
综述 | 计算机视觉中的小样本学习
点击左上方蓝字关注我们

前言

如今,在使用数十亿张图像来解决特定任务方面,计算机可以做到超过人类。尽管如此,在现实世界中,很少能构建或找到包含这么多样本的数据集。
我们如何克服这个问题? 在计算机视觉领域,我们可以使用数据增强 (DA),或者收集和标记额外的数据。DA 是一个强大的技术,可能是解决方案的重要组成部分。标记额外的样本是一项耗时且昂贵的任务,但它确实提供了更好的结果。
如果数据集真的很小,这两种技术可能都无济于事。 想象一个任务,我们需要建立一个分类,每个类只有一两个样本,而每个样本都非常难以找到。
这将需要创新的方法。小样本学习(Few-Shot Learning, FSL)就是其中之一。
在本文中,我们将介绍:
什么是小样本学习——定义、目的和 FSL 问题示例
小样本学习变体——N-Shot Learning、Few-shot Learning、One-Shot Learning、Zero-Shot Learning.
小样本学习方法——Meta-Learning、Data-level、Parameter-level
元学习算法——定义、度量学习、基于梯度的元学习
Few-Shot图像分类算法——与模型无关的元学习、匹配、原型和关系网络
Few-Shot目标检测 – YOLOMAML
什么是小样本学习?
Few-Shot Learning(以下简称FSL)是机器学习的一个子领域。在只有少数具有监督信息的训练样本情况下,训练模型实现对新数据进行分类。
FSL 是一个相当年轻的领域,需要更多的研究和完善。计算机视觉模型可以在相对较少的训练样本下很好地工作。在本文中,我们将重点关注计算机视觉中的 FSL。
例如:假设我们在医疗保健行业工作,在通过 X 射线照片对骨骼疾病进行分类时遇到问题。
一些罕见的病理可能缺乏足够的图像用于训练集中。这正是可以通过构建 FSL 分类器解决的问题类型。
小样本学习变体
根据FSL的不同变化和极端情况可以分为四种类型:
N-Shot Learning (NSL)
Few-shot Learning (FSL)
One-Shot Learning (OSL)
Zero-Shot Learning (ZSL)
当我们谈论 FSL 时,我们通常指的是 N-way-K-Shot-classification。
N 代表类别的数量,K 代表每个类别要训练的样本数量。
N-Shot 学习被视为比所有其他概念更广泛的概念。这意味着,Few-Shot、One-Shot 和 Zero-Shot Learning 是 NSL 的子领域。
Zero-Shot Learning (ZSL)
Zero-Shot Learning 的目标是在没有任何训练样本的情况下对看不见的类进行分类。
这可能看起来有点牛逼,可以这样想:你能在没有看到物体的情况下对它进行分类吗? 如果你对一个对象、它的外观、属性和功能有一个大致的了解,那应该不成问题。这是在进行 ZSL 时使用的方法,根据当前的趋势,零样本学习将很快变得更加有效。
One-Shot和Few-Shot
在One-Shot Learning中,每个类只有一个样本。Few-Shot 每个类有 2 到 5 个样本,使其成为更灵活的 OSL 版本。
当我们谈论整体概念时,我们使用Few-Shot Learning术语。但是这个领域还很年轻,所以人们会以不同的方式使用这些术语。
小样本学习方法
