
【NLP】BERT 模型与中文文本分类实践
简介
2018年10月11日,Google发布的论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》[1],提出的 BERT 模型成功在11项 NLP 任务中取得 state of the art 的结果,赢得自然语言处理学界的一片赞誉之声,成为 NLP 发展史上的里程碑式的模型成就。BERT 的全称是 Bidirectional Encoder Representations from Transformer。
Bidirectional:BERT 的模型结构和 ELMo 类似,均为双向的。 Encoder:BERT 只是用到了 Transformer 的 Encoder 编码器部分。 Representation:做词 / 句子的语义表征。 Transformer:Transformer Encoder 是 BERT 模型的核心组成部分。
BERT 模型的目标是利用自监督学习方法在大规模无标注语料上进行预训练,从而捕捉文本中的丰富语义信息。在后续特定的 NLP 任务中,我们可以根据任务类型对 BERT 预训练模型参数进行微调,以取得更好的任务效果。BERT 论文链接:https://arxiv.org/abs/1810.04805 ,github 地址:https://github.com/google-research/bert
模型理解
网络架构
BERT 的网络架构使用的是《Attention is all you need》[2] 中提出的多层 Transformer Encoder 结构,其最大的特点是抛弃了传统的 RNN 和 CNN,通过 Attention 机制将任意位置的两个单词的距离转换成1,有效的解决了 NLP 中棘手的长期依赖问题。Transformer 的结构在 NLP 领域中已经得到了广泛应用,其网络架构如下图所示,Transformer 是一个 encoder-decoder 的结构,由若干个编码器和解码器堆叠形成。图中的左侧部分为编码器,由 Multi-Head Attention 和 Feed Forward 全连接层组成,用于将输入语料转化成特征向量。右侧部分是解码器,其输入为编码器的输出以及已经预测出的结果,由 Masked Multi-Head Attention, Multi-Head Attention 以及 Feed Forward 全连接层组成,用于输出最后结果的条件概率。
