PRGC:一种新的联合关系抽取模型

点击蓝字关注NLP论文精选
©NLP论文解读 原创•作者 | 小欣
论文标题:PRGC: Potential Relation and Global Correspondence Based Joint
Relational Triple Extraction
论文链接:https://arxiv.org/pdf/2106.09895.pdf
代码:https://github.com/hy-struggle/PRGC
 前言
前言
1. 论文的相关背景
关系抽取是信息抽取和知识图谱构建的关键任务之一,它的目标是从非结构化的文本中抽取形如<头实体,关系,尾实体>的三元组数据。通常使用Pipeline方法进行抽取:先对句子进行实体识别,然后对识别出的实体两两组合进行关系分类,最后把存在关系的实体对输出为三元组。但这样的做法存在以下缺点:1. 误差积累,实体识别模块的错误会影响下面的关系分类性能。2. 实体冗余:没有关系的实体对会带来多余信息,提升错误率,同时降低整个抽取流程的效率。3. 信息利用不充分:Pipeline方法中两个子任务相对独立,无法有效利用两个子任务的内在联系和依赖关系。为了缓解Pipeline方法存在的一些问题,联合关系抽取模型应运而生。联合关系抽取模型的设计目的是希望进一步利用两个任务之间的潜在信息,加强实体识别模型和关系分类模型之间的交互。早期的联合关系抽取模型通过模型参数共享、多任务和关系信息融入序列标注等方法进行联合抽取,但取得的效果并不尽如人意。随着CasRel、TPLinker等一系列联合解码模型的提出,联合关系抽取模型开始取得SOTA的效果。
2. 论文主要解决的问题
3. 论文的主要创新和贡献
通过将关系抽取拆解为关系判断、实体提取和主客实体对⻬三个子任务,定义了一种新的关系抽取模型方法 有助于缓解CasRel、TPLinker等模型存在的关系冗余、主客实体对齐效率低等问题
 论文摘要
论文摘要
 论文模型
论文模型
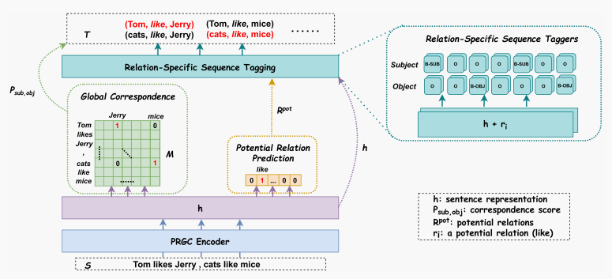
3.1 Relation Judgement
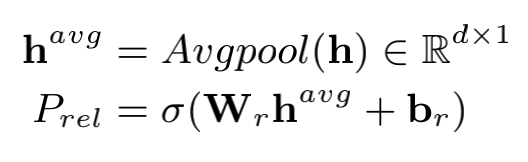
# (bs, h)
h_k_avg = self.masked_avgpool(sequence_output, attention_mask)
# (bs, rel_num)
rel_pred = self.rel_judgement(h_k_avg)
loss_func = nn.BCEWithLogitsLoss(reduction='mean')
loss_rel = loss_func(rel_pred, rel_tags.float())
在预测阶段,通过sigmoid函数获取句子对应的所有关系标签的概率,并结合预先设定的概率阈值获取句子蕴含的关系标签。
# (bs, rel_num)
rel_pred_onehot = torch.where(
torch.sigmoid(rel_pred) > rel_threshold,
torch.ones(rel_pred.size(), device=rel_pred.device),
torch.zeros(rel_pred.size(), device=rel_pred.device)
)
3.2 Entity Extraction
