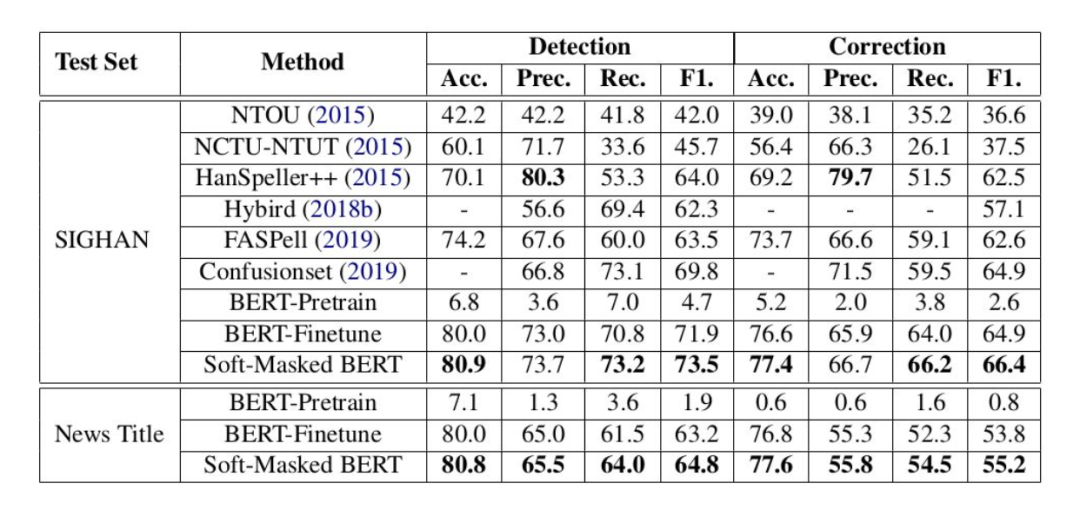
可以看出,在CSC数据集的测试中,Soft-Masked BERT模型的效果基本上都是比其他Baseline模型的效果要好。
而在Detection部分,HanSpeller++模型的精准率要高于Soft-Masked BERT模型的精准率,且Correction部分HanSpeller++模型的精准率也高于Soft-Masked BERT模型的精准率.
这是因为HanSpeller++模型中有许多人工添加的规则与特征,这些人工添加的规则与特征能在Detection部分过滤错误的识别,虽然这种人工规则与特征效果很好,但这种方式需要很多人工成本,而且泛化性也不好.
综上,在SIGHAN数据集的测试集上,Soft-Masked BERT模型的效果是最优的。
此外作者还用实验证明了:
fine-tuning的数据集(在5 million news titles数据集上)的规模越大,fine-tuning之后的模型在CSC任务中的效果也会越好;
消融对比研究,证明该提出的模型每一部分都是不可或缺的.
关于以上内容:
完整代码以及更详细的注释(一行代码三行注释)已上传到github
代码 获取方式:
分享本文到朋友圈
关注微信公众号 datayx 然后回复 纠错 即可获取。
AI项目体验地址 https://loveai.tech
参考
^[1] https://arxiv.org/pdf/2005.07421.pdf
^http://ir.itc.ntnu.edu.tw/lre/sighan7csc.html
^https://github.com/shibing624/pycorrector
^https://zhuanlan.zhihu.com/p/164873441
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码