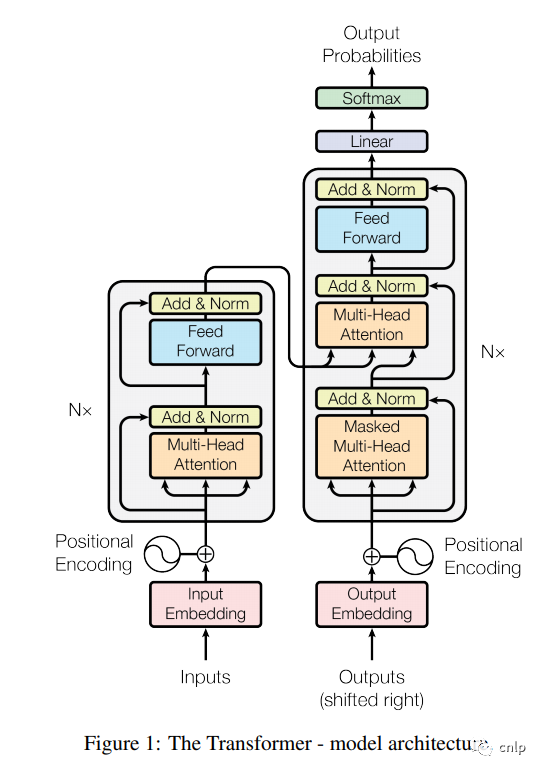
上图的左侧部分是一个 Transformer Block,对应到下图中的一个 “Trm”。
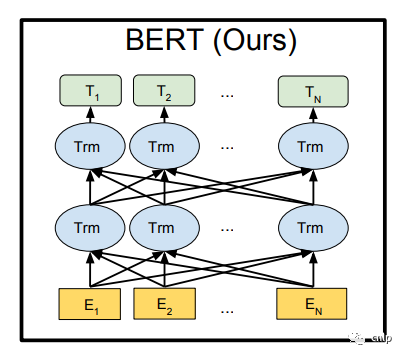
BERT 提供了基础和复杂两个模型,对应的超参数分别如下:
:L=12,H=768,A=12,参数总量110M :L=24,H=1024,A=16,参数总量340M
其中 L 表示网络的层数(即 Transformer blocks 的数量),A 表示 Multi-Head Attention 中 self-Attention 的数量,H 是输出向量的维度。谷歌提供了中文 BERT 基础预训练模型 bert-base-chinese,TensorFlow 版模型链接:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip ,Pytorch 版模型权重链接:https://huggingface.co/bert-base-chinese/tree/main
BERT 论文中还对比了 GPT[3] 和 ELMo[4],它们两个的结构如下图所示:
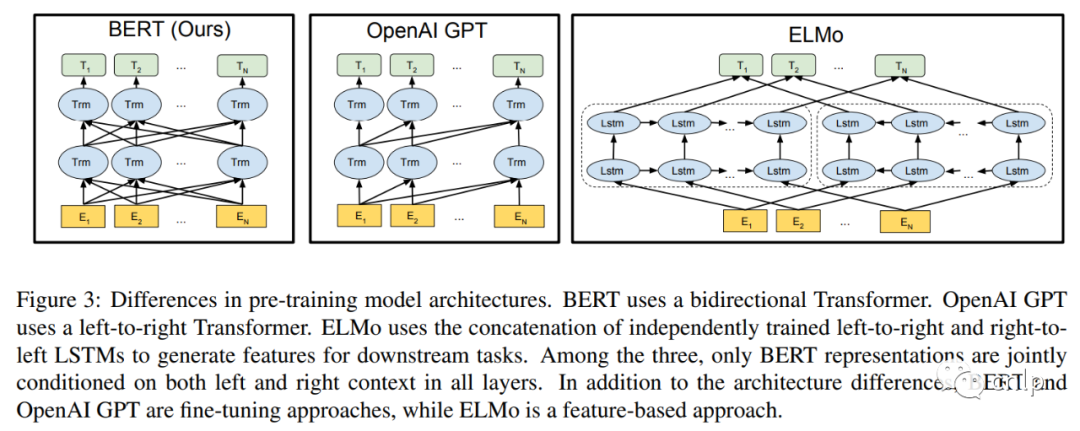
其中 BERT 使用的是双向 Transformer 编码器,GPT 使用的是单向 Transformer 解码器,ELMo 使用两个独立训练的 LSTM 结构,只有BERT表征会基于所有层中的左右两侧语境。除了结构上的不同,BERT 和 GPT 是基于微调的方式,而 ELMo 是基于特征的方法。
输入表示
BERT 模型的输入为表示单个文本句或一对文本的词序列,对于给定的词,其输入表示通过三部分 Embedding 求和得到。
