
深度学习视频理解之图像分类
👆点击“博文视点Broadview”,获取更多书讯

根据中国互联网络信息中心(CNNIC)第47次《中国互联网络发展状况统计报告》,截至2020年12月,中国网民规模达到9.89亿人,其中网络视频(含短视频)用户规模达到9.27亿人,占网民整体的93.7%,短视频用户规模为8.73亿人,占网民整体的88.3%。
回顾互联网近年来的发展历程,伴随着互联网技术(特别是移动互联网技术)的发展,内容的主流表现形式经历了从纯文本时代逐渐发展到图文时代,再到现在的视频和直播时代的过渡,相比于纯文本和图文内容形式,视频内容更加丰富,对用户更有吸引力。
随着近年来人们拍摄视频的需求更多、传输视频的速度更快、存储视频的空间更大,多种场景下积累了大量的视频数据,需要一种有效地对视频进行管理、分析和处理的工具。
视频理解旨在通过智能分析技术,自动化地对视频中的内容进行识别和解析。视频理解算法顺应了这个时代的需求。因此,近年来受到了广泛关注,取得了快速发展。
图像分类(Image Classification)是视频理解的基础,视频可以看作是由一组图像帧(Frame)按时间顺序排列而成的数据结构,RNN(Recurrent Neural Networks,循环神经网络)对时序数据(Sequential Data)有很强的建模能力。
本文将介绍 RNN和它的两个重要变种,即LSTM(Long Short-Term Memory,长短期记忆网络)(Hochreiter & Schmidhuber, 1997)和GRU(Gated Recurrent Units,门控循环单元)(Cho et al., 2014)。
本文介绍的RNN 及其变种 LSTM和GRU 十分擅长处理时序数据,但是LSTM和GRU的结构和运行机理比较复杂,不好理解,因此这里会介绍一种通用的方法,通过对 LSTM和GRU 数学形式的3次简化并将数据流画成一张图,可以简洁、直观地对其中的原理进行理解与分析。
我们使用下标  :
:
其中,
其中,
RNN的计算过程如图1所示,图中左边是输入 ,两者结果相加,以及最后经过
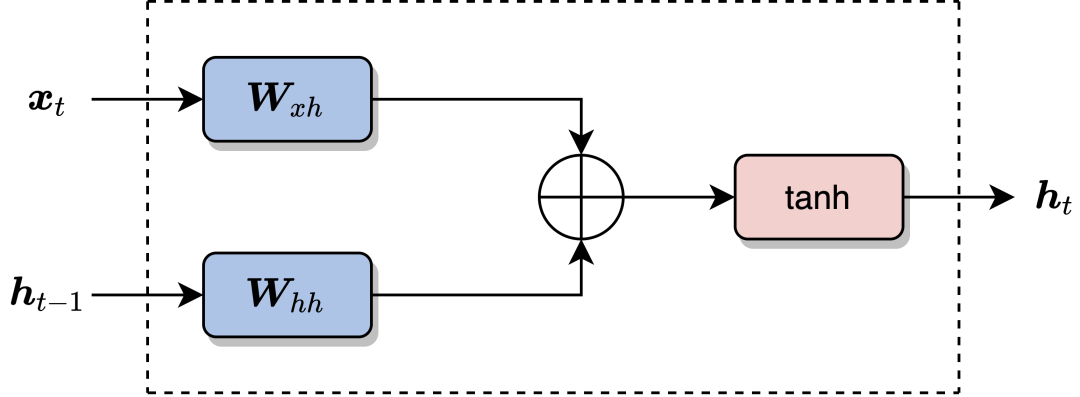
图1 RNN的计算过程
我们可以认为 。在新词 。
虽然理论上 RNN 可以捕获长距离依赖,但实际应用中,RNN 将会面临两个挑战:梯度爆炸(Gradient Explosion)和梯度消失(Vanishing Gradient),这使得 RNN 实际学习长距离依赖很难(Bengio et al., 1994)。
我们考虑一种简单情况,即激活函数是恒等(Identity)变换,此时
在进行误差反向传播(Error Backpropagation)时,当我们已知损失函数
我们可以利用RNN的依赖关系,沿时间维度展开,来计算 :
其中, 。
由于矩阵
其中
因此,
那么最后要计算的目标为:
当
(1)梯度爆炸。当 ,那么
此时偏导数
梯度爆炸相对比较好处理,可以用梯度裁剪(Gradient Clipping)(Goodfellow et al., 2016)来解决。当梯度的范数(Norm)大于某个阈值时,我们人为地给梯度乘以一个缩放系数,使得梯度的范数在我们希望的阈值内。这好比是不管前面的关税怎么加,设置一个最高市场价格,通过这个最高市场价格保证老百姓是买得起的。在RNN中,不管梯度回传的时候梯度范数大到什么程度,设置一个梯度的范数的阈值,梯度的范数最多是这么大。
(2)梯度消失。当 ,那么
此时偏导数
梯度消失现象解决起来要比梯度爆炸困难很多,如何缓解梯度消失是RNN 及几乎其他所有深度学习方法研究的关键所在。LSTM和GRU通过门控(Gate)机制控制 RNN中的信息流动,用来缓解梯度消失问题。其核心思想是有选择性地处理输入。比如我们看到一个商品的评论:
Amazing! This box of cereal gave me a perfectly balanced breakfast, as all things should be. In only ate half of it but will definitely be buying again!
