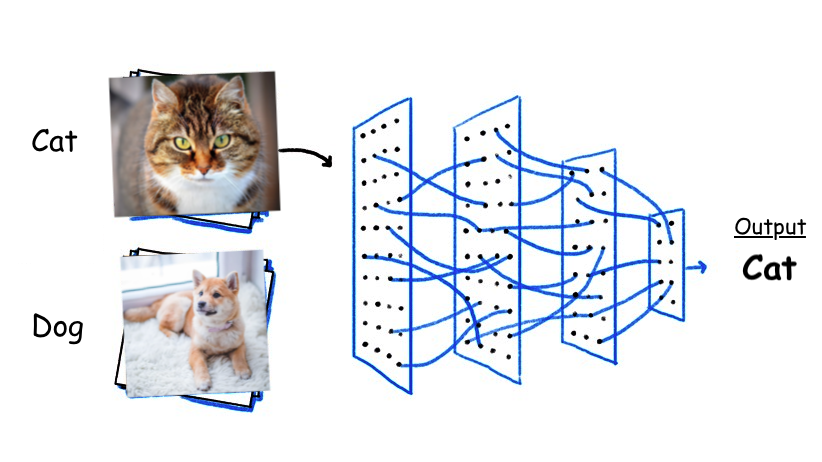
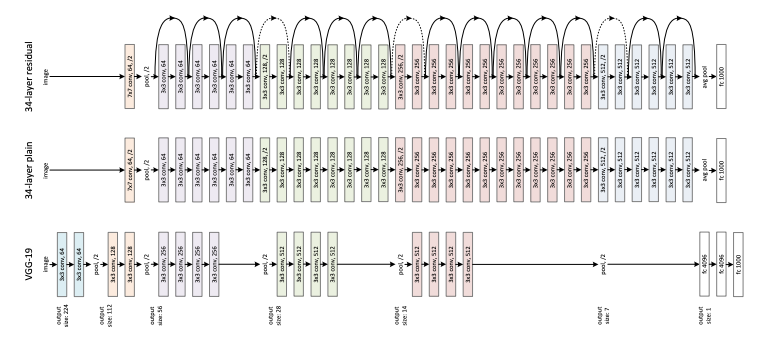
深度残差学习用于图像识别2015年可能是十年来计算机视觉发展最好的一年,我们看到了很多伟大的想法,不仅在图像分类方面,而且在各种各样的计算机视觉任务(如对象检测,语义分割等)中都应运而生。2015年诞生了一个新的网络,称为ResNet,或称为残差网络,该网络由Microsoft Research Asia的一组中国研究人员提出。正如我们在前面讨论的VGG网络,进一步深入的最大障碍是梯度消失问题,也就是说,当反向传播到更深的层时,导数变得越来越小,最终达到现代计算机体系结构无法真正有意义地表示的程度。GoogLeNet试图通过使用辅助监督和非对称初始模块来解决这一问题,但它只在一定程度上缓解了这个问题。如果我们想用50层甚至100层,有没有更好的方法让渐变流通过网络?ResNet的答案是使用残差模块。ResNet为输出添加了一个Identity输入,每个残差模块不能预测输入的是什么,从而不会迷失方向。更重要的是,残差模块不是希望每一层都直接适合所需的特征映射,而是尝试学习输出和输入之间的差异,这使得任务更加容易,因为所需的信息增益较少。假设你正在学习数学,对于每一个新的问题,你都会得到一个类似问题的解决方案,所以你需要做的就是扩展这个解决方案,并努力使它发挥作用,这比为你遇到的每一个问题想出一个全新的解决方案要容易得多。或者正如牛顿所说,我们可以站在巨人的肩膀上,Identity输入就是残差模块的那个巨人。除了Identity Mapping,ResNet还借用了Inception networks的瓶颈和批处理规范化,最终它成功地建立了一个有152个卷积层的网络,在ImageNet上达到了80.72%的最高精度。残差法后来也成为了许多其他网络的默认选择,如exception、Darknet等,并且由于其简洁美观的设计,在当今许多生产性视觉识别系统中仍被广泛应用。随着残差网络的大肆宣传,出现了许多的不变量。在《Identity Mappings in Deep Residual Networks》中,ResNet的原作者把激活放在残差模块之前,取得了更好的效果,这一设计后来被称为ResNetV2。此外,在2016年的一篇论文“Aggregated Residual Transformations for Deep Neural Networks(聚合深度神经网络的残差变换)”中,研究人员提出了ResNeXt,它为残差模块添加了并行分支,以聚合不同变换的输出。
2016年:Xception
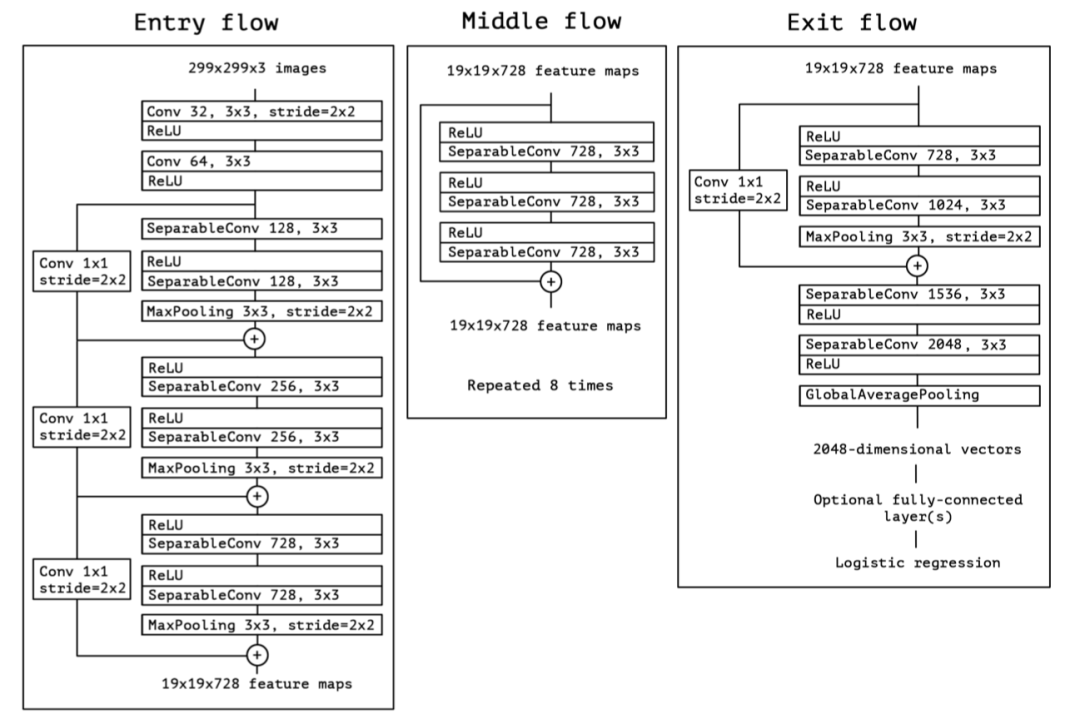
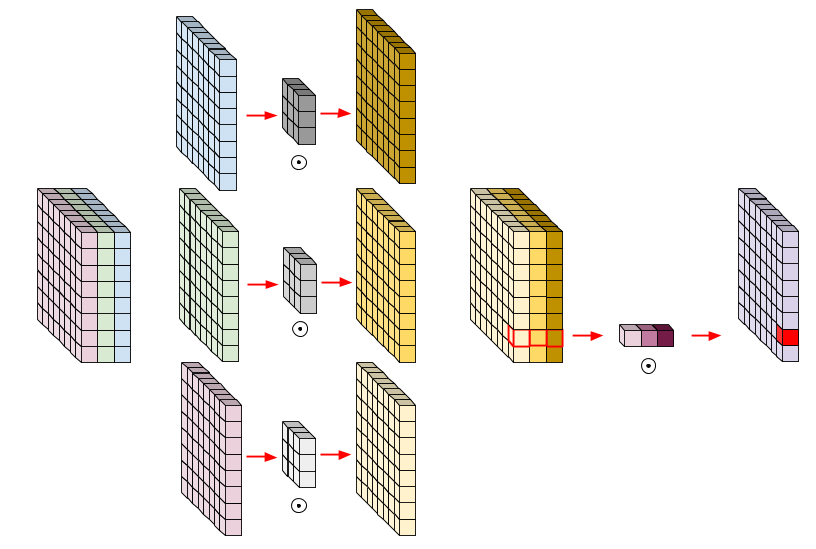
Xception:具有深度可分卷积的深度学习随着ResNet的发布,图像分类器中的大多数容易实现的目标看起来已经被抢先实现了,研究人员开始考虑研究CNN的内部机制原理。由于跨通道卷积通常会引入大量参数,因此Xception网络选择调查此操作以了解其效果的全貌。就像它的名字一样,Xception源自Inception网络。在Inception模块中,将不同转换的多个分支聚合在一起以实现拓扑稀疏性,但是为什么这种稀疏起作用了?Xception的作者,也是Keras框架的作者,将这一思想扩展到了一种极端情况,在这种情况下,一个3x3卷积对应于最后一个串联之前的一个输出通道,在这种情况下,这些并行卷积核实际上形成了一个称为深度卷积的新操作。