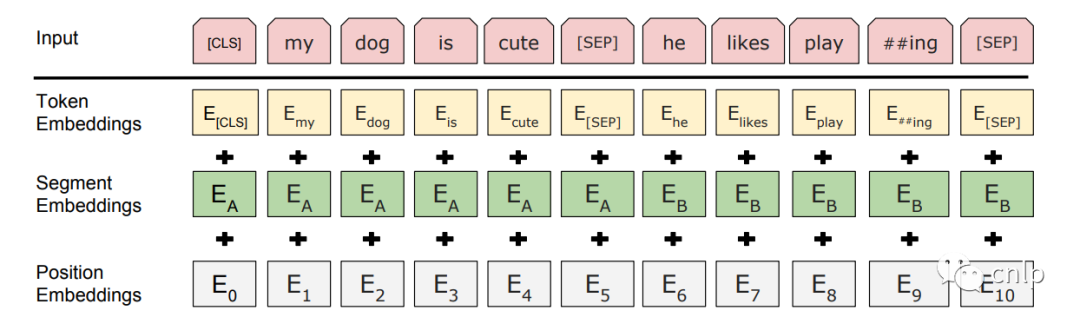
Token Embeddings:WordPiece 分词后的词向量。 Position Embedding:位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。 Segment Embedding:用于区分两个句子。对于句子对输入,第一个句子的特征值是0,第二个句子的特征值是1。
图中的两个特殊符号[CLS]和 [SEP]:[CLS]一般位于句首,是输入的第一个 token,其对应的输出向量可以作为整个输入句子的表示,用于之后的分类任务。[SEP]表示分句符号,用于断开输入语料中的两个句子。
预训练任务
BERT 模型使用两个新的无监督预测任务进行预训练,分别是 Masked LM(MLM)和 Next Sentence Prediction(NSP)。
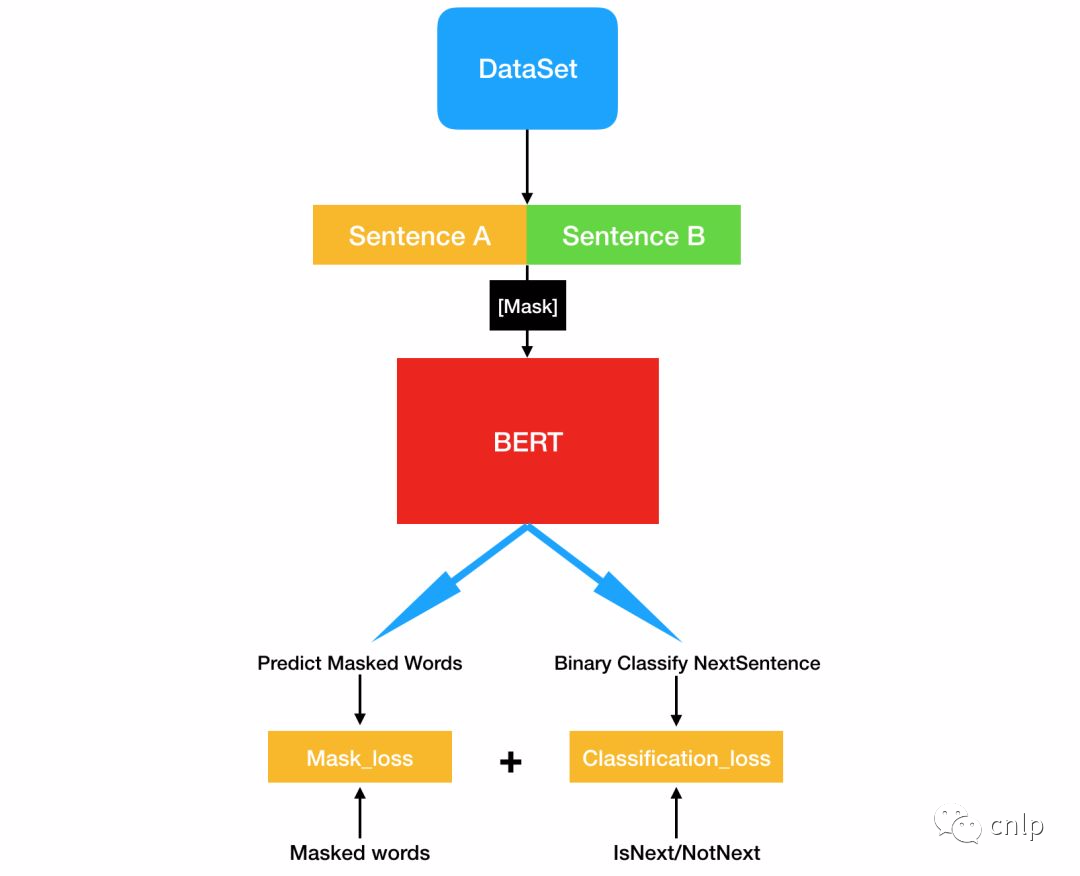
Masked LM
为了训练深度双向 Transformer 表示,采用了一种简单的方法:随机掩盖部分输入词,然后对那些被掩盖的词进行预测,此方法被称为“Masked LM”(MLM)。该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和 RNN 匹配一样,MLM 的这个性质和 Transformer 的结构也是非常匹配的。
BERT 在预训练时只预测[MASK]位置的单词,这样就可以同时利用上下文信息。但是在后续使用的时候,句子中并不会出现[MASK]的单词,这样会影响模型的性能。因此在训练时采用如下策略,随机选择句子中15%的单词进行 Mask,在选择为 Mask 的单词中,有80%真的使用[MASK]进行替换,10%使用一个随机单词替换,剩下10%保留原词不进行替换。
原句:my dog is hairy 80%:my dog is [MASK]10%:my dog is apple 10%:my dog is hairy