实体抽取模块与一般的序列标注任务的不同在于:输入的向量是融合了关系信息的句子向量。作者提供了两种融合方式,一种是直接拼接两个向量,另一种是通过向量相加进行融合。此外,实体抽取模块会将主体实体抽取和客体实体抽取分开进行抽取
if ex_params['emb_fusion'] == 'concat':
decode_input = torch.cat([sequence_output, rel_emb], dim=-1)
# sequence_tagging_sub就是个普通的序列标注模块
output_sub = self.sequence_tagging_sub(decode_input)
output_obj = self.sequence_tagging_obj(decode_input)
elif ex_params['emb_fusion'] == 'sum':
decode_input = sequence_output + rel_emb
# sequence_tagging_sum里面主客实体抽取也是分开进行的
output_sub, output_obj = self.sequence_tagging_sum(decode_input)
3.3 Subject-object Alignment
主客实体对齐模块本质上就是生成字符与字符的相关矩阵。
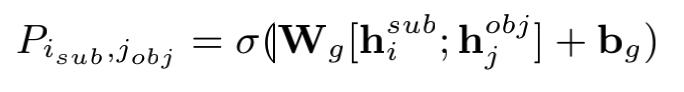
代码实现
# batch x seq_len x seq_len x 2*hidden
corres_pred = torch.cat([sub_extend, obj_extend], 3)
# (bs, seq_len, seq_len)
corres_pred = self.global_corres(corres_pred).squeeze(-1)
# global_corres的类代码
class MultiNonLinearClassifier(nn.Module):
def __init__(self, hidden_size, tag_size, dropout_rate):
super(MultiNonLinearClassifier, self).__init__()
self.tag_size = tag_size
self.linear = nn.Linear(hidden_size, int(hidden_size / 2))
self.hidden2tag = nn.Linear(int(hidden_size / 2), self.tag_size)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, input_features):
features_tmp = self.linear(input_features)
features_tmp = nn.ReLU()(features_tmp)
features_tmp = self.dropout(features_tmp)
features_output = self.hidden2tag(features_tmp)
return features_output
由于采用了拼接向量后通过全连接生成对齐矩阵,故而会占用较多的显存。笔者在这部分尝试了使用biffine机制进行向量的交叉融合,可以在不降低性能的情况下有效地节约显存。
