
BERT的若干改进模型思路
来源:知乎
直到今天,由BERT衍生出的模型仍然是百花齐放的状态,但是有新意的改进想法和思路却不过寥寥,今天我们通过ERNIE、RoBERTa、XLNet这些经典的BERT改进模型来看一下大佬们曾经新颖的思路,这些天马行空的奇思妙想值得讲述,在海边多走走,兴许自己也能捡到一些漂亮的贝壳。
1.百度ERNIE
2019年4月,百度发布了ERNIE模型。ERNIE基于BERT模型针对中文NLP任务做出进一步的优化,得到了SOTA的结果。
1.1 BERT在中文任务中存在的问题
我们知道BERT在实现中文任务时,是以汉字为单位来训练语言模型的。通常BERT对中文任务是难以使用词语作为单位来训练的,虽然理论上行得通,但是在实际工程中,汉语的词语几乎可以用无穷无尽来形容。但中文常用的汉字也就4000多个,BERT训练很容易实现,所以最初BERT对中文任务是以汉字为单位实现训练的。
于是就产生了一个问题,既然是以汉字为单位训练的,其训练出的就是孤零零的汉字向量,而在现代汉语中,单个汉字是远不足以表达像词语或者短语那样丰富的语义的,这就造成了BERT在很多中文任务上表现并不理想的情况。
1.2 针对中文进行改进
ERNIE的改进其实很好理解:给模型加上词语信息,即百度宣称的让模型学到“知识”,那要怎样加入知识信息呢?有两种方法:
第一种是显式的方法,即通过某种手段,在输入阶段,就给模型输入知识实体。
第二种是隐式的方法,即在masked训练阶段,将包含有某一个知识实体的汉字全都Mask掉,让模型来猜测这个词语,从而学习到知识实体。
百度的ERNIE选取的是第二种方案,其实清华大学也推出了一个同名的ERNIE模型,采取的就是第一种方法,但貌似表现效果和名气都不如百度的ERNIE,故在此不多谈。百度是国内搜索引擎常年的霸主,其对语义理解和知识图谱的研究可谓是炉火纯青,所以百度将知识图谱引入了BERT中,形成了ERNIE。
我们知道对于英文任务,BERT是以单词为单位来进行词向量的训练的,但实际上,英文任务也可以通过ERNIE的方式来改进,掩盖整个英文短语或者实体,让BERT学习到知识,如下图所示:
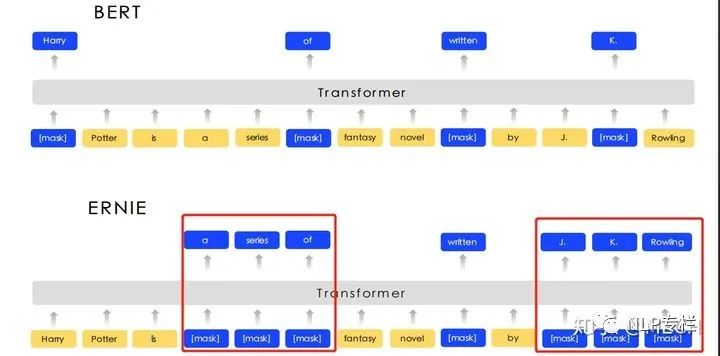
ERNIR的mask是由三个阶段学习组成,在第一个阶段,采用的是BERT模式的word piece级别的mask(basic-level masking),然后再加入短语级别的mask(phrase-level masking),然后再加入实体级别的mask(entity-level masking)。如下图:

在这个基础上,借助百度在中文的社区的强大能力,中文的ERNIR还用了各种混杂数据集(Heterogeneous Data)。此外为了适应多轮的贴吧数据,ERNIE引入了DLM 对话语言模型(Dialogue Language Model) 任务,在这里不展开细讲。
1.3 ERNIE 2.0
这是百度在之前的模型上做了新的改进,这篇论文主要是走多任务的思想,引入了多大7个任务来预训练模型,并且采用的是逐次增加任务的方式来预训练,具体的任务如下面图中所示,图中红框、蓝框、绿框里面的就是七种任务的名称:
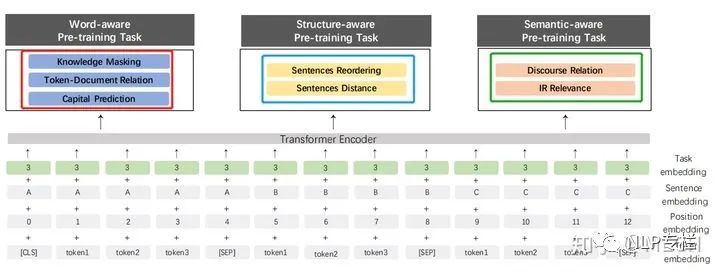
因为不同的任务输入不同,因此作者还引入了Task Embedding,来区分不同的任务。真就万物皆可Embedding呗。