首先,让我们定义一个 N-way-K-Shot-分类问题。
假定一个训练集,包括N 类标签,每类K个标记图像(少量,每类少于十个样本),Q张测试图片。
我们想在 N 个类别中对 Q 张测试图片进行分类。 训练集中的 N * K 个样本是我们仅有的样本。这里的主要问题是没有足够的训练数据。
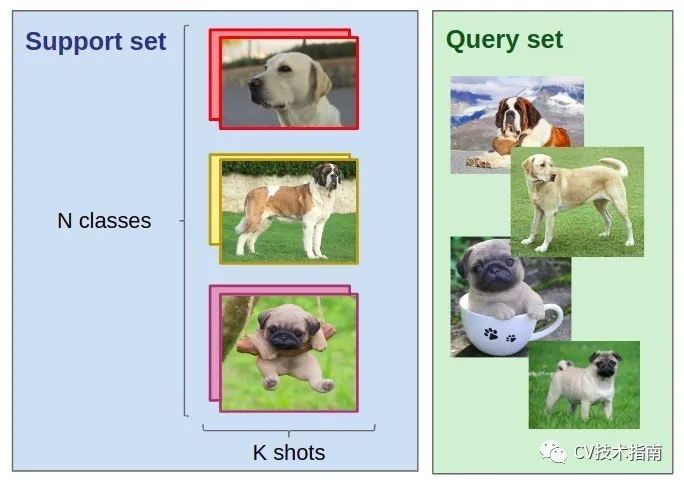
FSL 任务的第一步是从其他类似问题中获得经验。这就是为什么少样本学习被描述为元学习问题的原因。
在传统的分类问题中,我们尝试从训练数据中学习如何分类,并使用测试数据进行评估。在元学习中,我们学习如何学习给定一组训练数据进行分类。 我们将一组分类问题用于其他不相关的集合。
在解决 FSL 问题时,通常考虑两种方法:
数据级方法 (Data-level approach,DLA)
参数级方法 (Parameter-level approach,PLA)
数据级方法
这个方法真的很简单。 它基于这样一个概念:如果没有足够的数据来构建可靠的模型并避免过度拟合和欠拟合,只需要简单地添加更多数据。
这就是为什么通过使用来自大型基础数据集的附加信息来解决许多 FSL 问题的原因。基础数据集的关键特征是它没有在训练集中为Few-Show任务提供的类。 例如,如果想对特定鸟类进行分类,基础数据集可以包含许多其他鸟类的图像。
我们也可以自己产生更多的数据。为了达到这个目标,我们可以使用数据增强,甚至生成对抗网络 (GAN)。
参数级方法
从参数级别的角度来看,Few-Shot Learning 样本很容易过拟合,因为它们t通常具有广泛的高维空间。
为了克服这个问题,我们应该限制参数空间并使用正则化和适当的损失函数。 该模型将对有限数量的训练样本具有泛化能力。
另一方面,我们可以通过将其引导到广泛的参数空间来提高模型性能。 如果我们使用标准的优化算法,由于训练数据量很少,它可能无法给出可靠的结果。
这就是为什么在参数级别上训练的模型以在参数空间中找到最佳路线以提供最佳预测结果。正如我们上面已经提到的,这种技术称为元学习。
元学习算法
在经典范式中,当我们有一个特定的任务时,算法正在学习它的任务性能是否随着经验而提高。在元学习范式中,我们有一组任务。算法正在学会去学习它在每个任务上的性能是否随着经验和任务数量的增加而提高。该算法称为元学习算法。
假设我们有一个测试任务 TEST。我们将在一批训练任务 TRAIN 上训练我们的元学习算法。从尝试解决 TRAIN 任务中获得的训练经验将用于解决 TEST 任务。
解决 FSL 任务有一系列步骤。想象一下我们之前提到的分类问题。首先,我们需要选择一个基础数据集。选择基础数据集至关重要。
现在我们有 N-way-K-Shot 分类问题(让我们将其命名为 TEST)和一个大型基础数据集,我们将用作元学习训练集 (TRAIN)。
整个元训练过程将在有限的episode(情节,电视剧集)下完成。
从 TRAIN 中,我们对每个类别的 N 个类别和 K 个支持集图像以及 Q张测试图像进行采样。这样,我们就形成了一个类似于我们最终的 TEST 任务的分类任务。
在每个episode结束时,训练模型的参数以最大化测试集中 Q 图像的准确性。这是我们的模型学习解决看不见的分类问题的能力的地方。
模型的整体效率是通过其在 TEST 分类任务上的准确性来衡量的。
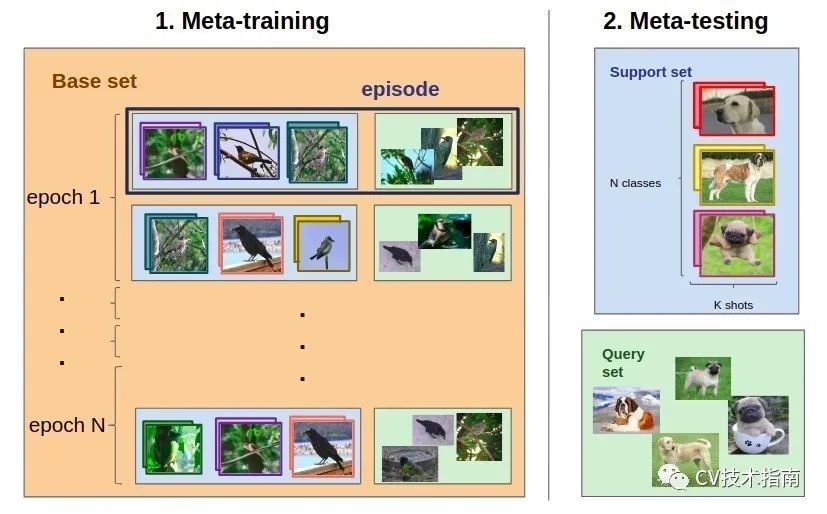