注意最后10%保留原句是为了将表征偏向真实观察值,而另外10%用其它随机词替代原词并不会影响模型对语言的理解能力,因为它只占所有词的1.5%(0.1 × 0.15)。此外,作者在论文中还表示因为每次只能预测15%的词,因此模型收敛比较慢。
Next Sentence Prediction
Next Sentence Prediction(NSP)是一个二分类任务,其目标是判断句子 B 是否是句子 A 的下文,如果是的话输出标签为 ‘IsNext’,否则输出标签为 ‘NotNext’。BERT 使用这一预训练任务的主要原因是,很多句子级别的任务如自动问答(QA)和自然语言推理(NLI)都需要理解两个句子之间的关系。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合 IsNext 关系,另外50%的第二句话是随机从预料中提取的,它们的关系是 NotNext 的。BERT 模型使用[CLS]的编码信息进行预测。
输入: [CLS]我 喜 欢 玩 英[MASK]联 盟[SEP]我 最 擅 长 的[MASK]色 是 亚 索[SEP]类别:IsNext 输入: [CLS]我 喜 欢 玩 英[MASK]联 盟[SEP]今 天 天 气 很[MASK][SEP]类别:NotNext
BERT 预训练的过程可以用下图来表示。
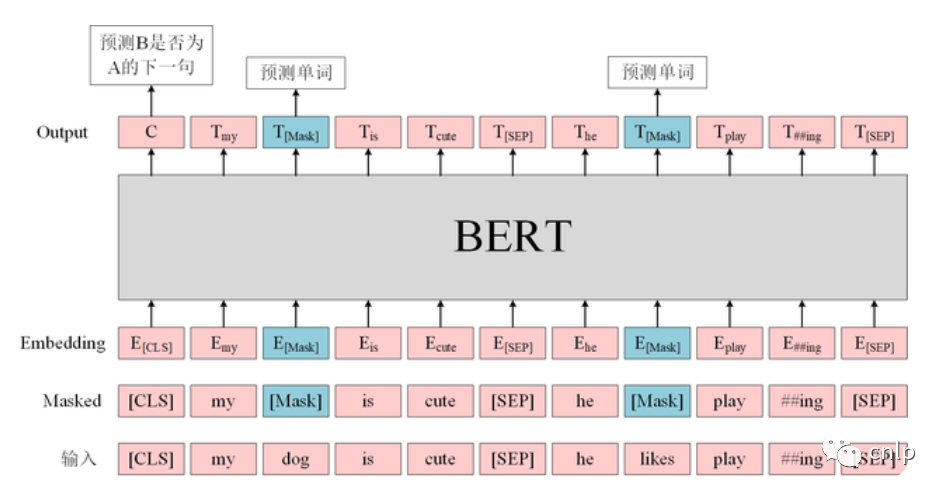
微调
预训练得到的 BERT 模型可以在后续用于具体 NLP 任务的时候进行微调 (Fine-tuning 阶段),BERT 模型可以适用于多种不同的 NLP 任务,如下图所示。
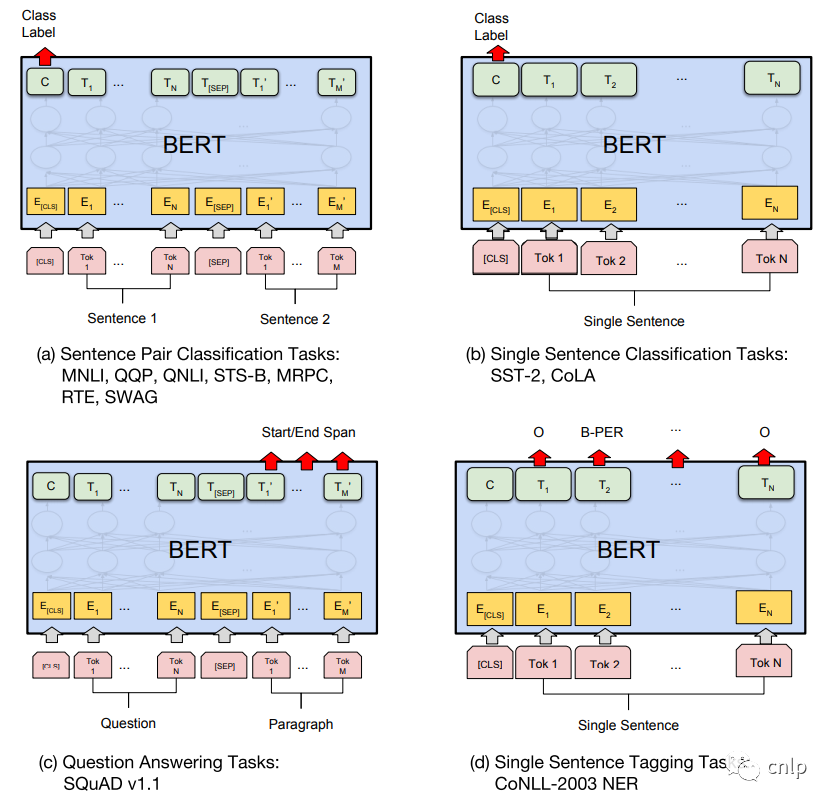
句子对分类任务
例如自然语言推断 (MNLI),句子语义等价判断 (QQP) 等,如上图 (a) 所示,需要将两个句子传入 BERT,然后使用 [CLS] 的输出向量 C 进行句子对分类。
单句分类任务
例如句子情感分析 (SST-2),判断句子语法是否可以接受 (CoLA) 等,如上图 (b) 所示,只需要输入一个句子,无需使用 [SEP] 标志,然后也是用 [CLS] 的输出向量 C 进行分类。
问答任务
