
BERT模型的优化改进方法!
BERT模型的优化改进方法!

本文为论文《BERT模型的主要优化改进方法研究综述》的阅读笔记,对 BERT主要优化改进方法进行了研究梳理。
BERT基础
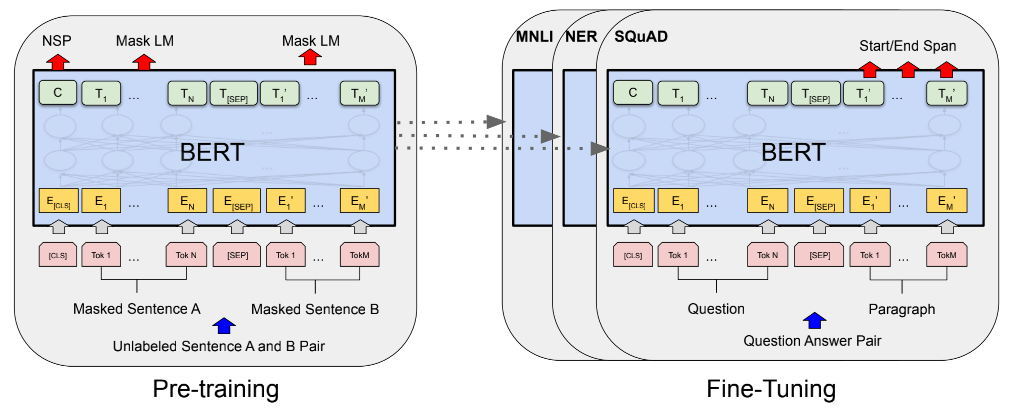
BERT是由Google AI于2018年10月提出的一种基于深度学习的语言表示模型。BERT 发布时,在11种不同的NLP测试任务中取得最佳效果,NLP领域近期重要的研究成果。
BERT基础
BERT主要的模型结构是Transformer编码器。Transformer是由 Ashish 等于2017年提出的,用于Google机器翻译,包含编码器(Encoder)和解码器(Decoder)两部分。
BERT预训练方法
BERT 模型使用两个预训练目标来完成文本内容特征的学习。
掩藏语言模型(Masked Language Model,MLM)通过将单词掩盖,从而学习其上下文内容特征来预测被掩盖的单词 相邻句预测(Next Sentence Predication,NSP)通过学习句子间关系特征,预测两个句子的位置是否相邻
分支1:改进预训练
自然语言的特点在于丰富多变,很多研究者针对更丰富多变的文本表达形式,在这两个训练目标的基础上进一步完善和改进,提升了模型的文本特征学习能力。
改进掩藏语言模型
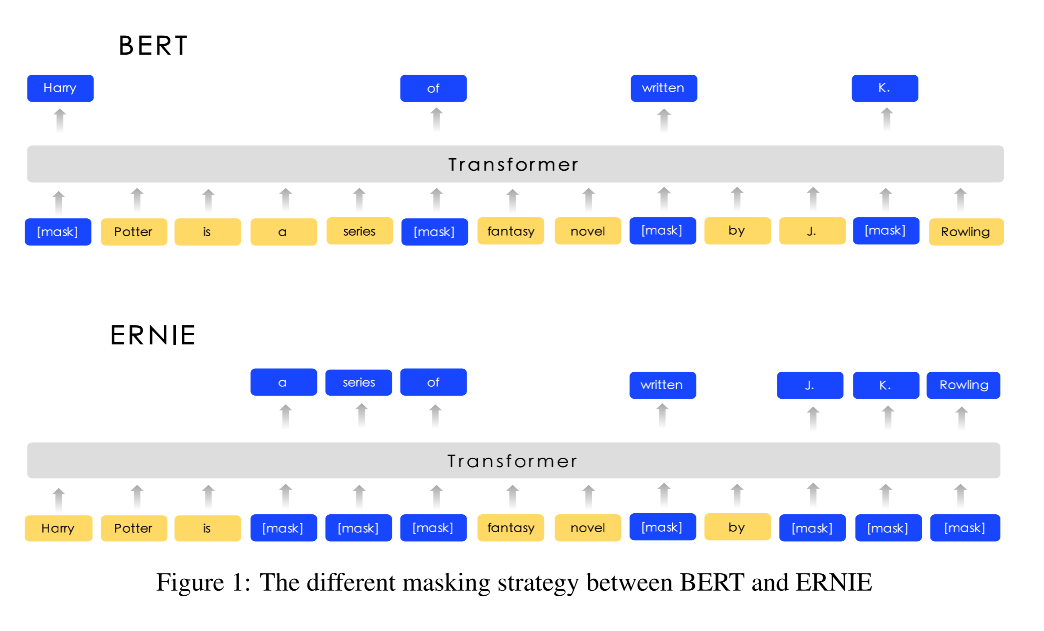
在BERT模型中,对文本的预处理都按照最小单位进行了切分。例如对于英文文本的预处理采用了Google的wordpiece方法以解决其未登录词的问题。
在MLM中掩盖的对象多数情况下为词根(subword),并不是完整的词;对于中文则直接按字切分,直接对单个字进行掩盖。这种掩盖策略导致了模型对于词语信息学习的不完整。针对这一不足,大部分研究者改进了MLM的掩盖策略。在 Google 随后发布的BERT-WWM模型中,提出了全词覆盖的方式。
BERT-Chinese-wwm利用中文分词,将组成一个完整词语的所有单字同时掩盖。ERNIE扩展了中文全词掩盖策略,扩展到对于中文分词、短语及命名实体的全词掩盖。SpanBERT采用了几何分布来随机采样被掩盖的短语片段,通过Span边界词向量来预测掩盖词
引入降噪自编码器