我们会重点关注其中的一些词,对它们进行处理:
Amazing! This box of cereal gave me a perfectly balanced breakfast, as all things should be. In only ate half of it but will definitely be buying again!
LSTM和GRU的关键是会选择性地忽略其中一些词,不让其参与到隐层状态向量的更新中,最后只保留相关的信息进行预测。
LSTM计算过程的数学形式如下:
其中, 。和RNN 相比,LSTM 多了一个隐状态变量
(1)第1次简化:忽略门控单元 、
使用相同计算方式的目的是它们都扮演了门控的角色,而使用不同参数的目的是为了在误差反向传播阶段对3个门控单元独立地进行更新。在理解 LSTM 运行机制的时候,为了对图进行简化,我们不在图中标注3个门控单元的计算过程,并假定各门控单元是给定的。
(2)第2次简化:考虑一维门控单元 、
由于门控单元变成了一维,所以向量和向量的逐元素相乘 变成了标量和向量相乘。
(3)第3次简化:各门控单元二值输出。门控单元
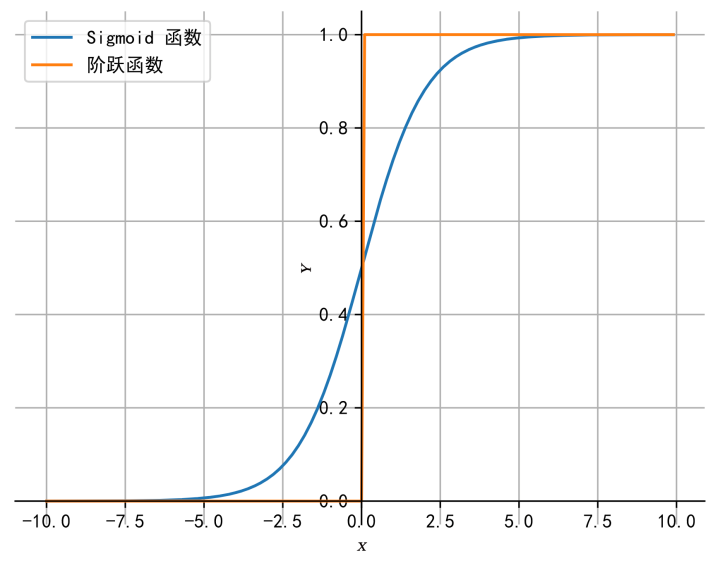
图2 Sigmoid 函数和单位阶跃函数
既然 Sigmoid 激活函数是为了近似 0/1 阶跃函数,那么,在进行 LSTM 理解分析的时候,为了理解方便,我们认为各门控单元输出是
(4)一张图。将3次简化的结果用图表示出来,左边是输入,右边是输出。在LSTM中,有一点需要特别注意,LSTM中的细胞状态 。为了方便画图,我们需要将公式做最后的调整:
最终画出的原理图如图3所示。和RNN 相同的是,网络接受两个输入,得到一个输出。其中使用了两个参数矩阵
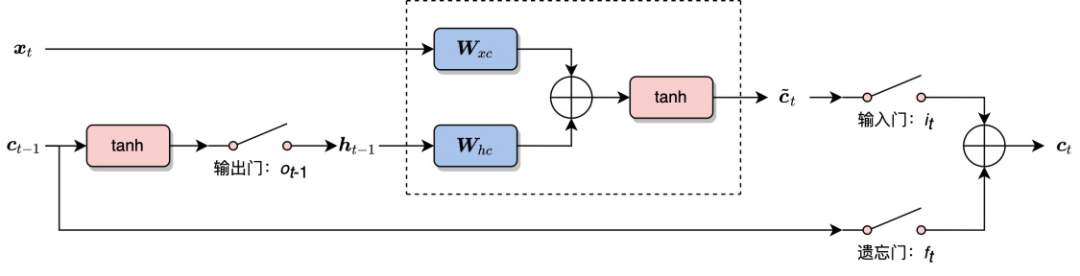
图3 LSTM 运行原理图
根据原理图,我们可以对 LSTM中各单元的作用进行分析。
输出门
:输出门的目的是从细胞状态 产生隐层单元 。并不是 中的全部信息都和隐层单元 有关, 可能包含了很多对 无用的信息。因此, 的作用就是判断 中哪些部分是对 有用的,哪些部分是无用的。 输入门
: 控制当前词 的信息融入细胞状态 。在理解一句话时,当前词 可能对整句话的意思很重要,也可能并不重要。输入门的目的就是判断当前词 对全局的重要性。当 (输入门开关打开)的时候,网络将不考虑当前输入 。遗忘门
: 控制上一时刻细胞状态 的信息融入细胞状态 。在理解一句话时,当前词 可能继续延续上文的意思继续描述,也可能从当前词 开始描述新的内容,与上文无关。和输入门 相反, 不对当前词 的重要性进行判断,而判断的是上一时刻的细胞状态 对计算当前细胞状态 的重要性。当 (遗忘门开关打开)的时候,网络将不考虑上一时刻的细胞状态 。细胞状态
: 综合了当前词 和前一时刻细胞状态 的信息。这和ResNet中的残差逼近思想十分相似(见 2.1.6 节),通过从 到 的“短路连接”,梯度得已有效地反向传播。当 (遗忘门开关闭合)时, 的梯度可以直接沿着最下面这条短路线传递到 ,不受参数 和 的影响,这是LSTM 能有效地缓解梯度消失现象的关键所在。
GRU是另一种主流的RNN衍生物。RNN和LSTM 都是在设计网络结构用于缓解梯度消失问题,只不过网络结构有所不同。GRU在数学上的形式化表示如下:
为了理解 GRU的设计思想,我们再一次运用“三次简化一张图”的方法来进行分析:
(1)第1次简化:忽略门控单元 的来源。
(2)考虑一维门控单元
(3)第3次简化:各门控单元二值输出。这里和 LSTM 略有不同的地方在于,当 ;当 。因此,
(4)一张图。将3次简化的结果用图表述出来,左边是输入,右边是输出,如图4所示。
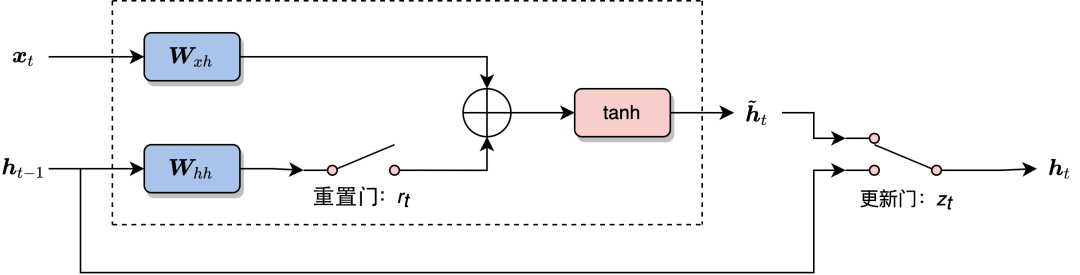
图4 GRU 运行原理图
与 LSTM 相比,GRU 将输入门 (重置门开关闭合)、
根据图4,我们可以对 GRU各单元的作用进行分析。
重置门
: 用于控制前一时刻隐层单元 对当前词 的影响。如果 对 不重要,即从当前词 开始表述了新的意思,与上文无关。那么开关 可以打开,使得 对 不产生影响; 更新门
: 用于决定是否忽略当前词 。类似于LSTM 中的输入门 , 可以判断当前词 对整体意思的表达是否重要。当 开关接通下面的支路时,我们将忽略当前词 ,同时构成了从 到 的短路连接,这使梯度得已有效地反向传播。和 LSTM 相同,这种短路机制有效地缓解了梯度消失现象,这个机制与高速公路网络(Highway Networks)(Srivastava et al., 2015a)十分相似。
*本文节选自《深度学习视频理解》一书,作者张皓
▼

本书重点介绍视频理解中的3大基础领域:动作识别(Action Recognition)、时序动作定位(Temporal Action Localization)和视频 Embedding。
动作识别的目标是识别出视频中出现的动作,通常是视频中人的动作。动作识别是视频理解的核心领域,虽然动作识别主要是识别视频中人的动作,但是该领域发展出来的算法大多数不特定针对人,也可以用于其他视频分类场景;
时序动作定位也称为时序动作检测(Temporal Action Detection),是视频理解的另一个重要领域。动作识别可以看作是一个纯分类问题,其中要识别的视频基本已经经过剪辑(Trimmed),即每个视频包含一段明确的动作,视频时长较短,且有唯一确定的动作类别。而在时序动作定位领域,视频通常没有被剪辑(Untrimmed),视频时长较长,动作通常只发生在视频中的一小段时间内,视频可能包含多个动作,也可能不包含动作,即为背景(Background)类。时序动作定位不仅要预测视频中包含了什么动作,还需要预测动作的起始和终止时刻;
视频 Embedding的主要作用是从视频中得到一个低维、稠密、浮点的特征向量表示,这个特征向量是对整个视频内容的总结和概括,使得不同视频 Embedding之间的距离(如欧式距离或余弦距离)反映了对应视频之间的相似性。
.png")
(五折专享优惠,快快扫码抢购吧!)
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,查看本书详情~