训练的方法是先训练任务1,保存模型,然后加载刚保存的模型,再同时训练任务1和任务2,依次类推,到最后同时训练7个任务。
2.0在效果上比1.0版本全面提升,其中,在阅读理解的任务上提升非常大。
2.BERT-WWM
BERT-WWM是2019年7月推出的,它是由哈工大讯飞联合实验室针对中文做出的改进,WWM的意思是Whole Word Masking,其实就是ERNIE模型中的短语级别遮盖(phrase-level masking)训练。
BERT-WWM属于BERT-base模型结构,由12层Transformers构成。训练第一阶段(最大长度为128)采用的batch size为2560,训练了100K步。训练第二阶段(最大长度为512)采用的batch size为384,训练了100K步。
后续又出了一个BERT-WWM-ext,它是BERT-WWM的一个升级版,相比于BERT-WWM的改进是增加了训练数据集同时也增加了训练步数,性能也得到了一定程度的提升。它也属于BERT-base模型结构,由12层Transformers构成。训练第一阶段(最大长度为128)采用的batch size为2560,训练了1000K步。训练第二阶段(最大长度为512)采用的batch size为384,训练了400K步。
为什么要单独说这个呢?因为提出BERT-WWM的论文中,作者团队还同时训练出了:BERT-WWM、BERT-WWM-ext、RoBERTa-WWM-ext和RoBERTa-WWM-ext-large模型,并且对比了这些模型的性能,其中RoBERTa-WWM-ext-large的强悍性能也让很多人对它青睐有加,即便是模型发布一年之久的今天它也难逢敌手。这些模型的发布为NLP从业者、学习者和爱好者提供了极大的方便,使用起来也很简单,在此感谢作者们。
3.RoBERTa
RoBERTa是FaceBook针对BERT提出的改进,第一作者貌似是位国人大佬。RoBERTa的改进思路为:
使用了更大的训练数据集,训练时间更长,batch size更大(增加为8K);
用字节进行编码以解决未发现词的问题;
作者还对Adam算法中的两处参数
 和
和  进行了调整;
进行了调整;移除了NSP任务。论文中验证了NSP任务会破坏原本词向量的性能,所以作者在RoBERTa源码中移除了NSP任务。第一种RoBERTa的文本生成方法是每次输入连续的多个句子,直到最大长度512(可以跨文章),只不过文章和文章之间会加一个特殊的分隔符。这种训练方式叫做(full-sentences)。RoBERTa还有另一种方法:Doc-sentences,和full-sentences一样,但是不跨文章,这种训练方式结果是最优的;
Masked LM中使用了动态Mask来代替BERT的静态Masked,原本的BERT采用的是静态mask的方式,即整个训练过程,15%的Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了。而RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。作者称其为动态Masking。这样做相当于对数据进行了简单的增强,并且有一定正则化的效果,所以RoBERTa的全称为Robustly Optimized BERT Approach,即具有一定鲁棒性的BERT优化方法。
4.XLNet
其实,BERT是有缺点的,成也“mask”,败也“mask”。第一篇中有说过,masked LM的提出让BERT得以实现真正的深层双向语言模型,但预训练阶段可以mask,微调阶段是不能mask的,没有mask后就导致预训练数据和微调数据的不统一,从而引入了一些人为误差。
4.1 AR(AutoRegressive)模型和AE(AutoEncoding)模型
1) AR模型的主要任务在于评估语料的概率分布,一个序列  ,AR模型的任务就是已知
,AR模型的任务就是已知  之前的序列,预测 的值:
之前的序列,预测 的值:  ,当然这个过程也可以反向,已知 之后的序列,预测 的值:
,当然这个过程也可以反向,已知 之后的序列,预测 的值:  。两个过程可以结合,但是前后向之间是不能有信息的交换的,否则就会出现“自己看到自己”这种标签泄露现象。ELMo这个模型就是用的双向LSTM实现了这个前向后相结合的过程。AR模型的缺点就是单向性,虽然可以前向后相结合,但是在模型的学习阶段是不能结合前后向信息的,向ELMo只是单纯的拼接了前想和后向的隐状态作为输出,我们更希望的是在训练过程中就把上下文的信息融合进模型中。
。两个过程可以结合,但是前后向之间是不能有信息的交换的,否则就会出现“自己看到自己”这种标签泄露现象。ELMo这个模型就是用的双向LSTM实现了这个前向后相结合的过程。AR模型的缺点就是单向性,虽然可以前向后相结合,但是在模型的学习阶段是不能结合前后向信息的,向ELMo只是单纯的拼接了前想和后向的隐状态作为输出,我们更希望的是在训练过程中就把上下文的信息融合进模型中。
2) AE模型采用的就是以上下文的方式,最典型的案例就是BERT,利用Mask机制避免掉标签泄露的现象,实现了前向后相信息的结合,但缺点是mask会带来预训练阶段与微调阶段的数据不一致问题。
4.2 XLNet选择的方法
不同于BERT,在XLNet中,采用了AR模型,但是它用了一种奇怪的机制,让AR模型也可以学习到上下文信息,叫做排序语言模型,该模型不再对传统的AR模型的序列的值按顺序进行建模,而是最大化所有可能的序列的因式分解顺序的期望对数似然,这句话可能有点不好理解,我们以一个例子来详细说明,假如我们有一个序列[1,2,3,4],如果我们的预测目标是3,对于传统的AR模型来说,结果是:
如果采用本文的方法,先对该序列进行排列组合,最终会有24种排列方式,下图是其中可能的四种情况,对于第一种情况因为3的左边没有其他的值,所以该情况无需做对应的计算:
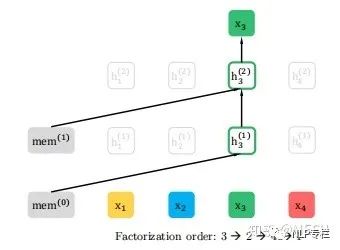
第二种情况3的左边还包括了2与4:

所以得到的结果是:
情况3、4如法炮制,这样处理过后不但保留了序列的上下文信息,也避免了采用mask标记位,巧妙的改进了BERT与传统AR模型的缺点。

在这个改动之外,XLNet还针对排序模型改进了transformer,提出了双流自注意力机制;并且集成了transformer-xl中两个重要的技术点:相对位置编码和片段循环机制。
本文XLNet部分学习自文献5,很多地方为摘抄,这里只说了语言模型方面的改进思路,其他细节见这篇博客,作者大大讲解的很清楚。