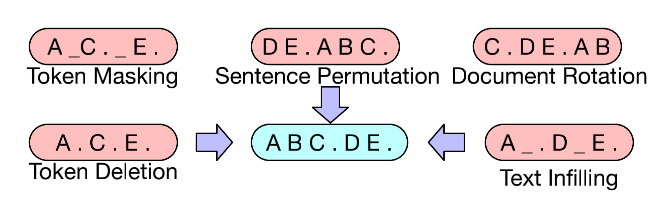
MLM 将原文中的词用[MASK]标记随机替换,这本身是对文本进行了破坏,相当于在文本中添加了噪声,然后通过训练语言模型来还原文本,消除噪声。
DAE 是一种具有降噪功能的自编码器,旨在将含有噪声的输入数据还原为干净的原始数据。对于语言模型来说,就是在原始语言中加入噪声数据,再通过模型学习进行噪声的去除以恢复原始文本。
BART引入了降噪自编码器,丰富了文本的破坏方式。例如随机掩盖(同 MLM 一致)某些词、随机删掉某些词或片段、打乱文档顺序等,将文本输入到编码器中后,利用一个解码器生成破坏之前的原始文档。
引入替代词检测
MLM 对文本中的[MASK]标记的词进行预测,以试图恢复原始文本。其预测结果可能完全正确,也可能预测出一个不属于原文本中的词。
ELECTRA引入了替代词检测,来预测一个由语言模型生成的句子中哪些词是原本句子中的词,哪些词是语言模型生成的且不属于原句子中的词。
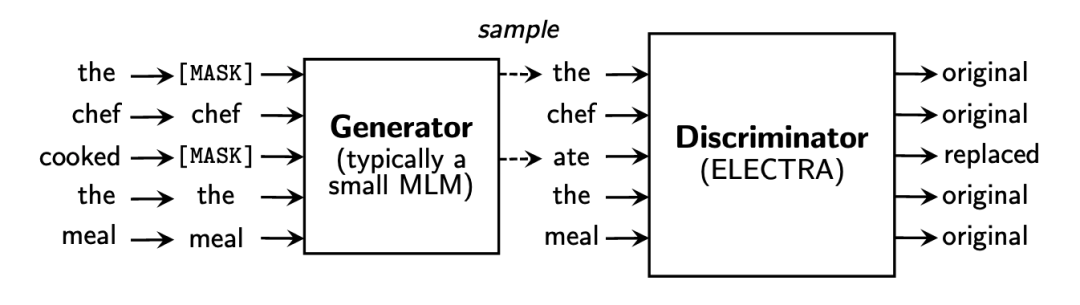
ELECTRA 使用一个小型的 MLM 模型作为生成器(Generator),来对包含[MASK]的句子进行预测。另外训练一个基于二分类的判别器(Discriminator)来对生成器生成的句子进行判断。
改进相邻句预测
在大多数应用场景下,模型仅需要针对单个句子完成建模,舍弃NSP训练目标来优化模型对于单个句子的特征学习能力。
删除NSP:NSP仅仅考虑了两个句子是否相邻,而没有兼顾到句子在整个段落、篇章中的位置信息。 改进NSP:通过预测句子之间的顺序关系,从而学习其位置信息。
分支2:融合融合外部知识
当下知识图谱的相关研究已经取得了极大的进展,大量的外部知识库都可以应用到 NLP 的相关研究中。
嵌入实体关系知识
实体关系三元组是知识图谱的最基本的结构,也是外部知识最直接和结构化的表达。K-BERT从BERT模型输入层入手,将实体关系的三元组显式地嵌入到输入层中。
特征向量拼接知识
BERT可以将任意文本表示为特征向量的形式,因此可以考虑采用向量拼接的方式在 BERT 模型中融合外部知识。
SemBERT利用语义角色标注工具,获取文本中的语义角色向量表示,与原始BERT文本表示融合。
训练目标融合知识