如上图所示,与传统的卷积不同,传统的卷积方法只对每个通道分别计算卷积,然后将输出串联在一起,这减少了通道之间的特征交换,但也减少了许多连接,因此产生了一个参数较少的层,但是此操作将输出与输入相同数量的通道(如果将两个或多个通道组合在一起,则输出的通道数更少),因此,一旦信道输出被合并,我们需要另一个常规的1x1滤波器,或点卷积,来增加或减少信道的数量,就像常规卷积一样。这个想法早在一篇名为“Learning visual representations at scale(学习视觉表征的规模)”的论文中有描述,偶尔也会在InceptionV2中使用。Exception更进一步的用这种新类型取代了几乎所有的卷积。模型实验结果很好,它超越了ResNet和InceptionV3,成为一种新的SOTA图像分类方法,这也证明了CNN中的交叉相关和空间相关性的映射可以完全解耦,此外,Exception与ResNet有着相同的优点,它的设计也简单美观,因此它的思想也被许多后续的研究所使用,如MobileNet、DeepLabV3等。
Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
https://arxiv.org/abs/1409.1556
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
https://arxiv.org/abs/1409.4842
Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
https://arxiv.org/abs/1502.03167
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
https://arxiv.org/abs/1512.03385
François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
https://arxiv.org/abs/1610.02357
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
https://arxiv.org/abs/1704.04861
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
https://arxiv.org/abs/1707.07012
Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
https://arxiv.org/abs/1905.11946
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/abs/1406.4729
Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
https://arxiv.org/abs/1608.06993
Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
https://arxiv.org/abs/1709.01507
Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
https://arxiv.org/abs/1707.01083
Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks