
深度学习: 细粒度图像分类 (fine-grained image recognition)

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
细粒度图像识别 (fine-grained image recognition),即 精细化分类。
细粒度图像分类(Fine-Grained Categorization),
又被称作子类别图像分类(Sub-Category Recognition),
是近年来计算机视觉、模式识别等领域一个
非常热门的研究课题. 其目的是对粗粒度的大类别
进行更加细致的子类划分, 但由于子类别间细微的
类间差异和较大的类内差异, 较之普通的图像分类
任务, 细粒度图像分类难度更大.
目前, 绝大多数的分类算法都遵循这样的流程框架:
首先找到前景对象(鸟)及其局部区域(头、脚、翅膀等), 之后分别对这些区
域提取特征. 对所得到的特征进行适当的处理之后, 用来完成分类器的训练
和预测.
精细化分类
识别出物体的大类别(比如:计算机、手机、水杯等)较易,但如果进一步去判断更为精细化的物体分类名称,则难度极大。
最大的挑战在于,同一大类别下 不同 子类别 间的 视觉差异 极小。
因此,精细化分类 所需的图像分辨率 较高。
目前,精细化分类的方法主要有以下两类:
1. 基于图像重要区域定位的方法:该方法集中探讨如何利用弱监督的信息自动找到图像中有判别力的区域,
从而达到精细化分类的目的。
2. 基于图像精细化特征表达的方法:该方法提出使用高维度的图像特征(如:bilinear vector)对图像信息进行高阶编码,
以达到准确分类的目的。
按照其使用的监督信息的多少 分为 强监督 和 弱监督
信息的细粒度图像分类模型
A. 基于强监督信息的细粒度图像分类模型

0. DeCAF Deep Convolutional Activation Feature

基于部件的CNN Part-based R-CNN
https://arxiv.org/pdf/1407.3867.pdf

2. 姿态归一化CNN Pose Normalized CNN
https://arxiv.org/pdf/1406.2952.pdf

3. 基于部位分割模型的 Mask-CNN
https://blog.csdn.net/cyiano/article/details/71440358

B. 基于弱监督信息的细粒度图像分类模型

1. 两级注意力算法 Two Level Attention Model
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Xiao_The_Application_of_2015_CVPR_paper.pdf
该模型主要关注两个不同层次的特征, 分别是对象级(Object-Level)和
局部级(Part-Level), 即在以往强监督工作中所使用的标注框和局部区域位置
这两层信息.
a. 在预处理阶段, 主要是从原始图像中检测并提取前景对象, 以减少背景信息带来的干扰. 仅仅使用卷积网络来对ss算法产生的区域中的背景区域进行过滤. 这样导致的结果是, 对于一张输入图像, 可能对应许多包含前景对象的候选区域.
b. 对象级模型,对对象级图像进行分类。一个区域候选, 经过卷积网络之后, 得到一个softmax 层的输出. 对所有区域的输出求平均, 作为该图像最终的softmax层输出.
c. 局部级模型, 为了从繁杂的候选区域中选出关键的局部区域
首先利用对象级模型得到的网络来对每一个候选区域提取特征.
对这些特征进行谱聚类, 得到k个不同的聚类簇, 每个簇代表一个局部信息, 如头部、脚等.
将不同局部区域的特征级联成一个特征向量,用来训练SVM, 作为局部级模型给出的分类器.
d. 最后, 将对象级模型的预测结果与局部级模型的结果相结合, 作为模型的最终输出.
2. 星座(Constellations)算法
https://arxiv.org/pdf/1504.08289v3.pd
3. Bilinear CNN
https://arxiv.org/pdf/1504.07889.pdf
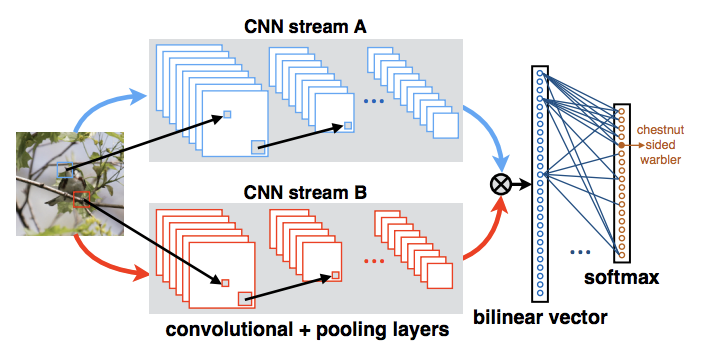
数据集
CUB200-2011 Caltech-UCSD Birds-200-2011
http://www.vision.caltech.edu/visipedia/CUB-200-2011.html
共包含200 种不同类别, 其中每类都有30+ 个训练图像,共11,788张鸟类图像数据. 每张图像包含15个局部部位标注点(part annotation)用来标记鸟类的身体部位,312 个二值属性, 1个标注框, 以及语义分割图像

Stanford Dogs 120种不同种
http://vision.stanford.edu/aditya86/ImageNetDogs/
狗的图像数据, 共有20,580 张图, 只提供标注框 和 类别标注数据
Oxford Flowers
http://www.robots.ox.ac.uk/~vgg/data/flowers/
分为两种不同规模的数据 库, 分别包含17种类别和102种类别的花. 其中,
102种类别的数据库比较常用, 每个类别包含了40到258 张图像数据, 总共有8,189张图像.
该数据库只提供语义分割图像, 不包含其他额外标注信息.Cars
http://ai.stanford.edu/~jkrause/cars/car_dataset.html
提供196类不同品牌不同年份不同车型的车辆图像数据, 一共包含有16,185张图像,分成训练集(8,144张)和测试集(8,041张)
只提供标注框信息。
FGVC-Aircraf Fine-Grained Visual Classification of Aircraft
http://www.robots.ox.ac.uk/~vgg/data/fgvc-aircraft/
提供102 类不同的飞机照片,每一类别含有100 张不同的照片, 整个数据库共
有10,200张图片, 只提供标注框信息.算法框架
1. CNN 特征提取网络(科目卷积层 、 属目卷积层、种目卷积层) 提取不同层面的特征
2. APN 注意力建议网络 得到不同的关注区域
3. DCNN 卷积细粒度特征描述网络
4. 全连接层之后得到粗细粒度互补的层次化特征表达,再通过 分类网络softmax 输出结果
注意力模型(Attention Model) 注意力机制
被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,
是深度学习技术中最值得关注与深入了解的核心技术之一。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。
人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,
而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,
是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,
忽略大多不重要的信息,这种思路仍然成立。
聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,
即权重代表了信息的重要性,而Value是其对应的信息。
图片描述(Image-Caption)
是一种典型的图文结合的深度学习应用,输入一张图片,人工智能系统输出一句描述句子,
语义等价地描述图片所示内容。可以使用Encoder-Decoder框架来解决任务目标。
1. 此时编码部分Encoder输入部分是一张图片,一般会用CNN来对图片进行特征抽取;
2. 解码Decoder部分使用RNN或者LSTM和注意力机制来输出自然语言句子。
RA-CNN
MSRA通过观察发现,对于精细化物体分类问题,其实形态、轮廓特征显得不那么重要,
而细节纹理特征则起到了主导作用。
因此提出了 “将判别力区域的定位和精细化特征的学习联合进行优化” 的构想,
从而让两者在学习的过程中相互强化,
也由此诞生了 “Recurrent Attention Convolutional Neural Network”
(RA-CNN,基于递归注意力模型的卷积神经网络)网络结构。
RA-CNN 网络可以更精准地找到图像中有判别力的子区域,
然后采用高分辨率、精细化特征描述这些区域,进而大大提高精细化物体
分类的精度: 论文地址
http://openaccess.thecvf.com/content_cvpr_2017/papers/Fu_Look_Closer_to_CVPR_2017_paper.pdf
RA-CNN思想
1. 首先原图大尺度图像通过 CNN 卷积网络 提取特征,
一部分进过APN(Attention Proposal Net 注意力建议网络)得到注意力中心框(
感兴趣区域,例如上半身区域),另一部分通过全连接层再经过softmax归一化分类概率输出;
2. 对第一步得到的注意力中心框(感兴趣区域,例如上半身区域),再进行1的步骤,
得到更小的注意力中心框,和分类概率;
3. 对第二步得到的注意力中心框(感兴趣区域,例如头部区域),通过卷积网络提取特征,通过全连接层再经过softmax归一化分类概率输出;
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码