近年来,研究人员发表了许多用于解决 FSL 分类问题的元学习算法。所有这些都可以分为两大类:度量学习 (Metric-Learning) 和基于梯度的元学习 (Gradient-Based Meta-Learning) 算法。
度量学习
当我们谈论度量学习时,通常指的是在目标上学习距离函数的技术。
一般来说,度量学习算法学习比较数据样本。 在少样本分类问题的情况下,他们根据测试样本与训练样本的相似性对测试样本进行分类。如果我们处理图像,我们基本上会训练一个卷积神经网络来输出图像嵌入向量,然后与其他嵌入向量进行比较以预测类别。
基于梯度的元学习
对于基于梯度的方法,需要构建一个元学习器和一个基学习器。
元学习器是一个跨集学习的模型,而基础学习器是一个由元学习器在每个集内初始化和训练的模型。
想象一下元训练的一个片段,其中包含由 N * K 个图像训练集和 Q 测试集定义的一些分类任务:
1. 选择一个元学习器模型,
2. episode(情节)开始,
3. 初始化基础学习器(通常是 CNN 分类器),
4. 在训练集上训练它(用于训练基础学习器的确切算法由元学习器定义),
5. Base-learner 预测测试集上的类,
6. 元学习器参数根据分类错误导致的损失进行训练,
7. 从这一点来看,管道可能会根据选择的元学习器而有所不同。
Few-Shot图像分类算法
在本节中,我们将介绍:
模型不可知元学习 (Model-Agnostic Meta-Learning, MAML)
匹配网络Matching Networks
原型网络Prototypical Networks
关系网络Relation Networks
模型不可知元学习
MAML 基于梯度元学习 (GBML) 概念。GBML 是关于元学习器从训练基础模型和学习所有任务的共同特征表示中获取先前经验。每当有新任务需要学习时,元学习器会利用新任务带来的少量新训练数据对具有其先前经验的元学习器进行一点微调。
不过,我们不想从随机参数初始化开始。如果我们这样做,我们的算法在几次更新后将不会收敛到良好的性能。
MAML 旨在解决这个问题。
MAML 提供了元学习器参数的良好初始化,以在仅使用少量梯度步骤的新任务上实现最佳快速学习,同时避免使用小数据集时可能发生的过度拟合。
这是它的完成方式:
1. 元学习器在每episode(情节)开始时创建自己的副本 (C),
2. C 接受了这一episode的训练(正如我们之前讨论过的,在 base-model 的帮助下),
3. C 对测试集进行预测,
4. 根据这些预测计算的损失用于更新 C,
5. 这一直持续到对所有episode进行了训练。

这种技术的最大优点是它被认为与元学习器算法选择无关。 因此,MAML 方法被广泛用于许多需要快速适应的机器学习算法,尤其是深度神经网络。
匹配网络
匹配网络 (MN) 是第一个旨在解决 FSL 问题的度量学习算法。
对于匹配网络算法,需要使用大型基础数据集来解决小样本学习任务。如上所示,这个数据集被分成了几集(episodes)。之后,对于每一集,匹配网络应用以下步骤:
1. 来自训练集和测试集的每个图像都被送进 CNN,输出embeddings,
2. 每张测试图像使用从其embeddings到训练集embeddings的余弦距离的 softmax 进行分类,
3. 结果分类的交叉熵损失通过 CNN 反向传播。