在知识图谱技术中,大量丰富的外部知识被用来直接进行模型训练,形成了多种训练任务。ERNIE以DAE的方式在BERT中引入了实体对齐训练目标,WKLM通过随机替换维基百科文本中的实体,让模型预测正误,从而在预训练过程中嵌入知识。
分支3:改进Transformer
由于Transformer结构自身的限制,BERT等一系列采用 Transformer 的模型所能处理的最大文本长度为 512个token。
改进 Encoder MASK矩阵
BERT 作为一种双向编码的语言模型,其“双向”主要体现在 Transformer结构的 MASK 矩阵中。Transformer 基于自注意力机制(Self-Attention),利用MASK 矩阵提供一种“注意”机制,即 MASK 矩阵决定了文本中哪些词可以互相“看见”。
UniLM通过对输入数据中的两个句子设计不同的 MASK 矩阵来完成生成模型的学习。对于第一个句子,采用跟 BERT 中的 Transformer-Encoder 一致的结构,每个词都能够“注意”到其“上文”和“下文”信息。
对于第二个句子,其中的每个词只能“注意”到第一句话中的所有词和当前句子的“上文”信息。利用这种巧妙的设计,模型输入的第一句话和第二句话形成了经典的“Seq2Seq”的模式,从而将 BERT 成功用于语言生成任务。
Encoder + Decoder语言生成
BART模型同样采用Encoder+Decoder 的结构,借助DAE语言模型的训练方式,能够很好地预测和生成被“噪声”破坏的文本,从而也得到具有文本生成能力的预训练语言模型。
分支4:量化与压缩
模型蒸馏
对 BERT 蒸馏的研究主要存在于以下几个方面:
在预训练阶段还是微调阶段使用蒸馏 学生模型的选择 蒸馏的位置
DistilBERT在预训练阶段蒸馏,其学生模型具有与BERT结构,但层数减半。
TinyBERT为BERT的嵌入层、输出层、Transformer中的隐藏层、注意力矩阵都设计了损失函数,来学习 BERT 中大量的语言知识。
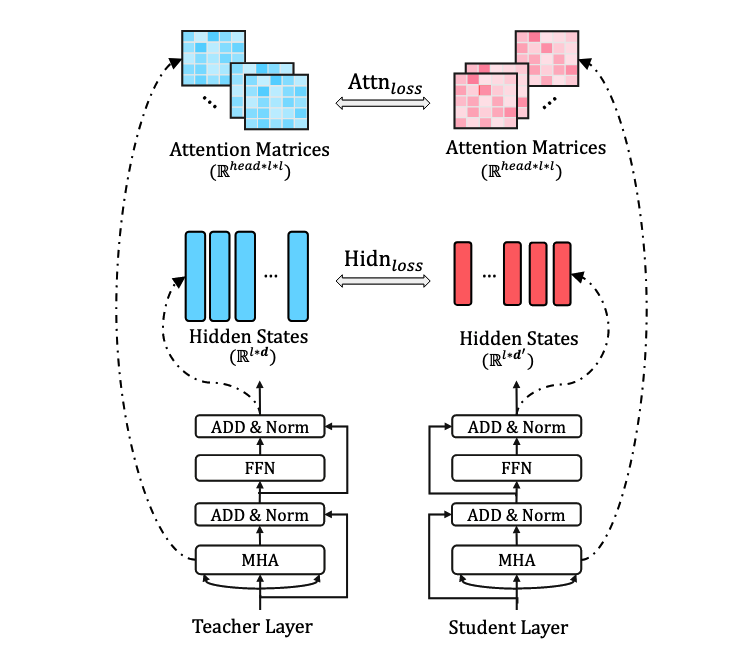
模型剪枝
剪枝(Pruning)是指去掉模型中不太重要的权重或组件,以提升推理速度。用于 BERT 的剪枝方法主要有权重修剪和结构修剪。
——The End——

干货学习,点赞三连↓