如 SQuAD v1.1 数据集,样本是语句对 (Question, Paragraph),Question 表示问题,Paragraph 是一段来自 Wikipedia 的文本,Paragraph 包含了问题的答案。而训练的目标是在 Paragraph 中找出答案的起始位置 (Start,End)。如上图 (c) 所示,将 Question 和 Paragraph 传入 BERT,然后 BERT 根据 Paragraph 所有单词的输出预测 Start 和 End 的位置。
单句标注任务
例如命名实体识别 (NER),输入单个句子,然后根据 BERT 对于每个单词的输出向量 T 预测这个单词的类别,是属于 Person,Organization,Location,Miscellaneous 还是 Other (非命名实体)。
任务效果
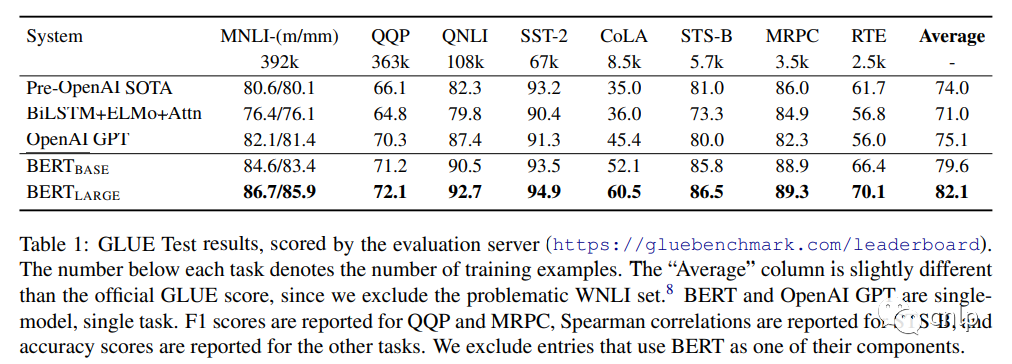
中文文本分类实践
基于 pytorch-transformers 实现的 BERT 中文文本分类代码仓库:https://github.com/zejunwang1/bert_text_classification 。该仓库主要包含 data 文件夹、pretrained_bert 文件夹和4个 python 源文件。
config.py:模型配置文件,主要配置训练集 / 验证集 / 测试集数据路径,模型存储路径,batch size,最大句子长度和优化器相关参数等。 preprocess.py:实现 DataProcessor 数据预处理类。 main.py:主程序入口。 train.py:模型训练和评估代码。
从 THUCNews 中随机抽取20万条新闻标题,一共有10个类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐,每类2万条标题数据。数据集按如下划分:
训练集:18万条新闻标题,每个类别的标题数为18000 验证集:1万条新闻标题,每个类别的标题数为1000 测试集:1万条新闻标题,每个类别的标题数为1000