通过这种方式,匹配网络学习计算图像嵌入。这种方法允许 MN 在没有特定类的先验知识的情况下对图像进行分类。一切都是通过比较类的不同实例来完成的。
由于每一集中的类别不同,匹配网络计算与区分类别相关的图像特征。相反,在标准分类的情况下,算法学习特定于每个类的特征。
值得一提的是,作者实际上对初始算法提出了一些改进。例如,他们用双向 LSTM 增强了他们的算法。每个图像的嵌入取决于其他图像的嵌入。
所有改进方案都可以在他们的初始文章中找到。不过,提高算法的性能可能会使计算时间更长。
原型网络
原型网络 (PN) 类似于匹配网络。尽管如此,仍有一些细微的差异有助于提高算法的性能。PN 实际上获得了比 MN 更好的结果。
PN 过程本质上是相同的,但是测试图像的embeddings不会与训练集中的每个图像embeddings进行比较。相反,原型网络提出了一种替代方法。
在PN中,你需要形成类原型。它们基本上是通过平均来自此类的图像的嵌入而形成的类嵌入。然后将测试图像嵌入仅与这些类原型进行比较。
值得一提的是,在 One-Shot Learning 问题的情况下,算法类似于 Matching Networks。
此外,PN 使用欧几里得距离而不是余弦距离。它被视为算法改进的主要部分。
关系网络
为构建匹配和原型网络而进行的所有实验实际上导致了关系网络 (RN) 的创建。RN 建立在 PN 概念之上,但对算法进行了重大更改。
距离函数不是预先定义的,而是由算法学习的。 RN 有自己的关系模块来执行此操作。
整体结构如下。关系模块放在嵌入模块的顶部,该模块是从输入图像计算嵌入和类原型的部分。关系模块被输入查询图像与每个类原型的嵌入的串联,并输出每对的关系分数。 将 Softmax 应用于关系分数,得到一个预测。

Few-Show目标检测
很明显,我们可能会在所有计算机视觉任务中遇到 FSL 问题。
一个 N-way-K-Shot 目标检测任务包括一个训练集:N个类标签,对于每一类,包含至少一个属于该类的对象的 K 个标记图像,Q张测试图片。
注意,与Few-Shot 图像分类问题有一个关键区别,因为目标检测任务存在一张图像包含属于N 个类别中的一个或多个的多个目标的情况。因此可能会面临类不平衡问题,因为算法对每个类的至少 K 个样本目标进行训练。
YOLOMAML
Few-Shot目标检测领域正在迅速发展,但有效的解决方案并不多。这个问题最稳定的解决方案是 YOLOMAML 算法。
YOLOMAML 有两个混合部分:YOLOv3 对象检测架构和 MAML 算法。
如前所述,MAML 可以应用于多种深度神经网络,这就是为什么开发人员很容易将这两部分结合起来。
YOLOMAML 是 MAML 算法在 YOLO 检测器上的直接应用。如果想了解更多信息,请查看官方 Github 存储库。
https://github.com/ebennequin/FewShotVision
总结
在本文中,我们已经弄清楚了什么是Few-Shot Learning,有哪些 FSL 变体和问题解决方法,以及可以使用哪些算法来解决图像分类和目标检测 FSL 任务。
Few-Shot Learning 是一个快速发展和有前途的领域,但仍然非常具有挑战性和未经研究,还有很多工作要做、研究和开发。
原文链接:
https://neptune.ai/blog/understanding-few-shot-learning-in-computer-vision
END
整理不易,点赞三连↓