3.4 Loss Function
PRGC的损失采用了三个子任务加权的形式,本质上都是交叉熵,只是针对不同维度进行了处理。作者在论文中并未详细讨论不同的加权方式对模型的影响,在代码实现中也是采用了常规的三个损失直接相加的结构。笔者认为由于三个损失的收敛情况不同,可以尝试根据训练轮数动态调整三个损失之间的加权关系。
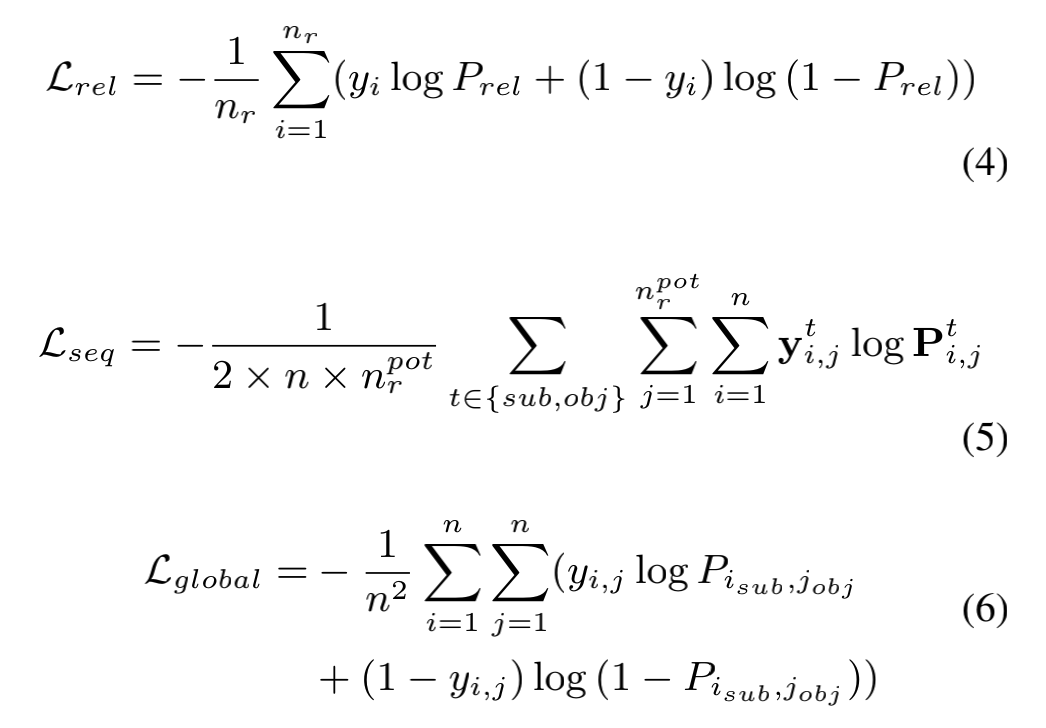
 论文实验
论文实验
PRGC主要在NYT和WebNLG上进行实验,NYT和WebNLG都有两个版本,一个版本是标注出整个实体,另一个版本是仅标注出实体的最后一个字符,作者将仅标注出实体的最后一个字符的版本记为NYT*和WebNLG*。如下例中实体North Carolina在NYT中是整体标出的,而在NYT*中则是仅标出Carolina。
NYT的数据格式:
{
"text": "North Carolina EASTERN MUSIC FESTIVAL Greensboro , June 25-July 30 .",
"triple_list": [
[
"North Carolina",
"/location/location/contains",
"Greensboro"
]
]
}
NYT*的数据格式:
{
"text": "North Carolina EASTERN MUSIC FESTIVAL Greensboro , June 25-July 30 .",
"triple_list": [
[
"Carolina",
"/location/location/contains",
"Greensboro"
]
]
}
WebNLG的数据格式:
{
"text": "Alan Bean , who graduated in 1955 from UT Austin with a B.S . and was selected by NASA in 1963 , spent 100305.0 minutes in space .",
"triple_list": [
[
"Alan Bean",
"was selected by NASA",
"1963"
]
]
}
WebNLG*的数据格式:
{
"text": "Alan Bean , who graduated in 1955 from UT Austin with a B.S . and was selected by NASA in 1963 , spent 100305.0 minutes in space .",
"triple_list": [
[
"Bean",
"was selected by NASA",
"1963"
]
]
}
评价指标采用了常见的精准率(Prec.)、 召回率(Rec.)和F1-score。实验结果如下图,可以看出PRGC在四个数据上都取得了不错的效果。
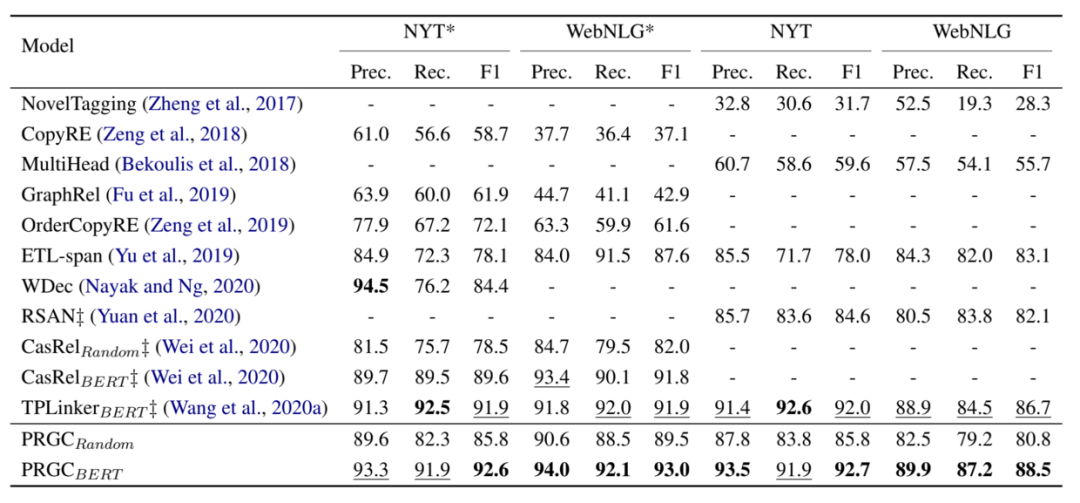
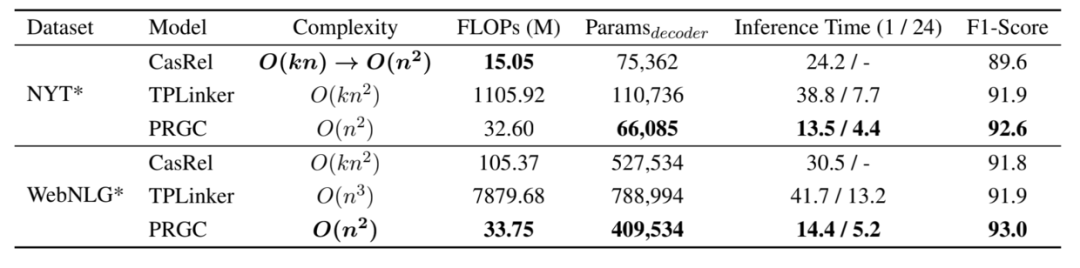
此外,作者还对PRGC的效率进行了实验,得益于PRGC可以通过关系判断去除掉句子中不包含的关系标签和整个模型不存在过于复杂的解码方式,PRGC在复杂度和推理速度上相比于CasRel和TPLinker都有明显的优势:
记得点个在看哟