训练集对应 data 文件夹下的 train.txt,验证集对应 data 文件夹下的 dev.txt,测试集对应 data 文件夹下的 test.txt。可以按照 data 文件夹中的数据格式来准备自己任务所需的数据,并调整 config.py 中的相关配置参数。
预训练 BERT 模型
从 huggingface 官网上下载 bert-base-chinese 模型权重、配置文件和词典到 pretrained_bert 文件夹中,下载地址:https://huggingface.co/bert-base-chinese/tree/main
模型训练
文本分类模型训练:
python main.py --mode train --data_dir ./data --pretrained_bert_dir ./pretrained_bert
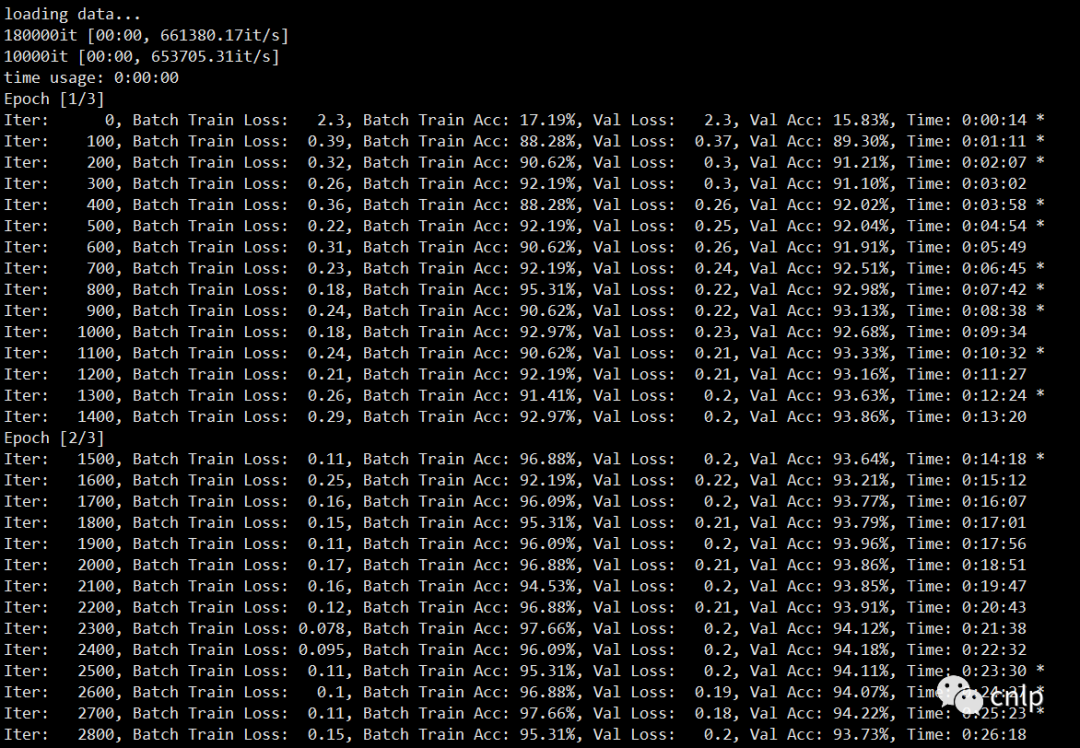
训练中间日志如下:
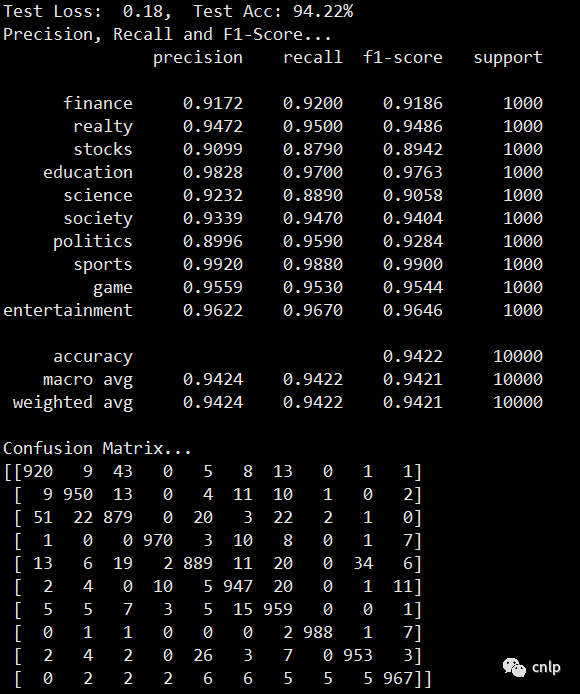
模型在验证集上的效果如下:
Demo演示
文本分类 demo 展示:
python main.py --mode demo --data_dir ./data --pretrained_bert_dir ./pretrained_bert

模型预测
对 data 文件夹下的 input.txt 中的文本进行分类预测:
python main.py --mode predict --data_dir ./data --pretrained_bert_dir ./pretrained_bert --input_file ./data/input.txt
输出如下结果:

参考文献
[1] BERT: https://arxiv.org/pdf/1810.04805.pdf
[2] Transformer: https://arxiv.org/pdf/1706.03762.pdf
[3] GPT: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
[4] ELMo: https://arxiv.org/pdf/1802.05365.pdf
往期精彩回顾 本站qq群851320808,加入微信群请扫码: